git项目开发版本控制实践
linux和bsd:
第一, bsd, berkeley software distribution, 伯克利软件套装, 是最开始的unix是开放的, 然后berkeley对unix进行了修改, 形成了它的bsd, 后来hp和ibm在bsd的基础上, 形成了hp-unix, ibm的aix系统
linux是在minix的基础上, 仿unix做出的. 即 bsd是unix的分支, 而linux是仿unix的, bsd 跟unix的关系更近!
第二, bsd是内核和应用软件一体的 版本, 只有 freeBSD, Netbsd, openBSD 几种, 如同windows只有xp, win7, win10等一样.
而linux主要是指内核, 而基于linux内核 的发行版很多几百种...
第三, 两者的许可协议不同, bsd相对来说要宽松些, 允许用户使用并修改源代码, 并不要求公布 修改后的代码, 允许作为商业目的使用. 而GPL协议,要求修改后的代码要 公布, 而且 发行版要包括 编译包, 保证软件除了二进制包之外, 还有 源代码包可以获取.
第四, BSD的源码增删由core team小组来决定, 而linux内核代码则不是.
git和cvs, svn clearcase的区别?
git是轻量级的分布式的版本管理系统, 而svn等是中央式的重量级的 服务器式的集中管理版本系统.
一般正式的项目开法, 用2中系统, 正式颁布和预发行版本, 采用svn版本管理, 而开发阶段开发者的子模块 开发用git, 最后代码审核后 , 再merge到svn中.
git config -globe user.name "foo"
git config -globe user.email "foo@bar.com"
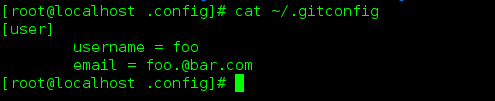
顾名思义, globe是全局配置, 这个配置将放在 用户的家目录 ~/.gitconfig文件中, 对整个用户创建的所有项目都 生效, 是用户在提交 文件时的 "签名":就是当你 commit file1 file2 ...时你的签名, 表示是谁commit的. 不会 再弹出一个对话框, 让你填写commit的用户名... 那样就太麻烦了.
git的 .gitignore文件, 是指 git是通过 追踪 "track"文件的状态 ,来 知道哪些文件是修改的, 哪些文件是需要 "进行版本管理的". 而像c项目中编译过程中产生的 obj, lnk, .xxx文件, 都是临时文件, 都不需要git进行跟踪的.这时, 可以把这些/这类 文件放入到ignore文件中. 否则, 你的文件夹就会有很多 untracked 标记的文件, 同时, 也不好用 git add . 和 git commit -a -m("后面的注释内容, 对正式项目开发很重要"), 这些文件包括具体的某一个文件,也可以包含某一类文件: 如: foo.txt, *.txt, !bar.txt(排除某一个具体的文件), .svn/等,
具体的 "忽略"文件放置位置:
- 如果放在~/.gitignore家目录下, 则对所有的项目都起作用,
- 放在 当前项目的 .git/info/exclude文件中.对当前项目起作用? 应该就是针对 跟 .git平级的 那些文件和目录. 注意, 在写文件或目录的时候, 虽然是在.git//info/exclude目录下, 但是你针对的 相对目录是 跟版本库 .git相 平级的 同一个位置 下的 视觉 而言的 ....
- 还可以放在当前项目下的, 某些子目录中, 在这些子目录中创建文件 .gitignore忽略文件, 则对该子目录下 的文件和目录起作用.., 如果是在根目录下手动创建 .gitignore配置文件, 根在 .git/info/exclude文件中配置就是 等效果的 !
一定要注意的是, 忽略文件最好要在 项目 一开始就配置, 在第一次add, push, commit之前就配置, 否则会由很多麻烦, 如果在配置忽略文件前就把某些要ignore的文件提交到 index了, 可以使用 git rm --cached
git 软件在存放和 写入某些 "管理性"的文件时, 会在自己的 系统中进行 管理和记录. 他自己会知道的. 同时, 他自己会去找, 自己会去读, 只要你不去 乱删 乱改就行!
软件的思想和架构?
什么叫软件. 就是通过程序对文件系统进行管理的东西. 因此, 你要写一个软件, 通常要包含两个部分: 一个是 用来解释, 编译, 处理代码的部分, 这个通常称为 "解释器, 编译器 引擎", 实际上他们也是以文件代码的形式存在的, 在运行他们的时候, 就载入到内存进行 工作. 另一个部分就是 用来存储, 处理, 记录 前面那个 引擎要处理 作用 的内容, 档案, 文件, 目录, 数据库等等, 这些东西的设计很重要, 并不一定是以单个文件的形式存在的, 很多时候, 比如数据库, 为了增加安全性, 通常是很多文件, 共同作用, 相互作用, 甚至是分布在各个不同的地方, 不同的文件目录结构中.
