Python基础-week06 面向对象编程基础
一.面向对象编程
1.面向过程 与 面向对象编程
面向过程的程序设计:
核心是 过程二字,过程指的是解决问题的步骤,即先干什么再干什么......面向过程的设计就好比精心设计好一条流水线,是一种机械式的思维方式。
优点是:复杂度的问题流程化,进而简单化(一个复杂的问题,分成一个个小的步骤去实现,实现小的步骤将会非常简单)
缺点是:一套流水线或者流程就是用来解决一个问题,生产汽水的流水线无法生产汽车,即便是能,也得是大改,改一个组件,牵一发而动全身。
应用场景:一旦完成基本很少改变的场景,著名的例子有Linux內核,git,以及Apache HTTP Server等。
面向对象的程序设计:
核心是 对象二字,(要理解对象为何物,必须把自己当成上帝,上帝眼里世间存在的万物皆为对象,不存在的也可以创造出来。面向对象的程序设计好比如来设计西游记,如来要解决的问题是把经书传给东土大唐,如来想了想解决这个问题需要四个人:唐僧,沙和尚,猪八戒,孙悟空,每个人都有各自的特征和技能(这就是对象的概念,特征和技能分别对应对象的数据属性和方法属性),然而这并不好玩,于是如来又安排了一群妖魔鬼怪,为了防止师徒四人在取经路上被搞死,又安排了一群神仙保驾护航,这些都是对象。然后取经开始,师徒四人与妖魔鬼怪神仙交互着直到最后取得真经。如来根本不会管师徒四人按照什么流程去取),对象是特征与技能的结合体,基于面向对象设计程序就好比在创造一个世界,你就是这个世界的上帝,存在的皆为对象,不存在的也可以创造出来,与面向过程机械式的思维方式形成鲜明对比,面向对象更加注重对现实世界的模拟,是一种“上帝式”的思维方式。
优点是:解决了程序的扩展性。对某一个对象单独修改,会立刻反映到整个体系中,如对游戏中一个人物参数的特征和技能修改都很容易。
缺点是:
1. 编程的复杂度远高于面向过程,不了解面向对象而立即上手基于它设计程序,极容易出现过度设计的问题。一些扩展性要求低的场景使用面向对象会徒增编程难度,比如管理linux系统的shell脚本就不适合用面向对象去设计,面向过程反而更加适合。
2. 无法向面向过程的程序设计流水线式的可以很精准的预测问题的处理流程与结果,面向对象的程序一旦开始就由对象之间的交互解决问题,即便是上帝也无法准确地预测最终结果。于是我们经常看到对战类游戏,新增一个游戏人物,在对战的过程中极容易出现阴霸的技能,一刀砍死3个人,这种情况是无法准确预知的,只有对象之间交互才能准确地知道最终的结果。
应用场景:需求经常变化的软件,一般需求的变化都集中在用户层,互联网应用,企业内部软件,游戏等都是面向对象的程序设计大显身手的好地方
面向对象的程序设计并不是全部。对于一个软件质量来说,面向对象的程序设计只是用来解决扩展性。
选读:程序设计思想发展史:http://www.cnblogs.com/linhaifeng/articles/6428835.html
二.类与对象
1.类与对象的关系
如果说对象是特征和技能的结合体,类则是一些列对象相似的特征与技能的结合体。
在现实世界中:一定是现有一个个具体的对象,然后随着人类文明的发展由人类站在不同的角度总结出来的类。
注意:
1.类是抽象的概念,而对象才是具体存在的事物。
2.站在不同的角度,可以总结出不同的类。
在程序中:一定是先有类,后调用类产生对象!!
2.如何定义类和对象
按照上述步骤,我们来定义一个类(我们站在老男孩学校的角度去看,在座的各位都是学生)
#在现实世界中,站在老男孩学校的角度:先有对象,再有类
对象1:李坦克
特征:
学校=oldboy
姓名=李坦克
性别=男
年龄=18
技能:
学习
吃饭
睡觉 对象2:王大炮
特征:
学校=oldboy
姓名=王大炮
性别=女
年龄=38
技能:
学习
吃饭
睡觉 对象3:牛榴弹
特征:
学校=oldboy
姓名=牛榴弹
性别=男
年龄=78
技能:
学习
吃饭
睡觉 现实中的老男孩学生类
相似的特征:
学校=oldboy
相似的技能:
学习
吃饭
睡觉 在现实世界中:先有对象,再有类
现实世界中:现有对象,后有类!
#在程序中,务必保证:先定义(类),后使用(产生对象)
PS:
1. 在程序中特征用变量标识,技能用函数标识
2. 因而类中最常见的无非是:变量和函数的定义 #程序中的类
class OldboyStudent:
school='oldboy'
def learn(self):
print('is learning') def eat(self):
print('is eating') def sleep(self):
print('is sleeping') #注意:
1.类中可以有任意python代码,这些代码在类定义阶段便会执行
2.因而会产生新的名称空间,用来存放类的变量名与函数名,可以通过OldboyStudent.__dict__查看
3.对于经典类来说我们可以通过该字典操作类名称空间的名字(新式类有限制),但python为我们提供专门的.语法
4.点是访问属性的语法,类中定义的名字,都是类的属性 #程序中类的用法
.:专门用来访问属性,本质操作的就是__dict__
OldboyStudent.school #等于经典类的操作OldboyStudent.__dict__['school']
OldboyStudent.school='Oldboy' #等于经典类的操作OldboyStudent.__dict__['school']='Oldboy'
OldboyStudent.x=1 #等于经典类的操作OldboyStudent.__dict__['x']=1
del OldboyStudent.x #等于经典类的操作OldboyStudent.__dict__.pop('x') #程序中的对象
#调用类,或称为实例化,得到对象
s1=OldboyStudent()
s2=OldboyStudent()
s3=OldboyStudent() #如此,s1、s2、s3都一样了,而这三者除了相似的属性之外还各种不同的属性,这就用到了__init__
#注意:该方法是在对象产生之后才会执行,只用来为对象进行初始化操作,可以有任意代码,但一定不能有返回值
class OldboyStudent:
......
def __init__(self,name,age,sex):
self.name=name
self.age=age
self.sex=sex
...... s1=OldboyStudent('李坦克','男',18) #先调用类产生空对象s1,然后调用OldboyStudent.__init__(s1,'李坦克','男',18)
s2=OldboyStudent('王大炮','女',38)
s3=OldboyStudent('牛榴弹','男',78) #程序中对象的用法
#执行__init__,s1.name='牛榴弹',很明显也会产生对象的名称空间
s2.__dict__
{'name': '王大炮', 'age': '女', 'sex': 38} s2.name #s2.__dict__['name']
s2.name='王三炮' #s2.__dict__['name']='王三炮'
s2.course='python' #s2.__dict__['course']='python'
del s2.course #s2.__dict__.pop('course') 在程序中:先定义类,后产生对象
程序中:先有类,后有对象!
3.细说 __init__方法
#方式一、为对象初始化自己独有的特征
class People:
country='China'
x=1
def run(self):
print('----->', self) # 实例化出三个空对象
obj1=People()
obj2=People()
obj3=People() # 为对象定制自己独有的特征
obj1.name='egon'
obj1.age=18
obj1.sex='male' obj2.name='lxx'
obj2.age=38
obj2.sex='female' obj3.name='alex'
obj3.age=38
obj3.sex='female' # print(obj1.__dict__)
# print(obj2.__dict__)
# print(obj3.__dict__)
# print(People.__dict__) #方式二、为对象初始化自己独有的特征
class People:
country='China'
x=1
def run(self):
print('----->', self) # 实例化出三个空对象
obj1=People()
obj2=People()
obj3=People() # 为对象定制自己独有的特征
def chu_shi_hua(obj, x, y, z): #obj=obj1,x='egon',y=18,z='male'
obj.name = x
obj.age = y
obj.sex = z chu_shi_hua(obj1,'egon',18,'male')
chu_shi_hua(obj2,'lxx',38,'female')
chu_shi_hua(obj3,'alex',38,'female') #方式三、为对象初始化自己独有的特征
class People:
country='China'
x=1 def chu_shi_hua(obj, x, y, z): #obj=obj1,x='egon',y=18,z='male'
obj.name = x
obj.age = y
obj.sex = z def run(self):
print('----->', self) obj1=People()
# print(People.chu_shi_hua)
People.chu_shi_hua(obj1,'egon',18,'male') obj2=People()
People.chu_shi_hua(obj2,'lxx',38,'female') obj3=People()
People.chu_shi_hua(obj3,'alex',38,'female') # 方式四、为对象初始化自己独有的特征
class People:
country='China'
x=1 def __init__(obj, x, y, z): #obj=obj1,x='egon',y=18,z='male'
obj.name = x
obj.age = y
obj.sex = z def run(self):
print('----->', self) obj1=People('egon',18,'male') #People.__init__(obj1,'egon',18,'male')
obj2=People('lxx',38,'female') #People.__init__(obj2,'lxx',38,'female')
obj3=People('alex',38,'female') #People.__init__(obj3,'alex',38,'female') # __init__方法
# 强调:
# 1、该方法内可以有任意的python代码
# 2、一定不能有返回值
class People:
country='China'
x=1 def __init__(obj, name, age, sex): #obj=obj1,x='egon',y=18,z='male'
# if type(name) is not str:
# raise TypeError('名字必须是字符串类型')
obj.name = name
obj.age = age
obj.sex = sex def run(self):
print('----->', self) # obj1=People('egon',18,'male')
obj1=People(3537,18,'male') # print(obj1.run)
# obj1.run() #People.run(obj1)
# print(People.run) !!!__init__方法之为对象定制自己独有的特征
init的演变过程
PS:
1. 站的角度不同,定义出的类是截然不同的,详见面向对象实战之需求分析
2. 现实中的类并不完全等于程序中的类,比如现实中的公司类,在程序中有时需要拆分成部门类,业务类......
