HashMap原理与优化
参考文献:
HashMap的工作原理
java中HashMap重要性质和优化总结
一、HashMap的基本了解
基本定义:根据源代码的描述可知,HashMap是基于哈希表的Map接口的实现,其包含了Map接口的所有映射操作,并且允许使用null键和null值。
与HashTable的区别:HashMap可以近似地看成是HashTable,但是它是非线程安全的,并且允许使用null键和null值,而这些都与HashTable恰巧相反。注:HashMap可以使用ConcurrentHashMap代替,ConcurrentHashMap是一个线程安全,更加快速的HashMap,欲了解ConcurrentHashMap,可点击http://www.blogjava.net/wuxufeng8080/articles/152238.html
存储结构:HashMap的存储结构其实就是哈希表的存储结构(由数组与链表结合组成,称为链表的数组)。如下图所示:
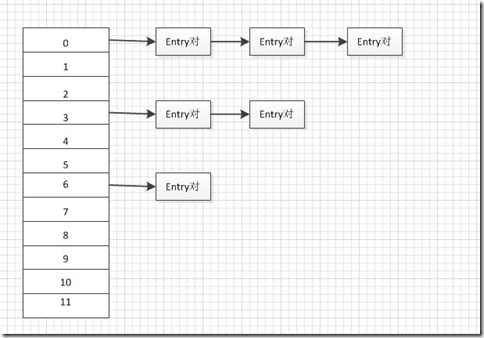
如上图所示,HashMap中元素存储的形式是键-值对(key-value对,即Entry对),所有具有相同hashcode值的键(key)所对应的entry对会被链接起来组成一条链表,而数组的作用则是存储链表中第一个结点的地址值。
二、影响HashMap性能的因素
在HashMap中,还存在着两个概念,桶(buckets)和加载因子(load factor)。
桶(buckets):上图中的标有0、1、2、3、….、11所对应的数组空间就是一个个桶。
加载因子(load factor):是哈希表在其容量自动增加之前可以达到多满的一种尺度,默认值是0.75。
根据源代码中所述,影响HashMap性能有两个因素:哈希表中的初始化容量(桶的数量)和加载因子。当哈希表中条目数超过了当前容量与加载因子的乘积时,哈希表将会作出自我调整,将容量扩充为原来的两倍,并且重新将原有的元素重新映射到表中,这一过程成为rehash。看到这里,相必大家会发现rehash操作是会造成时间与空间的开销的,因此为什么初始化容量与加载因子会影响HashMap的性能也就可以理解了。
代码示例1.添加键-值对的java源代码:
|
1
2
3
4
5
6
|
void addEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; //找到元素要插入的桶 table[bucketIndex] = new Entry<K,V>(hash, key, value, e); if (size++ >= threshold) //threshold的值为当前容量*加载因子(0.75) resize(2 * table.length); //将HashMap的容量扩充为当前容量的两倍 } |
代码示例2.扩充HashMap实例容量源代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; if (oldCapacity == MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } Entry[] newTable = new Entry[newCapacity]; //重新定义新容量的Entry对 transfer(newTable); //rehash操作,将旧表中的元素重新映射到新表中 table = newTable; threshold = (int)(newCapacity * loadFactor);//新的临界值为新的容量*加载因子 } |
三、put/get方法实现原理
put操作:HashMap在进行put操作的时候,会首先调用Key值中的hashCode()方法,用于获取对应的bucket的下标值以便存放数据。具体操作可以参照如下的java源代码:
代码示例3.put方法的java源代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public V put(K key, V value) { if (key == null) return putForNullKey(value); int hash = hash(key.hashCode()); int i = indexFor(hash, table .length ); for (Entry<K,V> e = table[i]; e != null; e = e. next) { Object k; if (e. hash == hash && ((k = e. key) == key || key.equals(k))) { V oldValue = e. value; e. value = value; e.recordAccess( this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null; } |
正如上述代码所示,HashMap通过key值的hashcode获得了对应的bucket存储空间的下标,然后进入bucket空间,通过链表遍历的方式逐个查询,看看链表中是否已经存在了这个key的键-值对,如果已经存在则用新值替换旧值,否则插入新的键-值对。看到这里,相信大家会发现,hashCode值相同的两个值可能是不同的两个对象,而当put进去的是另一个hashCode值相等的对象时,会发生冲突,而在HashMap中解决这种冲突的方法就是将hashCode值相同的key值所对应的key-value对串联成一条链表,请见上面的HashMap数据结构图。