前面的引擎 会对后面的 "记录"结构 进行各种各杨的 操作: 如写入,读取, 如增删改查, 等等. 都是由 其内部自己来实现的. 所以有些文件, 东西, 你不能 乱删. 否则, 程序可能就会 因为某些 配置文件, 某些记录文件不存在, 无法读取 而down.
这就如同家庭主妇在厨房中做饭炒菜一样, 家庭主妇是 前者"解释器,编译器, 引擎", 他知道所有的一切 工具/佐料 在哪里, 应该怎样使用, 而只有主妇, 也不能作出饭菜来的, 还必须有 后面哪一部分: 文件目录结构 - 厨房的 炊具, 锅盆, 米菜等. 这些东西就是用来记录 存储的东西, 供前者来 操作 使用的!
总之, 由主妇和厨房中的哪些东西, 一起, 构成整个 "程序", "软件", 由 主妇"引擎" 对炊具米菜进行操作 就作出可口的 程序饭菜来了.
而实际我们开发的东西, 通常都没有去 自己 "做" 工具,自己作 "引擎". 而是由别人把 工具引擎写好了的 , 如: php, mysql, httpd等等这些, 都是由牛人 写好的, 而我们字是去 使用, 使用工具, 然后自己去创建 后者, 存储东西的 文件/目录结构. 这个就是应用程序, 而前者就叫做 系统软件.
yacc: yet another compiler compiler 和lisp 用来写编译器, 不好用? 就自己写一个 gimp! yacc是 用来写词法analyzer 和语法分析Parse 的语言.
Backus john & naur, 前者设计了ibm的 fortran语言(formula translation: 公式翻译器), 他们在lisp的设计中,提出了 使用符号形式来 表示 编译器的语法的 概念.这个叫做 BNF 叫做: 巴克斯範式.巴科斯范式.
如果只是针对某一个项目的配置, 则不加 --global选项..
linux的参数和选项的区别?
参数是命令直接 作用的对象, 选项是用来说明命令执行/表达的方式, 形式, 条件等.
参数是可以变化的, 而选项通常是固定的那几个
参数不带前导的-或--, 选项要用前导符. **linux的思维方式: 参数不用逗号分隔, 用空格来分隔多个参数: commit file1 file2 -m "提交详细描述信息..."
git的add和commit? add是将要提交的文件加入"索引"中, 而commit是正式提交到版本库中. 这里就有一个"缓冲", 可以在add后, 还可以 去掉某些文件, 不进行commit...
查看系统信息的命令: 查看主板: lspci (-v), 查看内存和cpu: cat /proc/meminfo, cat /proc/cpuinfo. 查看硬盘使用信息: fdisk -l, df等
有一个统一的命令来查看系统信息: dmidecode: http://www.aichengxu.com/view/6209792
dmidecode = dmi - decode. dmi: desktop management interface. 桌面管理接口, 帮助收集系统固件信息的工具程序. decode用可读的方式 显示 dmi数据库中的信息. 前三行是 记录头: record head(handle 0x0002记录的id, dmi type 2(typeid), bytes记录的字节数...), 后面是记录详细信息
该命令默认的会显示所有硬件信息, -t指定显示硬件 的类型. 如: dmidecode -t memory.... (dmidecode是linux下一个命令, 用法跟其他命令类似...)
可以使用选项,也可以用grep来过滤信息...
笔记本在安静的场合发出 兹兹的声音, 是硬盘的 磁头 "寻道" 读写 硬盘的声音, 正常的? 要安静, 换固体硬盘.
git 中的术语和作用
status 要常用, 用它来查看 工作区, 暂存区, 和 版本库等状态;
log要常用, 用它来查看 提交的 历史记录, 提交会产生一个提交名称, 是git自动生成的一个sha-1码, 用这个提交名称来跟踪 提交, 保证每次提交的名称都是独一无二的, 使用git log -Number, 来限制查看 "提交"日至的个数
checkout的使用 , 一是用来 切换分支; 二是用来 "捡出"暂存区和版本库中等内容 到-> 工作区/暂存区... 这个操作是比较危险的..., 会放弃丢失工作区或暂存区的更改 (但是这个功能确实是很强大的, 在修改后, 关机后, 按平常的话, 你是恢复不了, 找不回原来的代码了, 但是我通过checkout --
通常, 创建版本库, 就放在你经常使用, 编写代码的目录中, 比如在php html开发中, 就经常是在 /var/www/html目录下工作, 就可以在这个目录下创建版本库. 这个就是 git的分布式版本库 的含义: ta 可以在 任何一个目录下 进行版本管理和控制, 在一个电脑中, 你可以创建多个 开发工作目录, 每个目录都可以创建一个版本库.... . 版本库和 工作目录 通常是 在 同一个目录下, 也就是 : .git 和 工作目录下的 文件是在 同一个位置的. 同样 可以 认为 /var/www/html 也就是 版本库的 目录, 因为 .git在 html目录下.
git的版本库, 是放在工作目录下的, 跟工作目录中的实际内容: 文件/数据等, 放在同一个平级的地方, 他才能狗管理 , 识别到这些文件...