3. 有时为了编程需求,程序中也可能会定义现实中不存在的类,比如策略类,现实中并不存在,但是在程序中却是一个很常见的类
4.python为类内置的特殊属性
类名.__name__# 类的名字(字符串)
类名.__doc__# 类的文档字符串
类名.__base__# 类的第一个父类(在讲继承时会讲)
类名.__bases__# 类所有父类构成的元组(在讲继承时会讲)
类名.__dict__# 类的字典属性
类名.__module__# 类定义所在的模块
类名.__class__# 实例对应的类(仅新式类中)
ps:类的特殊属性(了解即可)
5.从代码级别看面向对象 (补充)
#1、在没有学习类这个概念时,数据与功能是分离的
def exc1(host,port,db,charset):
conn=connect(host,port,db,charset)
conn.execute(sql)
return xxx def exc2(host,port,db,charset,proc_name)
conn=connect(host,port,db,charset)
conn.call_proc(sql)
return xxx #每次调用都需要重复传入一堆参数
exc1('127.0.0.1',3306,'db1','utf8','select * from tb1;')
exc2('127.0.0.1',3306,'db1','utf8','存储过程的名字') #2、我们能想到的解决方法是,把这些变量都定义成全局变量
HOST=‘127.0.0.1’
PORT=3306
DB=‘db1’
CHARSET=‘utf8’ def exc1(host,port,db,charset):
conn=connect(host,port,db,charset)
conn.execute(sql)
return xxx def exc2(host,port,db,charset,proc_name)
conn=connect(host,port,db,charset)
conn.call_proc(sql)
return xxx exc1(HOST,PORT,DB,CHARSET,'select * from tb1;')
exc2(HOST,PORT,DB,CHARSET,'存储过程的名字') #3、但是2的解决方法也是有问题的,按照2的思路,我们将会定义一大堆全局变量,这些全局变量并没有做任何区分,即能够被所有功能使用,然而事实上只有HOST,PORT,DB,CHARSET是给exc1和exc2这两个功能用的。言外之意:我们必须找出一种能够将数据与操作数据的方法组合到一起的解决方法,这就是我们说的类了 class MySQLHandler:
def __init__(self,host,port,db,charset='utf8'):
self.host=host
self.port=port
self.db=db
self.charset=charset
def exc1(self,sql):
conn=connect(self.host,self.port,self.db,self.charset)
res=conn.execute(sql)
return res def exc2(self,sql):
conn=connect(self.host,self.port,self.db,self.charset)
res=conn.call_proc(sql)
return res obj=MySQLHandler('127.0.0.1',3306,'db1')
obj.exc1('select * from tb1;')
obj.exc2('存储过程的名字') #改进
class MySQLHandler:
def __init__(self,host,port,db,charset='utf8'):
self.host=host
self.port=port
self.db=db
self.charset=charset
self.conn=connect(self.host,self.port,self.db,self.charset)
def exc1(self,sql):
return self.conn.execute(sql) def exc2(self,sql):
return self.conn.call_proc(sql) obj=MySQLHandler('127.0.0.1',3306,'db1')
obj.exc1('select * from tb1;')
obj.exc2('存储过程的名字') 数据与专门操作该数据的功能组合到一起
代码实例面向对象
三.实例变量和类变量 与 私有方法和私有属性
类变量:类中的变量,作用于类,类中的实例可以共用的属性和状态,类本身也可以调用。
实例变量:实例中的变量,描述实例的一些属性和状态,仅作用于该实例,其他实例和类无法使用。
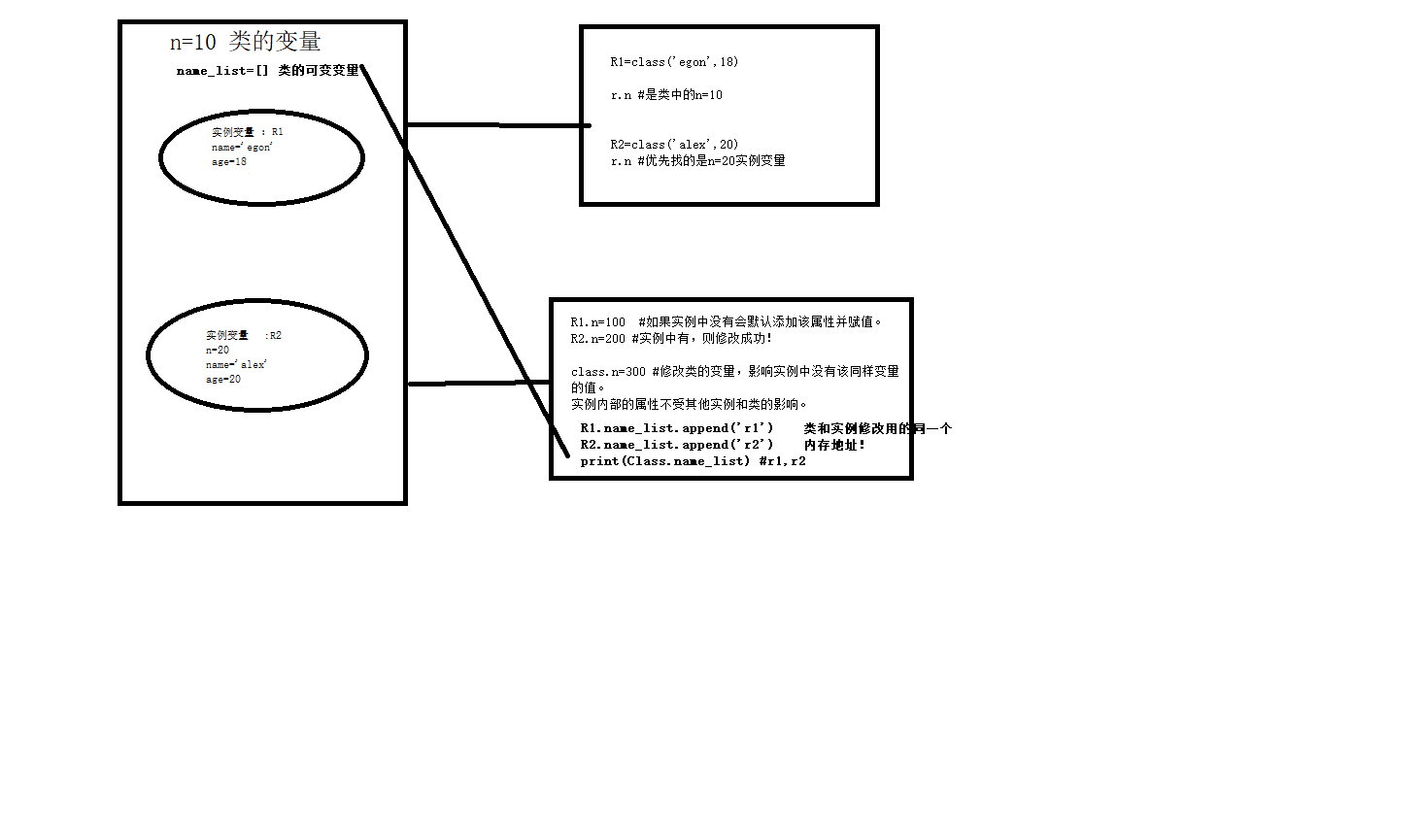
1.类变量 和 实例变量关系:
#Author http://www.cnblogs.com/Jame-mei class Role1:
n=10 #类变量
name='我是类name'
name_list=[]
def __init__(self,name,password,age,sex):#构造函数,实例化的时候做初始化工作
self.name=name
self.password=password
self.age=age
self.sex=sex #实例变量(静态属性) def study1(self): #类的方法,功能(动态属性)
print('%s is study'%self.name) class Role2:
n = 20
name='我是类name'
def __init__(self, password, age, sex):
self.password = password
self.age = age
self.sex = sex def study2(self):
print('%s is study' % self.name) r1=Role1('egon','',18,'male')
r2=Role2('',20,'male') r1.study1() #等价于 Role1.study1(r1)
print(r1.n)# 等价于print(Role1.n) 不用实例化也可以调用类变量 #类变量可以被其中的实例和类本身调用,且实例变量优先于类变量!
