log4j2
转载自 Blog of 天外的星星: http://www.cnblogs.com/leo-lsw/p/log4j2tutorial.html
Log4j 2的好处就不和大家说了,如果你搜了2,说明你对他已经有一定的了解,并且想用它,所以这里直接就上手了。
1. 去官方下载log4j 2,导入jar包,基本上你只需要导入下面两个jar包就可以了(xx是乱七八糟的版本号):
log4j-core-xx.jar
log4j-api-xx.jar
2. 导入到你的项目中:这个就不说了。
3. 开始使用:
我们知道,要在某个类中使用log4j记录日志,只需要申明下面的成员变量(其实不一定要是成员变量,只是为了方便调用而已),log4j 2.0的使用非常简单,只要用LogManager的getLogger函数获取一个logger,就可以使用logger记录日志。
private static Logger logger = LogManager.getLogger(MyApp.class.getName());
这里getLogger有一个参数指定的是这个logger的名称,这个名称在配置文件里面可是有需要的,这个待会儿再说。
声明了Logger对象,我们就可以在代码中使用他了。
4. 日志的级别:
我们现在要调用logger的方法,不过在这个Logger对象中,有很多方法,所以要先了解log4j的日志级别,log4j规定了默认的几个级别:trace<debug<info<warn<error<fatal等。这里要说明一下:
1)级别之间是包含的关系,意思是如果你设置日志级别是trace,则大于等于这个级别的日志都会输出。
2)基本上默认的级别没多大区别,就是一个默认的设定。你可以通过它的API自己定义级别。你也可以随意调用这些方法,不过你要在配置文件里面好好处理了,否则就起不到日志的作用了,而且也不易读,相当于一个规范,你要完全定义一套也可以,不用没多大必要。从我们实验的结果可以看出,log4j默认的优先级为ERROR或者WARN(实际上是ERROR)
3)这不同的级别的含义大家都很容易理解,这里就简单介绍一下:
trace: 是追踪,就是程序推进以下,你就可以写个trace输出,所以trace应该会特别多,不过没关系,我们可以设置最低日志级别不让他输出。
debug: 调试么,我一般就只用这个作为最低级别,trace压根不用。是在没办法就用eclipse或者idea的debug功能就好了么。
info: 输出一下你感兴趣的或者重要的信息,这个用的最多了。
warn: 有些信息不是错误信息,但是也要给程序员的一些提示,类似于eclipse中代码的验证不是有error 和warn(不算错误但是也请注意,比如以下depressed的方法)。
error: 错误信息。用的也比较多。
fatal: 级别比较高了。重大错误,这种级别你可以直接停止程序了,是不应该出现的错误么!不用那么紧张,其实就是一个程度的问题。
5. 日志调用:
这里随便写个类,调用就是这么简单,log4j的核心在配置文件上。

import org.apache.logging.log4j.Level;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger; public class Hello { static Logger logger = LogManager.getLogger(Hello.class.getName()); public boolean hello() {
logger.entry(); //trace级别的信息,单独列出来是希望你在某个方法或者程序逻辑开始的时候调用,和logger.trace("entry")基本一个意思
logger.error("Did it again!"); //error级别的信息,参数就是你输出的信息
logger.info("我是info信息"); //info级别的信息
logger.debug("我是debug信息");
logger.warn("我是warn信息");
logger.fatal("我是fatal信息");
logger.log(Level.DEBUG, "我是debug信息"); //这个就是制定Level类型的调用:谁闲着没事调用这个,也不一定哦!
logger.exit(); //和entry()对应的结束方法,和logger.trace("exit");一个意思
return false;
}
}
如果没有自定义配置文件,上面这个类在写一个main方法,控制台会输入下面的样子:
19:09:40.256 [main] ERROR cn.lsw.base.log4j2.Hello - Did it again!
19:09:40.260 [main] FATAL cn.lsw.base.log4j2.Hello - 我是fatal信息
看到没,只有>=ERROR的日志输出来了(这是因为Log4j有一个默认的配置,它的日志级别是ERROR,输出只有控制台)。如果我已经定义好了日志,我把日志级别改成了TRACE,输出会变成下面这样:
19:11:36.941 TRACE cn.lsw.base.log4j2.Hello 12 hello - entry
19:11:36.951 ERROR cn.lsw.base.log4j2.Hello 13 hello - Did it again!
