Redis 命令执行过程(下)
在上一篇文章中《Redis 命令执行过程(上)》中,我们首先了解 Redis 命令执行的整体流程,然后细致分析了从 Redis 启动到建立 socket 连接,再到读取 socket 数据到输入缓冲区,解析命令,执行命令等过程的原理和实现细节。接下来,我们来具体看一下 set 和 get 命令的实现细节和如何将命令结果通过输出缓冲区和 socket 发送给 Redis 客户端。
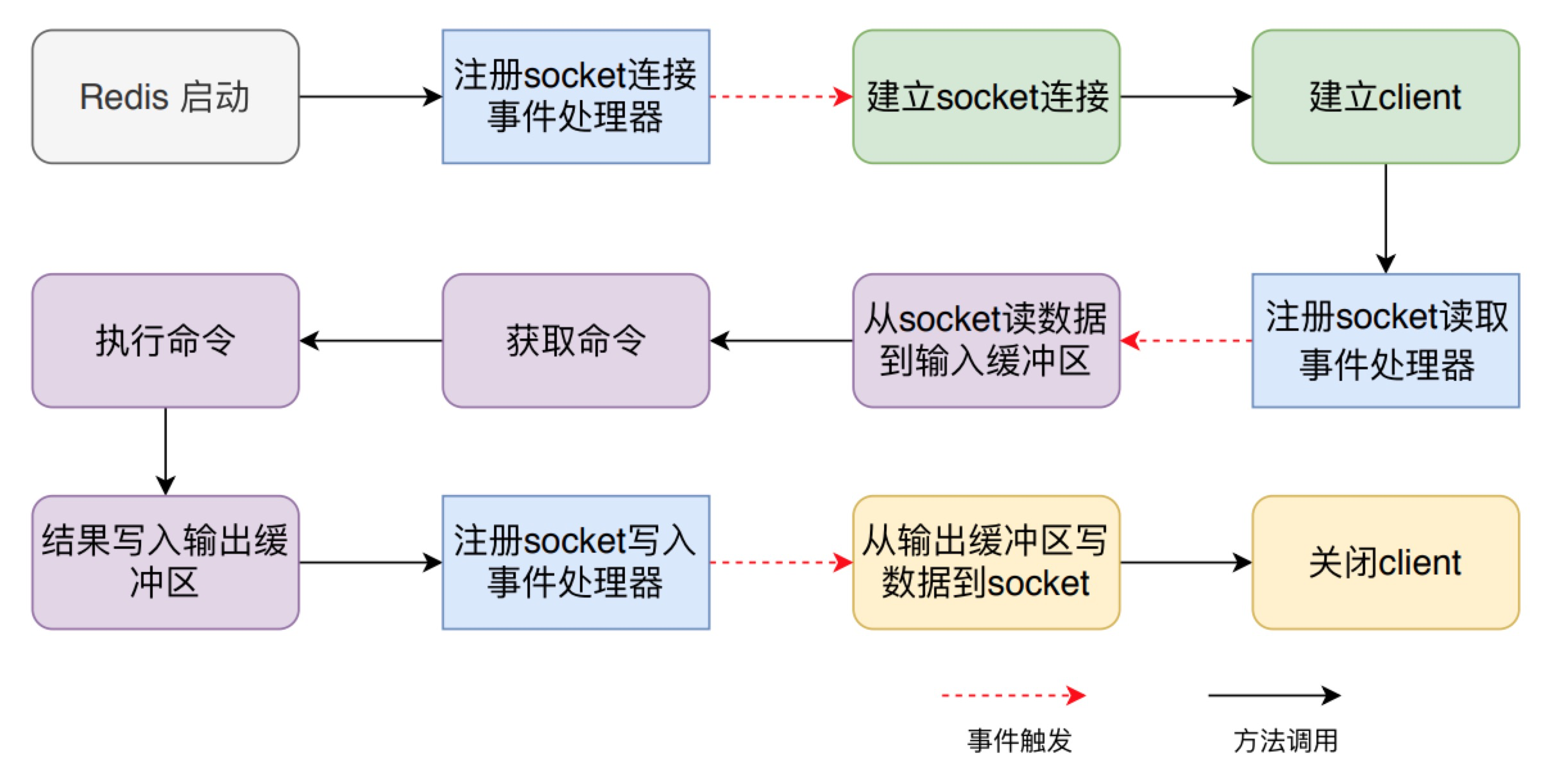
set 和 get 命令具体实现
前文讲到 processCommand 方法会从输入缓冲区中解析出对应的 redisCommand,然后调用 call 方法执行解析出来的 redisCommand的 proc 方法。不同命令的的 proc 方法是不同的,比如说名为 set 的 redisCommand 的 proc 是 setCommand 方法,而 get 的则是 getCommand 方法。通过这种形式,实际上实现在Java 中特别常见的多态策略。
void call(client *c, int flags) {
....
c->cmd->proc(c);
....
