Atlassian In Action-Jira之二次开发(五)
到现在已经写到了第五章节,实际上离Jira的官方系统已经越来越远,本章节的内容基本上已经完全脱离了Jira这个系统本身,而是依赖Jira的API接口和数据库进行开发了。主要包含如下几个功能:
- 人员任务排期管理
- 历史人员任务排期检查
- BI报表
注意:
由于我们的二次开发基本都是做成静态页面,但是大量使用了Jira的API接口,为了能够方便的使用。所以我们将这些页面放到Jira的容器当中,在其中建立了一个目录。这样就能够和Jira在同一个域名下,只要Jira系统有登录,访问接口都是不需要额外进行认证的。
人员任务排期管理
背景
这个页面的需求实际上是源自于BigGantt这个插件,我们前面讲过这是一个非常强大的插件,对于迭代的任务管理有很大的帮助。
但是在慢慢的使用过程中产生了一个管理的场景:有一个重点项目占用了一部分的研发力量,需要了解这部分的任务安排情况。并且当任务有变更的时候,能够快速了解是否还有研发资源可以安排调整。
分析之后我们了解到,实际上这个需求有两个重点,一要有一个任务列表(通常是一个JQL语句筛选出的主任务列表),二要有涉及的人力资源和子任务清单。BigGantt是否满足呢?它可以根据JQL筛选出任务列表,但是这个列表只能够以任务为视角展开。当我们需要评估某个人员排期如何,是否能够插入或者调整时,没有太好的界面来清晰的展示。
实现
所以我们设计了如下的功能:
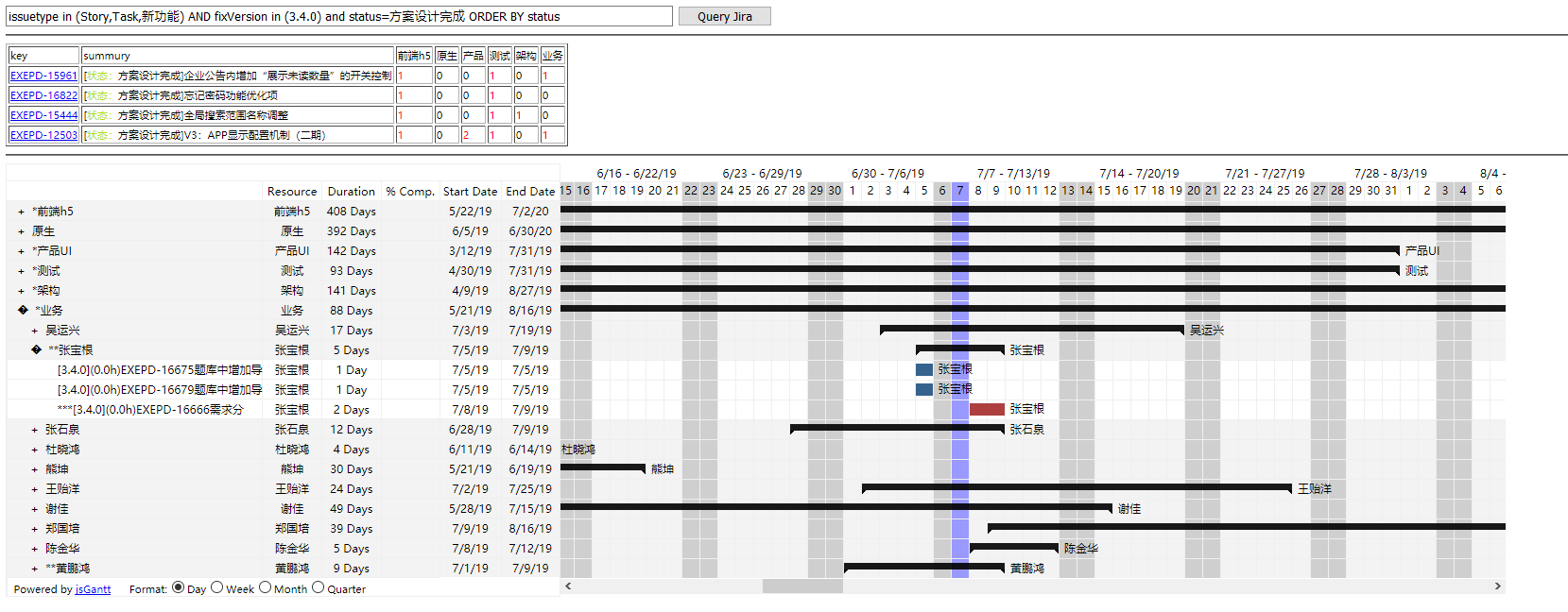
可以看到这个界面分为三部分
第一部分是文本输入框,用于执行JQL语句。
第二部分是主任务列表。
第三部分是人力资源甘特图。
任务列表通过
https://jira.yourdomain.com/rest/api/2/search?jql=' + jqlstr + '&maxResults=9999
接口就可以获取任务的json数据。
人力资源甘特图是写了一个python脚本启动了一个web容器,从jira的底层数据库读取数据,组织返回json。获取的就是所有研发中心人员未完成的子任务。为什么要用python?因为Jira这台服务器上没有其他容器,如果要安装tomcat之类的太麻烦,还要做一个mvc框架之类的东西或者直接写jsp,太麻烦了。
下面给出获取数据的sql:
select concat(a.id) as pissueId,
ifnull(concat("EXEPD-", k.issuenum),"无父任务") as pikey,
k.SUMMARY as pisummary,
concat("EXEPD-", a.issuenum) as ikey,
'子任务' as itype,
a.SUMMARY,
b.pname,
ifnull(ifnull(i.vname, e.customvalue), '版本为空') as vname,
ac.last_name,
ad.lower_parent_name,
(case ad.lower_parent_name
when 'org-pd-qa' then '测试'
when 'org-pd-frontside-h5' then '前端h5'
when 'org-pd-frontside-native' then '原生'
when 'org-pd-serverside-b' then '业务'
when 'org-pd-serverside-a' then '架构'
