SQL Server 致程序员(容易忽略的错误)
一、概述
因为每天需要审核程序员发布的SQL语句,所以收集了一些程序员的一些常见问题,还有一些平时收集的其它一些问题,这也是很多人容易忽视的问题,在以后收集到的问题会补充在文章末尾,欢迎关注,由于收集的问题很多是针对于生产数据,测试且数据量比较大,这里就不把数据共享出来了,大家理解意思就行。
二、概念
1.大小写
大写T-SQL 语言的所有关键字都使用大写,规范要求。
2.使用“;”
使用“;”作为 Transact-SQL 语句终止符。虽然分号不是必需的,但使用它是一种好的习惯,对于合并操作MERGE语句的末尾就必须要加上“;”
(cte表表达式除外)
3.数据类型
避免使用ntext、text 和 image 数据类型,用 nvarchar(max)、varchar(max) 和 varbinary(max)替代
后续版本会取消ntext、text 和 image 该三种类型
4.查询条件不要使用计算列
例如year(createdate)=2014,使用createdate>=’ 20140101’ and createdate<=’ 20141231’来取代。
IF OBJECT_ID('News','U') IS NOT NULL DROP TABLE News
GO
CREATE TABLE News
(ID INT NOT NULL PRIMARY KEY IDENTITY(1,1),
NAME NVARCHAR(100) NOT NULL,
Createdate DATETIME NOT NULL
)
GO
CREATE NONCLUSTERED INDEX [IX1_News] ON [dbo].[News]
(
[Createdate] ASC
)
INCLUDE ( [NAME]) WITH (STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
GO
INSERT INTO News(NAME,Createdate)
VALUES( '新闻','2014-08-20 00:00:00'),( '新闻','2014-08-20 00:00:00'),( '新闻','2014-08-20 00:00:00'),( '新闻','2014-08-20 00:00:00')
---使用计算列查询(走的是索引扫描)
SELECT ID,NAME,Createdate FROM News
WHERE YEAR(Createdate)=2014

---不使用计算列(走的是索引查找)
SELECT ID,NAME,Createdate FROM News
WHERE CreateDate>='2014-01-01 00:00:00' and CreateDate<'2015-01-01 00:00:00'

对比两个查询显然绝大部分情况下走索引查找的查询性能要高于走索引扫描,特别是查询的数据库不是非常大的情况下,索引查找的消耗时间要远远少于索引扫描的时间,如果想详细了解索引的体系结构可以查看了我前面写的几篇关于聚集、非聚集、堆的索引体系机构的文章。

请参看:http://www.cnblogs.com/chenmh/p/3780221.html
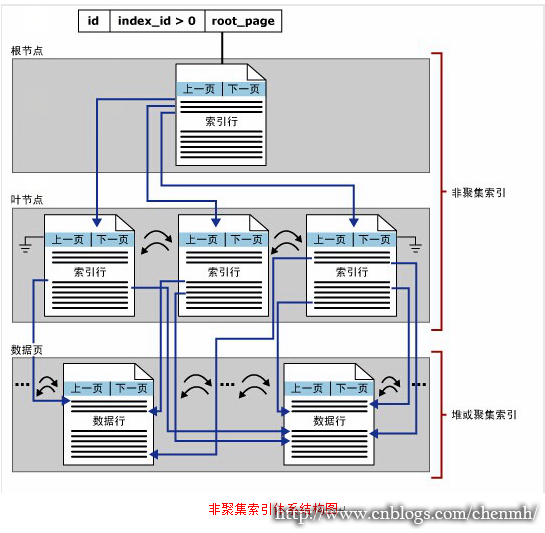
请参看:http://www.cnblogs.com/chenmh/p/3782397.html
5.建表时字段不允许为null
发现很多人在建表的时候不会注意这一点,在接下来的工作中当你需要查询数据的时候你往往需要在WHERE条件中多加一个判断条件IS NOT NULL,这样的一个条件不仅仅增加了额外的开销,而且对查询的性能产生很大的影响,有可能就因为多了这个查询条件导致你的查询变的非常的慢;还有一个比较重要的问题就是允许为空的数据可能会导致你的查询结果出现不准确的问题,接下来我们就举个例子讨论一下。
T-SQL是三值逻辑(true,flase,unknown)
IF OBJECT_ID('DBO.Customer','U') IS NOT NULL DROP TABLE DBO.Customer
GO
CREATE TABLE DBO.Customer
(Customerid int not null );
GO
IF OBJECT_ID('DBO.OrderS','U') IS NOT NULL DROP TABLE DBO.OrderS
GO
CREATE TABLE DBO.OrderS
(Orderid int not null,
custid int);
GO
INSERT INTO Customer VALUES(1),(2),(3);
INSERT INTO OrderS VALUES(1,1),(2,2),(3,NULL); ----查询没有订单的顾客
SELECT Customerid FROM DBO.Customer WHERE Customerid NOT IN(SELECT custid FROM OrderS); ---分析为什么查询结果没有数据
/*
因为true,flase,unknown都是真值
因为not in 是需要结果中返回flase值,not true=flase,not flase=flase,not unknown=unknown
因为null值是unknown所以not unknownn无法判断结果是什么值所以不能返回数据
*/ --可以将查询语句修改为
SELECT Customerid FROM DBO.Customer WHERE Customerid NOT IN(SELECT custid FROM OrderS WHERE custid is not null);
--或者使用EXISTS,因为EXISTS是二值逻辑只有(true,flase)所以不存在未知。
SELECT Customerid FROM DBO.Customer A WHERE NOT EXISTS(SELECT custid FROM OrderS WHERE OrderS.custid=A.Customerid ); ---in查询可以返回值,因为in是true,子查询true,flase,unknown都是真值所以可以返回子查询的true
SELECT Customerid FROM DBO.Customer WHERE Customerid IN(SELECT custid FROM OrderS); ----如果整形字段可以赋0,字符型可以赋值空(这里只是给建议)这里的空和NULL是不一样的意思
--增加整形字段可以这样写
ALTER TABLE TABLE_NAME ADD COLUMN_NAME INT NOT NULL DEFAULT(0) --增加字符型字段可以这样写
ALTER TABLE TABLE_NAME ADD COLUMN_NAME NVARCHAR(50) NOT NULL DEFAULT('')
6.分组统计时避免使用count(*)
IF OBJECT_ID('DBO.Customer','U') IS NOT NULL DROP TABLE DBO.Customer
GO
CREATE TABLE DBO.Customer
(Customerid int not null );
GO
IF OBJECT_ID('DBO.OrderS','U') IS NOT NULL DROP TABLE DBO.OrderS
GO
CREATE TABLE DBO.OrderS
(Orderid int not null,
custid int);
GO
INSERT INTO Customer VALUES(1),(2),(3);
INSERT INTO OrderS VALUES(1,1),(2,2),(3,NULL);
例如:需要统计每一个顾客的订单数量
---如果使用count(*)
SELECT Customerid,COUNT(*) FROM Customer TA LEFT JOIN OrderS TB ON TA.Customerid=TB.custid
GROUP BY Customerid ;