git 命令的语法, 同样遵守 linux命令的选项格式: 对于长单词选项,还是 用 -- 这种gnu格式, 对于短选项, 用- 这种unix格式
linux基本上所有配置文件中的 注释comment, 都是用 # 或 ; 来开头表示的...
git config : key does not contain a section?

说明, 在配置 git config的时候, 要指定 section, 也就是类似于 windows的 ini文件中 等 [core]样式的 section.
因此, 就不能直接写 git config username "foo" 因为没有指名 section, 而使得git不知道 怎样写 section. 要指名section."key"...
配置 当前项目内生效的 用户信息, 使用 --local选项 或 不加 任何选项. 这时候添加的 配置信息, 都会 "追加"到 .git下的 config文件中
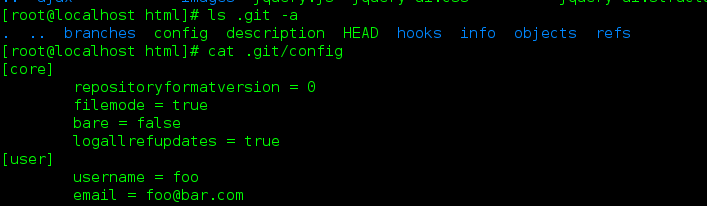
全局配置的 用户信息 , 会在用户 的 主目录中 添加 文件: .gitconfig , 如果再次定义 会重复覆盖 前面等用户信息设置..
在最开始的时候, 在没有git add的时候, 这个时候 是没有 暂存区的, 没有什么 index文件的! objects 也是空的!! 一旦你执行了git add... 命令后, 就创建了 index暂存区, 就会由两个东西来 表达暂存区: index文件(注意是文件, 不是目录!) , objects下的文件夹和目录. (objects就是 存放了真的提交到 暂存区 的 文件的 内容信息 ..). index文件和 objects文件都是 不可读的! 应该是 什么 sha-1...
HEAD 是一个指向 master分支的 常量, 这个文件的内容是: ref: refs/heads/master... 因为是常量, 所以要大写
git的很多命令, 包括stauts, log, add, commit等, 都要求在 must be run in a work tree. 工作树目录中 运行

当提交一次后, 生成, 新创建了: logs目录, 和 COMMIT_EDITMSG 文件(其中记录的是提交时的 备注信息). 其中, logs下的 HEAD 文件,指向了 logs/refs/heads/master. 两者的内容是一样的, 可以认为: 这里 的HEAD 就是 指向 logs/refs/heads/master的硬链接. 同样的 , .git下的 HEAD文件也应该是 指向 .git/refs/heads/master的硬连接.

一旦加入了git被 tracked , 文件修改时, git就能 "侦测"到, 然后作出提示
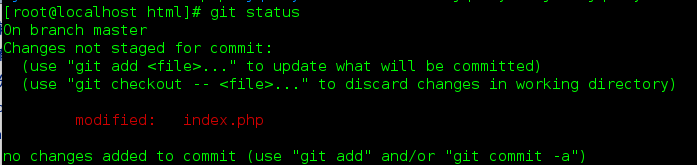
使用git, 就要用git的方式来管理项目和项目中的文件, 用他的命令, 来作. 计算机软件, 跟机器i一样, 也有一个 容错度, 你最好还是不要乱搞, 乱操作, 机器乱操作, 会把机器打坏, 特别是一些精密机器, 更是要仔细细心的操作, 否则错误操作, 可能造成 不可恢复的 损失... 所以, 人类造的东西, 不是像神的东西, 乱操作都没有问题, 没有那么神的!! 像 git的操作, 你乱搞, 有可能把 版本库 搞坏. 造成数据的丢失!!
git status -s?
注意这个单词, 是 status, 容易误写成 stauts..
后面的 -s, 是output的格式: --long: give the output in the long-format. this is the default. -s and --short is that give the output in the short-format. 用简短的格式 进行输出...
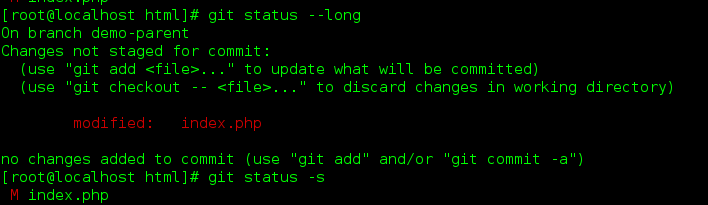
当提交后, 会生成提交 总结:

1 file changed. 27 insertions(+), 29 deletions(-): rewrite index.php 88%:
表示: 插入了 27行, 删除了29行... 重写率 88%.
stash: stage -> stash:
n. 隐藏物(赃物): the two crooks took turns counting their stash
隐藏处: a stash of liquor.
v. 藏匿, 隐藏: i secretly stash away some money.