get操作:HashMap在进行get操作的时候,与put方法类似,会首先调用Key值中的hashCode()方法,用于获取对应的bucket的下标值,找到bucket的位置后,再通过key.equals()方法找到对应的键-值对,从而获得对应的value值。java源代码如下:
代码示例4.get方法的java源代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public V get(Object key) { if (key == null) return getForNullKey(); int hash = hash(key.hashCode()); for (Entry<K,V> e = table[ indexFor(hash, table.length)]; e != null; e = e. next) { Object k; if (e. hash == hash && ((k = e. key) == key || key.equals(k))) return e. value; } return null;} |
总结:HashMap是基于hashing原理对key-value对进行存储与获取,当使用put()方法添加key-value对时,它会首先检查hashCode的值,并以此获得对应的bucket位置进行存储,当发生冲突时(hashcode值相同的两个不同key),新的key-value对会以结点的形式添加到链表的末尾。而使用get()方法时,同样地会根据key的hashCode值找到相应的bucket位置,再通过key.equals()方法找到对应的key-value对,最终成功获取value值。
四、hashMap重要属性与优化
1、
/**
* The default initial capacity - MUST be a power of two.(map的初始大小)
*/
DEFAULT_INITIAL_CAPACITY = 16;(默认大小)
2、
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*(最大容量,如果指定的容易大于最大容量,将使用此值)
*/
MAXIMUM_CAPACITY = 1 << 30;(最大容量)
3、
/**
* The load factor used when none specified in constructor.
*/
DEFAULT_LOAD_FACTOR = 0.75f;(默认负载因子)
4、
/**
* The next size value at which to resize (capacity * load factor).
* (map是否扩容的决定性因素)
*/
threshold;
5、
bucket(数组中最小存储单元,在源码中为Entry)
6、HashMap创建到put流程基本介绍
hashMap由其名字可以知道,它使用的是哈希算法来管理存储其中的对象的,具体是用数组和链表两种数据结构管理的。
a、初始化
如果参数均为指定,则使用默认值初始化
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];(这里就是初始化了一个数组,用于存放对象,buckets)
如果指定loadFactor和initialCapacity,则
this.loadFactor = loadFactor
程序将利用initialCapacity计算一个新的capacity,capacity大小为大于初始容易值的最小的2的整数次幂的值(如初始容量为15,则capacity为16.初始为3,则capacity为4),
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
b、put
put过程中,如果一个对象hash到同一个bucket,则会形成一个链表,链表查询是线性的。在对象放入map后,会检查map大小。如果map的size大于或等于threshold(capacity * load factor),注意不是在size大于capacity时扩容,则会以map两倍容量扩容(此步骤设计到重新申请空间和计算hash值,性能消耗比较大)
三、优化hashMap
如果哈希映射的内部数组只包含一个元素,则所有项将映射到此数组位置,从而构成一个较长的链接列表。由于我们的更新和访问使用了对链接列表的线性搜索,而这要比 Map 中的每个数组索引只包含一个对象的情形要慢得多,因此这样做的效率很低。访问或更新链接列表的时间与列表的大小线性相关,而使用哈希函数问或更新数组中的单个元素则与数组大小无关 — 就渐进性质(Big-O 表示法)而言,前者为 O(n),而后者为 O(1)。因此,使用一个较大的数组而不是让太多的项聚集在太少的数组位置中是有意义的。
调整 Map 实现的大小
在哈希术语中,内部数组中的每个位置称作“存储桶”(bucket),而可用的存储桶数(即内部数组的大小)称作容量 (capacity)。为使 Map 对象有效地处理任意数目的项,Map 实现可以调整自身的大小。但调整大小的开销很大。调整大小需要将所有元素重新插入到新数组中,这是因为不同的数组大小意味着对象现在映射到不同的索引值。先前冲突的键可能不再冲突,而先前不冲突的其他键现在可能冲突。这显然表明,如果将 Map 调整得足够大,则可以减少甚至不再需要重新调整大小,这很有可能显著提高速度。
使用 1.4.2 JVM 运行一个简单的测试,即用大量的项(数目超过一百万)填充 HashMap。表 5 显示了结果,并将所有时间标准化为已预先设置大小的服务器模式(关联文件中的 。对于已预先设置大小的 JVM,客户端和服务器模式 JVM 运行时间几乎相同(在放弃 JIT 编译阶段后)。但使用 Map 的默认大小将引发多次调整大小操作,开销很大,在服务器模式下要多用 50% 的时间,而在客户端模式下几乎要多用两倍的时间!
