[原]分享一下我和MongoDB与Redis那些事
缘起:来自于我在近期一个项目上遇到的问题,在Segmentfault上发表了提问
知识背景:
对不是很熟悉MongoDB和Redis的同学做一下介绍。
1.MongoDB数组查询:MongoDB自带List,可以存放类似这样的结构 List = [1, 2, 3, 4, 5, 6, 7, 8, 9].
如果我们有一个 l = [2, 3, 8], 则可以进行这样的查询:spce = { 'List' : { '$in' : l }, 这里spce就是一个查询条件,代表 l 是 List的一个子集。
2.Redis队列: Redis提供基本的List(普通链表),set(集合),Zset(有序集合) 类型的结构,将List的 lpush, rpop操作运用起来,可以做一个普通的队列,运用Zset 可以做一个带权值的最小堆排序的队列(可以看做优先级)。
整体架构如下图所示:
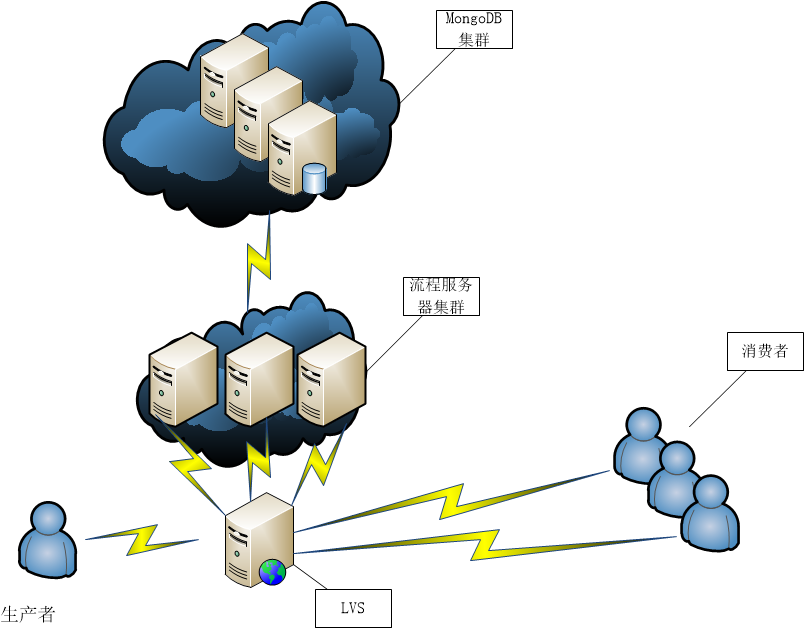
生产者产生任务,通过LVS与RPC服务器将任务记录到MongoDB,消费者同样通过RPC服务获取任务,这是个很简单的架构,一般服务可能去掉集群都是这样的。
整个业务架构需要一个前提,任务不能丢失,也就是说任务即使失败也需要重新加入到队列,至少若干次后任然失败也要知道为什么失败(非记录日志形式)。
很多人问为什么不直接用RabbitMQ或者Redis,因为这类消息队列无法做到管理任务超时等情况,因为业务需要,也需要做一些简单的查询,这类队列是不支持某些稍复杂的查询的,而且一开始我们的任务量估计在5KW/Day这样,担心Redis扛不住,后来我发现这是个错误的假设。
问题内容如下:
问题背景: 近期在重构公司内部一个重要的任务系统,由于原来的任务系统使用了MongoDB来保存任务,客户端从MongoDB来取,至于为什么用MongoDB,是一个历史问题,也是因为如果使用到MongoDB的数组查询可以减少任务数量很多次,假设这样的情况,一个md5(看做一条记录的唯一标识)需要针对N种情况做任务处理,如果用到MongoDB的数组,只需要将一个md5作为一条任务,其中包含一个长度为N的待处理任务列表,可以使用到MongoDB的数组(只有N个子任务都处理完后整个任务才算处理完毕),这样整个任务系统的数量级就变为原来的 1/N(如果需要用到普通的关系型数据库,可能需要创建 m*n 个任务,这样算下来我们的任务数量将可能达到一个很大的值,主要是因为处理任务的进程由于某些不确定因素无法控制,所以比较慢)
细节描述: 1.当MongoDB的任务数量增多的时候,数组查询相当的慢(已经做索引),任务数达到5K就已经不能容忍了,和我们每天的任务数不在一个数量级。
2.任务处理每个md5对应的N个子任务必须要全部完成才从MongoDB中删除
3.任务有相应的优先级(保证高优先级优先处理),任务在超时后可以重置。
改进方案如下: 由于原有代码的耦合,不能完全抛弃MongoDB,所以决定加一个Redis缓存。一个md5对应的N个子任务分发到N个Redis队列中(拆分子任务)。一个单独的进程从MongoDB中向Redis中将任务同步,客户端不再从MongoDB取任务。这样做的好处是抛弃了原有的MongoDB的数组查询,同步进程从MongoDB中取任务是按照任务的优先级偏移(已做索引)来取,所以速度比数组查询要快。这样客户端向Redis的N个队列中取子任务,把任务结果返回原来的MongoDB任务记录中(根据md5返回子任务)。
改进过程遇到的问题: 由于任务处理端向MongoDB返回时候会有一个update操作,如果N个子任务都完成,就将任务从MongoDB中删除。这样的一个问题就是,经过测试后发现MongoDB在高并发写的情况下性能很低下,整个任务系统任务处理速度最大为200/s(16核, 16G, CentOS, 内核2.6.32-358.6.3.el6.x86_64),原因大致为在频繁写情况下,MongoDB的性能会由于锁表操作急剧下降(锁表时间可以达到60%-70%,熟悉MongoDB的人都知道这是多么恐怖的数字)。
具体问题: (Think out of the Box)能否提出一个好的解决方案,能够保存任务状态(子任务状态),速度至少超过MongoDB的?
