R语言 决策树算法
###决策树基础概念
在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy (熵) 表示的是系统的凌乱程度,它是决策树的决策依据,熵的概念来源于香侬的信息论。
###决策树的决策过程
- 选择分裂特征:根据某一指标(信息增益,信息增益比或基尼系数)计算不同特征的指标值,选出最佳的特征作为分裂节点。
- 生成决策树:不断的重复分裂特征选择,并从上至下递归生成子节点,直到数据集不可分则停止决策树的生长。
- 决策树调整:完全展开的决策树一般容易过拟合,需要进行一定程度的剪枝(减少决策树的深度或子节点的数量)
###信息熵极其衍生概念
在具体的决策树算法前先理解下基础概念信息熵。
####信息熵和条件熵
信息熵(entropy)是消除不确定性所需信息量的度量,也即未知事件可能含有的信息量。它可以衡量一个随机变量出现的期望值。如果信息的不确定性越大,熵的值也就越大,出现的各种情况也就越多。比如在2018年世界杯开始前预测哪个球队会获得冠军,这个随机变量的不确定性很高,要消除这个不确定性,就需要引入很多的信息,即信息熵很大。而预测中国队获得冠军,这个事件的确定性很高(中国没有进入世界杯),几乎不需要引入新信息,因而信息熵很低。
信息熵公式表示为:
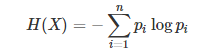
其中,X为所有事件集合,p为事件发生概率,n为特征总数。
条件熵(conditional entropy) 可以表示为已知某一个随机变量的情况下另一个变量的不确定性。
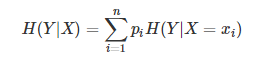
条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性。
####信息增益
信息增益(information gain)表示得知特征X的信息而使得类Y的信息的不确定性减少的程度。即使用某一特征进行分裂前后熵的差值。
特征A对训练数据集D的信息增益g(D,A),定义为集合D的熵H(D)与特征A给定条件下D的条件熵H(D|A)之差。
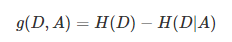
####信息增益比
信息增益比是信息增益和熵的比值。
特征A对训练数据集D的信息增益比gR(D,A)定义为其信息增益g(D,A)与训练数据集D关于特征A的值的熵HA(D)之比。
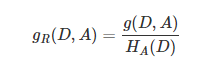
###决策树分类
目前主流的决策树有ID3,C4.5,CART等。
####决策树之ID3
ID3算法是以信息增益为准则选择分裂后信息增益最大的属性进行分裂。
ID3的实现过程:
- 初始化属性集合和数据集合
- 计算数据集合信息熵S和所有属性的信息熵,选择信息增益最大的属性作为当前决策节点
- 更新数据集合和属性集合(删除掉上一步中使用的属性,并按照属性值来划分不同分支的数据集合)
- 依次对每种取值情况下的子集重复第二步
- 若子集只包含单一属性,则为分支为叶子节点,根据其属性值标记。
- 完成所有属性集合的划分
ID3算法存在的问题:
- 信息增益对可取值数目较多的属性有所偏好,比如通过ID号可将每个样本分成一类,但是没有意义。
- ID3只能对离散属性的数据集构造决策树。
- 没有剪枝过程,为了去除过渡数据匹配的问题,可通过裁剪合并相邻的无法产生大量信息增益的叶子节点。
####决策树之C4.5
C4.5算法是ID3算法的一种改进。它是以信息增益率为准则选择属性。
C4.5相对于ID3改进的地方:
- 在信息增益的基础上对属性有一个惩罚,抑制可取值较多的属性,增强泛化性能。
- 在树的构造过程中可以进行剪枝,缓解过拟合;
- 同时能够对连续属性进行离散化处理(二分法);
- 还能够对缺失值进行处理;但在构造树的过程需要对数据集进行多次顺序扫描和排序,导致算法低效;
离散化处理过程:
- 将需要处理的样本(对应根节点)或样本子集(对应子树)按照连续变量的大小从小到大进行排序
- 假设该属性对应不同的属性值共N个,那么总共有N-1个可能的候选分割值点,每个候选的分割阈值点的值为上述排序后的属性值中两两前后连续元素的中点
- 用信息增益选择最佳划分
####决策树之CART
CART算法可以进行分类和回归,可以处理离散属性,也可以处理连续的。但数据对象的属性特征为离散型或连续型,并不是区别分类树与回归树的标准。
作为分类决策树时,待预测样本落至某一叶子节点,则输出该叶子节点中所有样本所属类别最多的那一类(即叶子节点中的样本可能不是属于同一个类别,则多数为主);作为回归决策树时,待预测样本落至某一叶子节点,则输出该叶子节点中所有样本的均值。