当我们在切换分支的时候, git checkout branch-another 时, 如果你 没有commit changes, 当切换后, 的分支, 文件的内容会覆盖 同名的文件时, 会报错, 这是git 保护 文件资料的 机制, 会放弃 aborting , 会提示你 提交变化, 或 隐藏/储藏变化(stash changes: 就是放弃修改, 或用 index/ repo来覆盖当前文件....): Please, commit your changes or stash them before you can switch branches. Aborting!

当git checkout feature-branch 时, 会用branchname中的文件替换staging和working area中的同名文件吗 ??? YES!
下面是 git checkout --help的内容:
sy'nopsis: 复数形式: synopses , 提纲, 总领, 不是 syntax + options...
datum: 数据的单数形式
plural: [plu:r2l] 复数 : data is a plural form of datum.
iss53: 53号问题.
git checkout -b iss53: 实际上是两个命令的合成: git branch iss53; git checkout iss53.
这个是csdn上的文章:http://blog.csdn.net/csfreebird/article/details/7992164 , 说的是, 开发版本的常规方法和经验: 不在master上开发, master只是用来合并主线, 开发模块和feature 的时候, 创建 develop -> develop feature 分支, 最后合并到 master上...

每次打开文件时, 在文件底部的状态栏上提示的是: 文件名, 行数, 字符数(500C : charaters) written.

关于git仓库和暂存区的理解
1, git clone和git init的区别?
当本地没有仓库的时候, 可以整个 的 将git项目拷贝 下来, 包括里面的日志信息, 和分支信息等等, 你可以直接使用这些分支进行继续开发...
(查看一下 bundle中的 项目的 分支 、提交情况)
如果本地有 工作区, 要进行本地的代码 开发, 就用git init。
- git push和 pull的区别?
push和pull是本地仓库,和远程仓库之间的代码推送。 两个仓库之间的地位是平等的, 不像工作区和本地仓库之间是 commit的关系. push是把本地仓库的代码, 传到 "线上" 远程仓库去.
git pull = git fetch + git merge; 从远程仓库获取最新更新代码, 然后, 和本地代码进行合并
- 工作区和仓库的关系?
从 "工作区" 和 "仓库"的命名, 也可以形象地比喻理解 源代码和仓库的 关系:
工作区, 就好比我们在院子里 打谷子, 打麦子的工作一样,
仓库, 这里是指 "代码仓库 code repo", 就好比 我们 装 麦子, 装谷子的 仓库一样.
打谷子麦子的过程: 我们打好了谷子,麦子, 得把它们放到仓库中去, 保存 储藏, statsh, 才能保存这些粮食,供以后的日子吃. 没有看到哪个, 把谷子打好了, 收好了, 辛辛苦苦的, 然后, 却不管, 就乱仍在院子地坝里的. 这样 的话,你的粮食就很可能 被破坏, 遭受很多的风险.
写代码项目的过程: 如同打谷子麦子的情况一样, 我们辛辛苦苦的把代码写好了, 那么多的项目文件, 你不提交到仓库中去, 就随便的散乱的放在 文件夹中, 这就如同把谷子打好了, 却不放到仓库里去是一样的! 很危险的, 代码随时都可能面临 "丢失, 删除, 错误, 打不开"等等风险和危险. 所以, 我们要把这些代码 放到 "提交到 commit"到 我们的 code repo代码仓库中 去。 这样 才能保证代码的安全.
而且放到仓库中去, 这个也是一门学问. 如同我们的粮食放到仓库中去,并不是各种粮食, 谷子, 麦子, 玉米什么的全都 混合在一起, 乱装乱放, 那以后也没有办法吃啊, 所以 对仓库的管理 也是一门学问, 也要通过git, svn这些工具 才能把仓库 分门别类的, 历史完整的 保管好.
git init和git init --bare的区别?
git init 是在本地进行项目开发. 包括版本库和工作区的源代码(文件和目录等)
而, 如果我们要创建的仓库, 不是为了源代码的开发, 只是为了 和其他团队开发者, 共享这些代码, 那么就没有必要使用git init去创建包含源码的 working repo了, 直接使用 git init --bare 去创建一个 共享仓库 sharing reop, bare repo.git是什么时候知道 工作区的代码发生了改变的?
情景: 当使用git status -s 的时候, 提示“M index.php", git是怎样知道变化的?
answer: git并不会每时每刻的,去查看,检查,扫描代码的改变。 正是在 执行这个命令 git status的时候, git会去检查(扫描工作区中的所有标记为 "被tracked" 的文件和目录) 工作区中的文件 是否改变了. 检查的过程是: 查看工作区文件的时间戳, 长度, 所有者等这些文件的 meta 元信息, 和 index stage暂存区中保持的文件的 这些信息, 相比较, 如果没有变化(时间戳不是 随自然时间的流逝而改变的), 就不跟踪, 不报告. 如果这些meta信息有变化, 再 调取 objects对象库中的文件的内容, 和现在的源码来进行比较.
因为, 判断文件是否改变, 不是直接 的: "调取 objects对象库中的文件的内容, 和现在的源码来进行比较", 所以git的效率比svn的效率要高, 这 也是暂存区 的主要作用.如何理解暂存区?