提出这个问题后,很感谢官方将问题发到微博首页,有一个回答我觉得可以采纳:
初步的思考了一下,仅供参考: 首先,提一下索引,相信这个你应该加了索引。
有个问题确认一下,mongodb最新版本中的锁粒度还是Database级别吧,不知道你用的哪个版本,还没到锁表(Collection)这个粒度,所以写并发大的情况下比较糟糕,不过应该性能也不至于糟到像你描述的那样啊?不解,建议考虑任务分库的可能性?
能否考虑把子任务的状态和主任务的状态分开保存。子任务的状态,可以放到redis,主任务只负责自己本身的状态,这样每个主任务更新频率降为1/N,可大大减少mongodb中主任务表的压力。
子任务完成或超时后,可否考虑后台异步单线程顺序同步mongodb的主任务状态?
上面这个Answer可以考虑,但是在做同步过程中发现很多问题。
在开发过程中发现,由单一进程从MongoDB向Redis同步数据,可以采取两种可参考的方案:
1.模拟MongoDB replication机制,一个进程模拟slave向master请求oplog,然后自己解析数据格式存放到Redis.
2.一个进程从MongoDB中按照优先级取数据然后同步到Redis.
两种参考方案各有优劣,我最终选择了第二种。
第一种方案
优点:
1.主MongoDB查询压力变小
2.以后业务扩展很方便(可以运用到查询缓存啊,读写分离什么的)
缺点:
1.可参考文档较少,需要模拟MongoDB replication的机制较为复杂
2.同步实时性无法估计确切时间
第二种方案:
优点:
1.编码相对简单,按照优先级做索引后查询不影响原有逻辑
2.开发较为灵活(似乎和第一点是一样的)
缺点:
1.(项目完成后测试不理想,具体原因会做说明)
2.同步进程单点,如果进程卡死或者机器崩溃会造成系统卡死
方案确定:由单一进程从MongoDB同步任务到Redis.
架构变迁到这样:

加上Redis,做到MongoDB的读写分离,单一进程从MongoDB及时把任务同步到Redis中。
看起来很完美,但是上线后出现了各种各样的问题,列举一下:
1.Redis队列长度为多少合适?
2.同步进程根据优先级从MongoDB向Redis同步过程中,一次取多少任务合适?太大导致很多无谓的开销,太小又会频繁操作MongoDB
3.当某一个子任务处理较慢的时候,会导致MongoDB的前面优先级较高的任务没有结束,而优先级较低的确得不到处理,造成消费者空闲
最终方案:

在生产者产生一个任务的同时,向Redis同步任务,Redis sort set(有序集合,保证优先级顺序不变),消费者通过RPC调用时候,RPC服务器从Redis中取出任务,然后结束任务后从MongoDB中删除。
测试结果,Redis插入效率。Redis-benchmark 并发150,32byte一个任务,一共100W个,插入效率7.3W(不使用持久化)
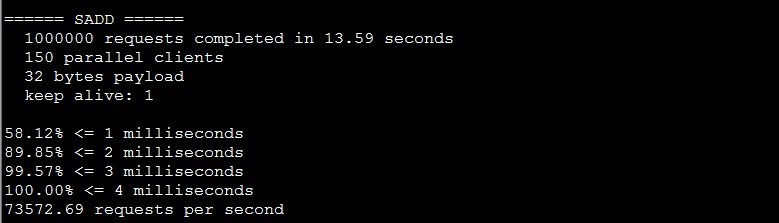
在这之前我们的担心都是没必要的,Redis的性能非常的好。
目前此套系统可以胜任每天5KW量的任务,我相信可以更多。后面有文章可能会讲到Redis的事务操作
U2A9MMB6@UA4C[510.jpg)
[原]分享一下我和MongoDB与Redis那些事的更多相关文章
- MySQL、MongoDB、Redis数据库Docker镜像制作
MySQL.MongoDB.Redis数据库Docker镜像制作 在多台主机上进行数据库部署时,如果使用传统的MySQL的交互式的安装方式将会重复很多遍.如果做成镜像,那么我们只需要make once ...