实际情况customerid=3是没有订单的,数量应该是0,但是结果是1,count()里面的字段是左连接右边的表字段,如果你用的是主表字段结果页是错误的。
----正确的方法是使用count(custid)
SELECT Customerid,COUNT(custid) FROM Customer TA LEFT JOIN OrderS TB ON TA.Customerid=TB.custid
GROUP BY Customerid;

7.子查询的表加上表别名
IF OBJECT_ID('DBO.Customer','U') IS NOT NULL DROP TABLE DBO.Customer
GO
CREATE TABLE DBO.Customer
(Customerid int not null );
GO
IF OBJECT_ID('DBO.OrderS','U') IS NOT NULL DROP TABLE DBO.OrderS
GO
CREATE TABLE DBO.OrderS
(Orderid int not null,
custid int);
GO
INSERT INTO Customer VALUES(1),(2),(3);
INSERT INTO OrderS VALUES(1,1),(2,2),(3,NULL);
大家发现下面语句有没有什么问题,查询结果是怎样呢?
SELECT Customerid FROM Customer WHERE Customerid IN(SELECT Customerid FROM OrderS WHERE Orderid=2 );

正确查询结果下查询出的结果是没有customerid为3的值
为什么结果会这样呢?
大家仔细看应该会发现子查询的orders表中没有Customerid字段,所以SQL取的是Customer表的Customerid值作为相关子查询的匹配字段。
所以我们应该给子查询加上表别名,如果加上表别名,如果字段错误的话会有错误标示
正确的写法:
SELECT Customerid FROM Customer WHERE Customerid IN(SELECT tb.custid FROM OrderS tb WHERE Orderid=2 );
8.建立自增列时单独再给自增列添加唯一约束
USE tempdb
CREATE TABLE TEST
(ID INT NOT NULL IDENTITY(1,1),
orderdate date NOT NULL DEFAULT(CURRENT_TIMESTAMP),
NAME NVARCHAR(30) NOT NULL,
CONSTRAINT CK_TEST_NAME CHECK(NAME LIKE '[A-Za-z]%' )
); GO
INSERT INTO tempdb.DBO.TEST(NAME)
VALUES('A中'),('a名'),('Aa'),('ab'),('AA'),('az'); ----4.插入报错后,自增值依旧增加
INSERT INTO tempdb.DBO.TEST(NAME)
VALUES('中');
GO
SELECT IDENT_CURRENT('tempdb.DBO.TEST');
SELECT * FROM tempdb.DBO.TEST; ---插入正常的数据
INSERT INTO tempdb.DBO.TEST(NAME)
VALUES('cc'); SELECT IDENT_CURRENT('tempdb.DBO.TEST')
SELECT * FROM tempdb.DBO.TEST; ----5.显示插入自增值
SET IDENTITY_INSERT tempdb.DBO.TEST ON INSERT INTO tempdb.DBO.TEST(ID,NAME)
VALUES(8,'A中'); SET IDENTITY_INSERT tempdb.DBO.TEST OFF ----会发现ID并不是根据自增值排列的,而且根据插入的顺序排列的
SELECT IDENT_CURRENT('tempdb.DBO.TEST');
SELECT * FROM tempdb.DBO.TEST; ----6.插入重复的自增值
SET IDENTITY_INSERT tempdb.DBO.TEST ON INSERT INTO tempdb.DBO.TEST(ID,NAME)
VALUES(8,'A中'); SET IDENTITY_INSERT tempdb.DBO.TEST OFF SELECT IDENT_CURRENT('tempdb.DBO.TEST')
SELECT * FROM tempdb.DBO.TEST;
---所以如果要保证ID是唯一的,单单只设置自增值不行,需要给字段设置主键或者唯一约束
DROP TABLE tempdb.DBO.TEST;
9.查询时一定要制定字段查询
l 查询时一定不能使用”*”来代替字段来进行查询,无论你查询的字段有多少个,就算字段太多无法走索引也避免了解析”*”带来的额外消耗。
l 查询字段值列出想要的字段,避免出现多余的字段,字段越多查询开销越大而且可能会因为多列出了某个字段而引起查询不走索引。
创建测试数据库
CREATE TABLE [Sales].[Customer](
[CustomerID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[PersonID] [int] NULL,
[StoreID] [int] NULL,
[TerritoryID] [int] NULL,
[AccountNumber] AS (isnull('AW'+[dbo].[ufnLeadingZeros]([CustomerID]),'')),
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_Customer_CustomerID] PRIMARY KEY CLUSTERED
(
[CustomerID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
创建索引
CREATE NONCLUSTERED INDEX [IX1_Customer] ON [Sales].[Customer]
(
[PersonID] ASC
)
INCLUDE ( [StoreID],
[TerritoryID],
[AccountNumber],
[rowguid]) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
查询测试
---使用SELECT * 查询
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT * FROM [Sales].[Customer]
WHERE PersonID=1;
SET STATISTICS TIME OFF
SET STATISTICS IO OFF