print(r1.name) #egon
print(Role1.name) #我是类name
print(r2.name) #我是类name,如果实例本身没有,找类的变量! #给实例添加属性
r1.money=100 #给r1实例添加的属性,不共享给其他实例。
print(r1.money) r2.name='alex'
print(r2.name)#alex,而查找不再是类变量的name了
#print(r2.money) #AttributeError: 'Role2' object has no attribute 'money' #修改实例的属性值
print(r1.name)#egon
r1.name='jame'
print(r1.name) #jame #修改类变量
r1.n=20
print(r1.n) #200 最后变成了添加属性了,类变量的值依然不变!
print(Role1.n) # r111=Role1('jame','',18,'male')
print(r111.n) #10 重新创建的实例,发现实例中没有n,会取类变量中找依然为10 #所需需要这么修改才生效
Role1.n=200
print(r1.n) #20 不会影响r1,有实例化添加的n变量。
print(r111.n) #200 #但是会影响r111,因为r111中没有n变量,还是会去找类变量!! #删除实例的属性
#del r1.sex
print(r1.sex) #AttributeError: 'Role1' object has no attribute 'sex' #添加类变量为一个列表
r1.name_list.append('from r1')
r111.name_list.append('from r111') print(r1.name_list) #['from r1', 'from r111']
print(r111.name_list) #['from r1', 'from r111']
print(Role1.name_list) #['from r1', 'from r111'] Role1.name_list.append('abc') print(r1.name_list) #['from r1', 'from r111', 'abc']
#由此可见,类的变量如果是可变类型,则实例和类都可以进行修改!
类变量和实例变量
2.类变量的作用 和 析构造函数
类变量的作用:减小开销(当多个实例共用一份变量时候)
class People:
cn='China' #国籍
def __init__(self,name,password,age,sex,cn='china'):#构造函数,实例化的时候做初始化工作
self.name=name
self.password=password
self.age=age
self.sex=sex #实例变量(静态属性) def study1(self): #类的方法,功能(动态属性)
print('%s is study'%self.name) p1=People('egon','',18,'male')
p2=People('egon','',18,'male')
#__init__中的cn变量和类中的cn变量,虽然实现效果相同,但是存在地址不一样
#如果有13亿人,cn的基本都是china,用类变量可节省开销。
类变量的作用
析构函数的作用:在实例释放、销毁的时候自动执行的,通常做一些扫尾工作。例如:关闭一些数据库的链接,临时打开的文件的....
#Author http://www.cnblogs.com/Jame-mei class Role:
def __init__(self,name,age):
self.name=name
self.age=age def __del__(self):
print('%s 彻底死了...'%self.name) def study(self):
print('%s:%s 正在学习..'%(self.name,self.age)) # r1=Role('zhangshan',18)
# r1.study()
#
# r2=Role('lisi',20)
# r2.study()
'''
zhangshan:18 正在学习..
lisi:20 正在学习..
zhangshan 彻底死了... #程序结束后,执行析构函数!!!
lisi 彻底死了...
''' r1=Role('zhangshan',18)
r1.study()
del r1 #在创建r2的时候,删除r1变量,模拟析构函数的作用! r2=Role('lisi',20)
r2.study()
'''
zhangshan:18 正在学习..
zhangshan 彻底死了... #这里结束了实力r1,会执行构函数!
lisi:20 正在学习..
lisi 彻底死了...
'''
析构函数作用模拟练习
3.私有方法和私有属性
私有属性:以__开头加变量名 ,只能在类的内部进行使用,实例化的对象无法直接使用和修改该属性。
私有方法:与私有属性概念类似,外部无法直接使用。
class Role:
def __init__(self,name,age,life_value=100):
self.name=name
self.age=age
self.__life_value=life_value #该私有属性,仅供在实例内部使用!!
# 通过对象无法直接查看和修改等操作。 def show_status(self):
print('%s:%s'%(self.name,self.__life_value)) def __got_shot(self): #私有方法和私有属性类似
self.__life_value-=50 #私有属性,在内部进行修改!
print('收到攻击减少:%s 的生命值'%(self.__life_value)) r1=Role('zhangshan',18)
#print(r1.__life_value) #私有属性无法通过对象.来使用
# #AttributeError: 'Role' object has no attribute '__life_value' r1.show_status()
#r1.__got_shot() #私有方法,无法通过对象,来使用
# #AttributeError: 'Role' object has no attribute '__got_shot'
私有属性和私有方法
四.属性查找
类有两种属性:数据属性和函数属性
1. 类的数据属性是所有对象共享的
class StudentPeople:
school='Oldboy' def choosecourse(self):
print('select course') print(id(StudentPeople.school))
s1=StudentPeople()
s2=StudentPeople()
s3=StudentPeople() print(id(s1.school))
print(id(s2.school))
print(id(s3.school))
'''
2460035560424
2460035560424
2460035560424
2460035560424
'''
类的属性共享给对象
2. 类的函数属性是绑定给对象用的
#Author http://www.cnblogs.com/Jame-mei class StudentPeople:
school='Oldboy' def choosecourse(self):
print('select course') print(id(StudentPeople.choosecourse),StudentPeople.choosecourse) print(id(s1.choosecourse),s1.choosecourse)
print(id(s2.choosecourse),s2.choosecourse)
print(id(s3.choosecourse),s3.choosecourse)
'''
1713127898104
<function StudentPeople.choosecourse at 0x0000017EAE633BF8> 1713094935752
1713094935752
1713094935752
<bound method StudentPeople.choosecourse of <__main__.StudentPeople object at 0x0000017EAE4BC978>>
<bound method StudentPeople.choosecourse of <__main__.StudentPeople object at 0x0000017EAE4BC198>>
<bound method StudentPeople.choosecourse of <__main__.StudentPeople object at 0x0000017EAE4BC470>>
'''
类的方法共享给对象
3.创建类和对象 本质上也是在创建"名称空间"
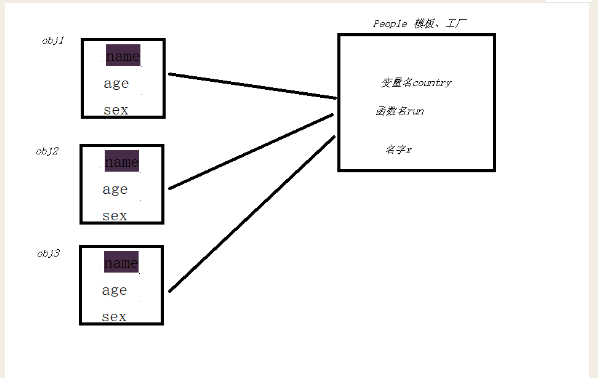
所以属性的查找顺序为: 在obj.name会先从obj实例化中名称空间里找name属性,找不到则去类中找,类也找不到就找父类...最后都找不到就抛出异常 !
练习:编写一个学生类,产生一堆学生对象,要求有一个计算器(属性),统计一共实例化多少次?
class StudentPeople:
count=0 def __init__(self,name,age,sex):
self.name=name
self.age=age
self.sex=sex
StudentPeople.count+=1 s1=StudentPeople('egon',18,'male')
s2=StudentPeople('mark',28,'female')
s3=StudentPeople('alex',18,'male')
s4=StudentPeople('lqz',28,'female') #查看共实例化多少次
print(StudentPeople.count)
统计实例化次数
五.类与类型
在python3.x中统一了类和类型的概念,即类就是类型!
且类的概念在之前的面向过程的编程方式中也有使用,并不是一个陌生的概念,只是当时并没有明确为类的概念。
下面的例子说明:
class Foo:
pass print(Foo)
obj=Foo()
print(obj,type(obj)) # print(list)
l1=[1,2,3] #l1=list([1,2,3])
print(l1.append)
l1.append(4)
print(l1)
#list.append(l1,4)
#print(l1) l2=['a','b','c'] #l2=list(['a','b','c'])
# l2.append('d')
# print(l2) list.append(l2,'d')
print(l2)
类和类型的概念
#1、在没有学习类这个概念时,数据与功能是分离的 host='127.0.0.1'
port=3306
db='db1'
charset='utf-8' #每次调用都需要重复传入一堆参数
exc1(host,port,db,charset,'select * from tb1;')
exc1(host,port,db,charset,'select * from tb1;')
exc1(host,port,db,charset,'select * from tb1;')
exc1(host,port,db,charset,'select * from tb1;')
exc2(host,port,db,charset,'存储过程的名字3') #2、基于面向对象的思想将数据与功能整合到一起
class Mysql:
def __init__(self,host,port,db,charset):
self.host=host
self.port=port
self.db=db
self.charset=charset def exc1(self,sql):
conn = connect(self.host, self.port, self.db, self.charset)
conn.execute(sql)
return xxx def exc2(self, proc_name)
conn = connect(self.host, self.port, self.db, self.charset)
conn.call_proc(proc_name)
return xxx obj=Mysql('1.1.1.1',3306,'db1','utf-8')
obj.exc1('select * from xxx')
obj.exc2('p1')
没有类的概念和面向对象概念对比
类即类型
提示:python的class术语与c++有一定区别,与 Modula-3更像。
python中一切皆为对象,且python3中类与类型是一个概念,类型就是类
六. 绑定到对象的方法的特殊之处
类中定义的函数(没有被任何装饰器装饰的)是类的函数属性,类可以使用,但必须遵循函数的参数规则,有几个参数需要传几个参数。
具体见如下实例:
#改写
class OldboyStudent:
school='oldboy'
def __init__(self,name,age,sex):
self.name=name
self.age=age
self.sex=sex
def learn(self):
print('%s is learning' %self.name) #新增self.name def eat(self):
print('%s is eating' %self.name) def sleep(self):
print('%s is sleeping' %self.name) s1=OldboyStudent('李坦克','男',18)
s2=OldboyStudent('王大炮','女',38)
s3=OldboyStudent('牛榴弹','男',78)
OldboyStudent.learn(s1) #李坦克 is learning
OldboyStudent.learn(s2) #王大炮 is learning
OldboyStudent.learn(s3) #牛榴弹 is learning
##必须遵循函数的参数规则,有几个参数需要传几个参数!!