when 'org-pd-product' then '产品UI'
else '' end) as deptname,
DATE_FORMAT(a.CREATED,'%Y-%m-%d') as creatdate,
DATE_FORMAT(a.DUEDATE,'%m/%d/%Y') as enddate,
DATE_FORMAT(cd.DATEVALUE,'%m/%d/%Y') as startdate,
concat(ab.ID) as asid,
concat(ad.parent_id) as dpid,
concat(ROUND(ifnull(a.TIMESPENT,0) / 3600, 1)) as timespent,
ab.lower_user_name asname,
1 as nums
from jiraissue a
join app_user ab on ab.user_key = a.ASSIGNEE
join cwd_user ac on ac.lower_user_name = ab.lower_user_name
join cwd_membership ad on ad.lower_child_name = ab.lower_user_name and ad.lower_parent_name in
('org-pd-frontside-h5',
'org-pd-frontside-native',
'org-pd-serverside-a',
'org-pd-serverside-b',
'org-pd-qa',
'org-pd-product')
join issuestatus b on b.ID = a.issuestatus
left join nodeassociation f on f.SOURCE_NODE_ID = a.ID and f.ASSOCIATION_TYPE = 'IssueFixVersion'
left join projectversion i on i.ID = f.SINK_NODE_ID
left join customfield c on c.cfname = '修正状态'
left join customfieldvalue d on d.CUSTOMFIELD = c.id and d.ISSUE = a.ID
left join customfieldoption e on e.CUSTOMFIELD = c.ID and e.id = d.STRINGVALUE
left join customfieldvalue dd on dd.CUSTOMFIELD = 10400 and dd.ISSUE = a.ID
left join customfieldoption de on de.CUSTOMFIELD = 10400 and de.id = dd.STRINGVALUE
left join customfield cc on cc.cfname = '开始日'
left join customfieldvalue cd on cd.CUSTOMFIELD = cc.id and cd.ISSUE = a.ID
left join issuelink j on j.DESTINATION = a.ID
left join jiraissue k on k.ID = j.SOURCE
where a.issuetype = 10003
and a.PROJECT = 10000