}
// redisCommand结构体
struct redisCommand {
char *name;
// 对应方法的函数范式
redisCommandProc *proc;
.... // 其他定义
};
// 使用 typedef 定义的别名
typedef void redisCommandProc(client *c);
// 不同的命令,调用不同的方法。
struct redisCommand redisCommandTable[] = {
{"get",getCommand,2,"rF",0,NULL,1,1,1,0,0},
{"set",setCommand,-3,"wm",0,NULL,1,1,1,0,0},
{"hmset",hsetCommand,-4,"wmF",0,NULL,1,1,1,0,0},
.... // 所有的 redis 命令都有
}

setCommand 会判断set命令是否携带了nx、xx、ex或者px等可选参数,然后调用setGenericCommand命令。我们直接来看 setGenericCommand 方法。
setGenericCommand 方法的处理逻辑如下所示:
- 首先判断 set 的类型是 set_nx 还是 set_xx,如果是 nx 并且 key 已经存在则直接返回;如果是 xx 并且 key 不存在则直接返回。
- 调用 setKey 方法将键值添加到对应的 Redis 数据库中。
- 如果有过期时间,则调用 setExpire 将设置过期时间
- 进行键空间通知
- 返回对应的值给客户端。
// t_string.c
void setGenericCommand(client *c, int flags, robj *key, robj *val, robj *expire, int unit, robj *ok_reply, robj *abort_reply) {
long long milliseconds = 0;
/**
* 设置了过期时间;expire是robj类型,获取整数值
*/
if (expire) {
if (getLongLongFromObjectOrReply(c, expire, &milliseconds, NULL) != C_OK)
return;
if (milliseconds <= 0) {
addReplyErrorFormat(c,"invalid expire time in %s",c->cmd->name);
return;
}
if (unit == UNIT_SECONDS) milliseconds *= 1000;
}
/**
* NX,key存在时直接返回;XX,key不存在时直接返回
* lookupKeyWrite 是在对应的数据库中寻找键值是否存在
*/
if ((flags & OBJ_SET_NX && lookupKeyWrite(c->db,key) != NULL) ||
(flags & OBJ_SET_XX && lookupKeyWrite(c->db,key) == NULL))
{
addReply(c, abort_reply ? abort_reply : shared.nullbulk);
return;
}
/**
* 添加到数据字典
*/
setKey(c->db,key,val);
server.dirty++;
/**
* 过期时间添加到过期字典
*/
if (expire) setExpire(c,c->db,key,mstime()+milliseconds);
/**
* 键空间通知
*/
notifyKeyspaceEvent(NOTIFY_STRING,"set",key,c->db->id);
if (expire) notifyKeyspaceEvent(NOTIFY_GENERIC,
"expire",key,c->db->id);
/**
* 返回值,addReply 在 get 命令时再具体讲解
*/
addReply(c, ok_reply ? ok_reply : shared.ok);
}