类中定义的函数(没有被任何装饰器装饰的),其实主要是给对象使用的,而且是绑定到对象的,虽然所有对象指向的都是相同的功能,但是绑定到不同的对象就是不同的绑定方法
强调:绑定到对象的方法的特殊之处在于,绑定给谁就由谁来调用,谁来调用,就会将‘谁’本身当做第一个参数传给方法,即自动传值(方法__init__也是一样的道理)
s1.learn() #等同于OldboyStudent.learn(s1)
s2.learn() #等同于OldboyStudent.learn(s2)
s3.learn() #等同于OldboyStudent.learn(s3)
注意:绑定到对象的方法的这种自动传值的特征,决定了在类中定义的函数都要默认写一个参数self,self可以是任意名字,但是约定俗成地写出self。
七. 对象之间的交互
class Garen: #定义英雄盖伦的类,不同的玩家可以用它实例出自己英雄;
camp='Demacia' #所有玩家的英雄(盖伦)的阵营都是Demacia;
def __init__(self,nickname,aggressivity=58,life_value=455): #英雄的初始攻击力58...;
self.nickname=nickname #为自己的盖伦起个别名;
self.aggressivity=aggressivity #英雄都有自己的攻击力;
self.life_value=life_value #英雄都有自己的生命值; def attack(self,enemy): #普通攻击技能,enemy是敌人;
enemy.life_value-=self.aggressivity #根据自己的攻击力,攻击敌人就减掉敌人的生命值。 class Riven:
camp='Noxus' #所有玩家的英雄(锐雯)的阵营都是Noxus;
def __init__(self,nickname,aggressivity=54,life_value=414): #英雄的初始攻击力54;
self.nickname=nickname #为自己的锐雯起个别名;
self.aggressivity=aggressivity #英雄都有自己的攻击力;
self.life_value=life_value #英雄都有自己的生命值; def attack(self,enemy): #普通攻击技能,enemy是敌人;
enemy.life_value-=self.aggressivity #根据自己的攻击力,攻击敌人就减掉敌人的生命值。 g1=Garen('草丛伦')
r1=Riven('锐雯') print(g1.life_value) #
#锐雯 开始攻击草丛伦
r1.attack(g1) #再次查看g1的生命值
print(g1.life_value) #
补充:
garen_hero.Q()称为向garen_hero这个对象发送了一条消息,让他去执行Q这个功能,类似的有:
garen_hero.W()
garen_hero.E()
garen_hero.R()
八. 继承 与 派生
1.初识继承
*什么是继承?
继承一种新建类的方式,新建的类称为子类或者派生类,被继承的类称为父类或基类或超类
子类会遗传父类的一系列属性
python支持多继承!!
注意:
在python3中,如果没有显式地继承任何类,那默认继承object类
在python2中,如果没有显式地继承任何类,也不会继承object类
在python中类分为两种:
新式类:
但凡继承object的类,以及该类的子类都是新式类
在python3中所有的类都是新式类
经典类
没有继承object类,以该类的子类都是经典类
只有在python2中才存在经典类,为何?
因为在python2中没有没有显式地继承任何类,也不会继承object类
继承的原理(python如何实现的继承):
python到底是如何实现继承的,对于你定义的每一个类,python会计算出一个方法解析顺序(MRO)列表,这个MRO列表就是一个简单的所有基类的线性顺序列表,例如
>>> F.mro() #等同于F.__mro__
[<class '__main__.F'>, <class '__main__.D'>, <class '__main__.B'>, <class '__main__.E'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
mro()函数基于c3算法实现
为了实现继承,python会在MRO列表上从左到右开始查找基类,直到找到第一个匹配这个属性的类为止。
而这个MRO列表的构造是通过一个C3线性化算法来实现的。我们不去深究这个算法的数学原理,它实际上就是合并所有父类的MRO列表并遵循如下三条准则:
1.子类会先于父类被检查
2.多个父类会根据它们在列表中的顺序被检查
3.如果对下一个类存在两个合法的选择,选择第一个父类
*为什么要继承?
减少代码冗余
*如何用继承?
class People:
def __init__(self,name,age,sex):
self.name=name
self.age=age
self.sex=sex
def eat(self):
print('%s is eating'%self.name)
def sleep(self):
print('%s is sleeping'%self.name)
def work(self):
print('%s is working'%self.name)
class Man(People):
def piao(self): #自己的方法
print('%s is piao ...2s...done'%self.name)
def sleep(self): #和分类方法同名,会直接覆盖了父类的!
People.sleep(self) #重构了父类的方法!
print('子类man is sleep')
class Women(People):
def get_birth(self):
print('%s is born a baby...'%self.name)
m1=Man('egon',20,'male')
m1.sleep()
m1.piao()
w1=Women('chenronghua',29,'female')
w1.get_birth()
#w1.piao() #w1.piao() #women调用man独有的piao,无法调用!
创建使用继承关系1
2.子类重用父类中的属性和方法(派生)
#在子类派生的新方法中重用父类的功能
#1.方式一:通过指名到姓的访问某一类的函数,与继承是没有关系的。
#teacherPeople.__init__(self,name,age,sex)
class People:
def __init__(self,name,age,sex):
self.name=name
self.age=age
self.sex=sex class Teacher(People):
def __init__(self,name,age,sex,level):
#People.__init__(self,name,age,sex)
super(Teacher,self).__init__(name,age,sex)
self.level=level t1=Teacher('egno',18,'male','super teacher')
print(t1.level,t1.name)
#super teacher egno
子类重构父类功能1
#2.方式二:super(自己的类名,self).父类的方法名
#调用super会得到一个特殊的对象,该对象专门用来引用父类中的方法的
#具体的:该对象会严格按照当前类的 mro列表从当前类的父类中依次查找属性,所以这种方法是严格依赖于继承的!
强调:二者使用哪一种都可以,但最好不要混合使用 ! 了解部分:
即使没有直接继承关系,super仍然会按照mro继续往后查找!
#A没有继承B,但是A内super会基于C.mro()继续往后找
class A:
def test(self):
super().test()
class B:
def test(self):
print('from B')
class C(A,B):
pass c=C()
c.test() #打印结果:from B print(C.mro())
#[<class '__main__.C'>, <class '__main__.A'>, <class '__main__.B'>, <class 'object'>]
super会严格按照mro方法往后查找实例.
注意:super()和类.函数的调用方式的区别?
#指名道姓
class A:
def __init__(self):
print('A的构造方法')
class B(A):
def __init__(self):
print('B的构造方法')
A.__init__(self) class C(A):
def __init__(self):
print('C的构造方法')
A.__init__(self) class D(B,C):
def __init__(self):
print('D的构造方法')
B.__init__(self)
C.__init__(self) pass
f1=D() #A.__init__被重复调用
'''
D的构造方法
B的构造方法
A的构造方法
C的构造方法
A的构造方法
''' #使用super()
class A:
def __init__(self):
print('A的构造方法')
class B(A):
def __init__(self):
print('B的构造方法')
super(B,self).__init__() class C(A):
def __init__(self):
print('C的构造方法')
super(C,self).__init__() class D(B,C):
def __init__(self):
print('D的构造方法')
super(D,self).__init__() f1=D() #super()会基于mro列表,往后找
'''
D的构造方法
B的构造方法
C的构造方法
A的构造方法
'''
子类调用父类的2种方式的实例
当你使用super()函数时,Python会在MRO列表上继续搜索下一个类。只要每个重定义的方法统一使用super()并只调用它一次,那么控制流最终会遍历完整个MRO列表,每个方法也只会被调用一次(注意注意注意:使用super调用的所有属性,都是从MRO列表当前的位置往后找,千万不要通过看代码去找继承关系,一定要看MRO列表)
class A:
def f1(self):
print('A')
#self.f2() #A B
super().f2() #A B,super()是基于当前c1对象的类的mro进行查找的!!! def f2(self):
print('A--f2') class B:
def f2(self):
print('B-f2') class C(A,B):
pass c1=C()
c1.f1()
#A
#B
子类重构父类方法2
#Author http://www.cnblogs.com/Jame-mei #class People: #经典类
class People(object):#新式类
def __init__(self,name,age,sex):
self.name=name
self.age=age
self.sex=sex def eat(self):
print('%s is eating'%self.name) def sleep(self):
print('%s is sleeping'%self.name) def work(self):
print('%s is working'%self.name) class Man(People):
def __init__(self,name,age,sex,money): #添加子类自己的属性money,需要把父类所有参数写完!
