sql学习笔记--存储过程
存储过程(stored procedure)有时也称sproc,它是真正的脚本,更准确地说,它是批处理(batch),但都不是很确切,它存储与数据库而不是单独的文件中。
存储过程中有输入参数,输出参数以及返回值等。
一、创建存储过程
创建存储过程的方法和创建数据库中任何其他对象一样,除了他使用AS关键字外。存储过程的基本语法如下:

CREATE PROCEDURE|PROC <sproc name>
[<parameter name> [schema.] <data type> [VARYING] [=<default value>] [OUT[PUT]] [READONLY]
[,<parameter name> [schema.] <data type> [VARYING] [=<default value>] [OUT[PUT]] [READONLY]
[,...
...
]]
[WITH
RECOMPILE | ENCRYPTION | [EXECUTE AS { CALLER | SELF | OWNER | <'user name'>}]
AS
<code> | EXTERNAL NAME <assembly name>.<assembly class>.<method>
在语法中,PROC是PROCEDURE的缩写,两个选项的意思一样。
在对存储过程命名完之后,接着是参数列表。参数是可选的。
关键字AS其后就是实际的代码。
简单的存储过程示例:
CREATE PROC spPerson
AS
SELECT * FROM Person
执行存储过程:
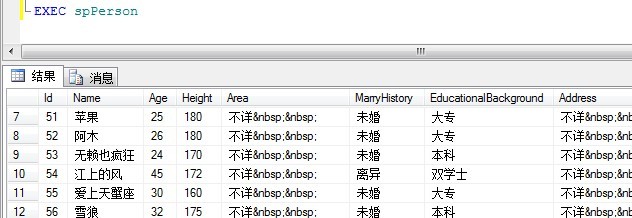
EXEC spPerson
查看结果:
二、ALTER修改存储过程
ALTER PROC和CREATE PROC的区别如下:
- ALTER PROC期望找到一个已有的存储过程,而CREATE则不是。
- ALTER PROC保留了存储过程上已经建立的任何权限。它在系统对象中保留了对象Id并允许保留依赖关系。例如,如果过程A调用过程B,如果删除并重建B,那么就不能在看到这两者间的依赖关系。如果使用ALTER,则依赖关系仍然存在。
- ALTER PROC在可能调用被修改的存储过程的其他对象上保留了任何依赖信息。
示例:
ALTER PROC spPerson
AS
SELECT * FROM Person WHERE Id = 45
三、删除存储过程
删除存储过程的语法最简单:
DROP PROC|PROCEDURE <sproc name>[;]
这样就完成了存储过程的删除。
四、参数化
如果存储过程没有办法接受一些数据,告诉其要完成的任务,则在大多数情况下,存储过程不会有太大帮助。例如,要删除一条数据,但却不指定Id,则存储过程也不知道要删除哪条,所以使用输入参数非常有必要。
1、声明参数
声明参数需要以下2到4部分的信息:
- 名称
- 数据类型
- 默认值
- 方向
其语法如下所示:
@parameter_name [AS] datatype [=default|NULL] [VARYING] [OUTPUT | OUT]
对于名称,有一组简单的规则。首先,它必须以@符号(和变量一样)开始。此外,除了不能内嵌空格外,其规则与普通变量规则相同。
数据类型和名称一样,必须像变量那样声明,采用SQL Server内置的或用户自定义的数据类型。
声明需要类型时需要注意,当声明CURSOR类型参数时,必须也使用VARYING和OUTPUT选项。同时,OUTPUT可以简写为OUT。
在默认值方面,参数与变量不同。对于同样的情况,变量一般初始化为NULL值,而参数不是。事实上,如果不提供默认则,则会假设参数是必须的,并且当调用存储过程时需要提供一个初始值。
一个需要传入参数的存储过程示例:
CREATE PROC spName
@Name nvarchar(50)
AS
SELECT Name FROM Person
WHERE Name LIKE @Name + '%';
执行存储过程:
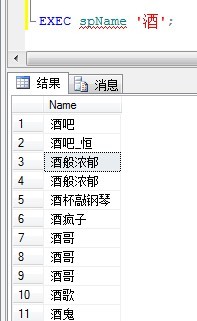
EXEC spName '酒';
显示结果如下:
2、提供默认值