19:11:36.951 INFO cn.lsw.base.log4j2.Hello 14 hello - 我是info信息
19:11:36.951 DEBUG cn.lsw.base.log4j2.Hello 15 hello - 我是debug信息
19:11:36.951 WARN cn.lsw.base.log4j2.Hello 16 hello - 我是warn信息
19:11:36.952 FATAL cn.lsw.base.log4j2.Hello 17 hello - 我是fatal信息
19:11:36.952 DEBUG cn.lsw.base.log4j2.Hello 18 hello - 我是debug信息
19:11:36.952 TRACE cn.lsw.base.log4j2.Hello 19 hello - exit
所有的日志都打印出来了,大家可以对照上面的代码看一看。
6. 配置文件:
现在开始正题了。
log4j是apache的一个开源项目,在写这篇博客的时候已经发布了2.0的beta版本,首先需要注意的是,log4j 2.0与以往的1.x有一个明显的不同,其配置文件只能采用.xml, .json或者 .jsn。在默认情况下,系统选择configuration文件的优先级如下:(classpath为scr文件夹)
- classpath下名为 log4j-test.json 或者log4j-test.jsn文件
- classpath下名为 log4j2-test.xml
- classpath下名为 log4j.json 或者log4j.jsn文件
- classpath下名为 log4j2.xml
本来以为Log4J 2应该有一个默认的配置文件的,不过好像没有找到,下面这个配置文件等同于缺省配置(from http://blog.csdn.net/welcome000yy/article/details/7962668):
<?xml version="1.0" encoding="UTF-8"?>
<configuration status="OFF">
<appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
</Console>
</appenders>
<loggers>
<root level="error">
<appender-ref ref="Console"/>
</root>
</loggers>
</configuration>
而我们只要把configuration>loggers>root的level属性改为trace,就可以输出刚才写的所有信息了。相信用过Log4j的人对这个配置文件也不算陌生,Log4J传统的配置一直是.properties文件,键值对的形式,那种配置方式很不好看,但是基本上我们从这个配置文件也能看到Log4J 1的影子,无非是appender了,layout之类的,含义也基本一样的。
这里不准备仔细的讲配置文件,没什么必要,大家只要知道一些基本的配置就可以了。我这里写几个配置文件,并且给了一定的注释和讲解,基本上可以用了。
第一个例子:
<?xml version="1.0" encoding="UTF-8"?>
<configuration status="OFF">
<appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{yyyy-MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36} - %msg%n"/>
</Console>
</appenders>
<loggers>
<!--我们只让这个logger输出trace信息,其他的都是error级别-->
<!--
additivity开启的话,由于这个logger也是满足root的,所以会被打印两遍。
不过root logger 的level是error,为什么Bar 里面的trace信息也被打印两遍呢
-->
<logger name="cn.lsw.base.log4j2.Hello" level="trace" additivity="false">
<appender-ref ref="Console"/>
</logger>
<root level="error">
<appender-ref ref="Console"/>
</root>
</loggers>
</configuration>
先简单介绍一下下面这个配置文件。
1)根节点configuration,然后有两个子节点:appenders和loggers(都是复数,意思就是可以定义很多个appender和logger了)(如果想详细的看一下这个xml的结构,可以去jar包下面去找xsd文件和dtd文件)
2)appenders:这个下面定义的是各个appender,就是输出了,有好多类别,这里也不多说(容易造成理解和解释上的压力,一开始也未必能听懂,等于白讲),先看这个例子,只有一个Console,这些节点可不是随便命名的,Console就是输出控制台的意思。然后就针对这个输出设置一些属性,这里设置了PatternLayout就是输出格式了,基本上是前面时间,线程,级别,logger名称,log信息等,差不多,可以自己去查他们的语法规则。
