【hadoop】——window下elicpse连接hadoop集群基础超详细版
1、Hadoop开发环境简介
1.1 Hadoop集群简介
Java版本:jdk-6u31-linux-i586.bin
Linux系统:CentOS6.0
Hadoop版本:hadoop-1.0.0.tar.gz
1.2 Windows开发简介
Java版本:jdk-6u31-windows-i586.exe
Win系统:Windows 7 旗舰版
Eclipse软件:eclipse-jee-indigo-SR1-win32.zip | eclipse-jee-helios-SR2-win32.zip
Hadoop软件:hadoop-1.0.0.tar.gz
Hadoop Eclipse 插件:hadoop-eclipse-plugin-1.0.0.jar
下载地址:http://download.csdn.net/detail/xia520pi/4113746
备注:下面是网上收集的收集的"hadoop-eclipse-plugin-1.0.0.jar",除"版本2.0"是根据"V1.0"按照"常见问题FAQ_1"改的之外,剩余的"V3.0"、"V4.0"和"V5.0"和"V2.0"一样是别人已经弄好的,而且我已经都测试过,没有任何问题,可以放心使用。我们这里选择第"V5.0"使用。记得在使用时重新命名为"hadoop-eclipse-plugin-1.0.0.jar"。
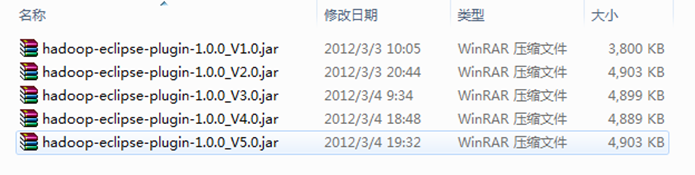
2、Hadoop Eclipse简介和使用
2.0 关闭系统防火墙
1)配置hosts,关闭WINDOW系统防火墙;
2)关闭Linux系统防火墙:
service iptables stop
chkconfig iptables off
2.1 Eclipse插件介绍
Hadoop是一个强大的并行框架,它允许任务在其分布式集群上并行处理。但是编写、调试Hadoop程序都有很大难度。正因为如此,Hadoop的开发者开发出了Hadoop Eclipse插件,它在Hadoop的开发环境中嵌入了Eclipse,从而实现了开发环境的图形化,降低了编程难度。在安装插件,配置Hadoop的相关信息之后,如果用户创建Hadoop程序,插件会自动导入Hadoop编程接口的JAR文件,这样用户就可以在Eclipse的图形化界面中编写、调试、运行Hadoop程序(包括单机程序和分布式程序),也可以在其中查看自己程序的实时状态、错误信息和运行结果,还可以查看、管理HDFS以及文件。总地来说,Hadoop Eclipse插件安装简单,使用方便,功能强大,尤其是在Hadoop编程方面,是Hadoop入门和Hadoop编程必不可少的工具。
2.2 Hadoop工作目录简介
为了以后方便开发,我们按照下面把开发中用到的软件安装在此目录中,JDK安装除外,我这里把JDK安装在C盘的默认安装路径下,下面是我的工作目录:
系统磁盘(E:)
|---HadoopWorkPlat
|--- eclipse
|--- hadoop-1.0.0
|--- workplace
|---……
按照上面目录把Eclipse和Hadoop解压到"E:\HadoopWorkPlat"下面,并创建"workplace"作为Eclipse的工作空间。
备注:大家可以按照自己的情况,不一定按照我的结构来设计。
2.3 修改系统管理员名字