为了使参数是可选的,必须提供默认值。方法是在数据类型后在逗号之前添加"="符号和作为默认值的值。这样,存储过程的用户尅有决定对此参数不提供值或是提供他们自己的值。
创建一个存储过程如下:
CREATE PROC spName
@Name nvarchar(50) = NULL
AS
IF @Name IS NOT NULL
SELECT * FROM Person WHERE NAME = @Name
ELSE
SELECT * FROM Person WHERE Id = 45
执行如下语句:
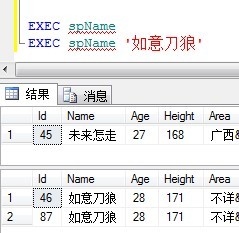
EXEC spName
EXEC spName '如意刀狼'
输出结果如下:
3、输出参数
下面来看看一个获得OUTPUT参数的存储过程:
CREATE PROC InsertPerson
@Id int OUTPUT --必须注明为OUTPUT
AS
INSERT INTO Person
VALUES('刘备',22,190,'不详','未婚','幼儿园','不详',4999999)
SET @Id = @@IDENTITY
执行存储过程:
DECLARE @Id int --实际上,调用时名称可以不同,例如也可以为@Num,@i等等。
EXEC InsertPerson @Id OUTPUT --注意此处也要有OUTPUT
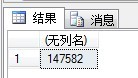
SELECT @Id
显示结果如下:
对于存储过程本身以及调用脚本对它的使用,需要注意以下几点:
- 对于存储过程声明中的输出参数,需要使用OUTPUT关键字。
- 和声明存储过程时一样,调用存储过程时,必须使用OUTPUT关键字。这样就对SQL Server作了提前通知,告诉它参数所需要的特殊处理。但需要注意的是,如果忘记包含OUTPUT关键字,不会产生运行时错误,但是输出的值不会传入变量中(变量很可能是NULL)。
- 赋值给输出结果的变量不需要和存储过程中的内部参数拥有相同的名称。
- EXEC(或EXECUTE)关键字是必须的,因为对存储过程的调用并不是批处理要做的第一件事(如果存储过程的调用是批处理的第一件事,则可以不使用EXEC)。
五、返回值
返回值的用途非常广泛,例如,返回数据,标识值或是存储过程影响的行数等等。而其实际作用是返回值可用来确定存储过程执行的状态。
事实上,不管是否提供返回值,程序都会收到一个返回值。SQL Server默认会在完成存储过程时自动返回一个0值。
为了从存储过程向调用代码传递返回值,只需要使用RETURN语句。
RETURN [<integer value to return>]
要特别注意的是:返回值必须是整数。
关于RETURN语句,最重要的是知道它是无条件地从存储过程中退出的。无论运行到存储过程的哪个位置,在调用RETURN语句之后将不会执行任何一行代码。
这里的无条件,并不是说无论执行到代码的何处都将执行RETURN语句。相反,可以再存储过程中有多个RETURN语句。只有当代码的标准条件结构发出命令的时候,才会执行这些RETURN语句。一旦发生,就不能再退回了。
创建一个存储过程如下:
CREATE PROC spTestReturns
AS
DECLARE @MyMessage nvarchar(50);
DECLARE @MyOtherMessage nvarchar(50); SELECT @MyMessage = '第一个RETURN';
PRINT @MyMessage;
RETURN; SELECT @MyOtherMessage = '第二个RETURN';
PRINT @MyOtherMessage;
RETURN;
执行存储过程,输出如下:

为了能捕获RETURN语句的值,需要在EXEC语句中把值赋给变量。例如:
DECLARE @Return int
EXEC @Return = spTestReturns
SELECT @Return
输出如下:
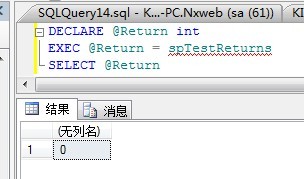
虽然简单但是还不错。当运行时,可以看到RETURN语句却是在运行其他代码前终止了代码运行。
如果总是返回0,那么执行成不成功都不知道,那么我们现在来改写下上面的存储过程,让其返回一个指定的值,以指示执行状态。