3)loggers下面会定义许多个logger,这些logger通过name进行区分,来对不同的logger配置不同的输出,方法是通过引用上面定义的logger,注意,appender-ref引用的值是上面每个appender的name,而不是节点名称。
这个例子为了说明什么呢?我们要说说这个logger的name(名称)了(前面有提到)。
7. name的机制:(可以参考: http://logging.apache.org/log4j/2.x/manual/architecture.html)
我们这里看到了配置文件里面是name很重要,没错,这个name可不能随便起(其实可以随便起)。这个机制意思很简单。就是类似于java package一样,比如我们的一个包:cn.lsw.base.log4j2。而且,可以发现我们前面生成Logger对象的时候,命名都是通过 Hello.class.getName(); 这样的方法,为什么要这样呢? 很简单,因为有所谓的Logger 继承的问题。比如 如果你给cn.lsw.base定义了一个logger,那么他也适用于cn.lsw.base.lgo4j2这个logger。名称的继承是通过点(.)分隔的。然后你可以猜测上面loggers里面有一个子节点不是logger而是root,而且这个root没有name属性。这个root相当于根节点。你所有的logger都适用与这个logger,所以,即使你在很多类里面通过 类名.class.getName() 得到很多的logger,而且没有在配置文件的loggers下面做配置,他们也都能够输出,因为他们都继承了root的log配置。
我们上面的这个配置文件里面还定义了一个logger,他的名称是 cn.lsw.base.log4j2.Hello ,这个名称其实就是通过前面的Hello.class.getName(); 得到的,我们为了给他单独做配置,这里就生成对于这个类的logger,上面的配置基本的意思是只有cn.lsw.base.log4j2.Hello 这个logger输出trace信息,也就是他的日志级别是trace,其他的logger则继承root的日志配置,日志级别是error,只能打印出ERROR及以上级别的日志。如果这里logger 的name属性改成cn.lsw.base,则这个包下面的所有logger都会继承这个log配置(这里的包是log4j的logger name的“包”的含义,不是java的包,你非要给Hello生成一个名称为“myhello”的logger,他也就没法继承cn.lsw.base这个配置了。
那有人就要问了,他不是也应该继承了root的配置了么,那么会不会输出两遍呢?我们在配置文件中给了解释,如果你设置了additivity="false",就不会输出两遍,否则,看下面的输出:
这里要在加入一个类做对比:
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger; public class Test { private static Logger logger = LogManager.getLogger(Test.class.getName()); public static void main(String[] args) { logger.trace("开始程序.");
Hello hello= new Hello();
// for (int i = 0; i < 10000;i++){
if (!hello.hello()) {
logger.error("hello");
}
// }
logger.trace("退出程序.");
}
}
这里先把配置文件改一下方便对照,一个是刚才第一个logger的名称还是cn.lsw.base.log4j2.Hello,additivity去掉或改为true(因为默认是true,所以可以去掉),第二是把root的level改为info方便观察。
然后运行Test,看控制台的日志输出:
2013-12-20 19:59:42.538 [main] INFO cn.lsw.base.log4j2.Test - test
2013-12-20 19:59:42.541 [main] TRACE cn.lsw.base.log4j2.Hello - entry
2013-12-20 19:59:42.541 [main] TRACE cn.lsw.base.log4j2.Hello - entry
2013-12-20 19:59:42.542 [main] ERROR cn.lsw.base.log4j2.Hello - Did it again!
2013-12-20 19:59:42.542 [main] ERROR cn.lsw.base.log4j2.Hello - Did it again!