由于建的索引‘IX1_Customer’没有包含ModifiedDate字段,所以需要通过键查找去聚集索引中获取该字段的值
---列出需要的字段查询,因为字段不包含不需要的列,所以走索引
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT CustomerID,
[PersonID]
,[StoreID]
,[TerritoryID]
,[AccountNumber]
,[rowguid]
FROM [Sales].[Customer]
WHERE PersonID=1;
SET STATISTICS TIME OFF
SET STATISTICS IO OFF

由于查询语句中没有对ModifiedDate字段进行查询,所以只走索引查找就可以查询到需要的数据,所以建议在查询语句中列出你需要的字段而不是为了方便用*来查询所有的字段,如果真的
需要查询所有的字段也同样建议把所有的字段列出来取代‘*’。
10.使用存储过程的好处
减少网络通信量。调用一个行数不多的存储过程与直接调用SQL语句的网络通信量可能不会有很大的差别,可是如果存储过程包含上百行SQL语句,那么其性能绝对比一条一条的调用SQL语句要高得多。
执行速度更快。有两个原因:首先,在存储过程创建的时候,数据库已经对其进行了一次解析和优化。其次,存储过程一旦执行,在内存中就会保留一份这个存储过程缓存计划,这样下次再执行同样的存储过程时,可以从内存中直接调用。
更强的适应性:由于存储过程对数据库的访问是通过存储过程来进行的,因此数据库开发人员可以在不改动存储过程接口的情况下对数据库进行任何改动,而这些改动不会对应用程序造成影响。
布式工作:应用程序和数据库的编码工作可以分别独立进行,而不会相互压制。
更好的封装移植性。
安全性,它们可以防止某些类型的 SQL 插入攻击。
PROCEDURE [dbo].[SPSalesPerson]
(@option varchar(50))
AS
BEGIN
SET NOCOUNT ON
IF @option='select'
BEGIN
SELECT [DatabaseLogID]
,[PostTime]
,[DatabaseUser]
,[Event]
,[Schema]
,[Object]
,[TSQL]
,[XmlEvent]
FROM [dbo].[DatabaseLog]
END
IF @option='SalesPerson'
BEGIN
SELECT [BusinessEntityID]
,[TerritoryID]
,[SalesQuota]
,[Bonus]
,[CommissionPct]
,[SalesYTD]
,[SalesLastYear]
,[rowguid]
,[ModifiedDate]
FROM [Sales].[SalesPerson]
WHERE BusinessEntityID<300
END
SET NOCOUNT OFF
END
EXEC SPSalesPerson @option='select'
EXEC SPSalesPerson @option='SalesPerson' DBCC FREEPROCCACHE----清空缓存 ---测试两个查询是否都走了缓存计划
SELECT usecounts,size_in_bytes,cacheobjtype,objtype,TEXT FROM sys.dm_exec_cached_plans cp
CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st; --执行计划在第一次执行SQL语句时产生,缓存在内存中,这个缓存的计划一直可用,直到 SQL Server 重新启动,或直到它由于使用率较低而溢出内存。 默认情况下,存储过程将返回过程中每个语句影响的行数。如果不需要在应用程序中使用该信息(大多数应用程序并不需要),请在存储过程中使用 SET NOCOUNT ON 语句以终止该行为。根据存储过程中包含的影响行的语句的数量,这将删除客户端和服务器之间的一个或多个往返过程。尽管这不是大问题,但它可以为高流量应用程序的性能产生负面影响。
11.判断一条查询是否有值
--以下四个查询都是判断连接查询无记录时所做的操作
---性能最差消耗0.8秒
SET STATISTICS IO ON
SET STATISTICS TIME ON
DECLARE @UserType INT ,@Status INT
SELECT @UserType=COUNT(c.Id) FROM Customerfo t INNER JOIN Customer c ON c.Id=t.CustomerId
WHERE c.customerTel=''
IF(@UserType=0)
BEGIN
SET @Status = 2
PRINT @Status
END
SET STATISTICS TIME OFF
SET STATISTICS IO OFF
go ----性能较好消耗0.08秒
SET STATISTICS IO ON