- Linux系统安装NoSQL(MongoDB和Redis)步骤及问题解决办法
➠更多技术干货请戳:听云博客 如下是我工作中的记录,介绍的是linux系统下NoSQL:MongoDB和Redis的安装过程和遇到的问题以及解决办法: 需要的朋友可以按照如下步骤进行安装,可以快速安装 ...
- Mongodb 和Redis 的相同点和不同点
MongoDB和Redis都是NoSQL,采用结构型数据存储.二者在使用场景中,存在一定的区别,这也主要由于二者在内存映射的处理过程,持久化的处理方法不同.MongoDB建议集群部署,更多的考虑到集群 ...
- MongoDB与Redis的比较
MongoDB和Redis都是NoSQL,采用结构型数据存储.二者在使用场景中,存在一定的区别,这也主要由于二者在内存映射的处理过程,持久化的处理方法不同. MongoDB建议集群部署,更多的考虑到集 ...
- MySQL、MongoDB、Redis 数据库之间的区别
NoSQL 的全称是 Not Only SQL,也可以理解非关系型的数据库,是一种新型的革命式的数据库设计方式,不过它不是为了取代传统的关系型数据库而被设计的,它们分别代表了不同的数据库设计思路. M ...
- 百万级运维心得一:Mongodb和Redis数据不能放在同一个服务器
百万级运维经验一:Mongodb和Redis数据不能放在同一个服务器 一开始时,为了省服务器,把Mongodb和Redis放在一个服务器上.网站每到高峰期都特别卡,还经常出现502.找了很久的原因,发 ...
- mongodb,redis,memcached,mysql对比
1.性能都比较高,性能对我们来说应该都不是瓶颈总体来讲,TPS方面redis和memcache差不多,要大于mongodb 2.操作的便利性memcache数据结构单一redis丰富一些,数据操作方面 ...
- 3类数据库的联动:mysql、mongodb、redis
3类数据库的联动:mysql.mongodb.redis from pymysql import * from pymongo import * from redis import * class M ...
- 数据库基础 非关系型数据库 MongoDB 和 redis
数据库基础 非关系型数据库 MongoDB 和 redis 1 NoSQL简介 访问量增加,频繁的读写 直接访问(硬盘)物理级别的数据,会很慢 ,关系型数据库的压力会很大 所以,需要内存级的读写操作, ...
随机推荐
- 再谈CAAnimation动画
CAAnimaton动画分为CABasicAnimation & CAKeyframeAnimation CABasicAnimation动画, 顾名思义就是最基本的动画, 老规矩先上代码: ...
- netty5 HTTP协议栈浅析与实践
一.说在前面的话 前段时间,工作上需要做一个针对视频质量的统计分析系统,各端(PC端.移动端和 WEB端)将视频质量数据放在一个 HTTP 请求中上报到服务器,服务器对数据进行解析.分拣后从不同的 ...
- 主成分分析(PCA)原理总结
主成分分析(Principal components analysis,以下简称PCA)是最重要的降维方法之一.在数据压缩消除冗余和数据噪音消除等领域都有广泛的应用.一般我们提到降维最容易想到的算法就 ...
- 解读发布:.NET Core RC2 and .NET Core SDK Preview 1
先看一下 .NET Core(包含 ASP.NET Core)的路线图: Beta6: 2015年7月27日 Beta7: 2015年9月2日 Beta8: 2015年10月15日 RC1: 2015 ...
- Android 几种消息推送方案总结
转载请注明出处:http://www.cnblogs.com/Joanna-Yan/p/6241354.html 首先看一张国内Top500 Android应用中它们用到的第三方推送以及所占数量: 现 ...
- 如何使用本地账户"完整"安装 SharePoint Server 2010+解决“New-SPConfigurationDatabase : 无法连接到 SharePoint_Config 的 SQL Server 的数据 库 master。此数据库可能不存在,或当前用户没有连接权限。”
注:目前看到的解决本地账户完整安装SharePoint Server 2010的解决方案如下,但是,有但是的哦: 当我们选择了"完整"模式安装SharePointServer201 ...
- 在禅道中实现WORD等OFFICE文档转换为PDF进行在线浏览
条件: 安装好禅道的服务器 能直接浏览PDF的浏览器(或通过 安装插件实现 ) 文档转换服务程序(建议部署在另一台服务器上) 实现 原理: 修改禅道的文件预览功能(OFFICE文档其使用的是下 ...
- 多个ul中第一个li获取定位
如果我们只是获取一个ul中的第一个li的话,那么我们可以这样写: $("ul li:first"); $("ul li").eq(0); $("ul ...
- OpenGL ES 3.0: 图元重启(Primitive restart)
[TOC] 背景概述 在OpenGL绘制图形时,可能需要绘制多个并不相连的图形.这样的情况下这几个图形没法被当做一个图形来处理.也就需要多次调用 DrawArrays 或 DrawElements. ...
- [PHP源码阅读]count函数
在PHP编程中,在遍历数组的时候经常需要先计算数组的长度作为循环结束的判断条件,而在PHP里面对数组的操作是很频繁的,因此count也算是一个常用函数,下面研究一下count函数的具体实现. 我在gi ...