因此,分类树使用GINI系数来选择划分属性:在所有候选属性中,选择划分后GINI系数最小的属性作为优先划分属性。而回归树使用用最小平方差。
####CART之分类树
分类树使用GINI增益系数来选择划分属性,GINI增益系数表示的是分裂后子样本的纯净度,GINI增益系数越小,子样本的纯净度越高,分裂效果越好,它和熵的作用刚好相反。
GINI系数公式:
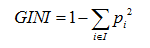
其中,pi表示分类结果中第i类出现的概率。
GINI增益系数公式:
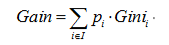
####CART之回归树
区别于分类树,回归树的待预测结果为连续型数据。同时,区别于分类树选取Gain_GINI为评价分裂属性的指标,回归树选取Gain_σ(可以称之为方差增益)为评价分裂属性的指标。选择具有最小Gain_σ的属性及其属性值,作为最优分裂属性以及最优分裂属性值。Gain_σ值越小,说明二分之后的子样本的“差异性”越小,说明选择该属性(值)作为分裂属性(值)的效果越好。
平方差公式:
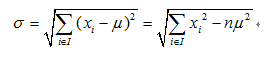
其中,μ表示样本集中预测结果的均值。
Gain_σ公式:
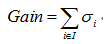
####R决策树实现
R中有实现决策树算法的包rpart,和画出决策树的包rpart.plot
生成树 :rpart () 函数
rpart (formula , data , weights , subset , na. action= na. rpart , method , model = FALSE , x = FALSE ,y = TRUE , parms , control , cost , . . . )
主要参数说明 :
* formula 回归方程形式 : 例如 y~x1 + x2 + x3 。
* data 数据 : 包含前面方程中变量的数据框 ( dataframe)
* na . action 缺失数据的处理办法 : 默认办法是删除因变量缺失的观测而保留自变量缺失的观测。
* method 根据树末端的数据类型选择相应变量分割方法 ,本参数有四种取值 : 连续型 ] “anova” ; 离散型 ]“ class” ; 计数型 ( 泊松过程) ] “ poisson” ; 生存分析型 ] “ exp ”。程序会根据因变量的类型*
* 自动选择方法 ,但一般情况下最好还是指明本参数 ,以便让程序清楚做哪一种树模型。
* parms 用来设置三个参数 : 先验概率、损失矩阵、分类纯度的度量方法。
* control 控制每个节点上的最小样本量、交叉验证 的 次 数、复 杂 性 参 量 : 即 cp : com plexit y
* pamemeter ,这个参数意味着对每一步拆分 , 模型的拟合优度必须提高的程度 ,等等。
剪枝 :prune () 函数
函数用法 :prune ( tree , . . . ) prune ( tree , c p , . . . )
* tree 一个回归树对象 ,常是 r part () 的结果对象。
* cp 复杂性参量 ,指定剪枝采用的阈值。
建模实例
library(rpart)
model<-rpart(Species~Sepal.Length+Sepal.Width+Petal.Length+Petal.Width,
data=iris,method="class",control=5,
parms=list(prior=c(0.3,0.4,0.3), split = "information"))
plot(model,margin=0.2)
text(model,use.n=T,all=T,cex=0.9)
决策树画出来的结果

R语言 决策树算法的更多相关文章
- 机器学习-决策树算法+代码实现(基于R语言)
分类树(决策树)是一种十分常用的分类方法.核心任务是把数据分类到可能的对应类别. 他是一种监管学习,所谓监管学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,通过学习得到一个 ...
- [转]机器学习——C4.5 决策树算法学习
1. 算法背景介绍 分类树(决策树)是一种十分常用的分类方法.它是一种监管学习,所谓监管学习说白了很简单,就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分 ...
- 零基础数据分析与挖掘R语言实战课程(R语言)
随着大数据在各行业的落地生根和蓬勃发展,能从数据中挖金子的数据分析人员越来越宝贝,于是很多的程序员都想转行到数据分析, 挖掘技术哪家强?当然是R语言了,R语言的火热程度,从TIOBE上编程语言排名情况 ...