暂存区, 相当于在将谷子麦子放入到仓库之前, 为了今后便于管理, 为了便于比较, 扫描,判断 院子中地坝中的 谷子麦子的收割情况 的变化, 提高工作效率, 不用每次都跑到仓库里面去看, 所以在 粮食放入到仓库之前, 会事先做一些登记.比如时间戳, 文件的属性, 长度,字符数等等. 根据这些来 提高管理效果...git archive?
要将git中的内容打包 需要使用git archive.
archive --format=tar包或 --format=zip
archive --prefix=/opt/...指明保持位置.
git archive --format=tar --prefix=/opt/myproj1/ 1.0 | gzip > myproj1.tar.gz
git archive --format=zip --prefix=/opt/myporj2/ 2.0 > myproj2.zipgit的diff命令
可以使用diff比较三个区域的不同: (三个区域A B, C, 只有3种 两两组合)
git diff 是比较工作区和暂存区的区别;
git diff --cached 是比较暂存区和版本库之间的区别;
git diff HEAD 是比较工作去和版本库之间的区别git reset和 revert的区别?
reset和revert都是用来回退 , 回滚的:
reset, 主要用在 代码未被push到线上 仓库(远程仓库)的时候, revert是用在 当代码, 被push到远程仓库后, 将线上和线下的仓库中的代码都 回滚到 某一次commit时的 状态..
git reset (参数有: --soft, --mixed, --hard) 三者依次回滚的程度增大.., 依次回滚 ->最开始回滚的是 commit信息, -> 然后回滚的是index区域, 最后混滚的是 working tree. 这里的--soft等 称之为
--soft, 只是回滚commit提交信息, 暂存区和工作区的代码不改变, 可以再次用commit直接提交;
--mixed, 回滚 commit和index的信息 , 工作区的代码改变 不混滚. 默认的 git reset就是 回滚这个 --mixed
--hard, 混滚从commit到 工作区的代码..
revert的回滚:
实际上准确的说, 这个不叫 "hungun", 因为它也是 一次 commit, 只不过 它commit的是, 以前的某个版本. 也就是说, 他用之前 的某个版本 的提交, 使本地和远程的版本库都回到 了之前的某个状态.., 重新又回到了之前的某个状态, 这个正是 "revert"单词 的含义 "重提, 重新回到"
准确的说, reset才是 真的 回滚. 当reset到某个之前的某个版本库的commit状态时, 他是真的要删除 返回的版本库 状态点, 之后的提交, master分支的HEAD指针是要向后移动的. 而revert的指针是一直向前的.
比如说, 提交历史: C0->C1->C2->C3, 现在HEAD指向c3, 如果用 git reset --mixed c1 那么c2, c3的提交都将被删除 , 然后 HEAD指向C1. 如果git revert C1, 则现在的提交树将是: C0->C1->C2->C3->C1(<= HEAD) .
删除暂存区的目录文件?
git rm --cached
关于diff?
diff是differ的形式, 叫"区别, 找出不同", differ的形容词叫: differ -ent.
单纯的, 任意两个, 不相关的文件来diff, 是没有意义的! diff主要是用来区分 同一个 开发 文件的不同版本 之间的区别, 查看版本间 前后增删 改动的情况. 是为 开发, 管理 版本间的文件 , 修改文件而用的, 据说linus 用了10 年diff, 然后写出了git. 所以 diff是git中非常重要的命令
diff [options] file1 file2 中的选项:
- 两个文件中, 凡是相同的 行, 都不会 显示出来
diff的显示结果的几种模式: --normal模式, 使用 d/ a/ c/ 来表示变化的行(diff是 line by line的比较, 然后判断)
d: delete, a: add, c: change .
当然比较文件的 先后位置颠倒, 结果也会不同. ( 见下图)
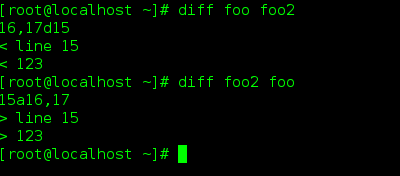
diff 参数-s 等于 --report-identical-files 这是报告文件是否是相同的 , 同样还有一个 -q == --brief, 它是报告文件是否不同, 只是报告不同,并不显示哪些差别.
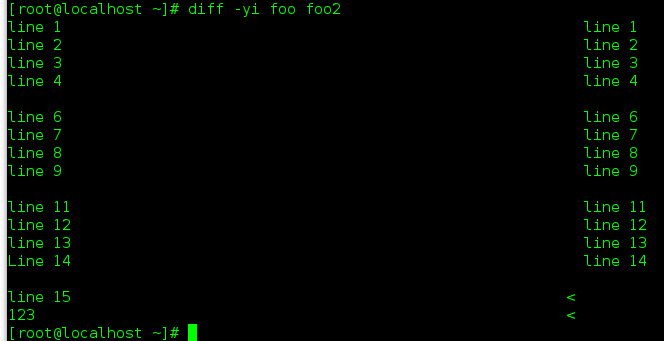
diff 显示结果的另外一种方式: -y === --side by side, 并排显示. 还可以指定 -W 宽度...