经过两天多次探索,为了使Eclipse能正常对Hadoop集群的HDFS上的文件能进行修改和删除,所以修改你工作时所用的Win7系统管理员名字,默认一般为"Administrator",把它修改为"hadoop",此用户名与Hadoop集群普通用户一致,大家应该记得我们Hadoop集群中所有的机器都有一个普通用户——hadoop,而且Hadoop运行也是用这个用户进行的。为了不至于为权限苦恼,我们可以修改Win7上系统管理员的姓名,这样就避免出现该用户在Hadoop集群上没有权限等都疼问题,会导致在Eclipse中对Hadoop集群的HDFS创建和删除文件受影响。
你可以做一下实验,查看Master.Hadoop机器上"/usr/hadoop/logs"下面的日志。发现权限不够,不能进行"Write"操作,网上有几种解决方案,但是对Hadoop1.0不起作用,详情见"常见问题FAQ_2"。下面我们进行修改管理员名字。
首先"右击"桌面上图标"我的电脑",选择"管理",弹出界面如下:
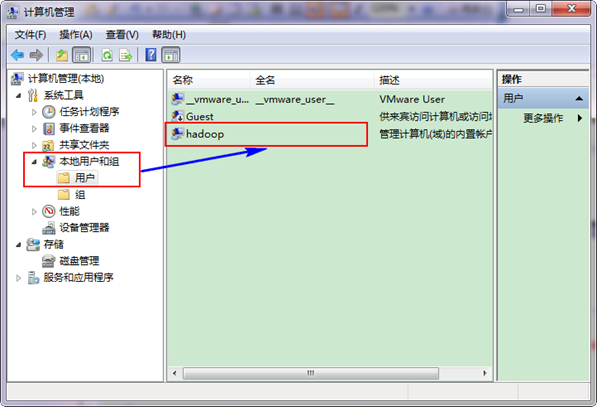
接着选择"本地用户和组",展开"用户",找到系统管理员"Administrator",修改其为"hadoop",操作结果如下图:
最后,把电脑进行"注销"或者"重启电脑",这样才能使管理员才能用这个名字。
2.4 Eclipse插件开发配置
第一步:把我们的"hadoop-eclipse-plugin-1.0.0.jar"放到Eclipse的目录的"plugins"中,然后重新Eclipse即可生效。
系统磁盘(E:)
|---HadoopWorkPlat
|--- eclipse
|--- plugins
|--- hadoop-eclipse-plugin-1.0.0.jar
上面是我的"hadoop-eclipse-plugin"插件放置的地方。重启Eclipse如下图:
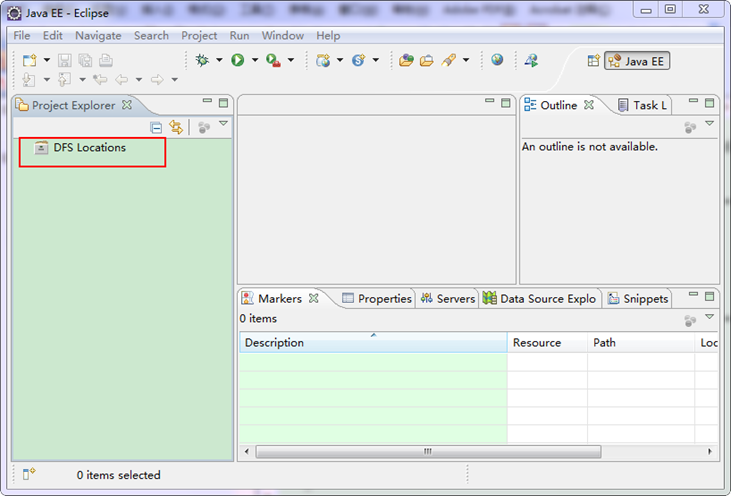
细心的你从上图中左侧"Project Explorer"下面发现"DFS Locations",说明Eclipse已经识别刚才放入的Hadoop Eclipse插件了。
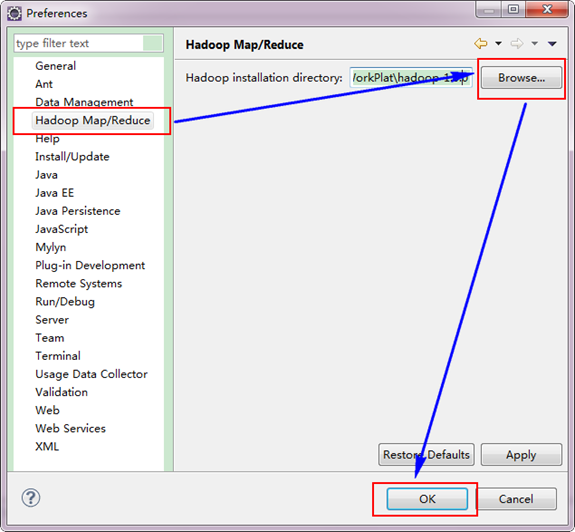
第二步:选择"Window"菜单下的"Preference",然后弹出一个窗体,在窗体的左侧,有一列选项,里面会多出"Hadoop Map/Reduce"选项,点击此选项,选择Hadoop的安装目录(如我的Hadoop目录:E:\HadoopWorkPlat\hadoop-1.0.0)。结果如下图:
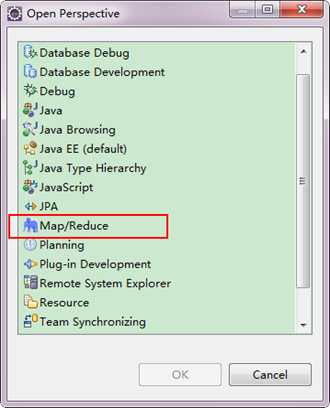
第三步:切换"Map/Reduce"工作目录,有两种方法:
1)选择"Window"菜单下选择"Open Perspective",弹出一个窗体,从中选择"Map/Reduce"选项即可进行切换。
2)在Eclipse软件的右上角,点击图标" "中的"
"中的" ",点击"Other"选项,也可以弹出上图,从中选择"Map/Reduce",然后点击"OK"即可确定。
",点击"Other"选项,也可以弹出上图,从中选择"Map/Reduce",然后点击"OK"即可确定。
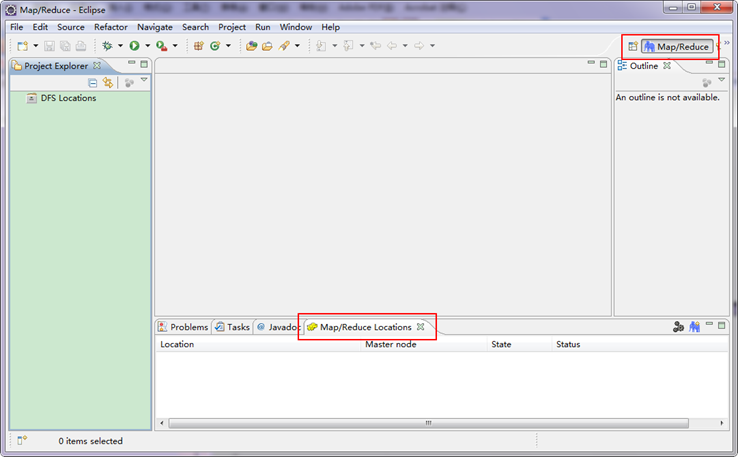
切换到"Map/Reduce"工作目录下的界面如下图所示。
第四步:建立与Hadoop集群的连接,在Eclipse软件下面的"Map/Reduce Locations"进行右击,弹出一个选项,选择"New Hadoop Location",然后弹出一个窗体。