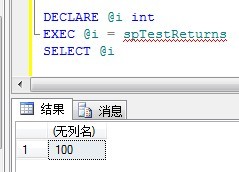
CREATE PROC spTestReturns
AS
DECLARE @MyMessage nvarchar(50);
DECLARE @MyOtherMessage nvarchar(50); SELECT @MyMessage = '第一个RETURN';
PRINT @MyMessage;
RETURN 100; --将这里改成返回100 SELECT @MyOtherMessage = '第二个RETURN';
PRINT @MyOtherMessage;
RETURN;
执行之后,显示结果如下:
六、存储过程的优缺点
存储过程的主要优点包括以下几个方面:
- 使得需要过程式动作的进程可调用
- 安全性
- 性能
1、创建可调用的进程
很多人并没有意识到要充分使用存储过程,使其作为实现安全性的工具。和视图类似,可以创建一个返回记录集的存储过程而不用赋予用户访问底层数据表的权限。赋予某人执行一个存储过程的权限意味着他们可以在该存储过程中执行任何动作。不过要假设动作是在存储过程的上下文中执行的。
2、存储过程和性能
一般来说,存储过程有助于系统性能的提高。但是,如果设计的存储过程缺乏只能,那么它会使在其创建的进程变得非常缓慢。
存储过程的运行示意图如下:

首先运行CREATE PROC过程。这回解析查询以确保会实际运行这些代码。它与直接运行脚本的区别在于CREATE PROC命令可以利用所谓的延迟名称解析。延迟名称解析可以忽略一些对象还不存在的事实。
在创建了存储过程后,它将等待第一次执行。在那时,存储过程被优化,而查询计划被编译并且缓存到系统上。后续几次运行该存储过程时,除非通过使用WITH RECOMPILE选项指定,否则都会使用缓存的查询计划而不是创建一个新的查询计划。这意味着每次使用该存储过程时,存储过程都会跳过很多优化和编译工作。节省的确切时间取决于批处理的复杂性,批处理中表的大小,以及每个表上索引的数量。通常,节省的时间不是很多。但对于大多数场景来说可能是1秒或更少-但通过百分比可以计算出此区别(1秒比2秒快了100%)。当需要进行多次调用时或针对循环的情况,这一区别会变得更明显。
3、存储过程的不利方面
对于存储过程的不利之处要认识到的最重要的一点事,除非手动地干预(使用WITH RECOMPILE选项),否则只会在第一次运行存储过程的时候,或者当查询所涉及的表更新了统计信息时,才对存储过程进行优化。
这种"一次优化,多次使用"的策略节省了存储过程的时间,但是该策略也是一把双刃剑。如果查询是动态的(即是在使用EXEC命令时建立的),那么只会在第一次运行时对存储过程进行优化,但是会发现以后再也不这样了。简而言之,可能会使用错误的计划。
4、WITH RECOMPILE选项
可以利用存储过程提供的安全性代码和代码封装方面的好处,但还是忽略了预编译代码方面的影响。可以回避未使用正确的查询计划的问题,因为可以确保为特定一次运行创建新的计划。方法就是使用WITH RECOMPILE选项。
使用该选项的方式有两种:
1、可以在运行时包含WITH RECOMPILE。
EXEC spMySproc '1/1/2004'
WITH RECOMPILE
这告诉SQL Server抛弃已有的执行计划并且创建一个新的计划-但只是这一次。也就是说,只是这次使用WITH RECOMPILE选项来执行存储过程。
也可以通过在存储过程中包含WITH RECOMPILE选项来使之变得更持久。如果使用这种方式,则在CREATE PROC或ALTER PROC语句中的AS语句前添加WITH RECOMPILE选项即可。
如果通过该选项创建存储过程,那么无论在运行时选择了其他什么选项,每次运行存储过程都会重新编译它。
sql学习笔记--存储过程的更多相关文章
- ORALCE PL/SQL学习笔记
ORALCE PL/SQL学习笔记 详情见自己电脑的备份数据资料
- SQL学习笔记七之MySQL视图、触发器、事务、存储过程、函数
阅读目录 一 视图 二 触发器 三 事务 四 存储过程 五 函数 六 流程控制 一 视图 视图是一个虚拟表(非真实存在),其本质是[根据SQL语句获取动态的数据集,并为其命名],用户使用时只需使用[名 ...