表 5:填充已预先设置大小的 HashMap 与填充默认大小的 HashMap 所需时间的比较
| 客户端模式 | 服务器模式 | |
| 预先设置的大小 | 100% | 100% |
| 默认大小 | 294% | 157% |
使用负载因子
为确定何时调整大小,而不是对每个存储桶中的链接列表的深度进行记数,基于哈希的 Map 使用一个额外参数并粗略计算存储桶的密度。Map 在调整大小之前,使用名为“负载因子”的参数指示 Map 将承担的“负载”量,即它的负载程度。负载因子、项数(Map 大小)与容量之间的关系简单明了:
- 如果(负载因子)x(容量)>(Map 大小),则调整 Map 大小
例如,如果默认负载因子为 0.75,默认容量为 11,则 11 x 0.75 = 8.25,该值向下取整为 8 个元素。因此,如果将第 8 个项添加到此 Map,则该 Map 将自身的大小调整为一个更大的值。相反,要计算避免调整大小所需的初始容量,用将要添加的项数除以负载因子,并向上取整,例如,
- 对于负载因子为 0.75 的 100 个项,应将容量设置为 100/0.75 = 133.33,并将结果向上取整为 134(或取整为 135 以使用奇数)
奇数个bucket使 map 能够通过减少冲突数来提高执行效率。虽然我所做的测试(关联文件中的 并未表明质数可以始终获得更好的效率,但理想情形是容量取质数。1.4 版后的某些 Map(如 HashMap 和 LinkedHashMap,而非 Hashtable 或 IdentityHashMap)使用需要 2 的幂容量的哈希函数,但下一个最高 2 的幂容量由这些 Map 计算,因此您不必亲自计算。
负载因子本身是空间和时间之间的调整折衷。较小的负载因子将占用更多的空间,但将降低冲突的可能性,从而将加快访问和更新的速度。使用大于 0.75 的负载因子可能是不明智的,而使用大于 1.0 的负载因子肯定是不明知的,这是因为这必定会引发一次冲突。使用小于 0.50 的负载因子好处并不大,但只要您有效地调整 Map 的大小,应不会对小负载因子造成性能开销,而只会造成内存开销。但较小的负载因子将意味着如果您未预先调整 Map 的大小,则导致更频繁的调整大小,从而降低性能,因此在调整负载因子时一定要注意这个问题。
HashMap原理与优化的更多相关文章
- Lucene底层原理和优化经验分享(1)-Lucene简介和索引原理
Lucene底层原理和优化经验分享(1)-Lucene简介和索引原理 2017年01月04日 08:52:12 阅读数:18366 基于Lucene检索引擎我们开发了自己的全文检索系统,承担起后台PB ...
- Java:HashMap原理与设计缘由
前言 Java中使用最多的数据结构基本就是ArrayList和HashMap,HashMap的原理也常常出现在各种面试题中,本文就HashMap的设计与设计缘由作出一一讲解,并解答面试常见的一些问题. ...