在用side by side方式显示时, 其中 | 表示 normal方式的change, 参数 -i 表示忽略大小写 : ignore (见下图)
- 关于文件中的空格, 比较选项, 有-w(忽略所有空格, 包括单词内部的空格), -B(忽略空行), -b(忽略单词和单词之间的空格),
linux中命令的选项, 位置, 有的可以放在 "紧接着" 命令的后面, 有的还可以放在最后, 即使 usage 说明文档说了是放在 命令名紧接着的后面, 实际使用中, 有的也可以放在 命令行内容的最后, 这个不用太计较. 实际上, 因为选项都是以 短线 - , 或 --开头的, 所以选项放在不同的位置, 是能够被 linux所识别的...
bin和sbin都是保存命令的目录,即里面保存的都是Linux的命令。区别是bin保存的任何用户 都可使用,而sbin保存的命令只有超级用户才可使用。需要注意的是usr目录下存在bin和sbin目录,这和一级目录bin和sbin的作用是一样的。
ll 下的信息?
记录的时间是: 文件被最后修改的时间. 这个时间可以看作是时间戳, 这个对于文件, 对于编译器才是 有意义的, 其实, 记录访问时间是没有 意义的...访问时间随时都在变,
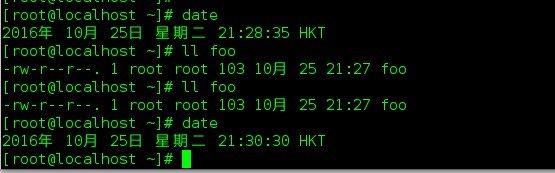
ll -Z 会列出文件的selinux属性 http://blog.csdn.net/xinlongabc/article/details/46801641
- 如果只有selinux 安全上下文, 没有其他访问控制, 如acl, 则只有一个点号表示
- 如果有selinux 或 acl等安全访问控制时, 用+号表示 (只要有acl都会用+ 表示);
如果selinux和acl都没有, 用空格表示. "看起来什么的哦没有"

inode和block的区别, 硬链接和软链接的区别? http://www.cnblogs.com/fuly550871915/p/4954024.html
不管是如软链接还是 硬链接, 都是链接, 因此 都有相同的功效: 修改任意一个 , 其他的另一个的访问 内容 也跟着变化...
不管时linux还是windows, 使用磁盘时, 首先要分区, 也就是按照 你的使用目的, 功能, 划分出多个区域. 如同一套房屋, 你得要划分出客厅, 卧室, 厨房等分区. 然后在每个分区中, 还要格式化(用来存储数据): 格式化作两件事: 一是将分区划成 许多 等大小的 数据块, 一个块叫做block, 这些块是实际存放数据内容的地方. 也就是我们常说的1KB, 4KB... 二是, 创建一个分区表, 用来记录存储文件的 meta数据. 相当于一个 保管员, 一个记账 的会计... 来记录 哪些文件 存放在 分区中的 哪些 blocks中. 分区表中, 每条记录就 是 一个文件的 inode记录, inode记录(就是文件的meta元信息) 包括了: 文件名, 对应的inode号(inode号主要是为了 从 文件名称 -> 查找到 分区表中的 记录, 找到 文件名对应的记录, inode号就相当于 数据库中数据表的 记录id, 根据文件名查找 inode号的工作, 是由linux命令ll , ls去作的, 当执行ls等命令的时候, 系统就会根据 "文件名" 去到 分区表中 去查找 定位 记录...., 因为一个文件名就对应着一个inode号...), 文件的大小, ctime, mtime , atime时间戳, 存储数据的block块的序号等... 然后系统根据blocks序号去分区中取出 实际的数据内容进行操纵...
硬链接, 多个文件的inode是一样的, 所以 , 相当于 一个教室有前后(设置中间)多个门, 每个门都是一个 硬链接, 这些门都可以进入这个教室, 删除关闭一个门, 其他门还是可以进入教室的, 这个根硬链接完全是一样的. 同样的 , 硬链接不能跨分区的, 如同教室的门不能在 不同的 楼层一样..
软链接, 是一个独立的文件, 它有自己的inode, 根链接对象的inode 就不一样, 只是, 软链接的 block中 存放的内容是 它链接的 target文件名和inode...