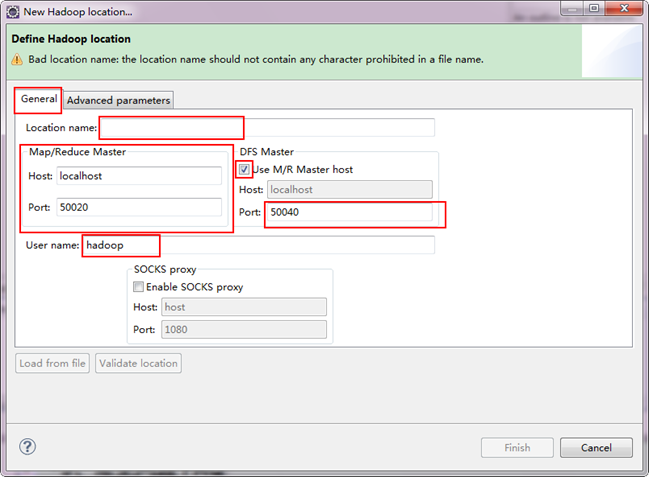
注意上图中的红色标注的地方,是需要我们关注的地方。
- Location Name:可以任意其,标识一个"Map/Reduce Location"
- Map/Reduce Master
Host:192.168.1.2(Master.Hadoop的IP地址)
Port:9001
- DFS Master
Use M/R Master host:前面的勾上。(因为我们的NameNode和JobTracker都在一个机器上。)
Port:9000
- User name:hadoop(默认为Win系统管理员名字,因为我们之前改了所以这里就变成了hadoop。)
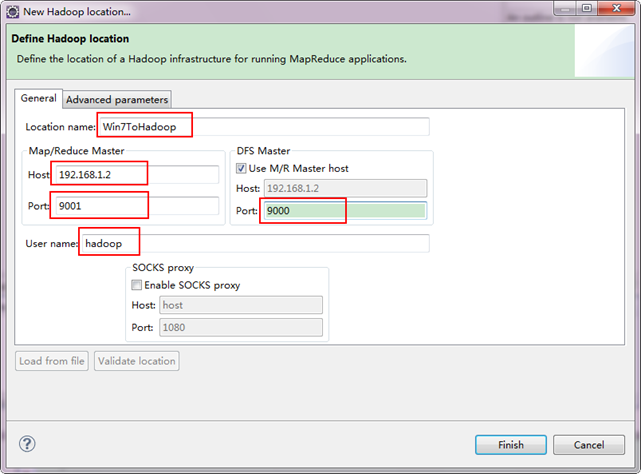
备注:这里面的Host、Port分别为你在mapred-site.xml、core-site.xml中配置的地址及端口。不清楚的可以参考"Hadoop集群_第5期_Hadoop安装配置_V1.0"进行查看。
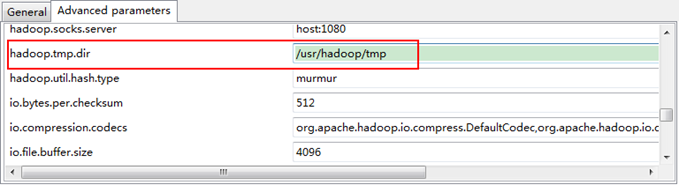
接着点击"Advanced parameters"从中找见"hadoop.tmp.dir",修改成为我们Hadoop集群中设置的地址,我们的Hadoop集群是"/usr/hadoop/tmp",这个参数在"core-site.xml"进行了配置。
点击"finish"之后,会发现Eclipse软件下面的"Map/Reduce Locations"出现一条信息,就是我们刚才建立的"Map/Reduce Location"。

第五步:查看HDFS文件系统,并尝试建立文件夹和上传文件。点击Eclipse软件左侧的"DFS Locations"下面的"Win7ToHadoop",就会展示出HDFS上的文件结构。
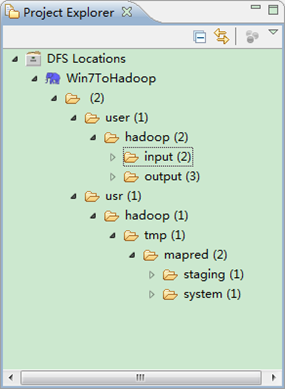
右击"Win7ToHadoopàuseràhadoop"可以尝试建立一个"文件夹--xiapi",然后右击刷新就能查看我们刚才建立的文件夹。
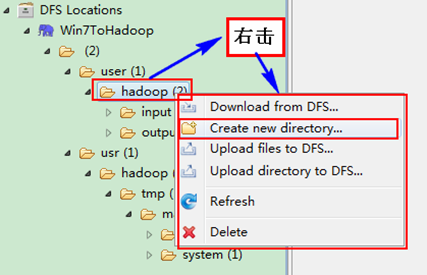
创建完之后,并刷新,显示结果如下:
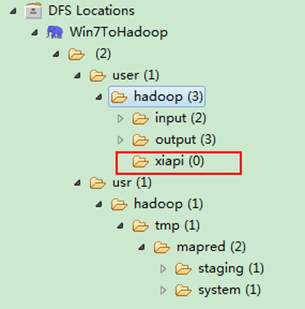
用SecureCRT远程登录"Master.Hadoop"服务器,用下面命令查看是否已经建立一个"xiapi"的文件夹。
hadoop fs -ls

到此为止,我们的Hadoop Eclipse开发环境已经配置完毕,不尽兴的同学可以上传点本地文件到HDFS分布式文件上,可以互相对比意见文件是否已经上传成功。
3、Eclipse运行WordCount程序
3.1 配置Eclipse的JDK
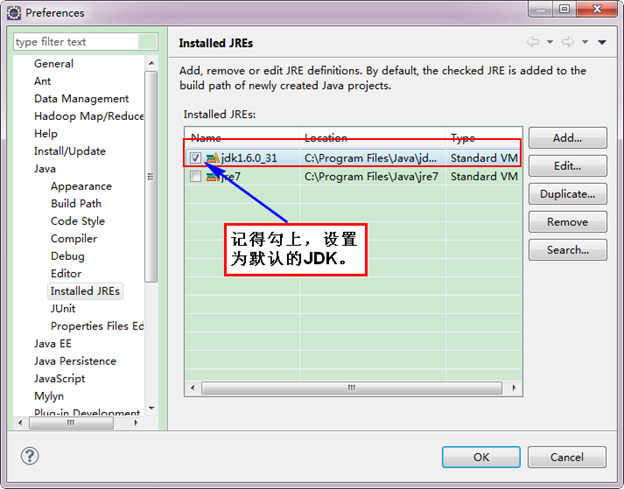
如果电脑上不仅仅安装的JDK6.0,那么要确定一下Eclipse的平台的默认JDK是否6.0。从"Window"菜单下选择"Preference",弹出一个窗体,从窗体的左侧找见"Java",选择"Installed JREs",然后添加JDK6.0。下面是我的默认选择JRE。
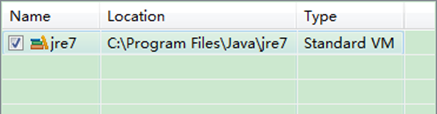
下面是没有添加之前的设置如下:
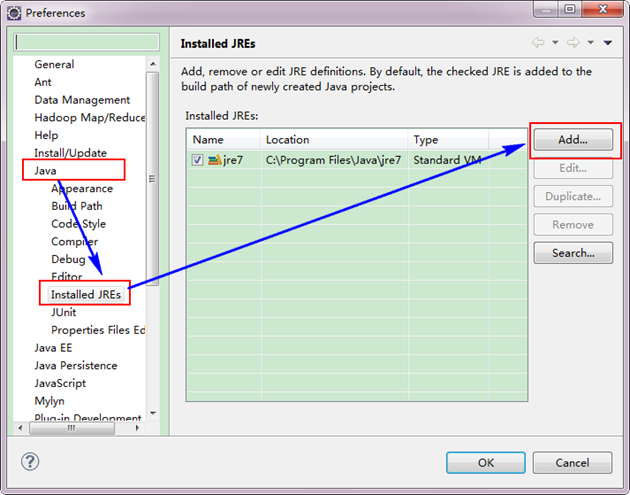
下面是添加完JDK6.0之后结果如下:
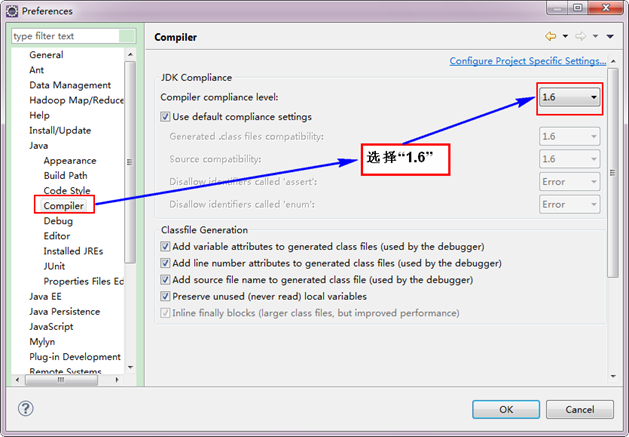