SET STATISTICS TIME ON IF NOT EXISTS(SELECT c.Id FROM Customerfo t INNER JOIN Customer c ON c.Id=t.CustomerId WHERE c.customerTel='')
BEGIN
DECLARE @Status int
SET @Status = 2
PRINT @Status
END SET STATISTICS TIME OFF
SET STATISTICS IO OFF
go ----性能较好消耗0.08秒
SET STATISTICS IO ON
SET STATISTICS TIME ON IF NOT EXISTS(SELECT top 1 c.id FROM Customerfo t INNER JOIN Customer c ON c.Id=t.CustomerId WHERE c.customerTel=''
ORDER BY NEWID() )
BEGIN
DECLARE @Status int
SET @Status = 2
PRINT @Status
END SET STATISTICS TIME OFF
SET STATISTICS IO OFF GO ---性能和上面的一样0.08秒
SET STATISTICS IO ON
SET STATISTICS TIME ON IF NOT EXISTS(SELECT 1 FROM Customerfo t INNER JOIN Customer c ON c.Id=t.CustomerId WHERE c.customerTel='' )
BEGIN
DECLARE @Status int
SET @Status = 2
PRINT @Status
END SET STATISTICS TIME OFF
SET STATISTICS IO OFF 这里说一下SELECT 1,之前因为有程序员误认为查询SELECT 1无论查询的数据有多少只返回一个1,其实不是这样的,和查询字段是一样的意思只是有多少记录就返回多少个1,1也不是查询的第一个字段。
12.理解TRUNCATE和DELETE的区别
---创建表Table1
IF OBJECT_ID('Table1','U') IS NOT NULL
DROP TABLE Table1
GO
CREATE TABLE Table1
(ID INT NOT NULL,
FOID INT NOT NULL)
GO --插入测试数据
INSERT INTO Table1
VALUES(1,101),(2,102),(3,103),(4,104)
GO ---创建表Table2
IF OBJECT_ID('Table2','U') IS NOT NULL
DROP TABLE Table2
GO
CREATE TABLE Table2
(
FOID INT NOT NULL)
GO
--插入测试数据
INSERT INTO Table2 VALUES(101),(102),(103),(104)
GO
SELECT * FROM Table1
GO
SELECT * FROM Table2
GO
在Table1表中创建触发器,当表中的数据被删除时同时删除Table2表中对应的FOID
CREATE TRIGGER TG_Table1 ON Table1
AFTER DELETE
AS
BEGIN
DELETE FROM TA FROM Table2 TA INNER JOIN deleted TB ON TA.FOID=TB.FOID
END
GO
---测试DELETE删除操作
DELETE FROM Table1 WHERE ID=1 GO
---执行触发器成功,Table2表中的FOID=101的数据也被删除
SELECT * FROM Table1
GO
SELECT * FROM Table2
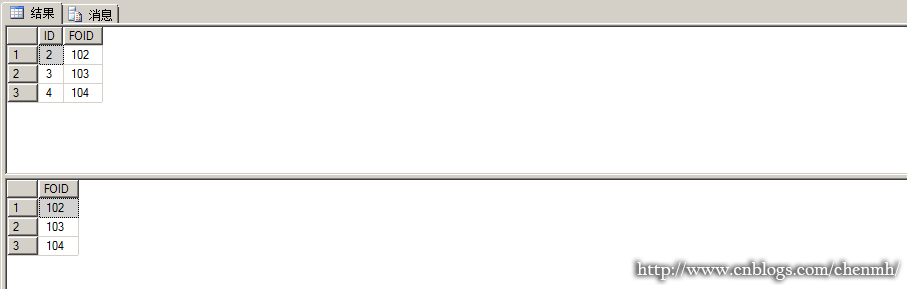
---测试TRUNCATE删除操作
TRUNCATE TABLE Table1 GO
---Table2中的数据没有被删除
SELECT * FROM Table1
GO
SELECT * FROM Table2

---查看TRUNCATE和DELETE的日志记录情况
CHECKPOINT
GO
SELECT * FROM fn_dblog(NULL,NULL)
GO
DELETE FROM Table2
WHERE FOID=102
GO
SELECT * FROM fn_dblog(NULL,NULL)
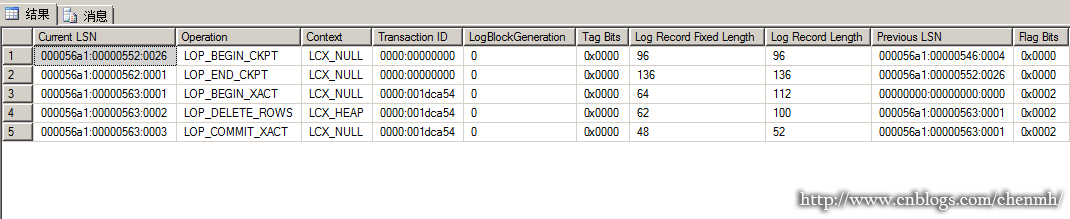
在第四行记录有一个lop_delete_rows,lcx_heap的删除操作日志记录
----TRUNCATE日志记录
CHECKPOINT
GO
SELECT * FROM fn_dblog(NULL,NULL)
GO
TRUNCATE TABLE Table2
GO
SELECT * FROM fn_dblog(NULL,NULL)
GO