and a.issuestatus != 10001
and a.PRIORITY<=5
order by ad.lower_parent_name,ac.last_name,cd.DATEVALUE
这里面就涉及到对于Jira数据库的了解了,jiraissue 是issue的库,app_user 是人员库,cwd_membership是分组库,customfield 、customfieldoption 、customfieldvalue 是自定义字段的三件套。这个语句并不能直接在任何Jira系统上使用,因为里面有较多的自定义设置规则。
比如我们增加了开始日、修正状态两个自定义字段,而且定义了一种优先级是在当前的管理面板忽略的(所以才有 PRIORITY<=5 这个条件)。
有了任务列表和人力资源列表,我们就要把两者结合起来了。
首先我们使用的Gantt插件是JSGantt,这个插件还是很简单的。我们的甘特图是三层的,第一层是部门,第二层是人员,第三层是任务。为了在甘特图能够清晰的展示和任务的关系,我们循环所有人员的子任务,当父任务在第二部分的任务列表中时,在第一层的标题打一个星号,第二层打两个星号,第三次打三个星号,并且任务的甘特图显示为红色。除了无法拖拽修改任务排期,基本能够满足我们上述的需求了。这个图也变成目前我用于检查迭代和人员排期的最重要的工具。
历史人员任务排期检查
背景
所有人的任务都是在不断滚动的,每个人每天都面临至少四种任务:
- 计划性任务(长期)
- 插入性任务(长期或短期,紧急)
- 线上问题(重要紧急短期)
- Bug问题(重要不紧急)
所以作为管理人员要管理好研发资源就要妥善的协调任务安排,而且时候还要针对任务变更情况进行分析,对内部人员或者外部需求单位提出改进需求。
实现
这是一个管理需求,基于人员视角,观察一段时间区间内某个人员的任务变化情况并进行分析。
由于观察的区间并不确定,所以我们要将每个人每天的未完成子任务缓存,并且根据页面需要获取指定时间区间的子任务聚合。
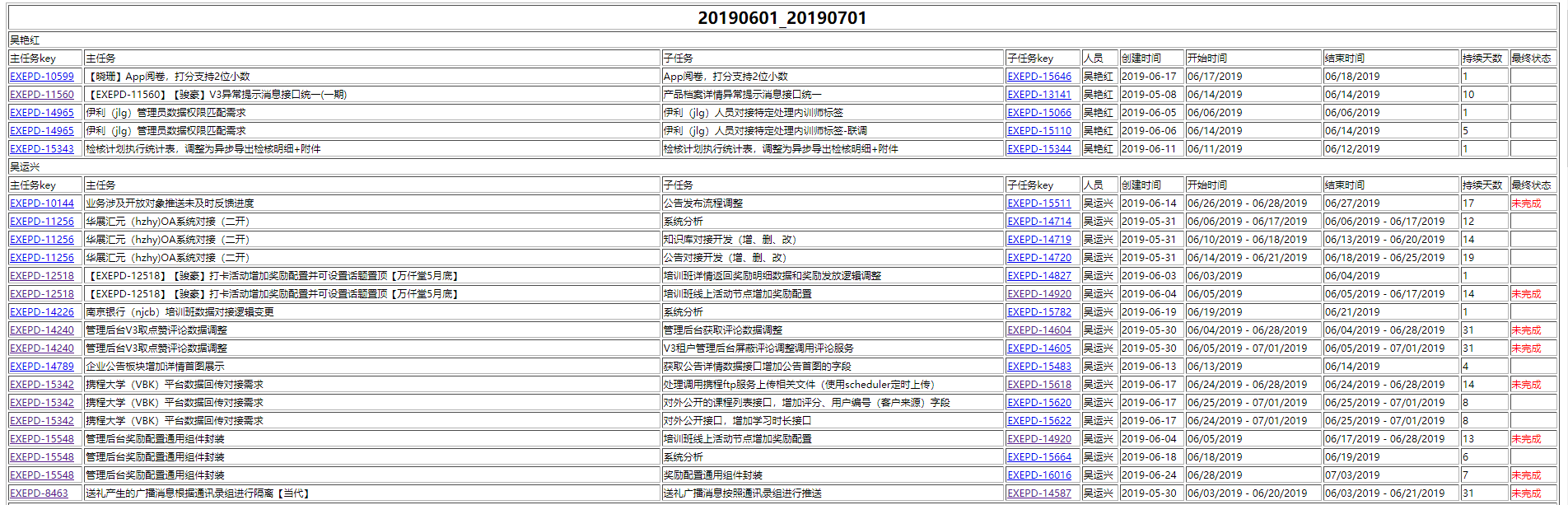
先给出最终效果:
我们要做的事情:
- 定时任务用于每天定时保存未完成子任务
- 后台服务根据前端传入条件查询并且聚合任务信息
- 前端展示
定时任务使用python作为脚本,使用crontab凌晨执行,每次都以日期作为表名新保存一个表,脚本实际上使用人员任务排期管理中的sql,用 create table z_subtask_%date () 包起来就OK了。
服务端还是使用上面的python启动的web服务,增加一个接口。
最终界面主要视角为人员,字段包括:
- 主任务和子任务的信息
- 何时创建(确认何时接收到任务)
- 开始日期和结束日期,如果日期从未变化过则是一个日期,如果有调整则是日期区间
- 持续天数,是指这个任务有缓存在多少天的库中,即新建之后持续了多少天
- 最终状态,是指到查询截止日期这天,这个任务是否完成
这样我们能够基本来分析某个人员他的任务计划性和延迟性,沟通了解原因并且制定相应的优化方案。
BI
背景
每个组织一定会有分析需求,无论是内部改进或者整体汇报,能够有图表和数据表的完整呈现是最基本的要求。这个需求最早是尝试在Jira的插件中来寻找的,但是尝试了不少插件发现都达不到预期的效果,最终只能转入了使用第三方BI框架,底层数据源自己组织。
实现
选定的就是阿里云的QuickBI。
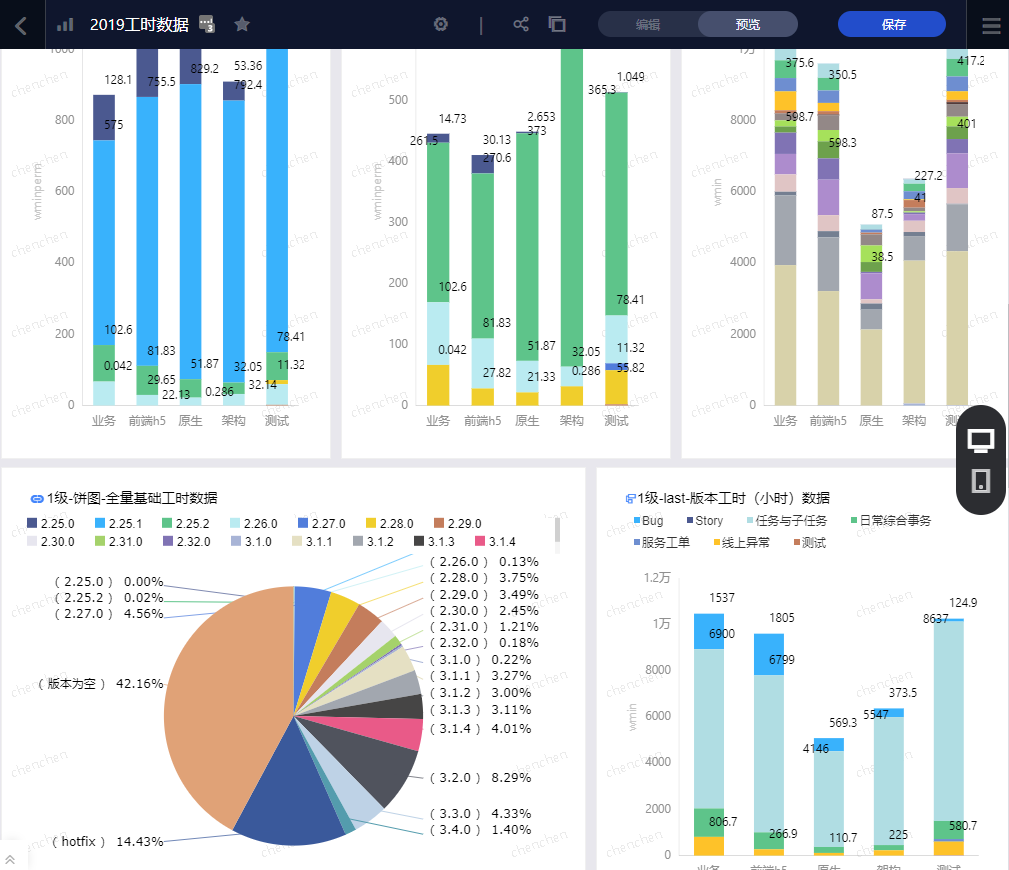
展示一部分效果图:
工时维度BI报表
迭代任务分析
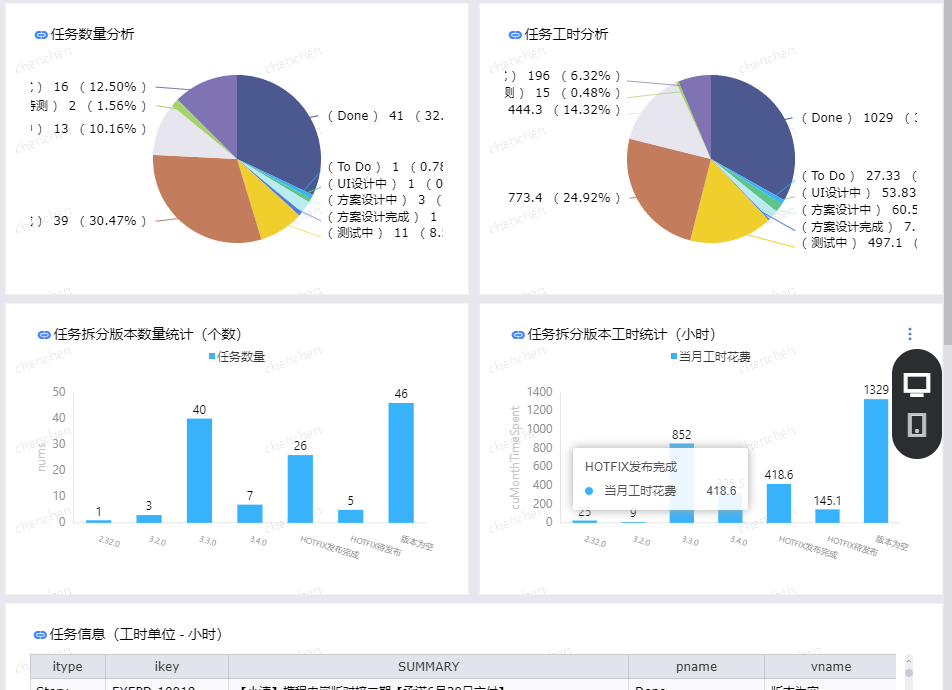
有了BI工具,实际上报表制作成什么样就没有太大约束了。基本主要还是针对工时、迭代任务两部分的分析。
我提供给大家两份sql参考Jira的底层数据库组织数据的示例:
迭代任务组织:
select concat('C_', a.id) as pissueId,
concat("EXEPD-", a.issuenum) as ikey,
k.pname as itype,
a.SUMMARY,
sum((ifnull(a.TIMESPENT, 0) + ifnull(j.TIMESPENT, 0)) / 3600) as allTimeSpent,
sum(ifnull(ll.timeworked, 0)) / 3600 as cuMonthTimeSpent,
b.pname,
ifnull(ifnull((case when i.vname='hotfix' then null else i.vname end) , e.customvalue), '版本为空') as vname,
1 as nums
from jiraissue a
join issuestatus b on b.ID = a.issuestatus
left join nodeassociation f on f.SOURCE_NODE_ID = a.ID and f.ASSOCIATION_TYPE = 'IssueFixVersion'
left join projectversion i on i.ID = f.SINK_NODE_ID
left join customfield c on c.cfname = '修正状态'
left join customfieldvalue d on d.CUSTOMFIELD = c.id and d.ISSUE = a.ID
left join customfieldoption e on e.CUSTOMFIELD = c.ID and e.id = d.STRINGVALUE
left join issuelink g on g.SOURCE = a.ID and g.LINKTYPE = 10100
left join jiraissue j on j.ID = g.DESTINATION
join issuetype k on k.id = a.issuetype
left join (select l.issueid, sum(ifnull(l.timeworked, 0)) as timeworked
from worklog l
where date_format(l.STARTDATE, '%Y-%m') = '2019-06'
group by l.issueid) ll on ll.issueid = j.ID
where a.issuenum in (1,2,3,4)
and a.PROJECT = 10000
group by a.ID
工时分析:
select a.id,
a.issueid,
concat('C_', ifnull(n.SOURCE, a.id)) as pissueId,
a.worklogbody,
(a.timeworked / 3600) as wmin,
(a.timeworked / 3600 / (case d.lower_parent_name
when 'org-pd-qa' then 10