接着设置Complier。
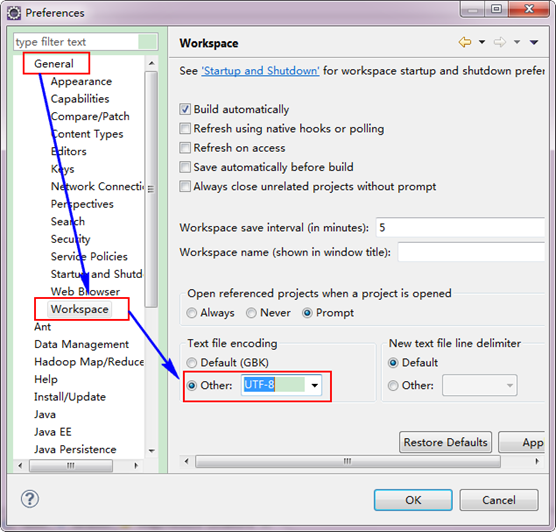
3.2 设置Eclipse的编码为UTF-8
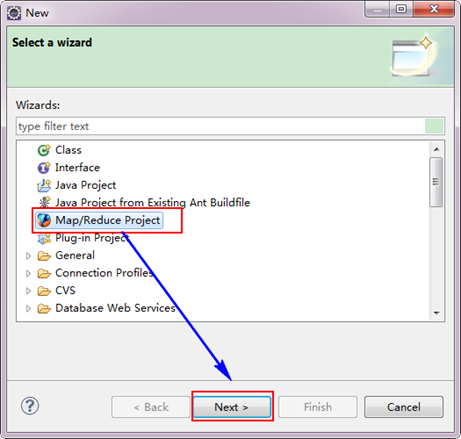
3.3 创建MapReduce项目
从"File"菜单,选择"Other",找到"Map/Reduce Project",然后选择它。
接着,填写MapReduce工程的名字为"WordCountProject",点击"finish"完成。
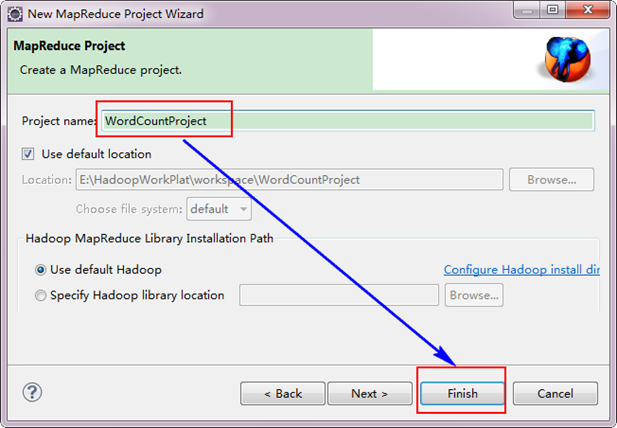
目前为止我们已经成功创建了MapReduce项目,我们发现在Eclipse软件的左侧多了我们的刚才建立的项目。
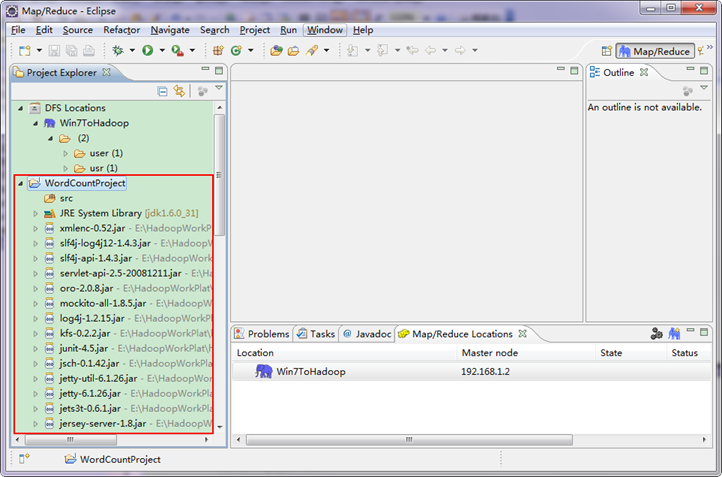
3.4 创建WordCount类
选择"WordCountProject"工程,右击弹出菜单,然后选择"New",接着选择"Class",然后填写如下信息:
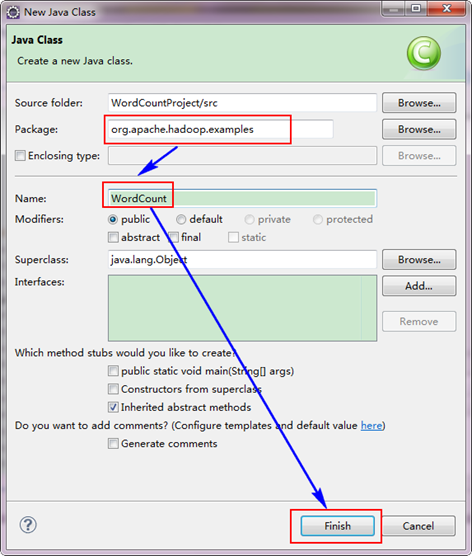
因为我们直接用Hadoop1.0.0自带的WordCount程序,所以报名需要和代码中的一致为"org.apache.hadoop.examples",类名也必须一致为"WordCount"。这个代码放在如下的结构中。
hadoop-1.0.0
|---src
|---examples
|---org
|---apache
|---hadoop
|---examples
从上面目录中找见"WordCount.java"文件,用记事本打开,然后把代码复制到刚才建立的java文件中。当然源码有些变动,变动的红色已经标记出。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
package org.apache.hadoop.examples;import java.io.IOException;import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.GenericOptionsParser;public class WordCount public static class TokenizerMapper extends Mapper<Object, private final static IntWritablenew IntWritable(1); private Textnew Text(); public void map(Object )throws IOException, StringTokenizernew StringTokenizer(value.toString()); while (itr.hasMoreTokens()) word.set(itr.nextToken()); context.write(word, } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> private IntWritablenew IntWritable(); public void reduce(Text Context )throws IOException, int sum0; for (IntWritable sum } result.set(sum); context.write(key, } } public static void main(String[]throws