TRUNCATE操作没有记录删除日志操作
主要的原因是因为TRUNCATE操作不会激活触发器,因为TRUNCATE操作不会记录各行的日志删除操作,所以当你需要删除一张表的数据时你需要考虑是否应该如有记录日志删除操作,而不是根据个人的习惯来操作。
13.事务的理解
---创建表Table1
IF OBJECT_ID('Table1','U') IS NOT NULL
DROP TABLE Table1
GO
CREATE TABLE Table1
(ID INT NOT NULL PRIMARY KEY,
Age INT NOT NULL CHECK(Age>10 AND Age<50));
GO ---创建表Table2
IF OBJECT_ID('Table2','U') IS NOT NULL
DROP TABLE Table2
GO
CREATE TABLE Table2
(
ID INT NOT NULL)
GO
1.简单的事务提交
BEGIN TRANSACTION
INSERT INTO Table1(ID,Age)
VALUES(1,20)
INSERT INTO Table1(ID,Age)
VALUES(2,5)
INSERT INTO Table1(ID,Age)
VALUES(2,20)
INSERT INTO Table1(ID,Age)
VALUES(3,20)
COMMIT TRANSACTION
GO
---第二条记录没有执行成功,其他的都执行成功
SELECT * FROM Table1
所以并不是事务中的任意一条语句报错整个事务都会回滚,其它的可执行成功的语句依然会执行成功并提交。

2.TRY...CATCH
DELETE FROM Table1 BEGIN TRY
BEGIN TRANSACTION
INSERT INTO Table1(ID,Age)
VALUES(1,20)
INSERT INTO Table1(ID,Age)
VALUES(2,20)
INSERT INTO Table1(ID,Age)
VALUES(3,20)
INSERT INTO Table3
VALUES(1)
COMMIT TRANSACTION
END TRY
BEGIN CATCH
ROLLBACK TRANSACTION
END CATCH ----重新打开一个回话执行查询,发现由于存在对象出错BEGIN CATCH并没有收到执行报错,且事务一直处于打开状态,没有被提交,也没有执行回滚。
SELECT * FROM Table1 ---如果事务已经提交查询XACT_STATE()的状态值是0,或者执行DBCC OPENTRAN
SELECT XACT_STATE() DBCC OPENTRAN ---手动执行提交或者回滚操作
ROLLBACK TRANSACTION
TRY...CATCH不会返回对象错误或者字段错误等类型的错误
想详细了解TRY...CATCH请参考http://www.cnblogs.com/chenmh/articles/4012506.html
3.打开XACT_ABORT
SET XACT_ABORT ON
BEGIN TRANSACTION
INSERT INTO Table1(ID,Age)
VALUES(1,20)
INSERT INTO Table1(ID,Age)
VALUES(2,20)
INSERT INTO Table1(ID,Age)
VALUES(3,20)
INSERT INTO Table3
VALUES(1)
COMMIT TRANSACTION
SET XACT_ABORT OFF ---事务全部执行回滚操作(对象table3是不存在报错,但是也回滚所有的提交,跟上面的TRY...CATCH的区别)
SELECT * FROM Table1