2013-12-20 19:59:42.542 [main] INFO cn.lsw.base.log4j2.Hello - 我是info信息
2013-12-20 19:59:42.542 [main] INFO cn.lsw.base.log4j2.Hello - 我是info信息
2013-12-20 19:59:42.542 [main] DEBUG cn.lsw.base.log4j2.Hello - 我是debug信息
2013-12-20 19:59:42.542 [main] DEBUG cn.lsw.base.log4j2.Hello - 我是debug信息
2013-12-20 19:59:42.542 [main] WARN cn.lsw.base.log4j2.Hello - 我是warn信息
2013-12-20 19:59:42.542 [main] WARN cn.lsw.base.log4j2.Hello - 我是warn信息
2013-12-20 19:59:42.542 [main] FATAL cn.lsw.base.log4j2.Hello - 我是fatal信息
2013-12-20 19:59:42.542 [main] FATAL cn.lsw.base.log4j2.Hello - 我是fatal信息
2013-12-20 19:59:42.542 [main] DEBUG cn.lsw.base.log4j2.Hello - 我是debug信息
2013-12-20 19:59:42.542 [main] DEBUG cn.lsw.base.log4j2.Hello - 我是debug信息
2013-12-20 19:59:42.543 [main] TRACE cn.lsw.base.log4j2.Hello - exit
2013-12-20 19:59:42.543 [main] TRACE cn.lsw.base.log4j2.Hello - exit
2013-12-20 19:59:42.543 [main] ERROR cn.lsw.base.log4j2.Test - hello
可以看出,Test的trace日志没有输出,因为他继承了root的日志配置,只输出info即以上级别的日志。Hello 输出了trace及以上级别的日志,但是每个都输出了两遍。你可以试一下,把第一个logger的level该为error,那么error以上的级别也是输出两遍。这时候,只要加上additivity为false就可以避免这个问题了。
当然,你可以为每个logger 都在配置文件下面做不同的配置,也可以通过继承机制,对不同包下面的日志做不同的配置。因为loggers下面可以写很多歌logger。
下面在看一个稍微复杂的例子:
<?xml version="1.0" encoding="UTF-8"?> <configuration status="error">
<!--先定义所有的appender-->
<appenders>
<!--这个输出控制台的配置-->
<Console name="Console" target="SYSTEM_OUT">
<!--控制台只输出level及以上级别的信息(onMatch),其他的直接拒绝(onMismatch)-->
<ThresholdFilter level="trace" onMatch="ACCEPT" onMismatch="DENY"/>
<!--这个都知道是输出日志的格式-->
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level %class{36} %L %M - %msg%xEx%n"/>
</Console>
<!--文件会打印出所有信息,这个log每次运行程序会自动清空,由append属性决定,这个也挺有用的,适合临时测试用-->
<File name="log" fileName="log/test.log" append="false">
<PatternLayout pattern="%d{HH:mm:ss.SSS} %-5level %class{36} %L %M - %msg%xEx%n"/>
</File> <!--这个会打印出所有的信息,每次大小超过size,则这size大小的日志会自动存入按年份-月份建立的文件夹下面并进行压缩,作为存档-->
<RollingFile name="RollingFile" fileName="logs/app.log"
filePattern="log/$${date:yyyy-MM}/app-%d{MM-dd-yyyy}-%i.log.gz">
<PatternLayout pattern="%d{yyyy-MM-dd 'at' HH:mm:ss z} %-5level %class{36} %L %M - %msg%xEx%n"/>
<SizeBasedTriggeringPolicy size="50MB"/>
</RollingFile>
</appenders>
<!--然后定义logger,只有定义了logger并引入的appender,appender才会生效-->
<loggers>
<!--建立一个默认的root的logger-->
<root level="trace">
<appender-ref ref="RollingFile"/>
<appender-ref ref="Console"/>
</root> </loggers>
</configuration>
