1.8-1.10 大数据仓库的数据收集架构及监控日志目录日志数据,实时抽取之hdfs系统上
一、数据仓库架构
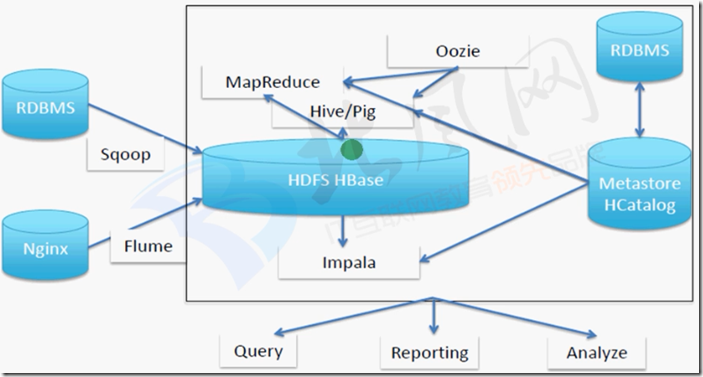
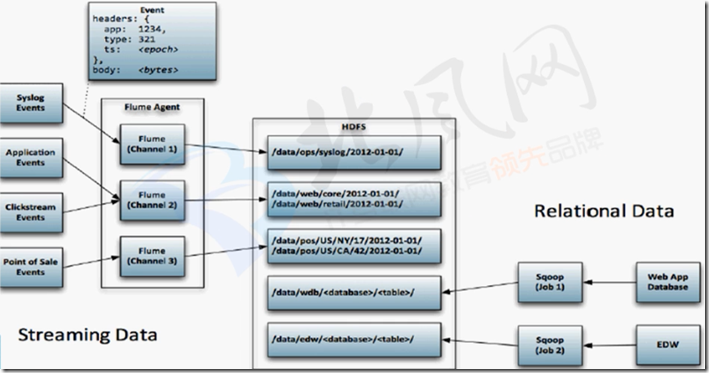
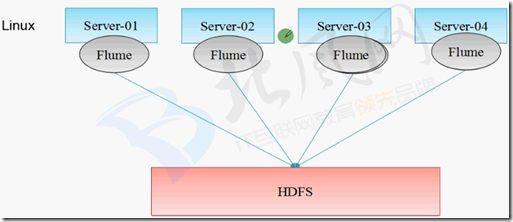
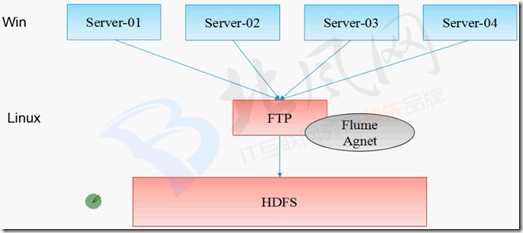
二、flume收集数据存储到hdfs
文档:http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#hdfs-sink
三、监控日志目录日志数据,实时抽取之hdfs系统上-实验
1、Source:Spooling Directory
在使用exec来监听数据源虽然实时性较高,但是可靠性较差,当source程序运行异常或者Linux命令中断都会造成数据丢失,
在恢复正常运行之前数据的完整性无法得到保障。 Spooling Directory Paths通过监听某个目录下的新增文件,并将文件的内容读取出来,实现日志信息的收集。实际生产中会结合log4j来使用。
被传输结束的文件会修改后缀名,添加.COMPLETED后缀(可修改)。
2、
监控目录
>日志目录,抽取完整的日志文件,写的日志文件不抽取 使用FileChannel
>本地文件系统缓冲,比内存安全性更高 数据存储HDFS
>存储对应hive表的目录或者hdfs目录
3、配置flume agent
##agent 配置文件:flume-app.conf 如下:
# The configuration file needs to define the sources,
# the channels and the sinks.
####define agent
a3.sources = r3
a3.channels = c3
a3.sinks = k3
###define sources
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir = /opt/cdh-5.3.6/flume-1.5.0-cdh5.3.6/spoollogs
a3.sources.r3.ignorePattern = ^(.)*\.log$
a3.sources.r3.fileSuffix = .delete
###define channel
a3.channels.c3.type = file
a3.channels.c3.checkpointDir = /opt/cdh-5.3.6/flume-1.5.0-cdh5.3.6/filechannel/checkpoint
a3.channels.c3.dataDirs = /opt/cdh-5.3.6/flume-1.5.0-cdh5.3.6/filechannel/data
###define sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://hadoop-senior.ibeifeng.com:8020/user/root/flume/splogs/
a3.sinks.k3.hdfs.fileType = DataStream
a3.sinks.k3.hdfs.writeFormat = Text
a3.sinks.k3.hdfs.batchSize = 10
###bind the soures and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
对agent配置文件的解释:
##define sources字段:
type : spooldir //通过监听某个目录下的新增文件,并将文件的内容读取出来,实现日志信息的收集
spoolDir //从哪个目录中读取数据
ignorePattern //排除哪些文件,用正则匹配
fileSuffix //给读取完的文件,加上一个后缀名 ##define channel
type = file //channel存到文件中,而不是内存,这样不易丢失数据
checkpointDir //存储检查点文件的存放目录
dataDirs //逗号分隔的目录列表,用于存储日志文件。在单独的磁盘上使用多个目录可以提高文件通道的性能 ##define sink
type = hdfs //抽取完的数据存到hdfs上
hdfs.path //在hdfs上的存储路径
hdfs.fileType //hdfs上的存储的文件格式,DataStream不会压缩输出文件
writeFormat //序列文件记录的格式,应该设置为Text,否则这些文件不能被Apache Impala(孵化)或Apache Hive读取
batchSize //number of events written to file before it is flushed to HDFS
4、运行agent
##先准备一些数据
mkdir -p /opt/cdh-5.3.6/flume-1.5.0-cdh5.3.6/spoollogs #创建待抽取数据存放目录 [root@hadoop-senior spoollogs]# ls #准备三个数据文件
emp.txt hivef.log hivef.sql mkdir -p /opt/cdh-5.3.6/flume-1.5.0-cdh5.3.6/filechannel/{checkpoint,data} #创建channel数据存放目录 bin/hdfs dfs -mkdir -p /user/root/flume/splogs/ #在hdfs上创建此目录 ##运行agent
bin/flume-ng agent \
-c conf \
-n a3 \
-f conf/flume-app.conf \
-Dflume.root.logger=DEBUG,console ##此时查看/opt/cdh-5.3.6/flume-1.5.0-cdh5.3.6/spoollogs中的数据,emp.txt hivef.sql后缀加上了.delete
##hivef.log没有加后缀,因为我们排除了.log的文件
[root@hadoop-senior spoollogs]# ls
emp.txt.delete hivef.log hivef.sql.delete ##查看hdfs上有没有数据,已经有了
[root@hadoop-senior hadoop-2.5.0-cdh5.3.6]# bin/hdfs dfs -ls -R /user/root/flume/splogs/
-rw-r--r-- 3 root supergroup 463 2019-05-09 09:37 /user/root/flume/splogs/FlumeData.1557365835585
-rw-r--r-- 3 root supergroup 228 2019-05-09 09:37 /user/root/flume/splogs/FlumeData.1557365835586
1.8-1.10 大数据仓库的数据收集架构及监控日志目录日志数据,实时抽取之hdfs系统上的更多相关文章
- 利用Flume将MySQL表数据准实时抽取到HDFS
转自:http://blog.csdn.net/wzy0623/article/details/73650053 一.为什么要用到Flume 在以前搭建HAWQ数据仓库实验环境时,我使用Sqoop抽取 ...
- SQL Server自动化运维系列——关于数据收集(多服务器数据收集和性能监控)
需求描述 在生产环境中,很多情况下需要采集数据,用以定位问题或者形成基线. 关于SQL Server中的数据采集有着很多种的解决思路,可以采用Trace.Profile.SQLdiag.扩展事件等诸多 ...