#People.__init__(self,name,age,sex) #经典类,父类的构造函数
super(Man,self).__init__(name,age,sex) #新式类写法,和上面效果一样,写法不同!
self.money=money
print('%s 一出生就有 $%s'%(self.name,self.money)) def piao(self): #自己的方法
print('%s is piao ...2s...done'%self.name) def sleep(self): #和分类方法同名,会直接覆盖了父类的!
People.sleep(self) #重构了父类的方法!
print('子类man is sleep') class Women(People): def get_birth(self):
print('%s is born a baby...'%self.name) m1=Man('alex',18,'male','100w') #男生初始化多了1个参数
#alex 一出生就有 $100w w1=Women('hou',18,'female') #女生初始化依然是3个参数
w1.get_birth() #hou is born a baby.. 子类重构父类的方法和添加自己的属性2
子类重构父类的方法和添加自己的属性2
当然子类也可以添加自己新的属性或者在自己这里重新定义这些属性(不会影响到父类),需要注意的是,一旦重新定义了自己的属性且与父类重名,那么调用新增的属性时,就以自己为准了。
class Riven(Hero):
camp='Noxus'
def attack(self,enemy): #在自己这里定义新的attack,不再使用父类的attack,且不会影响父类
print('from riven')
def fly(self): #在自己这里定义新的
print('%s is flying' %self.nickname)
子类派生自己的方法1
3.多继承关系
单继承的属性查找“:对象自己-》对象的类-》父类-》父类。。。。
多继承的属性查找“:对象自己-》对象的类-》从左往右一个一个的分支找下去
#Author http://www.cnblogs.com/Jame-mei #class People: #经典类
class People(object):#新式类
def __init__(self,name,age,sex):
self.name=name
self.age=age
self.sex=sex def eat(self):
print('%s is eating'%self.name) def sleep(self):
print('%s is sleeping'%self.name) def work(self):
print('%s is working'%self.name) class Relation(object): def make_friends(self,obj):
print('%s is make friends with %s'%(self.name,obj.name)) class Man(People,Relation):
def __init__(self,name,age,sex,money):
#People.__init__(self,name,age,sex)
super(Man,self).__init__(name,age,sex)
self.money=money
#print('%s 一出生就有 $%s'%(self.name,self.money)) def piao(self): #自己的方法
print('%s is piao ...2s...done'%self.name) def sleep(self):
People.sleep(self)
print('子类man is sleep') class Women(People,Relation): def get_birth(self):
print('%s is born a baby...'%self.name) m1=Man('alex',28,'male','100w')
w1=Women('hou',18,'female',) #w1.name='称三炮' #名字变了 m1.make_friends(w1)
#alex is make friends with hou
多继承练习3
4.经典类和新式类的继承顺序
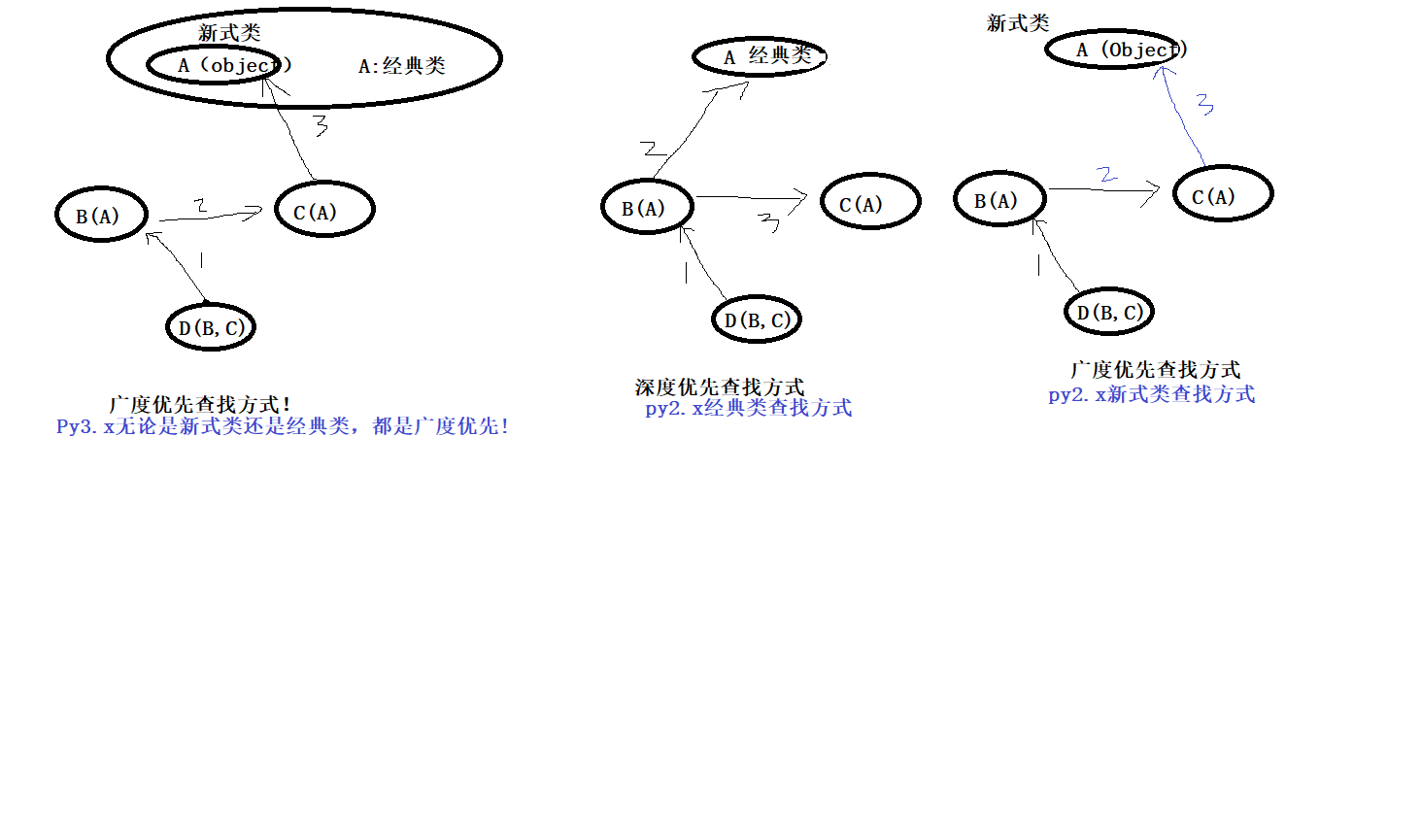
py2中遇到菱形的多继承关系时候,新式类是按照广度优先,经典类是按照深度优先。
py3中新式类和经典类多是按照广度优先的顺序!
Author http://www.cnblogs.com/Jame-mei #class A: #经典类
class A(object): #新式类
def __init__(self):
print('A init ......') class B(A):
pass
# def __init__(self):
# print('B init .....') class C(A):
def __init__(self):
print('C init .....') class D(B,C):
pass d1=D()
#C init ..... #python3.x无论新式类或者经典类都是按照广度优先,会先找C #A init ..... #python2.x经典类A()深度优先,会先找A; 新式类A(object),会按照广度优先,会先找C
实例:新式类和经典类的继承顺序
ps:如何查看类的继承关系查找的顺序呢?可在python3.x中,用类.mro()内置方法可查看!
所以python的mcro 内置方法的继承的实现原理 基于c3线性化的算法,把子类和父类的继承顺序记录到列表里,查找的时候从左到右依次查找,找到后则不继续往后查找!
5.组合的使用
软件重用的重要方式除了继承之外还有另外一种方式,即:组合
1、什么是组合
对象的属性的值是来自于另外一个类的对象,这就叫类的组合使用
2、为何要用组合
组合是用来减少类与类代码冗余的
组合vs继承?
只有在类与类之间有从属的关系的时候才能用继承
否则的话用组合
3、如何用组合
class People():
def __init__(self,name,password,age):
self.name=name
self.password=password
self.age=age class Student(People):
def __init__(self,name,password,age,stuid):
#People.__init__(self,name,password,age)
#super(Student,self).__init__(name,password,age)
super().__init__(name,password,age)
self.stuid=stuid
self.course=[] def study(self):
print('%s is study...'%self.name) class Course:
def __init__(self,name,price,period):
self.name=name
self.price=price
self.period=period def course_info(self):
print('''
course_name:%s,
price:%s,
period:%s
'''%(self.name,self.price,self.period)) python=Course('python',8999,'6months')
linux=Course('linux',7999,'6months') stu1=Student('jame','',27,'')
stu1.course.append(python) #这里把Course类的对象,当作Student类的属性添加,叫组合!!
stu1.course.append(linux) #print(stu1.course)
#查看学生学的每门课的信息
for course in stu1.course:
course.course_info()
类与类的组合1
4.组合与继承在何时使用?