Exception Configurationnew Configuration(); conf.set("mapred.job.tracker","192.168.1.2:9001"); String[]new String[]{"input","newout"}; String[]new GenericOptionsParser(conf, if (otherArgs.length2) System.err.println("Usage:); System.exit(2); } Jobnew Job(conf,"word); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job,new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job,new Path(otherArgs[1])); System.exit(job.waitForCompletion(true)0 :1); }} |
备注:如果不加"conf.set("mapred.job.tracker", "192.168.1.2:9001");",将提示你的权限不够,其实照成这样的原因是刚才设置的"Map/Reduce Location"其中的配置不是完全起作用,而是在本地的磁盘上建立了文件,并尝试运行,显然是不行的。我们要让Eclipse提交作业到Hadoop集群上,所以我们这里手动添加Job运行地址。详细参考"常见问题FAQ_3"。
3.5 运行WordCount程序
选择"Wordcount.java"程序,右击一次按照"Run ASàRun on Hadoop"运行。然后会弹出如下图,按照下图进行操作。
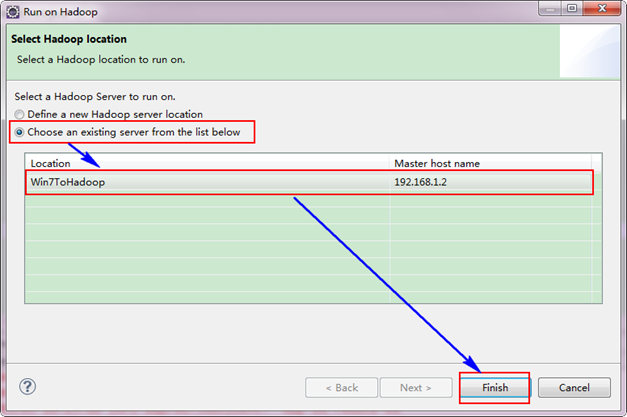
运行结果如下:
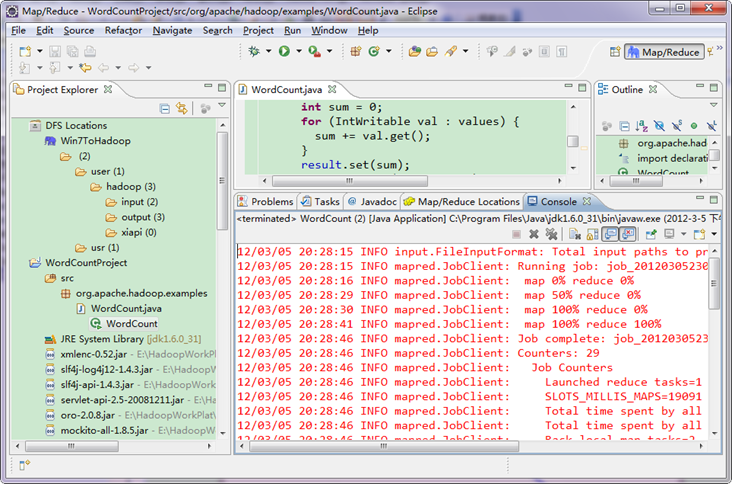
从上图中我们得知我们的程序已经运行成功了。
3.6 查看WordCount运行结果
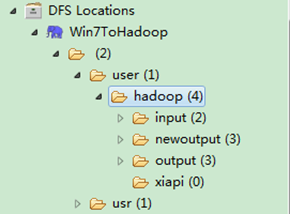
查看Eclipse软件左侧,右击"DFS LocationsàWin7ToHadoopàuseràhadoop",点击刷新按钮"Refresh",我们刚才出现的文件夹"newoutput"会出现。记得"newoutput"文件夹是运行程序时自动创建的,如果已经存在相同的的文件夹,要么程序换个新的输出文件夹,要么删除HDFS上的那个重名文件夹,不然会出错。
打开"newoutput"文件夹,打开"part-r-00000"文件,可以看见执行后的结果。
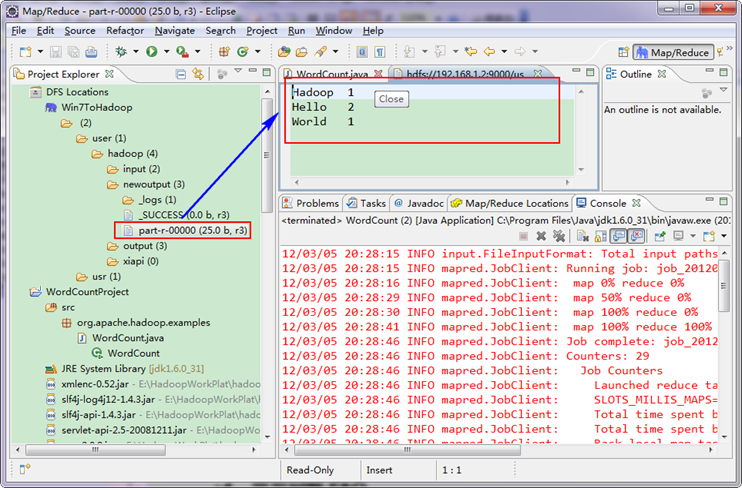
到此为止,Eclipse开发环境设置已经完毕,并且成功运行Wordcount程序,下一步我们真正开始Hadoop之旅。
4、常见问题FAQ
4.1 "error: failure to login"问题
下面以网上找的"hadoop-0.20.203.0"为例,我在使用"V1.0"时也出现这样的情况,原因就是那个"hadoop-eclipse-plugin-1.0.0_V1.0.jar",是直接把源码编译而成,故而缺少相应的Jar包。具体情况如下
详细地址:http://blog.csdn.net/chengfei112233/article/details/7252404
在我实践尝试中,发现hadoop-0.20.203.0版本的该包如果直接复制到eclipse的插件目录中,在连接DFS时会出现错误,提示信息为: "error: failure to login"。