when 'org-pd-frontside-h5' then 9
when 'org-pd-frontside-native' then 5
when 'org-pd-serverside-b' then 12
when 'org-pd-serverside-a' then 7
when 'org-pd-product' then 9
else '' end)) as wminperm,
date_format(a.STARTDATE, '%Y-%m-%d') as sdate,
date_format(a.STARTDATE, '%Y-%m') as sdm,
c.last_name,
(case d.lower_parent_name
when 'org-pd-qa' then '测试'
when 'org-pd-frontside-h5' then '前端h5'
when 'org-pd-frontside-native' then '原生'
when 'org-pd-serverside-b' then '业务'
when 'org-pd-serverside-a' then '架构'
when 'org-pd-product' then '产品UI'
else '' end) as deptname,
k.pname,
concat(h.pkey, '-', e.issuenum) as issuekey,
concat('https://jira.exexm.com/browse/', h.pkey, '-', e.issuenum) as issueurl,
(case j.pname when 'Sub-task' then '任务与子任务' when 'Task' then '任务与子任务' else j.pname end) as issuetypename,
-- (case j.pname when 'Sub-task' then '子任务' when 'Task' then '任务' else j.pname end) as issuetypename,
e.SUMMARY,
-- ifnull(ifnull(i.vname, ifnull(m.customvalue,mm.customvalue)), '版本为空') as vname,
i.vname,
(case
when
(i.vname is null and (l.STRINGVALUE is not null or ll.STRINGVALUE is not null))
then 'hotfix'
when
(i.vname is null or i.vname='')
then '版本为空'
when
a.issueid = 10752
then '日常事务'
when
a.issueid = 18019
then '规划外事务'
else i.vname end) as cord
from worklog a
join app_user b on b.user_key = a.AUTHOR
join cwd_user c on c.lower_user_name = b.lower_user_name
join cwd_membership d on d.lower_child_name = b.lower_user_name and d.lower_parent_name in
('org-pd-frontside-h5',