组合与继承都是有效地利用已有类的资源的重要方式。但是二者的概念和使用场景皆不同,
1.继承的方式
通过继承建立了派生类与基类之间的关系,它是一种'是'的关系,比如白马是马,人是动物。
当类之间有很多相同的功能,提取这些共同的功能做成基类,用继承比较好,比如老师是人,学生是人
2.组合的方式
用组合的方式建立了类与组合的类之间的关系,它是一种‘有’的关系,比如教授有生日,教授教python和linux课程,教授有学生s1、s2、s3...
当类之间有显著不同,并且较小的类是较大的类所需要的组件时,用组合比较好
九. 多态与多态性
1.多态初识
*.什么是多态?
同一种事物的多种形态(例如:水 冰 蒸汽)
*.为何要用多态?
多态性:指的是可以在不用考虑对象具体类型的前提下,直接调用对象的方法 *.如何用多态?
#多态
class Animal:
def talk(self):
print('Animal talk...') class People(Animal):
def talk(self):
print('say hello') class Dog(People):
def talk(self):
print('汪汪汪') class Pig(People):
def talk(self):
print('哼哼哼') #上面基于继承的people,dog,pig都具有继承与父类的talk,但是每个的talk内容基于各自又有不同的实现,这叫多态! peo=People()
d1=Dog()
p1=Pig() #多态性
peo.talk()
d1.talk()
p1.talk()
'''
say hello
汪汪汪
哼哼哼
'''
多态练习1
import abc #多态
class Animal(metaclass=abc.ABCMeta): #抽象基类,不能被实例化。
@abc.abstractclassmethod #子类要强制遵循该方法 不然会报TypeError: Can't instantiate abstract class People with abstract methods talk
def talk(self):
print('Animal talk...') class People(Animal):
def talk(self):
print('say hello') class Dog(People):
def talk(self):
print('汪汪汪') class Pig(People):
def talk(self):
print('哼哼哼') #上面基于继承的people,dog,pig都具有继承与父类的talk,但是每个的talk内容基于各自又有不同的实现,这叫多态! peo1=People()
d1=Dog()
p1=Pig() #多态性
p1.talk()
d1.talk()
p1.talk()
'''
say hello
汪汪汪
哼哼哼
'''
抽象基类的强制子类使用2
*Python推崇的鸭子类型
#python 推崇的是鸭子类型:只要你长得像鸭子,你就是鸭子。
#所以下面,我有必要关心他是人叫,还是狗叫,还是猪叫吗,只用该对象调用talk的方法就可以实现多态的特性。而不用继承!
# class Animal:
# def talk(self):
# print('Animal talk...')
#
# class People:
# def talk(self):
# print('say hello')
# class Dog:
# def talk(self):
# print('汪汪汪')
# class Pig:
# def talk(self):
# print('哼哼哼')
#
#
#
# peo1=People()
# d1=Dog()
# p1=Pig()
#
#
#
# p1.talk()
# d1.talk()
# p1.talk()
鸭子类型实例1
# 例如:Linux中一切皆对象的概念,也能体现多态的用法。
'''
下面三个类都没有直接去继承某个父类的关系,但是三个都有一个长的一样的方法,
只要调用read(),write()就可以实现多态的特征,而不用去考虑这三个哪个是文件什么的。
'''
class Disk:
def read(self):
print('disk read')
def write(self):
print('disk write') class Process:
def read(self):
print('process read')
def write(self):
print('process write') class Memory:
def read(self):
print('memory read') def write(self):
print('memory write') disk1=Disk()
proc1=Process()
mem1=Memory() disk1.read()
proc1.read()
mem1.read()
'''
disk read
process read
memory read
'''
鸭子类型实例2
十. 封装
1 什么是封装?
装就是将数据属性或者函数属性存放到一个名称空间里
封指的是隐藏,该隐藏是为了明确地区分内外,即该隐藏是对外不对内(在类外部无法直接访问隐藏的属性,而在类内部是可以访问)
2 为何要封装?
1. 封数据属性:??? 通过内部接口修改
2. 封函数属性:??? 隔离复杂度
所以: 封装的真实意图:把数据属性或函数属性装起来就是为了以后使用的,封起来即藏起来是为不让外部直接使用
# 1.封数据属性:把数据属性藏起来,是为了不让外部直接操作隐藏的属性,而通过类内开辟的接口来间接地操作属性,
我们可以在接口之上附加任意的控制逻辑来严格控制使用者对属性的操作。
# @Time : 2018/8/20 13:25
# @Author : Jame class People:
def __init__(self, name, age):
self.__name = name
self.__age = age def tell_info(self):
print('<name:%s age:%s>' % (self.__name, self.__age)) def set_info(self, name, age):
if type(name) is not str:
print('名字必须是str类型')
return
if type(age) is not int:
print('年龄必须是int类型')
return self.__name = name
self.__age = age obj = People('egon', 18) #1查看
#obj.tell_info() #2修改
#obj.set_info('EGON',19)
#obj.tell_info()
数据属性封装实例
#2.封函数属性: 隔离复杂度
class ATM:
def __card(self):
print('插卡')
def __auth(self):
print('用户认证')
def __input(self):
print('输入取款金额')
def __print_bill(self):
print('打印账单')
def __take_money(self):
print('取款') def withdraw(self):
self.__card()
self.__auth()
self.__input()
self.__print_bill()
self.__take_money() a=ATM()
a.withdraw()
函数属性封装实例
#3 在继承中,父类如果不想让子类覆盖自己的方法,可以在该方法前加__开头。
class Foo:
def __f1(self): #_Foo__f1
print('Foo.f1') def f2(self):
print('Foo.f2')
self.__f1() #self._Foo__f1() class Bar(Foo):
def __f1(self):#_Bar__f1
print('Bar.f1') b1=Bar()
b1.f2()
#Foo.f2
#Foo.f1
父类防止子类覆盖实例
3 如何封装???
在类内定义的属性前加__开头,例如如下实例:
class People:
__country='China'
__n=111 def __init__(self,name):
self.__name=name
#self._People__name=name def run(self):
print('%s:%s is running'%(self.__country,self.__name)) #print(People.__n) #AttributeError: type object 'People' has no attribute '__n'
peo1=People('jame')
peo1.run() #China:jame is running print(peo1.__dict__) #{'_People__name': 'jame'}
print(peo1._People__name) #jame peo1.__age=20
print(peo1.__age) # # 总结这种隐藏需要注意的问题:
# 1. 这种隐藏只是一种语法上的变形,并没有真的限制访问
# 2. 这种变形只在类定义阶段检测语法时变形一次,类定义阶段之后新增的__开头的属性不会发生变形!
4.property 装饰器的使用
property 是一个可以将类中的函数属性,在对象调用的时候伪装成数据属性的方式来调用。
'''
成人的BMI数值:
过轻:低于18.5
正常:18.5-23.9
过重:24-27
肥胖:28-32
非常肥胖,高于32 体质指数(BMI)=体重(kg)/身高^2(m)
ex:70kg/(1.7*1.7) ''' class People:
def __init__(self,name,weight,height):
self.name=name
self.weight=weight
self.height=height @property
def bim(self):
return self.weight/(self.height **2) obj=People('jame',67,1.7)
print(obj.bim)
BMI例子1
property其他使用方法:了解。
class People:
def __init__(self,name):
self.__name=name @property
def name(self):
return self.__name @name.setter
def name(self,obj):
if type(obj) is not str:
print('name is must be str')
return
self.__name=obj @name.deleter
def name(self):
print('name not delete')
#del self.__name obj=People('jame')
#1 查看
print(obj.name) #2 修改
obj.name='tom'
print(obj.name) #3 删除
del obj.name
#name not delete
property其他实例
class People:
def __init__(self,name,age):
self.__name=name
self.age=age def get_name(self):
return self.__name def set_name(self,obj):
if type(obj) is not str:
print('name is must be str')
return
self.__name=obj def del_name(self):
del self.__name obj=People('jame',18)
#print(obj.name) #AttributeError: 'People' object has no attribute 'name' #1 查看
print(obj.get_name()) #jame #2 修改
obj.set_name('tom')
print(obj.get_name()) #tom #3 删除
obj.del_name()
print(obj.__dict__) #{'age': 18}
不用property来实现
十 一.绑定方法与非绑定方法
类中定义的函数有两大类(3小种)用途,一类是绑定方法,另外一类是非绑定方法。
1. 绑定方法:
特点:绑定给谁就应该由谁来调用,谁来调用就会将谁当作第一个参数自动传入
1.1 绑定给对象的:类中定义的函数默认就是绑定对象的
1.2 绑定给类的:在类中定义的函数上加一个装饰器classmethod
2. 非绑定方法
特点: 既不与类绑定也不与对象绑定,意味着对象或者类都可以调用。
但无论谁来调用都是一个普通函数,根本没有自动传值一说
3.如何区分绑定方法和非绑定方法?