- HashMap 原理解析
HashMap是由数组加链表的结合体.如下图: 图中可以看出HashMap底层就是一个数组结构,每个数组中又存储着链表(链表的引用) JDK1.6实现hashmap的方式是采用位桶(数组)+链表的方式 ...
- java中HashMap原理?
参考:https://www.cnblogs.com/yuanblog/p/4441017.html(推荐) https://blog.csdn.net/a745233700/article/deta ...
- 【Java基础】HashMap原理详解
哈希表(hash table) 也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,本文会对java集合框架中Has ...
- Java_冒泡排序_原理及优化
冒泡排序及其优化 一.原理及优化原理 1.原理讲解 冒泡排序即:第一个数与第二个数进行比较,如果满足条件位置不变,再把第二个数与第三个数进行比较.不满足条件则替换位置,再把第二个数与第三个数进行比较, ...
- ==和equasl、hashmap原理(***)
public class String01 { public static void main(String[] args) { String a="test"; String b ...
- Java基础-hashMap原理剖析
Java基础-hashMap原理剖析 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.什么是哈希(Hash) 答:Hash就是散列,即把对象打散.举个例子,有100000条数 ...
- HashMap原理(二) 扩容机制及存取原理
我们在上一个章节<HashMap原理(一) 概念和底层架构>中讲解了HashMap的存储数据结构以及常用的概念及变量,包括capacity容量,threshold变量和loadFactor ...
随机推荐
- Java提高篇——静态代码块、构造代码块、构造函数以及Java类初始化顺序
静态代码块:用staitc声明,jvm加载类时执行,仅执行一次构造代码块:类中直接用{}定义,每一次创建对象时执行.执行顺序优先级:静态块,main(),构造块,构造方法. 构造函数 public H ...
- My Baits入门(一)mybaits环境搭建
1)在工程下引入mybatis-3.4.1.jar包,再引入数据库(mysql,mssql..)包. 2)在src下新建一个配置文件conf.xml <?xml version="1. ...
- mysql入门
mysql:关系型数据库的一种,用来存储数据: 一个仓库------一个数据库: 一个箱子------ 表: 进入mysql命令行:mysql -uroot -p(密码):查看数据库中所有表:show ...
- Transaction Save Point (SET XACT_ABORT { ON | OFF })
ref:http://blog.csdn.net/wym3587/article/details/6940630 ref:http://www.cnblogs.com/jiajiayuan/archi ...
- Could not find a getter for id in class 的异常
检查.hbm.xml里边的id是否大小写一致
- NOI 05:最高的分数描述
描述 孙老师讲授的<计算概论>这门课期中考试刚刚结束,他想知道考试中取得的最高分数.因为人数比较多,他觉得这件事情交给计算机来做比较方便.你能帮孙老师解决这个问题吗? 输入输入两行,第一行 ...
- 《量化投资:以MATLAB为工具》连载(1)基础篇-N分钟学会MATLAB(上)
http://blog.sina.com.cn/s/blog_4cf8aad30102uylf.html <量化投资:以MATLAB为工具>连载(1)基础篇-N分钟学会MATLAB(上) ...
- 利用Servlet导出Excel
-----因为Excel可以打开HTML文件,因此可以利用页面的Form表单把页面中的table内容提交给Servlet,然后后台把提交上来的table内容转换成文件流的形式,并以下载的形式转给客户端 ...
- C#压缩库SharpZipLib的应用
SharpZipLib是一个开源的C#压缩解压库,应用非常广泛.就像用ADO.NET操作数据库要打开连接.执行命令.关闭连接等多个步骤一样,用SharpZipLib进行压缩和解压也需要多个步骤. ...
- c#的逻辑运算符重载
不光是C++,实际上C#中同样可以对操作符重载.如:namespace Com.EVSoft.Math{ public class Vector3:BaseObject { ... . ...