'org-pd-frontside-native',
'org-pd-serverside-a',
'org-pd-serverside-b',
'org-pd-qa',
'org-pd-product')
join jiraissue e on e.ID = a.issueid
left join nodeassociation f on f.SOURCE_NODE_ID = e.ID and f.ASSOCIATION_TYPE = 'IssueFixVersion'
left join projectversion i on i.ID = f.SINK_NODE_ID
join issuetype j on j.id = e.issuetype
join project h on h.ID = e.PROJECT
left join issuelink n on n.DESTINATION = e.ID and n.LINKTYPE = 10100
join issuestatus k on k.ID = e.issuestatus
left join customfieldvalue l on l.CUSTOMFIELD = 10025 and l.ISSUE = n.SOURCE
left join customfieldoption m on m.CUSTOMFIELD = 10025 and m.id = l.STRINGVALUE
left join customfieldvalue ll on ll.CUSTOMFIELD = 10025 and ll.ISSUE = e.ID
left join customfieldoption mm on mm.CUSTOMFIELD = 10025 and mm.id = ll.STRINGVALUE
where a.STARTDATE >= '2019-1-1'
order by a.STARTDATE asc
总结
写到这里,所有关于Jira的使用的整理目前告一段落了。但是这应该还只是一个阶段性里程碑而已,我们的组织架构在进步,过程管理方法在进步,Atlassian也在进步,所以我们也不能停下自己的脚步。Jira还只是完整生态当中的一个环节,我们要更好的组织我们的研发团队,后面还有一些伙伴给大家介绍。一个企业、研发团队要能长久的生存和提高,就需要积累,但是不能口口相传,还要能进行阶段性的梳理和提高。下一章就是企业如何使用Confluence进行知识积累。
Atlassian In Action-Jira之二次开发(五)的更多相关文章
- Atlassian In Action - (Atlassian成长之路)
Atlassian是我工作过程中,使用过的最满意的研发团队管理套装.使用的主要软件包括Jira Software,Confluence,Fisheye/Crucible.理论上还可以再加上Bitbuc ...
- 哪个项目管理工具好用到哭?JIRA VS 华为软件开发云
一.产品介绍 JIRA是Atlassian公司出品的项目与事务跟踪工具,被广泛应用于缺陷跟踪.客户服务.需求收集.流程审批.任务跟踪.项目跟踪和敏捷管理等工作领域. 华为软件开发云 (DevCloud ...
- iwebshop二次开发
1.iwebshop中写hello world ① 动作action方式 controllers目录下,然后创建text.php. <?php class Test extends IContr ...