具体 setKey 和 setExpire 的方法实现我们这里就不细讲,其实就是将键值添加到db的 dict 数据哈希表中,将键和过期时间添加到 expires 哈希表中,如下图所示。

接下来看 getCommand 的具体实现,同样的,它底层会调用 getGenericCommand 方法。
getGenericCommand 方法会调用 lookupKeyReadOrReply 来从 dict 数据哈希表中查找对应的 key值。如果找不到,则直接返回 C_OK;如果找到了,则根据值的类型,调用 addReply 或者 addReplyBulk 方法将值添加到输出缓冲区中。
int getGenericCommand(client *c) {
robj *o;
// 调用 lookupKeyReadOrReply 从数据字典中查找对应的键
if ((o = lookupKeyReadOrReply(c,c->argv[1],shared.nullbulk)) == NULL)
return C_OK;
// 如果是string类型,调用 addReply 单行返回。如果是其他对象类型,则调用 addReplyBulk
if (o->type != OBJ_STRING) {
addReply(c,shared.wrongtypeerr);
return C_ERR;
} else {
addReplyBulk(c,o);
return C_OK;
}
}
lookupKeyReadWithFlags 会从 redisDb 中查找对应的键值对,它首先会调用 expireIfNeeded判断键是否过期并且需要删除,如果为过期,则调用 lookupKey 方法从 dict 哈希表中查找并返回。具体解释可以看代码中的详细注释
/*
* 查找key的读操作,如果key找不到或者已经逻辑上过期返回 NULL,有一些副作用
* 1 如果key到达过期时间,它会被设备为过期,并且删除
* 2 更新key的最近访问时间
* 3 更新全局缓存击中概率
* flags 有两个值: LOOKUP_NONE 一般都是这个;LOOKUP_NOTOUCH 不修改最近访问时间
*/
robj *lookupKeyReadWithFlags(redisDb *db, robj *key, int flags) { // db.c
robj *val;
// 检查键是否过期
if (expireIfNeeded(db,key) == 1) {
.... // master和 slave 对这种情况的特殊处理
}
// 查找键值字典
val = lookupKey(db,key,flags);
// 更新全局缓存命中率
if (val == NULL)
server.stat_keyspace_misses++;
else
server.stat_keyspace_hits++;
return val;
}
Redis 在调用查找键值系列方法前都会先调用 expireIfNeeded 来判断键是否过期,然后根据 Redis 是否配置了懒删除来进行同步删除或者异步删除。关于键删除的细节可以查看《详解 Redis 内存管理机制和实现》一文。
在判断键释放过期的逻辑中有两个特殊情况:
- 如果当前 Redis 是主从结构中的从实例,则只判断键是否过期,不直接对键进行删除,而是要等待主实例发送过来的删除命令后再进行删除。如果当前 Redis 是主实例,则调用 propagateExpire 来传播过期指令。
- 如果当前正在进行 Lua 脚本执行,因为其原子性和事务性,整个执行过期中时间都按照其开始执行的那一刻计算,也就是说lua执行时未过期的键,在它整个执行过程中也都不会过期。
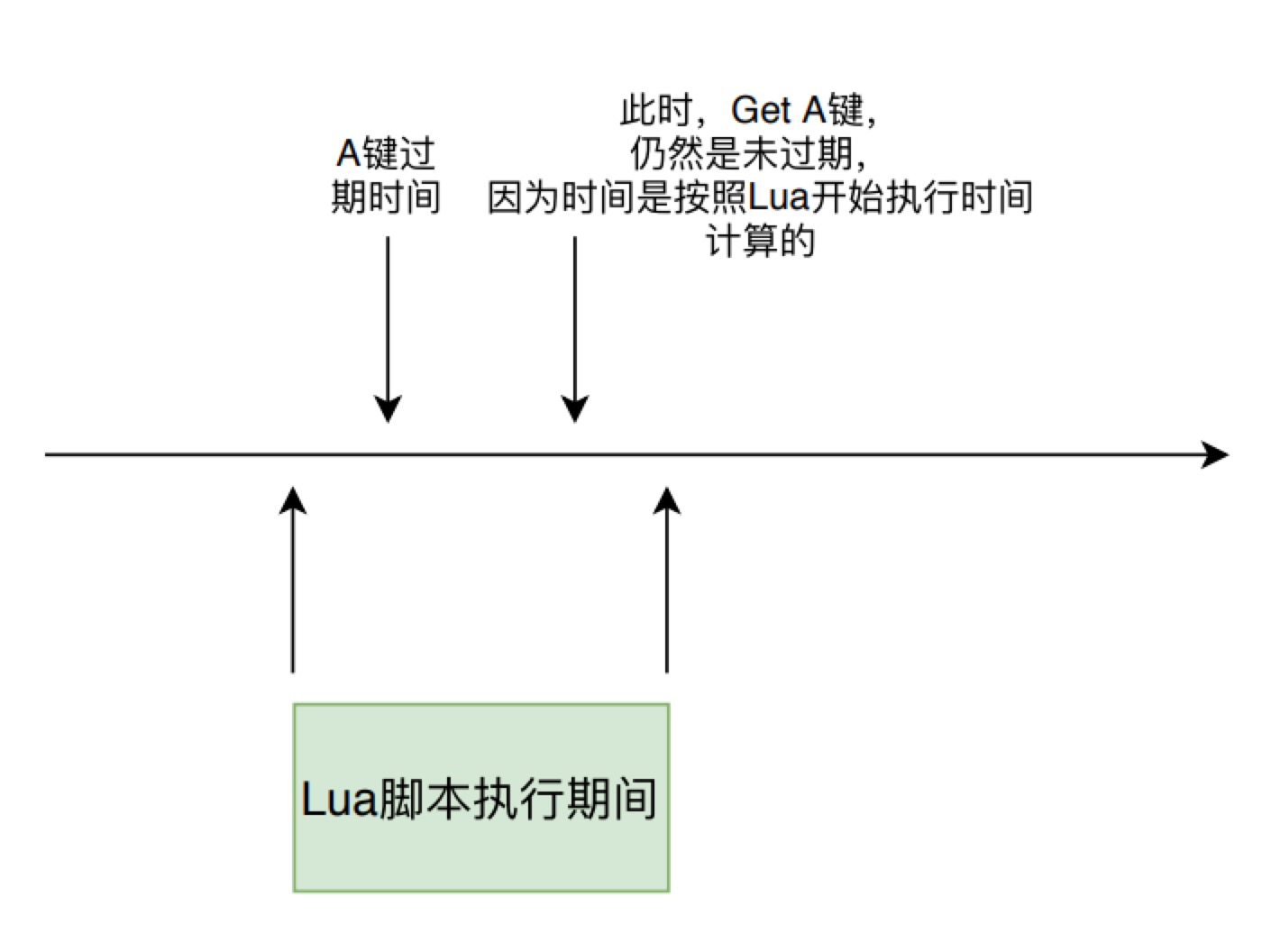
/*
* 在调用 lookupKey*系列方法前调用该方法。
* 如果是slave:
* slave 并不主动过期删除key,但是返回值仍然会返回键已经被删除。
* master 如果key过期了,会主动删除过期键,并且触发 AOF 和同步操作。
* 返回值为0表示键仍然有效,否则返回1
*/
int expireIfNeeded(redisDb *db, robj *key) { // db.c
// 获取键的过期时间