---查询是否有打开事务
SELECT XACT_STATE() DBCC OPENTRAN
未查询到有打开事务
当 SET XACT_ABORT 为 ON 时,如果执行 Transact-SQL 语句产生运行时错误,则整个事务将终止并回滚。
当 SET XACT_ABORT 为 OFF 时,有时只回滚产生错误的 Transact-SQL 语句,而事务将继续进行处理。如果错误很严重,那么即使 SET XACT_ABORT 为 OFF,也可能回滚整个事务。OFF 是默认设置。
编译错误(如语法错误)不受 SET XACT_ABORT 的影响。
所以我们应该根据自己的需求选择正确的事务。
14.修改字段NOT NULL的过程
在Address表中的有一个Address字段,该字段允许为NULL,现在需要将其修改为NOT NULL.
BEGIN TRANSACTION
SET QUOTED_IDENTIFIER ON
SET ARITHABORT ON
SET NUMERIC_ROUNDABORT OFF
SET CONCAT_NULL_YIELDS_NULL ON
SET ANSI_NULLS ON
SET ANSI_PADDING ON
SET ANSI_WARNINGS ON
COMMIT
BEGIN TRANSACTION
GO
CREATE TABLE dbo.Tmp_Address
(
ID int NOT NULL,
Address nvarchar(MAX) NOT NULL
) ON [PRIMARY]
TEXTIMAGE_ON [PRIMARY]
GO
ALTER TABLE dbo.Tmp_Address SET (LOCK_ESCALATION = TABLE)
GO
IF EXISTS(SELECT * FROM dbo.Address)
EXEC('INSERT INTO dbo.Tmp_Address (ID, Address)
SELECT ID, Address FROM dbo.Address WITH (HOLDLOCK TABLOCKX)')
GO
DROP TABLE dbo.Address
GO
EXECUTE sp_rename N'dbo.Tmp_Address', N'Address', 'OBJECT'
GO
COMMIT ---从上面就是一个重置字段为非空的过程,从上面的语句我们可以看到首先要创建一张临时表在临时表中Address字段建成了NOT NULL,然后将原表中的数据插入到临时表当中,最后修改表名,大家可以想一下如果我要修改的表有几千万数据,那这个过程该多么长而且内存一下子就会增加很多,所以大家建表的时候就要养成设字段为NOT NULL --当你要向现有的表中增加一个字段的时候你也要不允许为NULL,可以用默认值替代空
Alter Table Address Add Type smallint Not Null Default (1)
15.条件字段的先后顺序
你平时在写T_SQL语句的时候WHERE条件后面的字段的先后顺序你有注意吗?
---创建测试表
IF OBJECT_ID('TAINFO','U')IS NOT NULL DROP TABLE TAINFO
GO CREATE TABLE [dbo].[TAINFO](
ID INT NOT NULL PRIMARY KEY IDENTITY(1,1),
OID INT NOT NULL,
Stats SMALLINT CHECK (Stats IN(1,2)),
MAC uniqueidentifier NOT NULL ) ON [PRIMARY] GO
---插入测试数据
INSERT INTO TAINFO(OID,Stats,MAC)
VALUES(101,1,'46B550F9-6E24-436D-9BC7-F0650F562E54'),(101,2,'46B550F9-6E24-436D-9BC7-F0650F562E54'),(102,1,'46B550F9-6E24-436D-9BC7-F0650F562E54'),
(102,2,'46B550F9-6E24-436D-9BC7-F0650F562E54'),(103,2,'46B550F9-6E24-436D-9BC7-F0650F562E54'),(103,2,'46B550F9-6E24-436D-9BC7-F0650F562E54'),
(103,1,'46B550F9-6E24-436D-9BC7-F0650F562E54'),(103,1,'46B550F9-6E24-436D-9BC7-F0650F562E54')
GO
如果这是你的写的查询语句
SELECT ID,OID,Stats MAC FROM TAINFO WHERE MAC='46B550F9-6E24-436D-9BC7-F0650F562E54' AND STATS=1 AND OID=102
我现在根据你的查询语句创建一条索引
CREATE INDEX IX2_TAINFO ON TAINFO(MAC,STATS,OID)
分别执行三条查询语句
---1.WHERE条件是索引字段且查询字段也是索引字段
SELECT ID,OID,Stats MAC FROM TAINFO WHERE MAC='46B550F9-6E24-436D-9BC7-F0650F562E54' AND STATS=1 AND OID=102
--2.WHERE 条件是索引的部分字段(这条语句或许是平时查询该表用到的最多的一条语句)
SELECT ID,OID,Stats MAC FROM TAINFO WHERE OID=102 AND STATS=1
--3.WHERE 条件是索引的部分字段
SELECT ID,OID,Stats MAC FROM TAINFO WHERE STATS=1
执行计划分别为
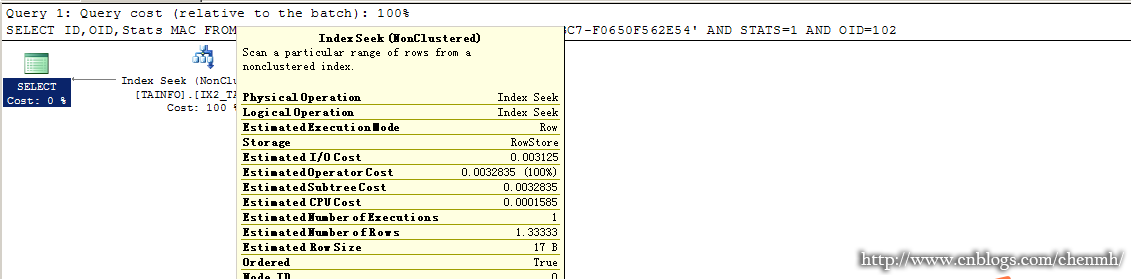
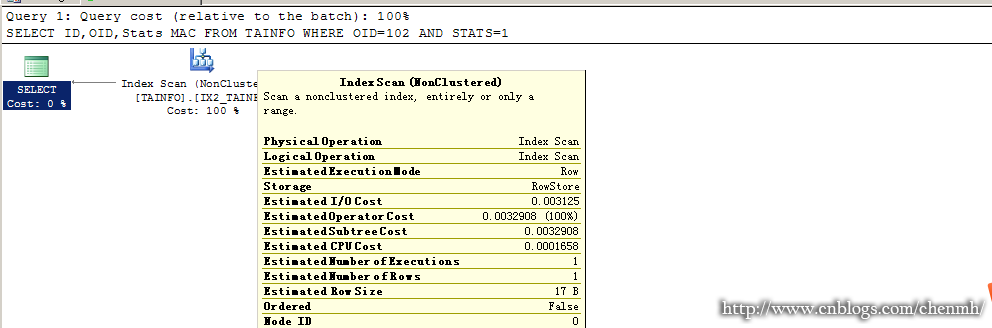

从上面三天查询语句可以看出,只有第一条语句走的是索引查找,另外两条语句走的是索引扫描,而我们从字段的名称应该可以看的出OID字段应该是该表的一个外键字段也是经常会被用作查询的字段。
接下来我们重新换一下索引顺序
--创建索引
DROP INDEX IX2_TAINFO ON TAINFO
GO
CREATE INDEX IX1_TAINFO ON TAINFO(OID)
INCLUDE(STATS,MAC)
GO
依然执行前面的三条查询语句分析执行计划



