重新认识mapreduce
写这篇文章,是因为最近遇到了mapreduce的二次排序问题。以前的理解不完全正确。首先看一下mapreduce的过程

相信这张图熟悉MR的人都应该见过,再来一张图

wordcount也不细说了,hadoop里面的hello,world
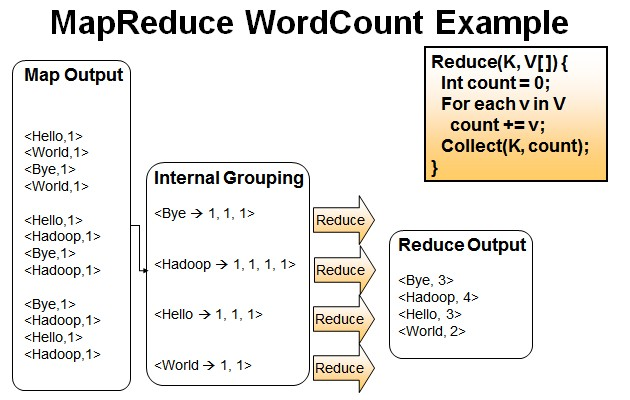
之前我的理解是map过来的<k,v>会形成(k,<v1,v2,v3...>)的格式,并且按照这种思路写出来不少的mapreduce程序,而且没有错。
后来自定义Writable对象,封装一组值作为key,也没有什么问题,而且一直认为key只要在compareTo中重写 了方法就万事大吉,而且compareTo返回0的会作为相同的key。误区就在这里,之前一直认为key相同的value会合并到一个"list"中-。这句话就有错,key是key,value是value,根本不会将key对应的value合并在一起,真实情况是默认将key相同(compareTo返回0的)的合并成了一组,在组相同的里面去foreach里面的value,如果是自定义key的话你可以将key打印一下,或发现key并不相同。
上代码:
- public class Entry implements WritableComparable<Entry> {
- private String yearMonth;
- private int count;
- public Entry() {
- }
- @Override
- public int compareTo(Entry entry) {
- int result = this.yearMonth.compareTo(entry.getYearMonth());
- if (result == 0) {
- result = Integer.compare(count, entry.getCount());
- }
- return result;
- }
- @Override
- public void write(DataOutput dataOutput) throws IOException {
- dataOutput.writeUTF(yearMonth);
- dataOutput.writeInt(count);
- }
- @Override
- public void readFields(DataInput dataInput) throws IOException {
- this.yearMonth = dataInput.readUTF();
- this.count = dataInput.readInt();
- }
- public String getYearMonth() {
- return yearMonth;
- }
- public void setYearMonth(String yearMonth) {
- this.yearMonth = yearMonth;
- }
- public int getCount() {
- return count;
- }
- public void setCount(int count) {
- this.count = count;
- }
- @Override
- public String toString() {
- return yearMonth;
- }
- }
自定义分区 EntryPartitioner.java
- public class EntryPartitioner extends Partitioner<Entry, Text> {
- @Override
- public int getPartition(Entry entry, Text paramVALUE, int numberPartitions) {
- return Math.abs((entry.getYearMonth().hashCode() % numberPartitions));
- }
- }
自定义分组
- public class EntryGroupingComparator extends WritableComparator {
- public EntryGroupingComparator() {
- super(Entry.class, true);
- }
- @Override
- public int compare(WritableComparable a, WritableComparable b) {
- Entry a1 = (Entry) a;
- Entry b1 = (Entry) b;
- return a1.getYearMonth().compareTo(b1.getYearMonth());
- }
- }
mapper类
- public class SecondarySortMapper extends
- Mapper<LongWritable, Text, Entry, Text> {
- private Entry entry = new Entry();
- private Text value = new Text();
- @Override
- protected void map(LongWritable key, Text lines, Context context)
- throws IOException, InterruptedException {
- String line = lines.toString();
- String[] tokens = line.split(",");
- String yearMonth = tokens[0] + "-" + tokens[1];
- int count = Integer.parseInt(tokens[2]);
- entry.setYearMonth(yearMonth);
- entry.setCount(count);
- value.set(tokens[2]);
- context.write(entry, value);
- }
- }
reducer类
- public class SecondarySortReducer extends Reducer<Entry, Text, Entry, Text> {
- @Override
- protected void reduce(Entry key, Iterable<Text> values, Context context)
- throws IOException, InterruptedException {
- System.out.println("-----------------华丽的分割线-----------------");
- StringBuilder builder = new StringBuilder();
- for (Text value : values) {
- System.out.println(key+"==>"+value);
- builder.append(value.toString());
- builder.append(",");
- }
- context.write(key, new Text(builder.toString()));
- }
- }
reducer中打印出来的跟原来想的不一样,一组的值除了自定义分组的属性相同外,其他的属性有不同的。看来以前是自己理解不够深入啊,特此写出,以示警戒
重新认识mapreduce的更多相关文章
- Mapreduce的文件和hbase共同输入
Mapreduce的文件和hbase共同输入 package duogemap; import java.io.IOException; import org.apache.hadoop.co ...