mstime_t when = getExpire(db,key);
mstime_t now;
if (when < 0) return 0;
/*
* 如果当前是在执行lua脚本,根据其原子性,整个执行过期中时间都按照其开始执行的那一刻计算
* 也就是说lua执行时未过期的键,在它整个执行过程中也都不会过期。
*/
now = server.lua_caller ? server.lua_time_start : mstime();
// slave 直接返回键是否过期
if (server.masterhost != NULL) return now > when;
// master时,键未过期直接返回
if (now <= when) return 0;
// 键过期,删除键
server.stat_expiredkeys++;
// 触发命令传播
propagateExpire(db,key,server.lazyfree_lazy_expire);
// 和键空间事件
notifyKeyspaceEvent(NOTIFY_EXPIRED,
"expired",key,db->id);
// 根据是否懒删除,调用不同的函数
return server.lazyfree_lazy_expire ? dbAsyncDelete(db,key) :
dbSyncDelete(db,key);
}
lookupKey 方法则是通过 dictFind 方法从 redisDb 的 dict 哈希表中查找键值,如果能找到,则根据 redis 的 maxmemory_policy 策略来判断是更新 lru 的最近访问时间,还是调用 updateFU 方法更新其他指标,这些指标可以在后续内存不足时对键值进行回收。
robj *lookupKey(redisDb *db, robj *key, int flags) {
// dictFind 根据 key 获取字典的entry
dictEntry *de = dictFind(db->dict,key->ptr);
if (de) {
// 获取 value
robj *val = dictGetVal(de);
// 当处于 rdb aof 子进程复制阶段或者 flags 不是 LOOKUP_NOTOUCH
if (server.rdb_child_pid == -1 &&
server.aof_child_pid == -1 &&
!(flags & LOOKUP_NOTOUCH))
{
// 如果是 MAXMEMORY_FLAG_LFU 则进行相应操作
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
updateLFU(val);
} else {
// 更新最近访问时间
val->lru = LRU_CLOCK();
}
}
return val;
} else {
return NULL;
}
}
将命令结果写入输出缓冲区
在所有的 redisCommand 执行的最后,一般都会调用 addReply 方法进行结果返回,我们的分析也来到了 Redis 命令执行的返回数据阶段。
addReply 方法做了两件事情:
- prepareClientToWrite 判断是否需要返回数据,并且将当前 client 添加到等待写返回数据队列中。
- 调用 _addReplyToBuffer 和 _addReplyObjectToList 方法将返回值写入到输出缓冲区中,等待写入 socekt。
void addReply(client *c, robj *obj) {
if (prepareClientToWrite(c) != C_OK) return;
if (sdsEncodedObject(obj)) {
// 需要将响应内容添加到output buffer中。总体思路是,先尝试向固定buffer添加,添加失败的话,在尝试添加到响应链表
if (_addReplyToBuffer(c,obj->ptr,sdslen(obj->ptr)) != C_OK)
_addReplyObjectToList(c,obj);
} else if (obj->encoding == OBJ_ENCODING_INT) {
