基于局部敏感哈希的协同过滤推荐算法之E^2LSH
需要代码联系作者,不做义务咨询。
一.算法实现
基于p-stable分布,并以‘哈希技术分类’中的分层法为使用方法,就产生了E2LSH算法。
E2LSH中的哈希函数定义如下:
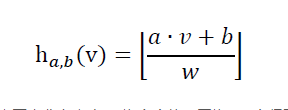
其中,v为d维原始数据,a为随机变量,由正态分布产生; w为宽度值,因为a∙v+b得到的是一个实数,如果不加以处理,那么起不到桶的效果,w是E2LSH中最重要的参数,调得过大,数据就被划分到一个桶中去了,过小就起不到局部敏感的效果。b使用均匀分布随机产生,均匀分布的范围在[0,w]。
但是这样,得到的结果是(N1,N2,…,Nk),其中N1,N2,…,Nk在整数域而不是只有0,1两个值,这样的k元组就代表一个桶。但将k元组直接当做桶标号存入哈希表,占用内存且不便于查找,为了方便存储,设计者又将其分层,使用数组+链表的方式。
对每个形式为k元组的桶标号,使用如下h1函数和h2函数计算得到两个值,其中h1的结果是数组中的位置,数组的大小也相当于哈希表的大小,h2的结果值作为k元组的代表,链接到对应数组的h1位置上的链表中。在下面的公式中,r’为[0,prime-1]中依据均匀分布随机产生。
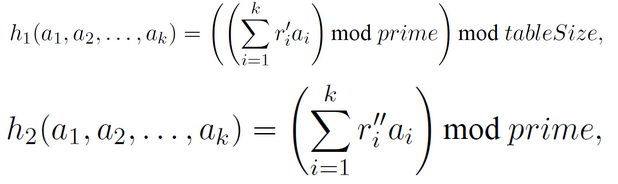
经过如上操作后,查询步骤如下。
对于查询点query,
使用k个哈希函数计算桶标号的k元组;
对k元组计算h1和h2值,
获取哈希表的h1位置的链表,
在链表中查找h2值,
获取h2值位置上存储的样本
Query与上述样本计算精确的相似度,并排序
按照顺序返回结果。
E2LSH方法存在两方面的不足[8]:首先是典型的基于概率模型生成索引编码的结果并不稳定。虽然编码位数增加,但是查询准确率的提高确十分缓慢;其次是需要大量的存储空间,不适合于大规模数据的索引。E2LSH方法的目标是保证查询结果的准确率和查全率,并不关注索引结构需要的存储空间的大小。E2LSH使用多个索引空间以及多次哈希表查询,生成的索引文件的大小是原始数据大小的数十倍甚至数百倍。
部分参考文献:http://dataunion.org/12912.html
二.遗留问题
2.1 hash过后不是还需要由hash吗找到原来的点么,怎么实现?
2.2 球p稳定分布例子
2.3 k元组存入多个哈希表?那查找的结果是什么?每个表中的结果的并?
三.问题扩展
E2LSH可以说是分层法基于p-stable distribution的应用。另一种当然是转换成hashcode,则定义哈希函数如下:

其中,a和v都是d维向量,a由正态分布产生。同上,选择k个上述的哈希函数,得到一个k位的hamming码,按照”哈希技术分类”中描述的技术即可使用该算法。
KP7L6G16E0.png)
基于局部敏感哈希的协同过滤推荐算法之E^2LSH的更多相关文章
- 基于局部敏感哈希的协同过滤算法之simHash算法
搜集了快一个月的资料,虽然不完全懂,但还是先慢慢写着吧,说不定就有思路了呢. 开源的最大好处是会让作者对脏乱臭的代码有羞耻感. 当一个做推荐系统的部门开始重视[数据清理,数据标柱,效果评测,数据统计, ...
- 基于物品的协同过滤推荐算法——读“Item-Based Collaborative Filtering Recommendation Algorithms” .
ligh@local-host$ ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.0.3 基于物品的协同过滤推荐算法--读"Item-Based ...
- 基于MapReduce的(用户、物品、内容)的协同过滤推荐算法
1.基于用户的协同过滤推荐算法 利用相似度矩阵*评分矩阵得到推荐列表 已经推荐过的置零 2.基于物品的协同过滤推荐算法 3.基于内容的推荐 算法思想:给用户推荐和他们之前喜欢的物品在内容上相似的物品 ...