弹出的错误提示框内容为"An internal error occurred during: "Connecting to DFS hadoop".org/apache/commons/configuration/Configuration". 经过察看Eclipse的log,发现是缺少jar包导致的。进一步查找资料后,发现直接复制hadoop-eclipse-plugin-0.20.203.0.jar,该包中lib目录下缺少了jar包。
经过网上资料搜集,此处给出正确的安装方法:
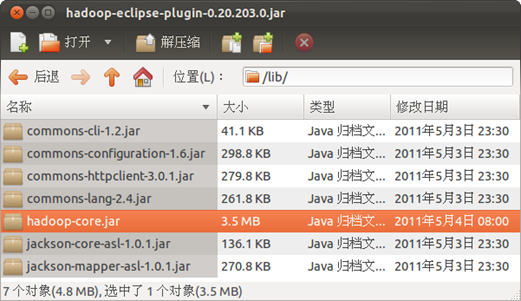
首先要对hadoop-eclipse-plugin-0.20.203.0.jar进行修改。用归档管理器打开该包,发现只有commons-cli-1.2.jar 和hadoop-core.jar两个包。将hadoop/lib目录下的:
- commons-configuration-1.6.jar ,
- commons-httpclient-3.0.1.jar ,
- commons-lang-2.4.jar ,
- jackson-core-asl-1.0.1.jar
- jackson-mapper-asl-1.0.1.jar
一共5个包复制到hadoop-eclipse-plugin-0.20.203.0.jar的lib目录下,如下图:
然后,修改该包META-INF目录下的MANIFEST.MF,将classpath修改为一下内容:
Bundle-ClassPath:classes/,lib/hadoop-core.jar,lib/commons-cli-1.2.jar,lib/commons-httpclient-3.0.1.jar,lib/jackson-core-asl-1.0.1.jar,lib/jackson-mapper-asl-1.0.1.jar,lib/commons-configuration-1.6.jar,lib/commons-lang-2.4.jar
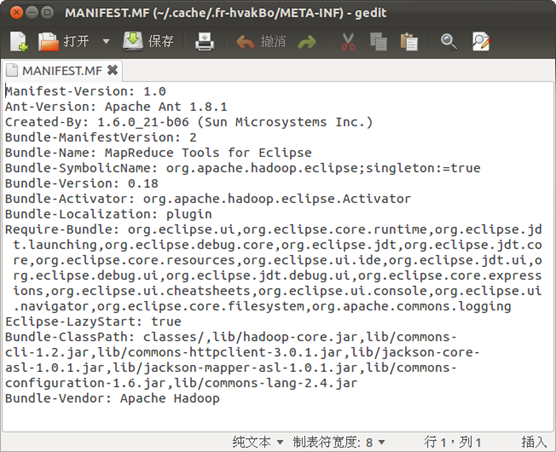
这样就完成了对hadoop-eclipse-plugin-0.20.203.0.jar的修改。
最后,将hadoop-eclipse-plugin-0.20.203.0.jar复制到Eclipse的plugins目录下。
备注:上面的操作对"hadoop-1.0.0"一样适用。
4.2 "Permission denied"问题
网上试了很多,有提到"hadoop fs -chmod 777 /user/hadoop ",有提到"dfs.permissions 的配置项,将value值改为 false",有提到"hadoop.job.ugi",但是通通没有效果。
参考文献:
地址1:http://www.cnblogs.com/acmy/archive/2011/10/28/2227901.html
地址2:http://sunjun041640.blog.163.com/blog/static/25626832201061751825292/
错误类型:org.apache.hadoop.security.AccessControlException: org.apache.hadoop.security .AccessControlException: Permission denied: user=*********, access=WRITE, inode="hadoop": hadoop:supergroup:rwxr-xr-x