- dedecms自定义函数(二次开发)
一些功能可能dedecms没有,这个时候可以自己写一些函数: 1.打开inlude->extend.func.php,将函数写到里面 比如:前台: [field:id function=&quo ...
- phpcms v9二次开发之模型类的应用(1)
在<phpcms二次开发之模型类model.class.php>中讲到了模型类的建立方法,接下来我讲一下模型类的应用. 前段时间我基于phpcms v9开发了一个足球网.足球网是 ...
- phpcms二次开发步骤
文件目录结构 根目录 | – api 接口文件目录 | – caches 缓存文件目录 | – configs 系统配置文件目录 | – caches_* 系统缓存目录 | – phpcms phpc ...
- appium-desktop录制脚本二次开发,生成我司自动化脚本
目的 通过对appium-desktop脚本录制功能进行二次开发,使录制的java脚本符合我司自动化框架要求. 实现步骤 1.增加元素名称的输入框 由于ATK(我司自动化测试框架)脚本中元素是以“ap ...
- revit二次开发wpf里button按钮无法实现事务
不能在revit提供的api外部使用事务,解决此方法, 1.把button里要实现的功能写到外部事件IExternalEventHandler中,注册外部事件,在button事件中.raise()使用 ...
- JMeter二次开发(1)-eclipse环境配置及源码编译
1.下载src并解压 http://jmeter.apache.org/download_jmeter.cgi 2.获取所需jar包,编译 ant download_jars ant instal ...
随机推荐
- springboot部署到tomcat
把spring-boot项目按照平常的web项目一样发布到tomcat容器下 多点经验: 1.保证运行环境的jdk和开发环境一致,不然class文件无法被编译 2.保证tomcat和java的版本匹配 ...
- 布隆过滤器 - 如何在100个亿URL中快速判断某URL是否存在?
题目描述 一个网站有 100 亿 url 存在一个黑名单中,每条 url 平均 64 字节.这个黑名单要怎么存?若此时随便输入一个 url,你如何快速判断该 url 是否在这个黑名单中? 题目解析 这 ...
- vue项目接入api接口
我们在做项目时,一切基础在于数据上面,所以接入api接口是关键. 访问接口是我们会遇到跨域,而,vue-cli给我们提供了反向代理,所以我们只需要配置一下就可以了. 在config文件中找到index ...
- H5离线缓存基础系列
1.什么是离线缓存 离线缓存:离线缓存可以将站点的一些文件缓存到本地,它是浏览器自己的一种机制,将需要的文件缓存下来,以便后期即使没有连接网络,被缓存的页面也可以展示. 2.离线缓存的优势 在没有网络 ...
- C# Redis分布式锁(基于ServiceStack.Redis)
相关的文章其实不少,我也从中受益不少,但是还是想自己梳理一下,毕竟自己写的更走心! 首先给出一个拓展类,通过拓展方法实现加锁和解锁. 注:之所以增加拓展方法,是因为合理使用拓展类(方法),可以让程序更 ...
- kafka入门(二)分区和group
topic 在kafka中消息是按照topic进行分类的:每条发布到Kafka集群的消息都有一个类别,这个类别被称为topic parition 一个topic可以配置几个parition,每一个分区 ...
- 浅谈 JavaScript 中 Array 类型的方法使用
前言:Array 类型是 JavaScript 中除了 Object 类型以外最常用的类型. 一.创建数组 JavaScript 中的数组与其他语言中的数组有着很大的区别.例如Java.PHP等语言中 ...
- 为什么Python 3.6以后字典有序并且效率更高?
在Python 3.5(含)以前,字典是不能保证顺序的,键值对A先插入字典,键值对B后插入字典,但是当你打印字典的Keys列表时,你会发现B可能在A的前面. 但是从Python 3.6开始,字典是变成 ...
- Java NIO学习系列四:NIO和IO对比
前面的一些文章中我总结了一些Java IO和NIO相关的主要知识点,也是管中窥豹,IO类库已经功能很强大了,但是Java 为什么又要引入NIO,这是我一直不是很清楚的?前面也只是简单提及了一下:因为性 ...
- EF 使用遇到过的错误记录备忘
1. is only supported for sorted input in LINQ to Entities The method :只支持排序输入实体LINQ 的方法 是使用skip()时没 ...