第1节 flume:12、flume的load_balance实现机制
1.5、flume的负载均衡load balancer
负载均衡是用于解决一台机器(一个进程)无法解决所有请求而产生的一种算法。Load balancing Sink Processor 能够实现 load balance 功能,如下图Agent1 是一个路由节点,负责将 Channel 暂存的 Event 均衡到对应的多个 Sink组件上,而每个 Sink 组件分别连接到一个独立的 Agent 上,示例配置,如下所示:
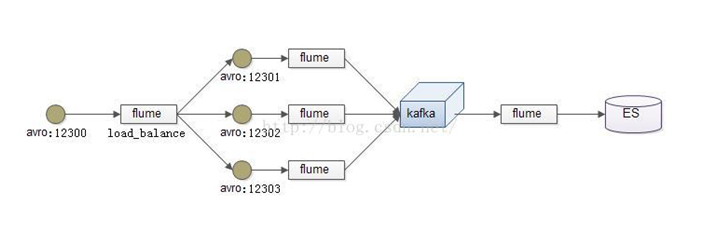
在此处我们通过三台机器来进行模拟flume的负载均衡
三台机器规划如下:
node01:采集数据,发送到node02和node03机器上去
node02:接收node01的部分数据
node03:接收node01的部分数据
第一步:开发node01服务器的flume配置
node01服务器配置:
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim load_balancer_client.conf
#agent name
a1.channels = c1
a1.sources = r1
a1.sinks = k1 k2
#set gruop
a1.sinkgroups = g1
#set channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /export/servers/taillogs/access_log
# set sink1
a1.sinks.k1.channel = c1
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node02
a1.sinks.k1.port = 52020
# set sink2
a1.sinks.k2.channel = c1
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = node03
a1.sinks.k2.port = 52020
#set sink group
a1.sinkgroups.g1.sinks = k1 k2
#set failover
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = round_robin
a1.sinkgroups.g1.processor.selector.maxTimeOut=10000
第二步:开发node02服务器的flume配置
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim load_banlancer_server.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = node02
a1.sources.r1.port = 52020
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
第三步:开发node03服务器flume配置
node03服务器配置
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim load_banlancer_server.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = node03
a1.sources.r1.port = 52020
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
第四步:准备启动flume服务
启动node03的flume服务
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin
bin/flume-ng agent -n a1 -c conf -f conf/load_balancer_server.conf -Dflume.root.logger=DEBUG,console
启动node02的flume服务
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin
bin/flume-ng agent -n a1 -c conf -f conf/load_balancer_server.conf -Dflume.root.logger=DEBUG,console
启动node01的flume服务
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin
bin/flume-ng agent -n a1 -c conf -f conf/load_balancer_client.conf -Dflume.root.logger=DEBUG,console
第五步:node01服务器运行脚本产生数据
cd /export/servers/shells
sh tail-file.sh
第1节 flume:12、flume的load_balance实现机制的更多相关文章
- Flume篇---Flume安装配置与相关使用
一.前述 Copy过来一段介绍Apache Flume 是一个从可以收集例如日志,事件等数据资源,并将这些数量庞大的数据从各项数据资源中集中起来存储的工具/服务,或者数集中机制.flume具有高可用, ...
- [Flume][Kafka]Flume 与 Kakfa结合例子(Kakfa 作为flume 的sink 输出到 Kafka topic)
Flume 与 Kakfa结合例子(Kakfa 作为flume 的sink 输出到 Kafka topic) 进行准备工作: $sudo mkdir -p /flume/web_spooldir$su ...
- [Flume]使用 Flume 来传递web log 到 hdfs 的例子
[Flume]使用 Flume 来传递web log 到 hdfs 的例子: 在 hdfs 上创建存储 log 的目录: $ hdfs dfs -mkdir -p /test001/weblogsfl ...
- flume到flume消息传递
环境:两台虚拟机( 每台都有flume) 第一台slave作为消息的产生者 第二台master作为消息的接收者 IP(192.168.83.133) 原理:通过监听slave中文件的变化,获取变 ...
- 12.Flume的安装
先把flume包上传并解压 给flume创建一个软链接 给flume配置环境变量 #flume export FLUME_HOME=/opt/modules/flume export PATH=$PA ...
- 整体认识flume:Flume介绍、分布式安装、常见问题及解决方案
问题导读 1.什么是flume? 2.flume包含哪些组件? 3.Flume在读取utf-8格式的文件时会出现解析不了时间戳,该如何解决? Flume是一个分布式.可靠.和高可用的海量日志采集.聚合 ...
- Flume学习——Flume中事务的定义
首先要搞清楚的问题是:Flume中的事务用来干嘛? Flume中的事务用来保证消息的可靠传递. 当使用继承自BasicChannelSemantics的Channel时,Flume强制在操作Chann ...
- Flume学习——Flume的架构
Flume有三个组件:Source.Channel 和 Sink.在源码中对应同名的三个接口. When a Flume source receives an event, it stores it ...
- 【Flume】flume于transactionCapacity和batchSize进行详细的分析和质疑的概念
我不知道你用flume读者熟悉无论这两个概念 一开始我是有点困惑,? 没感觉到transactionCapacity的作用啊? batchSize又是干啥的啊? -- -- 带着这些问题,我们深入源代 ...
随机推荐
- OVS数据库操作
说明 [Record]就是行对应的_uuid [if-exists]当值不存在的是否会报错而不是返回False 基本信息查询 列举数据库 # ovsdb-client list-dbs Open_vS ...
- ZOJ2898【折半搜索】
题意: 给出一系列值和对应的陷阱,对于陷阱如果存在两个就抵消,求价值最大. 思路: 折半枚举,利用异或 #include <bits/stdc++.h> using namespace s ...
- wordcount作业
搭档:201631062427,201631062627 代码地址:https://gitee.com/oyyyyyy/wordcount 作业地址: 一: 代码互审情况 我们采用的都是c语言的方式完 ...
- C++ com
http://www.cnblogs.com/hlxs/p/3783920.html 昨天看了<COM本质论>的第一章"COM是一个更好的C++",觉得很有必要做一些笔 ...
- .Net WebApi接口Swagger集成简单使用
Swagger介绍 Swagger 是一款RESTFUL接口的.基于YAML.JSON语言的文档在线自动生成.代码自动生成的工具.而我最近做的项目用的是WebAPI,前后端完全分离,这时后端使用Swa ...
- left join on 和where条件的放置(转)
http://blog.csdn.net/muxiaoshan/article/details/7617533
- 洛谷P1002 过河卒
关于蒟蒻的我,刚刚接触DP.... 那么就来做一道简单DP吧.... 首先先看题: 题目描述 棋盘上AA点有一个过河卒,需要走到目标BB点.卒行走的规则:可以向下.或者向右.同时在棋盘上CC点有一 ...
- moment.js插件的简单上手使用
开发过程中看长篇幅的技术文档是件多么影响多发效率的事情丫,哼哼,人家明明只是想用个简单的功能而已丫,下面文档很好的解决了这个问题,yeah~~~ 一.monent.js时间插件 1.Moment.js ...
- [LOJ 2190] 「SHOI2014」信号增幅仪
[LOJ 2190] 「SHOI2014」信号增幅仪 链接 链接 题解 坐标系直到 \(x\) 轴与椭圆长轴平行 点的坐标变换用旋转公式就可以了 因为是椭圆,所以所有点横坐标除以 \(p\) 然后最小 ...
- GIT使用笔记一:GIT初始化配置
本人系统环境:centos6.5 下 LNMP centos下git安装很简单sudo yum install gitOK 可先进行git 的全局配置 用户信息 git config --global ...