分析执行计划前面两条查询语句都走的是索引查找,第三条查询的是索引扫描,而根据一般单独用第三条查询的业务应该不会常见,所以现在一条索引解决了两个常用查询的索引需求,避免了建两条索引的必要(所以当你建索引的时候索引的顺序很重要,一般把查询最频繁的字段设第一个字段,可以避免建多余的索引)。
为什么要把这个问题提出来呢,因为平时有遇到程序员在写查询语句的时候对于同一个查询条件每次的写法都不一样,往往是根据自己想到哪个字段就写哪个字段先,这样的习惯往往是不好的,就好比上面的例子如果别人看到你的查询条件建一个索引也是这样写的话往往一个表会出现很多多余的索引(或许有人会说DBA建好索引的顺序就好了,这里把这个因素排除吧),像后面的那个索引就解决了两个查询的需求。
所以这里我一般是这样规定where条件的,对于经常用作查询的字段放在第一个位置(比如上面例子的OID),其它的字段根据表的实际字段顺序排列,这样往往你的查询语句走索引的概率会更大。
16.理解外连接
---创建测试表
IF OBJECT_ID('DBO.OrderS','U') IS NOT NULL DROP TABLE DBO.OrderS
GO
CREATE TABLE DBO.OrderS
(Orderid INT NOT NULL,
custid INT NOT NULL,
stats INT NOT NULL);
GO
IF OBJECT_ID('DBO.Customer','U') IS NOT NULL DROP TABLE DBO.Customer
GO
CREATE TABLE DBO.Customer
(Customerid INT NOT NULL );
GO ---插入测试数据
INSERT INTO OrderS VALUES(1,101,0),(2,102,0),(3,103,1),(4,104,0);
GO
INSERT INTO Customer VALUES(101),(102),(103); ----查询OrderS 表中stats不等于1且不在Customer 表中的数据
SELECT TA.Orderid,TA.custid,TA.stats,TB.Customerid FROM OrderS TA LEFT JOIN Customer TB ON TA.stats<>'' AND TA.custid=TB.Customerid
WHERE TB.Customerid IS NULL

看到这结果是不是有点疑惑,我在连接条件里面写了TA.stats<>'1',为什么结果还会查询出。
接下来我们换一种写法吧!
----查询OrderS 表中stats不等于1且不在Customer 表中的数据
SELECT TA.Orderid,TA.custid,TA.stats,TB.Customerid FROM OrderS TA LEFT JOIN Customer TB ON TA.custid=TB.Customerid
WHERE TA.stats<>'' AND TB.Customerid IS NULL

接下来我就解释一下原因:对于外连接,连接条件不会改变主表的数据,即不会删减主表的数据
对于上面的查询主表是orders,所以无论你在连接条件on里面怎样设置主表的条件都不影响主表数据的输出,影响主表数据的输出只在where条件里,where条件影响最后数据的输出。而对于附表Customer 的条件就应该写在连接条件(on)里而不是where条件里,这里说的是外连接(包括左连接和右连接)。
对于inner join就不存在这种情况,无论你的条件是写在where后面还是on后面都是一样的,但是还是建议写在where后面。
17.谓词类型要与字段类型对齐
IF OBJECT_ID('Person','u')IS NOT NULL DROP TABLE Person
GO
CREATE TABLE Person
(ID INT NOT NULL PRIMARY KEY IDENTITY(1,1),
Phone NVARCHAR(20) NOT NULL,
CreateDate DATETIME NOT NULL
)
---插入测试数据
INSERT INTO Person(Phone,CreateDate)
VALUES('',GETDATE()),('',GETDATE()),('',GETDATE())
---创建索引
CREATE INDEX IX_Person ON Person(Phone,CreateDate)
1.谓词类型与字段类型不一致
SELECT ID FROM Person WHERE Phone=13700000000 AND DATEDIFF(DAY,CreateDate,GETDATE())=0

由于定义表的phone字段类型是字符型,而上面的查询条件phone写成了整形,导致执行计划走了索引扫描,且执行计划select也有提示。
2.谓词类型与字段类型一致
SELECT ID FROM Person WHERE Phone='' AND DATEDIFF(DAY,CreateDate,GETDATE())=0

第二种查询phone谓词类型与字段类型一致,所以查询走了索引查找
在日常的语句编写过程中需要注意这类问题,这将直接影响性能。
18.避免使用长字节字段排序
SELECT O.name,O.create_date,C.name FROM SYS.columns C INNER JOIN SYS.objects O ON C.object_id=O.object_id
ORDER BY O.create_date DESC
GO
SELECT O.name,O.create_date,C.name FROM SYS.columns C INNER JOIN SYS.objects O ON C.object_id=O.object_id
ORDER BY O.object_id DESC