解决方案:
我的解决方案直接把系统管理员的名字改成你的Hadoop集群运行hadoop的那个用户。
4.3 "Failed to set permissions of path"问题
参考文献:https://issues.apache.org/jira/browse/HADOOP-8089
错误信息如下:
ERROR security.UserGroupInformation: PriviledgedActionException as: hadoop cause:java.io.IOException Failed to set permissions of path:\usr\hadoop\tmp\mapred\staging\hadoop753422487\.staging to 0700 Exception in thread "main" java.io.IOException: Failed to set permissions of path: \usr\hadoop\tmp \mapred\staging\hadoop753422487\.staging to 0700
解决方法一:
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "[server]:9001");
"[server]:9001"中的"[server]"为Hadoop集群Master的IP地址。
解决方法二:
右击WordCount.java,在Run As——>Run configurations——>Arguments——>Program arguments中加上参数:
hdfs://192.168.1.2:9000/input hdfs://192.168.1.2:9000/output
4.4 "hadoop mapred执行目录文件权"限问题
参考文献:http://blog.csdn.net/azhao_dn/article/details/6921398
错误信息如下:
job Submission failed with exception 'java.io.IOException(The ownership/permissions on the staging directory /tmp/hadoop-hadoop-user1/mapred/staging/hadoop-user1/.staging is not as expected. It is owned by hadoop-user1 and permissions are rwxrwxrwx. The directory must be owned by the submitter hadoop-user1 or by hadoop-user1 and permissions must be rwx------)
修改权限:

这样就能解决问题。
原文地址:http://www.cnblogs.com/xia520pi/archive/2012/05/20/2510723.html
【hadoop】——window下elicpse连接hadoop集群基础超详细版的更多相关文章
- [Hadoop] - Win7下提交job到集群上去
一般我们采用win开发+linux hadoop集群的方式进行开发,使用插件:hadoop-***-eclipse-plugin. 运行程序的时候,我们一般采用run as application或者 ...