- Oracle之PL/SQL学习笔记
自己在学习Oracle是做的笔记及实验代码记录,内容挺全的,也挺详细,发篇博文分享给需要的朋友,共有1w多字的学习笔记吧.是以前做的,一直在压箱底,今天拿出来整理了一下,给大家分享,有不足之处还望大家 ...
- SQL学习笔记
SQL(Structured Query Language)学习笔记 [TOC] Terminal登录数据库 1.登录mysql -u root -p ; 2.显示所有数据库show database ...
- SQL学习笔记五之MySQL索引原理与慢查询优化
阅读目录 一 介绍 二 索引的原理 三 索引的数据结构 四 聚集索引与辅助索引 五 MySQL索引管理 六 测试索引 七 正确使用索引 八 联合索引与覆盖索引 九 查询优化神器-explain 十 慢 ...
- PL/SQL学习笔记之存储过程
一:PL/SQL的两种子程序 子程序:子程序是执行一个特定功能.任务的程序模块.PL/SQL中有两种子程序:函数 和 过程. 函数:主要用于计算并返回一个值. 过程:没有直接返回值,主要用于执行操 ...
- 1.6(SQL学习笔记)存储过程
一.什么事存储过程 可以将存储过程看做是一组完成某个特定功能的SQL语句的集合. 例如有一个转账功能(A向B转账50),先将账户A中金额扣除50,然后将账户B中金额添加50. 那么我们可以定义一个名为 ...
- PL/SQL学习笔记_03_存储函数与存储过程
ORACLE 提供可以把 PL/SQL 程序存储在数据库中,并可以在任何地方来运行它.这样就叫存储过程或函数. 存储函数:有返回值,创建完成后,通过select function() from dua ...
- [SQL] SQL学习笔记之基础操作
1 SQL介绍 SQL 是用于访问和处理数据库的标准的计算机语言.关于SQL的具体介绍,我们通过回答如下三个问题来进行. SQL 是什么? SQL,指结构化查询语言,全称是 Structured Qu ...
随机推荐
- ionic隐藏tabs方法
<ion-tabs ng-class="{'tabs-item-hide': $root.hideTabs}"> <!-- tabs --> </io ...
- header()相关
header("Content-type: text/html; charset=utf-8"); header("refresh:3;url=biaodan.php?n ...
- JAVA正则表达式:Pattern类与Matcher类详解
java.util.regex是一个用正则表达式所订制的模式来对字符串进行匹配工作的类库包.它包括两个类:Pattern和Matcher Pattern 一个Pattern是一个正则表达式经编译后的表 ...
- (集成电路卡)ID卡
IC卡(intergrated Circuit Card,集成电路卡),又称为智能卡,智慧卡,微电路卡,微芯片卡 等等. 它是将一个微电子芯片嵌入符合ISO 7816标准的卡基中,做成卡片形状. IC ...
- 【GoLang】panic defer recover 深入理解
唉,只能说C程序员可以接受go的错误设计,相比java来说这个设计真的很差劲! 我认为知乎上说的比较中肯的: 1. The key lesson, however, is that errors ar ...
- ORM框架Entity Framework
博客园在推广ORM方面的确做了很大的贡献,很多的程序员开始使用ORM,不用写SQL的喜悦让他们激动不已,可是好景不长,他们很快发现众多的烦恼一个接一个的出现了. 很遗憾,我并不打算在这篇文章中解决这些 ...
- Oracle 与 entity framework 6 的配置,文档
官方文档: http://docs.oracle.com/cd/E56485_01/win.121/e55744/intro001.htm#ODPNT123 Oracle 对 微软 实体框架 EF6 ...
- POJ 2121
http://poj.org/problem?id=2121 一道字符串的转换的题目. 题意:就是把那个英文数字翻译成中文. 思路:首先打表,然后把每一个单独的单词分离出来,在组合相加相乘. #inc ...
- Shell 语法 if 、 case 、for 、 while、 until 、select 、repeat、子函数
if语法 : if [ expression ] then commandselif [ expression2 ] then commandselse commandsfi ...
- Unity3d《Shader篇》Logo闪光特效
Shader "Custom/Flash" { Properties { _MainTex ("Base (RGB)", 2D) = "white&q ...