说复杂,其实也不复杂,这一个例子主要是为了讲一下appenders。
这里定义了三个appender,Console,File,RollingFile,看意思基本也明白,第二个是写入文件,第三个是“循环”的日志文件,意思是日志文件大于阀值的时候,就开始写一个新的日志文件。
这里我们的配置文件里面的注释算比较详细的了。所以就大家自己看了。有一个比较有意思的是ThresholdFilter ,一个过滤器,其实每个appender可以定义很多个filter,这个功能很有用。如果你要选择控制台只能输出ERROR以上的类别,你就用ThresholdFilter,把level设置成ERROR,onMatch="ACCEPT" onMismatch="DENY" 的意思是匹配就接受,否则直接拒绝,当然有其他选择了,比如交给其他的过滤器去处理了之类的,详情大家自己去琢磨吧。
为什么要加一个这样的配置文件呢?其实这个配置文件我感觉挺好的,他的实用性就在下面:
8. 一个实用的配置文件:
我们用日志一方面是为了记录程序运行的信息,在出错的时候排查之类的,有时候调试的时候也喜欢用日志。所以,日志如果记录的很乱的话,看起来也不方便。所以我可能有下面一些需求:
1)我正在调试某个类,所以,我不想让其他的类或者包的日志输出,否则会很多内容,所以,你可以修改上面root的级别为最高(或者谨慎起见就用ERROR),然后,加一个针对该类的logger配置,比如第一个配置文件中的设置,把他的level设置trace或者debug之类的,然后我们给一个appender-ref是定义的File那个appender(共三个appender,还记得吗),这个appender的好处是有一个append为false的属性,这样,每次运行都会清空上次的日志,这样就不会因为一直在调试而增加这个文件的内容,查起来也方便,这个和输出到控制台就一个效果了。
2)我已经基本上部署好程序了,然后我要长时间运行了。我需要记录下面几种日志,第一,控制台输出所有的error级别以上的信息。第二,我要有一个文件输出是所有的debug或者info以上的信息,类似做程序记录什么的。第三,我要单独为ERROR以上的信息输出到单独的文件,如果出了错,只查这个配置文件就好了,不会去处理太多的日志,看起来头都大了。怎么做呢,很简单。
>首先,在appenders下面加一个Console类型的appender,通过加一个ThresholdFilter设置level为error。(直接在配置文件的Console这个appender中修改)
>其次,增加一个File类型的appender(也可以是RollingFile或者其他文件输出类型),然后通过设置ThresholdFilter的level为error,设置成File好在,你的error日志应该不会那么多,不需要有多个error级别日志文件的存在,否则你的程序基本上可以重写了。
这里可以添加一个appender,内容如下:
<File name="ERROR" fileName="logs/error.log">
<ThresholdFilter level="error" onMatch="ACCEPT" onMismatch="DENY"/>
<PatternLayout pattern="%d{yyyy.MM.dd 'at' HH:mm:ss z} %-5level %class{36} %L %M - %msg%xEx%n"/>
</File>
并在loggers中的某个logger(如root)中引用(root节点加入这一行作为子节点)。
<appender-ref ref="ERROR" />
>然后,增加一个RollingFile的appender,设置基本上同上面的那个配置文件。
>最后,在logger中进行相应的配置。不过如果你的logger中也有日志级别的配置,如果级别都在error以上,你的appender里面也就不会输出error一下的信息了。
还记得上面的Test类里面有一个被注释掉的for循环么?这个是为了做配置文件中RollingFile那个appender的配置的,取消注释,运行商一次或几次,看你的输出配置文件的地方,他是怎么“RollingFile”的,这里给个我测试的截图:(这里你可以把 <SizeBasedTriggeringPolicy size="50MB"/>这里的size改成2MB,要生成50MB的日志还是比较慢的。为了方便观察么!然后把Console的ThresholdFilter的level设置成error这样的较高级别,不然控制台输出东西太多了)
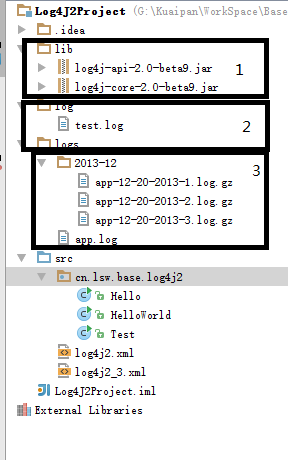
第一部分(图中标识为1),是我加入的jar包;
第二部分是File这个appender生成的日志文件,你会发现你运行很多次,这个文件中的日志是被覆盖的。
第三部分是RollingFile 这个appender生成的配置文件,可以发现,默认建立的是app.log这个日志,每次超过2MB的时候,就会生成对应年-月的文件夹,和制定命名格式的log文件,而且是压缩成gz格式文件,打开资源管理器发现这个文件只有11KB,解压后就是2MB。
最后,希望这个教程能够帮到大家!
log4j2的更多相关文章
- dubbox升级spring到4.x及添加log4j2支持
今天花了点时间,把dubbox依赖的spring从3.x升级成最新版的4.x了,其它一些依赖的组件也顺带升级了,同时dubbo支持的第三方日志组件居然没有log4j2,加了点代码也一并支持了,蛋疼的是 ...