- mapreduce多文件输出的两方法
mapreduce多文件输出的两方法 package duogemap; import java.io.IOException; import org.apache.hadoop.conf ...
- mapreduce中一个map多个输入路径
package duogemap; import java.io.IOException; import java.util.ArrayList; import java.util.List; imp ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- [Hadoop in Action] 第5章 高阶MapReduce
链接多个MapReduce作业 执行多个数据集的联结 生成Bloom filter 1.链接MapReduce作业 [顺序链接MapReduce作业] mapreduce-1 | mapr ...
- MapReduce
2016-12-21 16:53:49 mapred-default.xml mapreduce.input.fileinputformat.split.minsize 0 The minimum ...
- 使用mapreduce计算环比的实例
最近做了一个小的mapreduce程序,主要目的是计算环比值最高的前5名,本来打算使用spark计算,可是本人目前spark还只是简单看了下,因此就先改用mapreduce计算了,今天和大家分享下这个 ...
- MapReduce剖析笔记之八: Map输出数据的处理类MapOutputBuffer分析
在上一节我们分析了Child子进程启动,处理Map.Reduce任务的主要过程,但对于一些细节没有分析,这一节主要对MapOutputBuffer这个关键类进行分析. MapOutputBuffer顾 ...
- MapReduce剖析笔记之七:Child子进程处理Map和Reduce任务的主要流程
在上一节我们分析了TaskTracker如何对JobTracker分配过来的任务进行初始化,并创建各类JVM启动所需的信息,最终创建JVM的整个过程,本节我们继续来看,JVM启动后,执行的是Child ...
- MapReduce剖析笔记之六:TaskTracker初始化任务并启动JVM过程
在上面一节我们分析了JobTracker调用JobQueueTaskScheduler进行任务分配,JobQueueTaskScheduler又调用JobInProgress按照一定顺序查找任务的流程 ...
随机推荐
- sso demo 取消https (cas)
基本配置 参考之前得随笔 http://www.cnblogs.com/rocky-fang/p/5354947.html 1. 修改tomcat-cas 配置 1.1 在 D:\test\sso\ ...
- MYSQL 练习
导出现有数据库数据: mysqldump -u用户名 -p密码 数据库名称 >导出文件路径 # 结构+数据 mysqldump -u用户名 -p密码 -d 数据库名称 > ...
- ahjesus code simith 存储过程模板
<%------------------------------------------------------------------------------------------ * Au ...
- 【LoadRunner】OSGI性能测试实例
其实我们就两点 Ø 确定测试登录最大并发用户数:Ø 事务平均响应时间 (两个查询) 得到这个任务 如何展开测试工作呢? 一.WindowsResources 设置(其实不监控 设不设都行 我感觉) ...
- NotSerializableException解决方法
NotSerializableException 问题描述: 想要写入对象的时候的时候回抛出NotSerializableException:类名 原因: 写入的对象没有序列化,即没有实现java.i ...
- Lua-泛型for循环 pairs和ipairs的区别
先看一段简单的代码: local mytable = { , , aa = "abc", subtable = {}, , } --for循环1 print("for - ...
- jQuery自定义漂亮的下拉框插件8种效果演示
原始的下拉框不好看这里推荐一个jQuery自定义漂亮的下拉框插件8种效果演示 在线预览 下载地址 实例代码 <!DOCTYPE html> <html lang="en&q ...
- jQuery BreakingNews 间歇滚动
BreakingNews 是一款基于jQuery的间歇滚动插件.它可以设置标题.标题颜色.标题背景颜色.链接颜色.字体大小.边框.宽度.自动滚动.间歇时间等等,同时它还好提供两种过度方式--淡入淡出( ...
- 众人口中的JAVASCRIPT
目前所说的JAVASCRIPT=ECMAscript+DOM+BOM DOM全称:Document Object Model,造作网页内容的标准. BOM全称:Browse Object Model, ...
- angularjs——插值字符串
一.何为插值字符串? 其实插值字符串的意思就是:拥有字符插值标记的字符串.如: hello,{{ to }}....字符插值标记:相当于我们平时在字符串替换中使用到的占位符.上面的例子中的{{to}} ...