- SQL Server自动化运维系列 - 多服务器数据收集和性能监控
需求描述 在生产环境中,很多情况下需要采集数据,用以定位问题或者形成基线. 关于SQL Server中的数据采集有着很多种的解决思路,可以采用Trace.Profile.SQLdiag.扩展事件等诸多 ...
- SQL Server 自动化运维系列 - 多服务器数据收集和性能监控
需求描述 在生产环境中,很多情况下需要采集数据,用以定位问题或者形成基线. 关于SQL Server中的数据采集有着很多种的解决思路,可以采用Trace.Profile.SQLdiag.扩展事件等诸多 ...
- 第三百五十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—数据收集(Stats Collection)
第三百五十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—数据收集(Stats Collection) Scrapy提供了方便的收集数据的机制.数据以key/value方式存储,值大多是计数 ...
- 三十三 Python分布式爬虫打造搜索引擎Scrapy精讲—数据收集(Stats Collection)
Scrapy提供了方便的收集数据的机制.数据以key/value方式存储,值大多是计数值. 该机制叫做数据收集器(Stats Collector),可以通过 Crawler API 的属性 stats ...
- 【转】sql server数据收集和监控
转自:https://www.cnblogs.com/zhijianliutang/p/4476403.html 相关系列: https://www.cnblogs.com/zhijianliutan ...
- 创建数据收集器集(DSC)
TechNet 库 Windows Server Windows Server 2008 R2 und Windows Server 2008 按类别提供的 Windows Server 内容 按类别 ...
- GIS+=地理信息+行业+大数据——基于云环境流处理平台下的实时交通创新型app
应用程序已经是近代的一个最重要的IT创新.应用程序是连接用户和数据之间的桥梁,提供即时訪问信息是最方便且呈现的方式也是easy理解的和令人惬意的. 然而,app开发人员.尤其是后端平台能力,一直在努力 ...
随机推荐
- 笔记04 WPF对象引用
转自:http://www.fx114.net/qa-261-90254.aspx 我们应该都知道,XAML是一种声明式语言,XAML的标签声明的就是对象.一个XAML标签会对应着一个对象,这个对象一 ...
- vim调试
首先,想调试一个程序的话,输入以下命令: guest-djjtew@ubuntu:~$ python3 -m pdb 1.py 这时候就停止了,等待着你的输入,然后输入"l"的话, ...
- fedora delete openJDK
博客分类: linux 由于Fedora系统安装的时候会自带OpenJDK,安装完系统后 java -version 会显示 [root@localhost bin]# java -versio ...
- Vuex demo
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- ubuntu环境eclipse配置
ubuntu环境eclipse配置 首先下载Eclipse和JDK: 然后将上边两个压缩包解压到安装文件夹(如;/home/linux/softwares/java).然后配置/etc/profile ...
- 解析PE文件的附加数据
解析程序自己的附加数据,将附加数据写入文件里. 主要是解析PE文件头.定位到overlay的地方.写入文件. 常应用的场景是在crackme中,crackme自身有一段加密过的附加数据.在crackm ...
- 多媒体开发之---h.264 SPS PPS解析源代码,C实现一以及nal分析器
http://blog.csdn.net/mantis_1984/article/details/9465909 http://blog.csdn.net/arau_sh/article/detail ...
- 推荐一套免费跨平台的delphi 哈希及加密算法库
delphi 目前提供了部分哈希及加密算法. 但是不是特别全,今天给大家推荐一套免费的.跨平台的算法库. https://github.com/winkelsdorf/DelphiEncryption ...
- easyui datagrid 加载静态文件中的json数据
本文主要介绍easyui datagrid 怎么加载静态文件里的json数据,开发环境vs2012, 一.json文件所处的位置 二.json文件内容 {"total":28,&q ...
- 一款很好的日程安排插件fullcalendar 非常适合OA等系统
1.插件下载 http://arshaw.com/fullcalendar/download/ 2. <!DOCTYPE html> <meta http-equiv="C ...