- 大数据时代的精准数据挖掘——使用R语言
老师简介: Gino老师,即将步入不惑之年,早年获得名校数学与应用数学专业学士和统计学专业硕士,有海外学习和工作的经历,近二十年来一直进行着数据分析的理论和实践,数学.统计和计算机功底强悍. 曾在某一 ...
- R语言进行机器学习方法及实例(一)
版权声明:本文为博主原创文章,转载请注明出处 机器学习的研究领域是发明计算机算法,把数据转变为智能行为.机器学习和数据挖掘的区别可能是机器学习侧重于执行一个已知的任务,而数据发掘是在大数据中寻找有 ...
- R语言︱XGBoost极端梯度上升以及forecastxgb(预测)+xgboost(回归)双案例解读
XGBoost不仅仅可以用来做分类还可以做时间序列方面的预测,而且已经有人做的很好,可以见最后的案例. 应用一:XGBoost用来做预测 ------------------------------- ...
- R语言︱决策树族——随机森林算法
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:有一篇<有监督学习选择深度学习 ...
- R语言函数总结(转)
R语言特征 对大小写敏感 通常,数字,字母,. 和 _都是允许的(在一些国家还包括重音字母).不过,一个命名必须以 . 或者字母开头,并且如果以 . 开头,第二个字符不允许是数字. 基本命令要么是表达 ...
- 用R语言实现对不平衡数据的四种处理方法
https://www.weixin765.com/doc/gmlxlfqf.html 在对不平衡的分类数据集进行建模时,机器学**算法可能并不稳定,其预测结果甚至可能是有偏的,而预测精度此时也变得带 ...
随机推荐
- DDD(领域驱动设计)应对具体业务场景,Domain Model(领域模型)到底如何设计?
DDD(领域驱动设计)应对具体业务场景,Domain Model(领域模型)到底如何设计? 写在前面 阅读目录: 迷雾森林 找回自我 开源地址 后记 毫无疑问,领域驱动设计的核心是领域模型,领域模型的 ...
- AngularJS and Asp.net MVC
AngularJS 初印象------对比 Asp.net MVC 之前就早耳闻前端MVC的一些框架,微软自家的Knockout.js,google家的AngularJs,还有Backone.但未曾了 ...
- 验证API
验证API 本篇定位在数据入口的验证 普通的DataAnnotation验证 基于场景的DataAnnotation验证 可修改的外置式DataAnnotation验证 SUMMARY 最终调用时的用 ...
- Webapi帮助文档
生成自己的Webapi帮助文档(一) 最近Webapi接口的开发刚刚进入尾声,随之而来的是让用户知道接口的详细参数信息,看过淘宝的接口文档,但网上没找到他的实现方式 虽然新建Webapi时C#也会给你 ...
- C#中的深复制与浅复制
C#中分为值类型和引用类型,值类型的变量直接包含其数据,而引用类型的变量则存储对象的引用. 对于值类型,每个变量都有自己的数据副本,对一个变量的操作不可能影响到另一个变量.如 class Progra ...
- 静态页面调试JS出现跨域问题
在chrome浏览器或者firefox浏览器里,由于安全限制的原因,本地调试JS,如果不配服务器环境而直接打开页面,那所有的AJAX操作会抛出下面错误: XMLHttpRequest cannot l ...
- 初探performance.timing API
初探performance.timing API 浏览器新提供的performance接口精确的告诉我们当访问一个网站页面时当前网页每个处理阶段的精确时间(timestamp),以方便我们进行前端 ...
- Class org.apache.struts2.json.JSONWriter can not access a member of class oracle.jdbc.driver.Physica
产生这个错误的原因是因为我的oracle数据库中有一个CLOB字段,查询出来的时候要转换为JSON而报错. Class org.apache.struts2.json.JSONWriter can n ...
- 配置 SQL Server Email 发送以及 Job 的 Notification通知功能
配置 SQL Server Email 发送以及 Job 的 Notification通知功能 在与数据库相关的项目中, 比如像数据库维护, 性能警报, 程序出错警报或通知都会使用到在 SQL Ser ...
- [Android开发常见问题-11] Unable to execute dex: Multiple dex files define 解决方法
最近在开发一个工程,其中用到了一个开源的库项目Android-ViewPagerIndicator. 这个项目是作为一个库出现的,如下图: 这个项目中包含了android-support-v4.jar ...