.... // 特殊情况的优化
} else {
serverPanic("Wrong obj->encoding in addReply()");
}
}
prepareClientToWrite 首先判断了当前 client是否需要返回数据:
- Lua 脚本执行的 client 则需要返回值;
- 如果客户端发送来 REPLY OFF 或者 SKIP 命令,则不需要返回值;
- 如果是主从复制时的主实例 client,则不需要返回值;
- 当前是在 AOF loading 状态的假 client,则不需要返回值。
接着如果这个 client 还未处于延迟等待写入 (CLIENT_PENDING_WRITE)的状态,则将其设置为该状态,并将其加入到 Redis 的等待写入返回值客户端队列中,也就是 clients_pending_write队列。
int prepareClientToWrite(client *c) {
// 如果是 lua client 则直接OK
if (c->flags & (CLIENT_LUA|CLIENT_MODULE)) return C_OK;
// 客户端发来过 REPLY OFF 或者 SKIP 命令,不需要发送返回值
if (c->flags & (CLIENT_REPLY_OFF|CLIENT_REPLY_SKIP)) return C_ERR;
// master 作为client 向 slave 发送命令,不需要接收返回值
if ((c->flags & CLIENT_MASTER) &&
!(c->flags & CLIENT_MASTER_FORCE_REPLY)) return C_ERR;
// AOF loading 时的假client 不需要返回值
if (c->fd <= 0) return C_ERR;
// 将client加入到等待写入返回值队列中,下次事件周期会进行返回值写入。
if (!clientHasPendingReplies(c) &&
!(c->flags & CLIENT_PENDING_WRITE) &&
(c->replstate == REPL_STATE_NONE ||
(c->replstate == SLAVE_STATE_ONLINE && !c->repl_put_online_on_ack)))
{
// 设置标志位并且将client加入到 clients_pending_write 队列中
c->flags |= CLIENT_PENDING_WRITE;
listAddNodeHead(server.clients_pending_write,c);
}
// 表示已经在排队,进行返回数据
return C_OK;
}
Redis 将存储等待返回的响应数据的空间,也就是输出缓冲区分成两部分,一个固定大小的 buffer 和一个响应内容数据的链表。在链表为空并且 buffer 有足够空间时,则将响应添加到 buffer 中。如果 buffer 满了则创建一个节点追加到链表上。_addReplyToBuffer 和 _addReplyObjectToList 就是分别向这两个空间写数据的方法。

固定buffer和响应链表,整体上构成了一个队列。这么组织的好处是,既可以节省内存,不需一开始预先分配大块内存,并且可以避免频繁分配、回收内存。
上面就是响应内容写入输出缓冲区的过程,下面看一下将数据从输出缓冲区写入 socket 的过程。
prepareClientToWrite 函数,将客户端加入到了Redis 的等待写入返回值客户端队列中,也就是 clients_pending_write 队列。请求处理的事件处理逻辑就结束了,等待 Redis 下一次事件循环处理时,将响应从输出缓冲区写入到 socket 中。
将命令返回值从输出缓冲区写入 socket
在 《Redis 事件机制详解》
一文中我们知道,Redis 在两次事件循环之间会调用 beforeSleep 方法处理一些事情,而对 clients_pending_write 列表的处理就在其中。
下面的 aeMain 方法就是 Redis 事件循环的主逻辑,可以看到每次循环时都会调用 beforesleep 方法。