- hadoop2.6.4的HA集群搭建超详细步骤
hadoop2.0已经发布了稳定版本了,增加了很多特性,比如HDFS HA.YARN等.最新的hadoop-2.6.4又增加了YARN HA 注意:apache提供的hadoop-2.6.4的安装包是 ...
- Tomcat集群搭建超详细(apache+mod_jk+tomcat)
TOMCAT集群 目录 TOMCAT集群 1 1 集群 1 1.1 什么是集群 1 1.2 集群的特性 1 1.3 集群的分类 1 1.4 TOMCAT集群配置的优缺点 2 1.5 APACHE+TO ...
- HBase 1.2.6 完全分布式集群安装部署详细过程
Apache HBase 是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,是NoSQL数据库,基于Google Bigtable思想的开源实现,可在廉价的PC Server上搭建大规模结构化存 ...
- Hadoop及Zookeeper+HBase完全分布式集群部署
Hadoop及HBase集群部署 一. 集群环境 系统版本 虚拟机:内存 16G CPU 双核心 系统: CentOS-7 64位 系统下载地址: http://124.202.164.6/files ...
- 从VMware虚拟机安装到hadoop集群环境配置详细说明(第一期)
http://blog.csdn.net/whaoxysh/article/details/17755555 虚拟机安装 我安装的虚拟机版本是VMware Workstation 8.04,自己电脑上 ...
- Hadoop 2.6.4单节点集群配置
1.安装配置步骤 # wget http://download.oracle.com/otn-pub/java/jdk/8u91-b14/jdk-8u91-linux-x64.rpm # rpm -i ...
- Hadoop学习记录(5)|集群搭建|节点动态添加删除
集群概念 计算机集群是一种计算机系统,通过一组松散继承的计算机软件或硬件连接连接起来高度紧密地协作完成计算工作. 集群系统中的单个计算机通常称为节点,通过局域网连接. 集群特点: 1.效率高,通过多态 ...
- Hadoop入门 完全分布式运行模式-集群配置
目录 集群配置 集群部署规划 配置文件说明 配置集群 群起集群 1 配置workers 2 启动集群 总结 3 集群基本测试 上传文件到集群 查看数据真实存储路径 下载 执行wordcount程序 配 ...
随机推荐
- 【Java每日一题】20161208
package Dec2016; import java.util.List; public class Ques1208 { public static void add(List<? ext ...
- 【Java每日一题】20161108
package Nov2016; import java.util.TreeSet; public class Ques1108 { public static void main(String[] ...
- Output data in a cursor
http://www.java2s.com/Code/SQL/Cursor/Outputdatainacursor.htm mysql> mysql> mysql> CREATE T ...
- spring入门(二)【加载properties文件】
在开发过程当中需要用到配置信息,这些信息不能进行硬编码,这时配置文件是一个比较好的方式,java提供了properties格式的文件,以键值对的方式保存信息,在读取的时候通过键获得键对应的值,spri ...
- Nuget很慢,我们该怎么办
在VS中给项目添加程序已经采用NuGet 十分方便 不过很多时候速度很慢,一直显示“正在检索信息” 其实直接使用程序包管理控制台,速度就会好很多 如果命令不太会写,安装包名不是确认,可以先登录 htt ...
- 浅谈spring security 403机制
403就是access denied ,就是请求拒绝,因为权限不足 三种权限级别 一.无权限访问 <security:http security="none" pattern ...
- 酷!使用 jQuery & Canvas 制作相机快门效果
在今天的教程中,我们将使用 HTML5 的 Canvas 元素来创建一个简单的摄影作品集,它显示了一组精选照片与相机快门的效果.此功能会以一个简单的 jQuery 插件形式使用,你可以很容易地整合到任 ...
- CSS3文本温故
1.CSS早期属性,分为三大类:字体.颜色和文本: 2.CSS文本类型有11个属性: 注:还有一个颜色属性:color,主要用来设置文本颜色 3.CSS3文本阴影属性:text-shadow语法:te ...
- 浅析css布局模型1
css是网页的外衣,好不好看全凭css样式,而布局是css中比较重要的部分,下面来分析一下常见的几种布局. 流动模型 流动模型是网页布局的默认模式,也是最常见的布局模式,他有两个特点: 1.块状元素都 ...
- SharePoint 2010升级到sharePoint 2013后,人员失去对网站的权限的原因及解决方法。The reason and solution for permission lost after the upgrading
昨天碰到了一个问题,一个网站在从SharePoint 2010升级到SharePoint 2013后,人员都不能登录了,必须重加赋权,人员才能登录,这样非常麻烦. 原因:是认证方式的问题.在Share ...