class Foo:
def func1(self):
print('绑定给对象的方法',self) @classmethod
def func2(cls):
print('绑定给类的方法.',cls) @staticmethod
def func3():
print('普通函数,既不与类绑定 也不与 对象绑定.') obj=Foo() #绑定方法
obj.func1() #<__main__.Foo object at 0x00000000028C65C0>
print(obj.func1) #<bound method Foo.func1 of <__main__.Foo object at 0x00000000026C65C0>> Foo.func2() #<class '__main__.Foo'>
print(Foo.func2) #<bound method Foo.func2 of <class '__main__.Foo'>> #非绑定方法
#obj.func3()
#Foo.func3()
绑定方法和非绑定方法实例1
十二.python中关于OOP的常用术语
*抽象/实现
抽象指对现实世界问题和实体的本质表现,行为和特征建模,建立一个相关的子集,可以用于 绘程序结构,从而实现这种模型。抽象不仅包括这种模型的数据属性,还定义了这些数据的接口。
对某种抽象的实现就是对此数据及与之相关接口的现实化(realization)。现实化这个过程对于客户 程序应当是透明而且无关的。
*封装/接口
封装描述了对数据/信息进行隐藏的观念,它对数据属性提供接口和访问函数。通过任何客户端直接对数据的访问,无视接口,与封装性都是背道而驰的,除非程序员允许这些操作。作为实现的 一部分,客户端根本就不需要知道在封装之后,数据属性是如何组织的。在Python中,所有的类属性都是公开的,但名字可能被“混淆”了,以阻止未经授权的访问,但仅此而已,再没有其他预防措施了。这就需要在设计时,对数据提供相应的接口,以免客户程序通过不规范的操作来存取封装的数据属性。
注意:封装绝不是等于“把不想让别人看到、以后可能修改的东西用private隐藏起来”
真正的封装是,经过深入的思考,做出良好的抽象,给出“完整且最小”的接口,并使得内部细节可以对外透明
(注意:对外透明的意思是,外部调用者可以顺利的得到自己想要的任何功能,完全意识不到内部细节的存在)
*合成
合成扩充了对类的 述,使得多个不同的类合成为一个大的类,来解决现实问题。合成 述了 一个异常复杂的系统,比如一个类由其它类组成,更小的组件也可能是其它的类,数据属性及行为, 所有这些合在一起,彼此是“有一个”的关系。
*派生/继承/继承结构
派生描述了子类衍生出新的特性,新类保留已存类类型中所有需要的数据和行为,但允许修改或者其它的自定义操作,都不会修改原类的定义。
继承描述了子类属性从祖先类继承这样一种方式
继承结构表示多“代”派生,可以述成一个“族谱”,连续的子类,与祖先类都有关系。
*泛化/特化
基于继承
泛化表示所有子类与其父类及祖先类有一样的特点。
特化描述所有子类的自定义,也就是,什么属性让它与其祖先类不同。
*多态与多态性
多态指的是同一种事物的多种状态:水这种事物有多种不同的状态:冰,水蒸气
多态性的概念指出了对象如何通过他们共同的属性和动作来操作及访问,而不需考虑他们具体的类。
冰,水蒸气,都继承于水,它们都有一个同名的方法就是变成云,但是冰.变云(),与水蒸气.变云()是截然不同的过程,虽然调用的方法都一样
*自省/反射
自省也称作反射,这个性质展示了某对象是如何在运行期取得自身信息的。如果传一个对象给你,你可以查出它有什么能力,这是一项强大的特性。如果Python不支持某种形式的自省功能,dir和type内建函数,将很难正常工作。还有那些特殊属性,像__dict__,__name__及__doc__
十三.面向对象的软件开发工程
很多人在学完了python的class机制之后,遇到一个生产中的问题,还是会懵逼,这其实太正常了,因为任何程序的开发都是先设计后编程,python的class机制只不过是一种编程方式,如果你硬要拿着class去和你的问题死磕,变得更加懵逼都是分分钟的事,在以前,软件的开发相对简单,从任务的分析到编写程序,再到程序的调试,可以由一个人或一个小组去完成。但是随着软件规模的迅速增大,软件任意面临的问题十分复杂,需要考虑的因素太多,在一个软件中所产生的错误和隐藏的错误、未知的错误可能达到惊人的程度,这也不是在设计阶段就完全解决的。
所以软件的开发其实一整套规范,我们所学的只是其中的一小部分,一个完整的开发过程,需要明确每个阶段的任务,在保证一个阶段正确的前提下再进行下一个阶段的工作,称之为软件工程
面向对象的软件工程包括下面几个部:
1.面向对象分析(object oriented analysis ,OOA)
软件工程中的系统分析阶段,要求分析员和用户结合在一起,对用户的需求做出精确的分析和明确的表述,从大的方面解析软件系统应该做什么,而不是怎么去做。面向对象的分析要按照面向对象的概念和方法,在对任务的分析中,从客观存在的事物和事物之间的关系,贵南出有关的对象(对象的‘特征’和‘技能’)以及对象之间的联系,并将具有相同属性和行为的对象用一个类class来标识。
建立一个能反映这是工作情况的需求模型,此时的模型是粗略的。
2 面向对象设计(object oriented design,OOD)
根据面向对象分析阶段形成的需求模型,对每一部分分别进行具体的设计。
首先是类的设计,类的设计可能包含多个层次(利用继承与派生机制)。然后以这些类为基础提出程序设计的思路和方法,包括对算法的设计。
在设计阶段并不牵涉任何一门具体的计算机语言,而是用一种更通用的描述工具(如伪代码或流程图)来描述
3 面向对象编程(object oriented programming,OOP)
根据面向对象设计的结果,选择一种计算机语言把它写成程序,可以是python
4 面向对象测试(object oriented test,OOT)
在写好程序后交给用户使用前,必须对程序进行严格的测试,测试的目的是发现程序中的错误并修正它。
面向对的测试是用面向对象的方法进行测试,以类作为测试的基本单元。
5 面向对象维护(object oriendted soft maintenance,OOSM)
正如对任何产品都需要进行售后服务和维护一样,软件在使用时也会出现一些问题,或者软件商想改进软件的性能,这就需要修改程序。
由于使用了面向对象的方法开发程序,使用程序的维护比较容易。
因为对象的封装性,修改一个对象对其他的对象影响很小,利用面向对象的方法维护程序,大大提高了软件维护的效率,可扩展性高。
在面向对象方法中,最早发展的肯定是面向对象编程(OOP),那时OOA和OOD都还没有发展起来,因此程序设计者为了写出面向对象的程序,还必须深入到分析和设计领域,尤其是设计领域,那时的OOP实际上包含了现在的OOD和OOP两个阶段,这对程序设计者要求比较高,许多人感到很难掌握。
现在设计一个大的软件,是严格按照面向对象软件工程的5个阶段进行的,这个5个阶段的工作不是由一个人从头到尾完成的,而是由不同的人分别完成,这样OOP阶段的任务就比较简单了。程序编写者只需要根据OOd提出的思路,用面向对象语言编写出程序既可。
十四.练习,面向对象实战(选课系统)
1.练习(基于面向对象设计一个对战游戏)
1.1定义锐雯类:
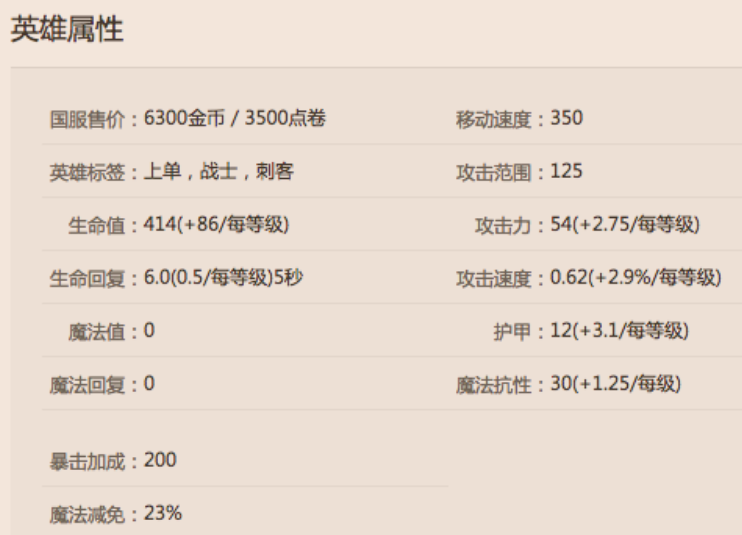
class Riven:
camp='Noxus'
def __init__(self,nickname,
aggressivity=54,
life_value=414,
money=1001,
armor=3):
self.nickname=nickname
self.aggressivity=aggressivity
self.life_value=life_value
self.money=money
self.armor=armor
def attack(self,enemy):
damage_value=self.aggressivity-enemy.armor
enemy.life_value-=damage_value
Riven类定义
1.2定义盖文类:
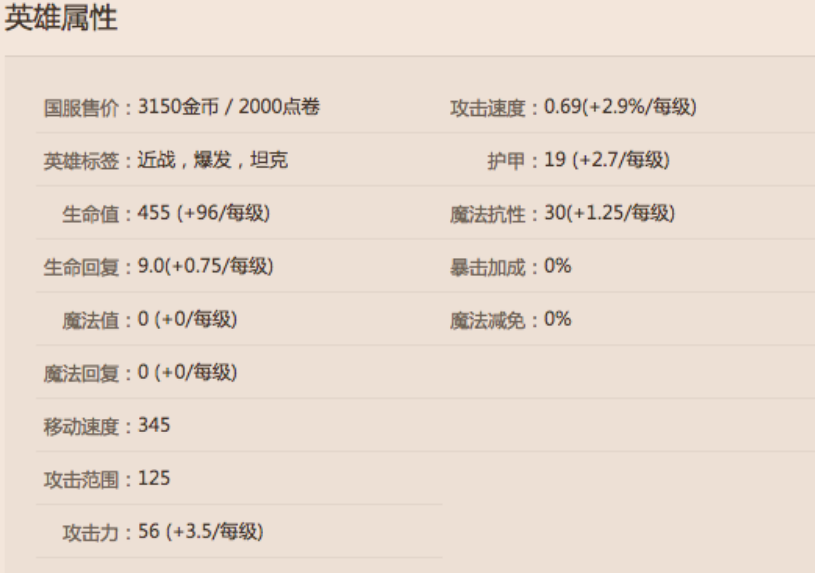
class Garen:
camp='Demacia'
def __init__(self,nickname,
aggressivity=58,
life_value=455,
money=100,
armor=10):
self.nickname=nickname