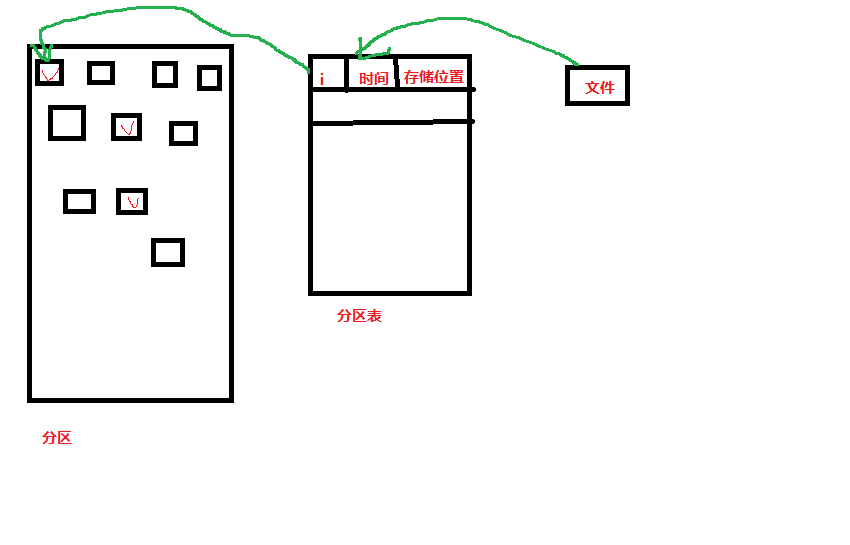
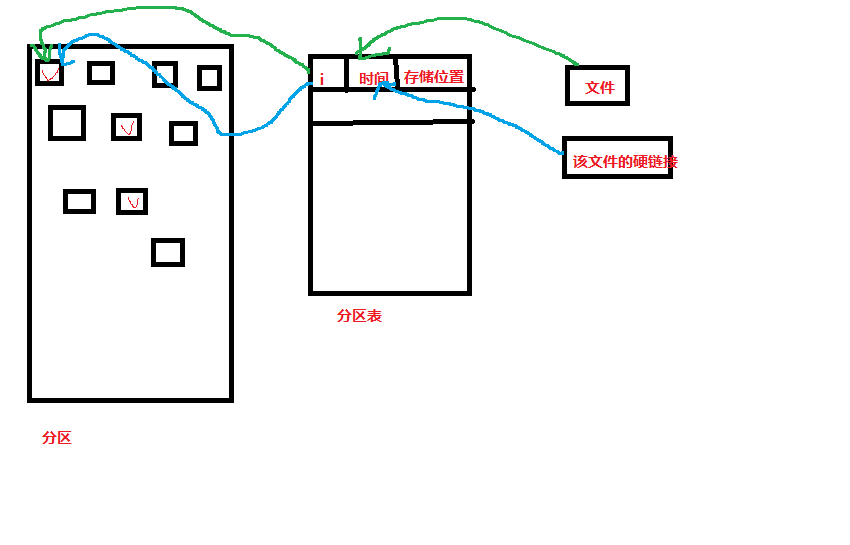
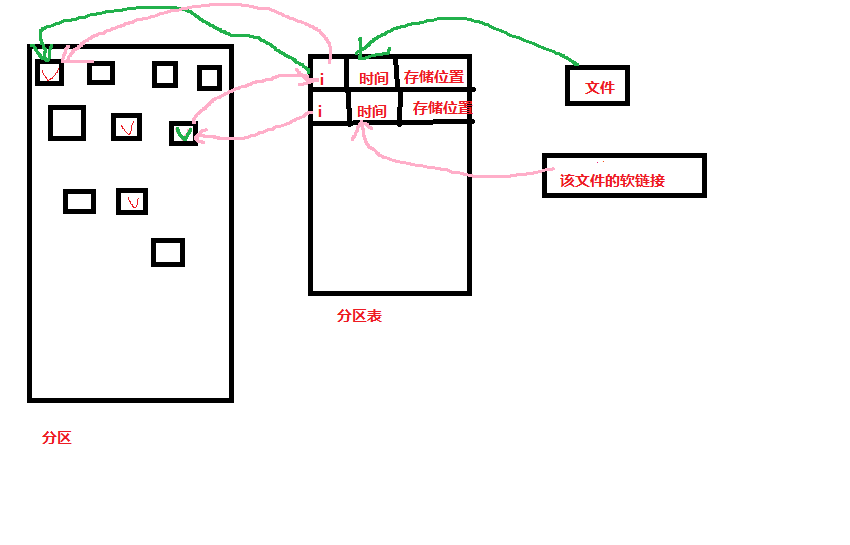
linux中 的一个基本思想: 在管理文件, 目录, 版本库等等, 所有需要管理的东西的时候, 都创建了一个 "中间层", 一个 "索引", (文件索引 => 分区表, 版本库的索引=> stage 暂存区...), 用来记录那些 要管理, 要存储的 实体数据的meta信息..., 并不是 一开始 就直接 来 操纵 那些实体的东西, 以便于 提高效率!
https://www.cnhzz.com/inode-block/: 一个inode, 是硬盘的分区 格式化后, 在分区表 中 记录一个文件的meta信息的 一行 信息记录 . 包括 inode节点号, 文件的ctime mtime atime时间戳, 存储数据的 block块的编号...
inode是记录元信息的, 而block是实际存储数据的位置...
ll返回的结果中, 链接数是指的 软链接数, 还是 硬链接数?
ll的帮助文档, 明确的指出, 其中的链接数, 是指的 硬链接数, 是指的 指向 同一个inode的文件的个数.