void aeMain(aeEventLoop *eventLoop) { // ae.c
eventLoop->stop = 0;
while (!eventLoop->stop) {
/* 如果有需要在事件处理前执行的函数,那么执行它 */
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
/* 开始处理事件*/
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP);
}
}
beforeSleep 函数会调用 handleClientsWithPendingWrites 函数来处理 clients_pending_write 列表。
handleClientsWithPendingWrites 方法会遍历 clients_pending_write 列表,对于每个 client 都会先调用 writeToClient 方法来尝试将返回数据从输出缓存区写入到 socekt中,如果还未写完,则只能调用 aeCreateFileEvent 方法来注册一个写数据事件处理器 sendReplyToClient,等待 Redis 事件机制的再次调用。
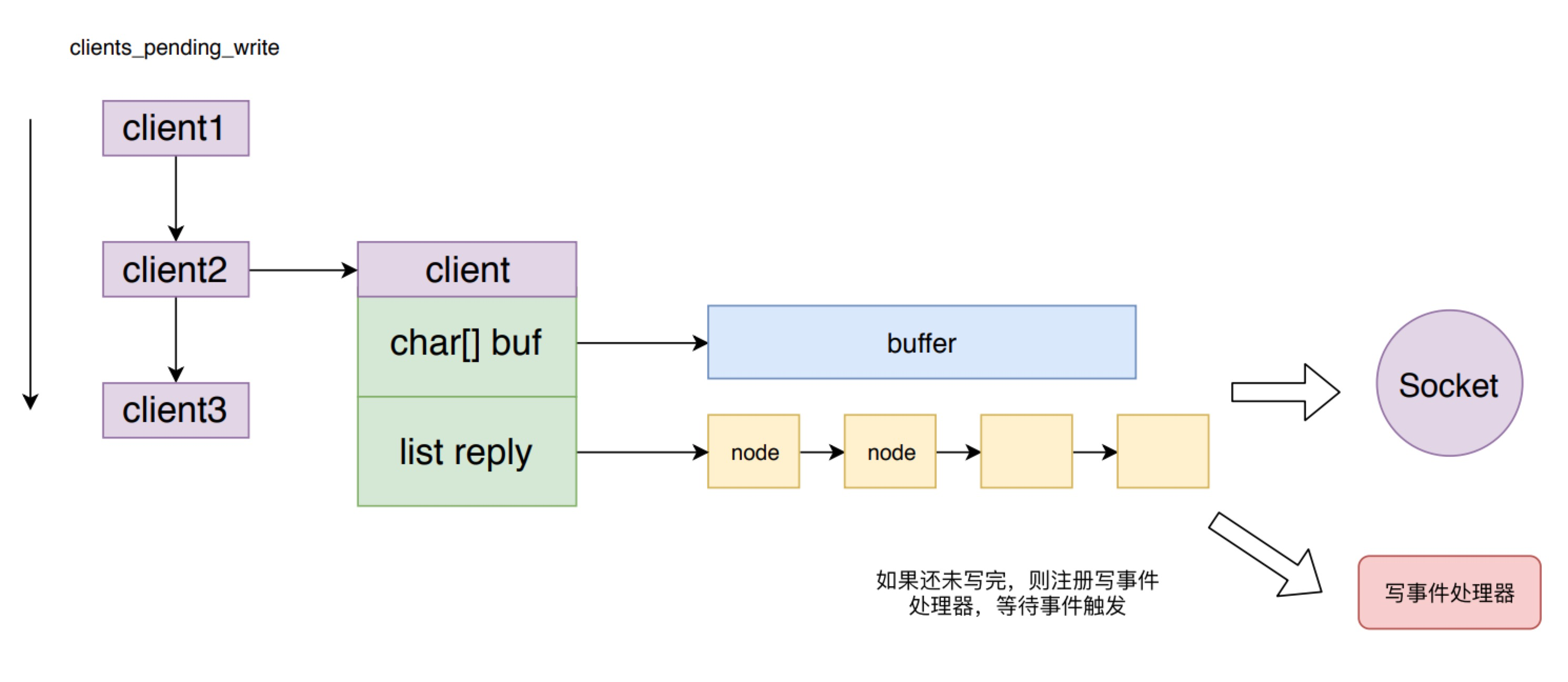
这样的好处是对于返回数据较少的客户端,不需要麻烦的注册写数据事件,等待事件触发再写数据到 socket,而是在下一次事件循环周期就直接将数据写到 socket中,加快了数据返回的响应速度。
但是从这里也会发现,如果 clients_pending_write 队列过长,则处理时间也会很久,阻塞正常的事件响应处理,导致 Redis 后续命令延时增加。
// 直接将返回值写到client的输出缓冲区中,不需要进行系统调用,也不需要注册写事件处理器
int handleClientsWithPendingWrites(void) {
listIter li;
listNode *ln;
// 获取系统延迟写队列的长度
int processed = listLength(server.clients_pending_write);
listRewind(server.clients_pending_write,&li);
// 依次处理
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_WRITE;
listDelNode(server.clients_pending_write,ln);
// 将缓冲值写入client的socket中,如果写完,则跳过之后的操作。
if (writeToClient(c->fd,c,0) == C_ERR) continue;
// 还有数据未写入,只能注册写事件处理器了
if (clientHasPendingReplies(c)) {
int ae_flags = AE_WRITABLE;
if (server.aof_state == AOF_ON &&
server.aof_fsync == AOF_FSYNC_ALWAYS)
{
ae_flags |= AE_BARRIER;
}
// 注册写事件处理器 sendReplyToClient,等待执行
if (aeCreateFileEvent(server.el, c->fd, ae_flags,
sendReplyToClient, c) == AE_ERR)
{
freeClientAsync(c);
}
}
}
return processed;
}
sendReplyToClient 方法其实也会调用 writeToClient 方法,该方法就是将输出缓冲区中的 buf 和 reply 列表中的数据都尽可能多的写入到对应的 socket中。
// 将输出缓冲区中的数据写入socket,如果还有数据未处理则返回C_OK
int writeToClient(int fd, client *c, int handler_installed) {
ssize_t nwritten = 0, totwritten = 0;
size_t objlen;
sds o;