- 聊一聊log4j2配置文件log4j2.xml
一.背景 最近由于项目的需要,我们把log4j 1.x的版本全部迁移成log4j 2.x 的版本,那随之而来的slf4j整合log4j的配置(使用Slf4j集成Log4j2构建项目日志系统的完美解决方 ...
- 使用Slf4j集成Log4j2构建项目日志系统的完美解决方案
一.背景 最近因为公司项目性能需要,我们考虑把以前基于的log4j的日志系统重构成基于Slf4j和log4j2的日志系统,因为,使用slf4j可以很好的保证我们的日志系统具有良好的兼容性,兼容当前常见 ...
- log4j2.xml实用例子
一个多月前,我写了篇关于log4j.xml配置的文章,点击此处查看:http://www.cnblogs.com/guogangj/p/3931397.html 最近,我把自己的log4j升级到2.0 ...
- log4j2 不使用配置文件,动态生成logger对象
大家平时使用Log4j一般都是在classpath下放置一个log4j的配置文件,比如log4j.xml,里面配置好Appenders和Loggers,但是前一阵想做某需求的时候,想要的效果是每一个任 ...
- Log4j2 - 配置
官方文档:http://logging.apache.org/log4j/2.x/index.html 1 概述 Log4j2的配置包含四种方式,其中3种都是在程序中直接调用Log4j2的方法进行配置 ...
- MyBatis - MyBatis使用log4j2显示sql和结果集
mybatis-config.xml <settings> <setting name="logImpl" value="LOG4J2" /& ...
- web项目 log4j2的路径问题
项目中用到log4j2记录日志,结果运行的时候总也不见log文件的产生. 查看官方文档得知,在web项目中使用log4j2需要加入log4j-web包 log4j2.xml <?xml vers ...
- 在java下使用log4j2记录日志
1.定义: log4j2 指log4j 2.X及以上版本 2.安装 log4j-core-xx.jarlog4j-api-xx.jarlog4j-web-xx.jar(web项目的需要引用) 3.配置 ...
- log4j2配置详解
1. log4j2需要两个jar log4j-api-2.x.x.jar log4j-core-2.x.x.jar .log4j和log4j2有很大的区别,jar包不要应错. 2. ...
随机推荐
- Dubbo源码学习--服务是如何发布的
相关文章: Dubbo源码学习--服务是如何发布的 Dubbo源码学习--服务是如何引用的 ServiceBean ServiceBean 实现ApplicationListener接口监听Conte ...
- 【Java每日一题】20170112
20170111问题解析请点击今日问题下方的"[Java每日一题]20170112"查看(问题解析在公众号首发,公众号ID:weknow619) package Jan2017; ...
- (转载)python日期函数
转载于http://www.cnblogs.com/emanlee/p/4399147.html 所有日期.时间的api都在datetime模块内. 1. 日期输出格式化 datetime => ...
- Android第二天
1.从看得见的活动入手 protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); ...
- ng-class,与ng-click
要求,后台传过来的数据,要求:(样式)性别为男的,变为灰色.(事件)并且没有点击事件,但女的有 <html> <head> <meta charset="utf ...
- C#调用winhttp组件 POST登录迅雷
下面是封装好的winhttp类 using System; using System.Collections.Generic; using System.Linq; using System.Text ...
- JavaScript简单的一些....
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Jenkins配置和使用
之前整理了Jenkins的下载和安装过程,有需要的可以参考我的博客,地址: http://www.cnblogs.com/luchangyou/p/5981884.html 接下来整理一下Jenk ...
- Firewalld防火墙
Firewalld服务是红帽RHEL7系统中默认的防火墙管理工具,特点是拥有运行时配置与永久配置选项且能够支持动态更新以及"zone"的区域功能概念,使用图形化工具firewall ...
- PIE 阻断回溯——Cut
PIE(Prolog Inference Engine)通常是搜索所有的解.举个例子, 当然dialog窗口中一开始调用 run. 只会显示一个解(虽然事实上会得到两个解),在前面加上 X=1,就可以 ...