- SimRank协同过滤推荐算法
在协同过滤推荐算法总结中,我们讲到了用图模型做协同过滤的方法,包括SimRank系列算法和马尔科夫链系列算法.现在我们就对SimRank算法在推荐系统的应用做一个总结. 1. SimRank推荐算法的 ...
- SparkMLlib—协同过滤推荐算法,电影推荐系统,物品喜好推荐
SparkMLlib-协同过滤推荐算法,电影推荐系统,物品喜好推荐 一.协同过滤 1.1 显示vs隐式反馈 1.2 实例介绍 1.2.1 数据说明 评分数据说明(ratings.data) 用户信息( ...
- 大规模异常滥用检测:基于局部敏感哈希算法——来自Uber Engineering的实践
uber全球用户每天会产生500万条行程,保证数据的准确性至关重要.如果所有的数据都得到有效利用,t通过元数据和聚合的数据可以快速检测平台上的滥用行为,如垃圾邮件.虚假账户和付款欺诈等.放大正确的数据 ...
- Spark ML协同过滤推荐算法
一.简介 协同过滤算法[Collaborative Filtering Recommendation]算法是最经典.最常用的推荐算法.该算法通过分析用户兴趣,在用户群中找到指定用户的相似用户,综合这些 ...
- 推荐系统| ② 离线推荐&基于隐语义模型的协同过滤推荐
一.离线推荐服务 离线推荐服务是综合用户所有的历史数据,利用设定的离线统计算法和离线推荐算法周期性的进行结果统计与保存,计算的结果在一定时间周期内是固定不变的,变更的频率取决于算法调度的频率. 离线推 ...
- 在茫茫人海中发现相似的你——局部敏感哈希(LSH)
一.引入 在做微博文本挖掘的时候,会发现很多微博是高度相似的,因为大量的微博都是转发其他人的微博,并且没有添加评论,导致很多数据是重复或者高度相似的.这给我们进行数据处理带来很大的困扰,我们得想办法把 ...
随机推荐
- Linux 命令 - traceroute: 数据报传输路径追踪
traceroute 工具用于跟踪数据报的传输路径:当数据报从一台计算机传向另一台计算机时,会经过多重的网关,traceroute 命令能够找到数据报传输路径上的所有路由器.通过 traceroute ...
- Nginx - Rewrite Module
Initially, the purpose of this module (as the name suggests) is to perform URL rewriting. This mecha ...
- asp.net上传文件时出现 404 - 找不到文件或目录。
昨天客户网站反应上传较大文件时出现404-找不到文件或目录的错误.如图: 网站上给出的提示是上传文件不能超过50M,但是在38M和40M这样的文件都不能上传了,显然不对. 在网上查了很久,第一个是检查 ...
- HDOJ2000ASCII码排序
ASCII码排序 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Su ...
- 风云CM - 算法分析 & genkey实现
// 风云CM分析 // 计算用户名 00402D8A |> \8D45 F8 LEA EAX, [LOCAL.2] 00402D8D |. 50 PUSH EAX 00402D8E |. E8 ...
- 什么是C++标准库?
C++中的标准程序库(简称标准库)是类库和函数的集合,其使用核心语言写成.标准程序库提供若干泛型容器.函数对象.泛型字符串和流(包含交互和文件I/O),支持部分语言特性和常用的函数,如开平方根.C++ ...
- javascript 实现图片预览(未上传到服务器端)
1,图片预览 越来越多的浏览器为了安全,都不能获得文件的,全路径,实现图片预览实现起来有点麻烦.有人选择复制图片到服务器的某个路径下,然后从服务器端找到路径,实现预览.但这不是最佳实现方案,如果用户一 ...
- 第九篇、微信小程序-button组件
主要属性: 注:button-hover 默认为{background-color: rgba(0, 0, 0, 0.1); opacity: 0.7;} 效果图: ml: <!--默认的but ...
- MacBook Pro 的照相机在哪?
用于拍照 用于录制视频
- Apache 使用密码文件验证用户
使用文本文件作为密码文件 创建密码文件 需要使用htpasswd.exe文件来创建用户密码文件 语法: htpasswd -c '文件完整路径' 用户名 向一个用户密码文件中添加一个新用户 语法: h ...