self.aggressivity=aggressivity
self.life_value=life_value
self.money=money
self.armor=armor
def attack(self,enemy):
damage_value=self.aggressivity-enemy.armor
enemy.life_value-=damage_value
定义Garen
1.3定义装备:

class BlackCleaver:
def __init__(self,price=475,aggrev=9,life_value=100):
self.price=price
self.aggrev=aggrev
self.life_value=life_value
def update(self,obj):
obj.money-=self.price #减钱
obj.aggressivity+=self.aggrev #加攻击
obj.life_value+=self.life_value #加生命值
def fire(self,obj): #这是该装备的主动技能,喷火,烧死对方
obj.life_value-=1000 #假设火烧的攻击力是1000
定义装备类
1.4测试交互:
r1=Riven('草丛伦')
g1=Garen('盖文')
b1=BlackCleaver()
print(r1.aggressivity,r1.life_value,r1.money) #r1的攻击力,生命值,护甲
if r1.money > b1.price:
r1.b1=b1
b1.update(r1)
print(r1.aggressivity,r1.life_value,r1.money) #r1的攻击力,生命值,护甲
print(g1.life_value)
r1.attack(g1) #普通攻击
print(g1.life_value)
r1.b1.fire(g1) #用装备攻击
print(g1.life_value) #g1的生命值小于0就死了
测试交互
2.面向对象实战
角色:学校、学员、课程、讲师
要求:
1. 创建北京、上海 2 所学校
2. 创建linux , python , go 3个课程 , linux\py 在北京开, go 在上海开
3. 课程包含,周期,价格,通过学校创建课程
4. 通过学校创建班级, 班级关联课程、讲师
5. 创建学员时,选择学校,关联班级
5. 创建讲师角色时要关联学校,
6. 提供两个角色接口
6.1 学员视图, 可以注册, 交学费, 选择班级,
6.2 讲师视图, 讲师可管理自己的班级, 上课时选择班级, 查看班级学员列表 , 修改所管理的学员的成绩
6.3 管理视图,创建讲师, 创建班级,创建课程
7. 上面的操作产生的数据都通过pickle序列化保存到文件里
ps:面向对象开发设计流程:http://www.cnblogs.com/linhaifeng/articles/7341318.html
#作业完成地址:https://gitee.com/meijinmeng/choose_course_system.git
Python基础-week06 面向对象编程基础的更多相关文章
- Python基础-week06 面向对象编程进阶
一.反射 1.定义:指的是通过字符串来操作类或者对象的属性 2.为什么用反射? 减少冗余代码,提升代码质量. 3.如何用反射? class People: country='China' def __ ...
- [.net 面向对象编程基础] (1) 开篇
[.net 面向对象编程基础] (1)开篇 使用.net进行面向对象编程也有好长一段时间了,整天都忙于赶项目,完成项目任务之中.最近偶有闲暇,看了项目组中的同学写的代码,感慨颇深.感觉除了定义个类,就 ...
- Python 面向对象编程基础
Python 面向对象编程基础 虽然Pthon是解释性语言,但是Pthon可以进行面向对象开发,小到 脚本程序,大到3D游戏,Python都可以做到. 一类: 语法: class 类名: 类属性,方法 ...
- Python基础 — 面向对象编程基础
目录 1. 面向对象编程基础 2. 定义类和创建对象 3. init() 方法 4. 魔法方法 5. 访问可见性问题 5. 练习 1. 面向对象编程基础 把一组数据结构和处理它们的方法组成对象(obj ...
- Python学习-第三天-面向对象编程基础
Python学习-第三天-面向对象编程基础 类和对象 简单的说,类是对象的蓝图和模板,而对象是类的实例.这个解释虽然有点像用概念在解释概念,但是从这句话我们至少可以看出,类是抽象的概念,而对象是具体的 ...
- day23面向对象编程基础
面向对象编程基础1.面向过程的编程思想 核心过程二字,过程指的是解决问题的步骤,即先干什么\再干什么\后干什么 基于该思想编写程序就好比在设计一条流水线,是一种机械式的思维方式 优点 ...
- 第二章 Matlab面向对象编程基础
DeepLab是一款基于Matlab面向对象编程的深度学习工具箱,所以了解Matlab面向对象编程的特点是必要的.笔者在做Matlab面向对象编程的时候发现无论是互联网上还是书店里卖的各式Matlab ...
- [Java入门笔记] 面向对象编程基础(二):方法详解
什么是方法? 简介 在上一篇的blog中,我们知道了方法是类中的一个组成部分,是类或对象的行为特征的抽象. 无论是从语法和功能上来看,方法都有点类似与函数.但是,方法与传统的函数还是有着不同之处: 在 ...
- [.net 面向对象编程基础] (2) 关于面向对象编程
[.net 面向对象编程基础] (2) 关于面向对象编程 首先是,面向对象编程英文 Object-Oriented Programming 简称 OOP 通俗来说,就是 针对对象编程的意思 那么问 ...
随机推荐
- Linux常用命令-1
内部命令:属于Shell解释器的一部分(已调入内存) 外部命令:独立于Shell解释器之外的程序文件(在磁盘上) 获得命令帮助 1)内部命令help 查看Bash内部命令的帮助信息 2)命令的“--h ...
- linux 命令——45 free(转)
free命令可以显示Linux系统中空闲的.已用的物理内存及swap内存,及被内核使用的buffer.在Linux系统监控的工具中,free命令是最经常使用的命令之一. 1.命令格式: free [参 ...
- IOS 强指针(strong)和弱指针(weak)
// strong 强指针 // weak 弱指针 // ARC, 只要对象没有强指针就会自动释放 // OC中默认都是强指针
- MVC文件下载和webform也能使用的下载方法
public ActionResult Index() { DownloadMethod("text/plain", "C:/Users/sunny/Pictures/S ...
- POJ-1936 All in All---字符串水题
题目链接: https://vjudge.net/problem/POJ-1936 题目大意: 给两个字符串,判断是s1是不是s2的子序列 思路: 水 #include<iostream> ...
- Angular4中常用管道
通常我们需要使用管道实现对数据的格式化,Angular4中的管道和之前有了一些变化,下面说一些常用的管道. 一.大小写转换管道 uppercase将字符串转换为大写 lowercase将字符串转换为小 ...
- Dropout & Maxout
[ML] My Journal from Neural Network to Deep Learning: A Brief Introduction to Deep Learning. Part. E ...
- django项目实现第三方github登录
OAuth(开放授权 Open Authorization)是一个开放标准,允许用户授权第三方网站访问他们存储在另外的服务提供者上的信息,而不需要将用户名和密码提供给第三方网站或分享他们数据的所有内容 ...
- 【前端_js】js中数字字符串之间的比较
js中字符串间的比较是按照位次优先,比较各字符的ASCII大小,包括数字字符串之间的比较. 1.console.log("1"<"3");//true 2 ...
- Linux系统kernel参数优化
目录 iptables相关 单进程最大打开文件数限制 内核TCP参数方面 内核其他TCP参数说明 众所周知在默认参数情况下Linux对高并发支持并不好,主要受限于单进程最大打开文件数限制.内核TCP参 ...