上面的语句查询结果是一样的,只是写法不一样,O.create_date是表的创建时间而object_id 是一个自增值根据两者的倒序排序得到的结果是一样的,但是二者的执行效率却不一样。无论是从执行时间还是执行计划明显是后者的效率要好,从执行计划可以看出后者的不需要进行排序操作因为object_id 本身就是排序好的,而且object_id 是整形而create_date是时间类型,如果是两个大表进行连接操作再进行排序效率更明显甚至前面用时间排序还可能查询很久不出来。
三、总结
后面收集到类似的问题会补充在文章的末尾,文章持续更新中....,欢迎关注讨论。
|
备注: 作者:pursuer.chen 博客:http://www.cnblogs.com/chenmh 本站点所有随笔都是原创,欢迎大家转载;但转载时必须注明文章来源,且在文章开头明显处给明链接,否则保留追究责任的权利。 《欢迎交流讨论》 |
SQL Server 致程序员(容易忽略的错误)的更多相关文章
- 关于SQL Server 安装程序在运行 Windows Installer 文件时遇到错误
前几日安装sql server2008r2 的时候碰到这个问题: 出现以下错误: SQL Server 安装程序在运行 Windows Installer 文件时遇到错误. Windows Insta ...
- sql server安装程序无法验证服务账户是什么原因
为了帮助网友解决“sql server安装程序无法验证服务”相关的问题,中国学网通过互联网对“sql server安装程序无法验证服务”相关的解决方案进行了整理,用户详细问题包括:能是尚未向所有要安装 ...
- 安装 SQL SERVER MsiGetProductInfo 无法检索 Product Code 1605错误 解决方案
重装数据库服务器上的SQL SERVER 2008 上遇到了以下问题 标题: SQL Server 安装程序失败. SQL Server 安装程序遇到以下错误: MsiGetProductInfo 无 ...
- [解决方案]在Sql Server 2008/2005 数据库还原出现 3154错误
在Sql Server 2008/2005 数据库还原出现 3154错误 解决方法1:不要在数据库名字上点右键选择还原,而要是在根目录“数据库”三个字上点右键选择还原,然后再选择数据库,问题便可以解决 ...
- SQL SERVER(MSSQLSERVER) 服务无法启用 特定服务错误:126
SQL SERVER(MSSQLSERVER) 服务无法启用 特定服务错误:126 对于这样一个错误google了一下 说是 要禁止掉via才行 回到SQL配置管理器中 禁止掉via 果然可以重新 ...
- 十个JAVA程序员容易犯的错误
十个JAVA程序员容易犯的错误 1. Array 转 ArrayList 一般开发者喜欢用: List<String> list = Arrays.asList(arr); Arrays. ...
- Sql Server 2008/2005 数据库还原出现 3154错误
在Sql Server 2008/2005 数据库还原出现 3154错误 解决方法1:不要在数据库名字上点右键选择还原,而要是在根目录“数据库”三个字上点右键选择还原,然后再选择数据库,问题便可以解决 ...
- 在SQL SERVER 2005中还原数据库时出现错误:system.data.sqlclient.sqlerror 媒体集有 2 个媒体簇 但只提供了 1 个。必须提供所有成员。 (microsoft.sqlserver.smo)
问题:在SQL SERVER 2005中还原数据库时出现错误:system.data.sqlclient.sqlerror 媒体集有 2 个媒体簇 但只提供了 1 个.必须提供所有成员. (micro ...
- sql数据黑马程序员——SQL入门
最近研究sql数据,稍微总结一下,以后继续补充: ---------------------- ASP.Net+Android+IO开辟S..Net培训.等待与您交流! --------------- ...
随机推荐
- 阿里巴巴直播内容风险防控中的AI力量
直播作为近来新兴的互动形态和今年阿里巴巴双十一的一大亮点,其内容风险监控是一个全新的课题,技术的挑战非常大,管控难点主要包括业界缺乏成熟方案和标准.主播行为.直播内容不可控.峰值期间数千路高并发处理. ...
- Entity Framework Core 1.1 升级通告
原文地址:https://blogs.msdn.microsoft.com/dotnet/2016/11/16/announcing-entity-framework-core-1-1/ 翻译:杨晓东 ...
- C#与C++的发展历程第三 - C#5.0异步编程巅峰
系列文章目录 1. C#与C++的发展历程第一 - 由C#3.0起 2. C#与C++的发展历程第二 - C#4.0再接再厉 3. C#与C++的发展历程第三 - C#5.0异步编程的巅峰 C#5.0 ...
- WPF做12306验证码点击效果
一.效果 和12306是一样的,运行一张图上点击多个位置,横线以上和左边框还有有边框位置不允许点击,点击按钮输出坐标集合,也就是12306登陆的时候,需要向后台传递的参数. 二.实现思路 1.获取验证 ...
- ZKWeb网页框架1.3正式发布
本次更新的内容有 更新引用包版本 Microsoft.AspNetCore.Hosting.Abstractions 1.1.0 Microsoft.AspNetCore.Http.Abstracti ...
- 关于font-family
在设置页面字体的时候,你会发现在 font-family 属性中会设置好多个字体,想看懂它们都是什么字体吗?不好意思,我不是搞设计的,我也不知道.那么,现在写的东西,只是对于一个前端人员来说,要了解的 ...
- 如何理解DT将是未来IT的转型之路?
如今的IT面临着内忧外患的挑战. 一方面,企业多多少少都建立了信息化,有些企业或集团甚至会有数几十个分公司,包含直销.代理.零售以及第三方物流等多种业态.越是复杂的业务,信息化建设越困难,比如运用大量 ...
- 易用BPM时代,软件开发者缘何选择H3?
近年来,企业级软件开发市场暗流汹涌,呈现出多种态势.软件开发团队规模趋于小型化,工作方式趋于快捷化,超过半数的软件开发者在工作中会选择使用易用的软件开发工具.随着流程管理越来越受到企业的重视,流程开发 ...
- Unity C#最佳实践(上)
本文为<effective c#>的读书笔记,此书类似于大名鼎鼎的<effective c++>,是入门后提高水平的进阶读物,此书提出了50个改进c#代码的原则,但是由于主要针 ...
- mono for android学习过程系列教程(4)
今天要讲的事情是构建安卓程序的UI界面. 首先给大家上点小点心,如图: 上面就是我们界面的设计模块,仔细看中间大块的下方,有一个Source,这就类似webform里面的设计和源代码界面. 在这个页面 ...