// 仍然有数据未写入
while(clientHasPendingReplies(c)) {
// 如果缓冲区有数据
if (c->bufpos > 0) {
// 写入到 fd 代表的 socket 中
nwritten = write(fd,c->buf+c->sentlen,c->bufpos-c->sentlen);
if (nwritten <= 0) break;
c->sentlen += nwritten;
// 统计本次一共输出了多少子节
totwritten += nwritten;
// buffer中的数据已经发送,则重置标志位,让响应的后续数据写入buffer
if ((int)c->sentlen == c->bufpos) {
c->bufpos = 0;
c->sentlen = 0;
}
} else {
// 缓冲区没有数据,从reply队列中拿
o = listNodeValue(listFirst(c->reply));
objlen = sdslen(o);
if (objlen == 0) {
listDelNode(c->reply,listFirst(c->reply));
continue;
}
// 将队列中的数据写入 socket
nwritten = write(fd, o + c->sentlen, objlen - c->sentlen);
if (nwritten <= 0) break;
c->sentlen += nwritten;
totwritten += nwritten;
// 如果写入成功,则删除队列
if (c->sentlen == objlen) {
listDelNode(c->reply,listFirst(c->reply));
c->sentlen = 0;
c->reply_bytes -= objlen;
if (listLength(c->reply) == 0)
serverAssert(c->reply_bytes == 0);
}
}
// 如果输出的字节数量已经超过NET_MAX_WRITES_PER_EVENT限制,break
if (totwritten > NET_MAX_WRITES_PER_EVENT &&
(server.maxmemory == 0 ||
zmalloc_used_memory() < server.maxmemory) &&
!(c->flags & CLIENT_SLAVE)) break;
}
server.stat_net_output_bytes += totwritten;
if (nwritten == -1) {
if (errno == EAGAIN) {
nwritten = 0;
} else {
serverLog(LL_VERBOSE,
"Error writing to client: %s", strerror(errno));
freeClient(c);
return C_ERR;
}
}
if (!clientHasPendingReplies(c)) {
c->sentlen = 0;
//如果内容已经全部输出,删除事件处理器
if (handler_installed) aeDeleteFileEvent(server.el,c->fd,AE_WRITABLE);
// 数据全部返回,则关闭client和连接
if (c->flags & CLIENT_CLOSE_AFTER_REPLY) {
freeClient(c);
return C_ERR;
}
}
return C_OK;
}

Redis 命令执行过程(下)的更多相关文章
- Redis 命令执行过程(上)
今天我们来了解一下 Redis 命令执行的过程.在之前的文章中<当 Redis 发生高延迟时,到底发生了什么>我们曾简单的描述了一条命令的执行过程,本篇文章展示深入说明一下,加深读者对 R ...
- Redis 命令执行全过程分析
今天我们来了解一下 Redis 命令执行的过程.我们曾简单的描述了一条命令的执行过程,本篇文章展示深入说明一下,加深大家对 Redis 的了解. 如下图所示,一条命令执行完成并且返回数据一共涉及三部分 ...