而文件的软链接, 它们是两个 不同的 inode号.
所以 , 列出 软链接 是没有意义的...
有几个以 d 开头的常用命令, du, df等, 其实打d, 然后tab, 会列出所有以d开头的命令...
git项目开发版本控制实践的更多相关文章
- 项目开发版本控制----Git
版本控制的工具我早之前用的svn,后来换成了git.同样是版本控制,为什么要换呢?肯定是有原因的啦~ 一.Git和SVN的比较 svn的优缺点 优点: 1.管理方便,逻辑明确,符合一般人思维习惯. 2 ...
- 个人项目开发PSP实践-MyWCprj
MyWCprj.exe Github仓库地址 1. What is MyWCprj.exe? wc是linux下一个非常好用的代码统计小工具,可以通过 -c .-w .-l等选项分别进行对指定文件的代 ...
- git -- 项目开发最常用操作记录
官方Git - Book https://git-scm.com/book/zh/v2 ------------------------------git配置以及公钥生成--------------- ...
- 团队项目开发中,常见的版本控制有svn,git
团队项目开发中,常见的版本控制有svn,git
- iOS开发——源代码管理——git(分布式版本控制和集中式版本控制对比,git和SVN对比,git常用指令,搭建GitHub远程仓库,搭建oschina远程仓库 )
一.git简介 什么是git? git是一款开源的分布式版本控制工具 在世界上所有的分布式版本控制工具中,git是最快.最简单.最流行的 git的起源 作者是Linux之父:Linus Bened ...
- Git项目协同开发学习笔记1:项目库开发基础git命令
这年头git基本都是项目开发的标配,之前刚好碰到了就花了两天时间系统学习了下.本文内容基本来自以下tutorial:Learn Git(建议直接去看原文,因为这个网站是有更新的).这个是我看过对git ...
- 项目开发中git常用命令、git工作流、git分支模型
#新建代码库git init # 在当前目录新建一个Git代码库git init [project-name] # 新建一个目录,将其初始化为Git代码库git clone [url] # 下载一个项 ...
- 使用 Git 命令去管理项目的版本控制(一)
参考资料:参考 参考 声明本文是作者原创,是自己的学习笔记,仅供学习参考. 在 10.11.2Mac系统中,要显示隐藏的文件夹使用命令行: defaults write com.apple.find ...
- Git工程开发实践(四)——Git分支管理策略
A successful Git branching model https://nvie.com/posts/a-successful-git-branching-model/ Git工程开发实践( ...
随机推荐
- IOS开发中UI编写方式——code vs. xib vs.StoryBoard
最近接触了几个刚入门的iOS学习者,他们之中存在一个普遍和困惑和疑问,就是应该如何制作UI界面.iOS应用是非常重视用户体验的,可以说绝大多数的应用成功与否与交互设计以及UI是否漂亮易用有着非常大的关 ...
- ping: icmp open socket: Operation not permitted的解决办法
这个是root权限造成的,我们从 ls -l /bin/ping 可以看出 指向了root用户. 那么我们在使用时,有如下操作: 1.直接在前面加sudo sudo ping 192.168.199. ...
- Bzoj1449 [JSOI2009]球队收益
Time Limit: 5 Sec Memory Limit: 64 MBSubmit: 741 Solved: 423 Description Input Output 一个整数表示联盟里所有球 ...
- PHP Lex Engine Sourcecode Analysis(undone)
catalog . PHP词法解析引擎Lex简介 . PHP标签解析 1. PHP词法解析引擎Lex简介 Relevant Link: 2. PHP标签解析 \php-5.4.41\Zend\zend ...
- iptables实现正向代理
拓扑图 实现目标 内网用户通过Firewall服务器(iptables实现)访问外网http服务 配置 #iptables iptables -t nat -A POSTROUTING -i eth0 ...
- C#和Javascript的try…catch…finally的一点差别
C#中规定:如果程序的控制流进入了一个带finally块的try语句,那么finally语句块始终会被执行 例子: class Program { static void Main(string[] ...
- A.Kaw矩阵代数初步学习笔记 1. Introduction
“矩阵代数初步”(Introduction to MATRIX ALGEBRA)课程由Prof. A.K.Kaw(University of South Florida)设计并讲授. PDF格式学习笔 ...
- HDU 5920 Ugly Problem
说起这道题, 真是一把辛酸泪. 题意 将一个正整数 \(n(\le 10^{1000})\) 分解成不超过50个回文数的和. 做法 构造. 队友UHC提出的一种构造方法, 写起来比较方便一些, 而且比 ...
- POJ 3468 A Simple Problem with Integers(线段树/区间更新)
题目链接: 传送门 A Simple Problem with Integers Time Limit: 5000MS Memory Limit: 131072K Description Yo ...
- Theano tutorial – basic type
博客摘自:Deep learning 第二篇 婴儿学步 Theano如何做算数? import theano.tensor as T from theano import function x=T.d ...