- ping命令执行过程详解
[TOC] ping命令执行过程详解 机器A ping 机器B 同一网段 ping通知系统建立一个固定格式的ICMP请求数据包 ICMP协议打包这个数据包和机器B的IP地址转交给IP协议层(一组后台运 ...
- Linux命令执行过程
目录 一.命令分类 二.命令执行顺序 三.命令分类及查找基本命令 四.命令执行过程 一.命令分类 Linux命令分为两类,具体为内部命令和外部命令 内部命令: 指shell内部集成的命令,此类命令无需 ...
- saltstack命令执行过程
saltstack命令执行过程 具体步骤如下 Salt stack的Master与Minion之间通过ZeroMq进行消息传递,使用了ZeroMq的发布-订阅模式,连接方式包括tcp,ipc salt ...
- U-Boot添加menu命令的方法及U-Boot命令执行过程
转;http://chenxing777414.blog.163.com/blog/static/186567350201141791224740/ 下面以添加menu命令(启动菜单)为例讲解U-Bo ...
- 探索Redis设计与实现10:Redis的事件驱动模型与命令执行过程
本文转自互联网 本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial ...
- Linux下shell命令执行过程简介
Linux是如何寻找命令路径的:http://c.biancheng.net/view/5969.html Linux上命令运行的基本过程:https://blog.csdn.net/hjx5200/ ...
- memcahced&redis命令行cmd下的操作
一.memcahced 1.安装 执行memcached.exe -d install 把memcached加入到服务中 执行memcached.exe -d uninstall 卸载memcac ...
随机推荐
- Weblogic 12c 的 Apache HTTP Server 整合插件(Plug-In)下载地址
资料来源:到哪里下载Weblogic 12c 的Plug-In 为 Apache HTTP Server 摘录如下: 最新的Weblogic 12c不再为 Apache HTTP Server提供缺省 ...
- Spring Boot Actuator监控使用详解
在企业级应用中,学习了如何进行SpringBoot应用的功能开发,以及如何写单元测试.集成测试等还是不够的.在实际的软件开发中还需要:应用程序的监控和管理.SpringBoot的Actuator模块实 ...
- Intellij IDEA搭建JSP+Tomcat开发环境
1.新建项目 然后填入项目名称和选择项目路径,填完点击完成. 2.添加WEB框架 别问我为什么不一开始就直接新建WEB框架,因为我也是看的别人的教程0.0 不过还遇到了一些新问题,后面会讲到 3.配置 ...
- 用PHP+Redis实现延迟任务,实现自动取消订单
简单定时任务解决方案:使用redis的keyspace notifications(键失效后通知事件) 需要注意此功能是在redis 2.8版本以后推出的,因此你服务器上的reids最少要是2.8版本 ...
- Jumpserver v2.0.0 使用说明
官方文档:http://www.jumpserver.org/ — 登录脚本 — 1.1 使用paramiko原生ssh协议登录后端主机(原来版本使用pexpect模拟登录) 1.2 新增使用别名或备 ...
- ZeroC ICE的远程调用框架 ServantLocator与Locator
ServantLocator定位的目标是Servant,而Locator定位的目标是“Ice Object”,即一个可定位的“Ice Object”代理.Servant是::Ice::Object的继 ...
- 微信小程序-rpx
rpx 是微信小程序解决自适应屏幕尺寸的尺寸单位.微信小程序规定屏幕的宽度为750rpx. 微信小程序同时也支持rem尺寸单位, rem 规定屏幕的宽度为20rem, 所以 1rem = (750/2 ...
- Linux基础命令复习01
一.Linux中的基本查看.查找命令: 1.ls 查看目录信息: -l #查看属性,以长格式显示 -d #查看本身属性 -A #显示包括以.开头的隐藏文档 -h #提供易读的单位 -R #表示递 ...
- 程序员用于机器学习数据科学的3个顶级 Python 库
NumPy NumPy(数值 Python 的简称)是其中一个顶级数据科学库,它拥有许多有用的资源,从而帮助数据科学家把 Python 变成一个强大的科学分析和建模工具.NumPy 是在 BSD 许可 ...
- vue 父子组件传值,兄弟组件传值
父子组件中的传值 父向子 v-bind props <!-- 组件使用v-bind传值 --> <router :msg="msg"></rou ...