Hadoop_MapReduce_03
1. MapReduce入门
1.1 MapReduce的思想
MapReduce的思想核心是"分而治之" , 适用于大量的复杂的任务处理场景 (大规模数据处理场景) .
Map负责"分" , 即把复杂的任务分解为若干个"简单的任务"来进行处理. 可以进行拆分的前提是这些小任务并行计算, 彼此间几乎没有依赖关系.
Reduce负责"合" , 即对map阶段的结果进行全局汇总.
这两个阶段合起来正是MR思想的体现.
1.2 MapReduce设计构思
MapReduce是一个分部式运算程序的编程框架, 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序. 并发运行在Hadoop集群上.
既然是做计算的框架, 那么表现形式就是有个输入 (input) , MR操作这个输入, 通过本身定义好的计算模型, 得到一个输出 (output) .
MR就是一种简化并行计算的编程模型, 降低了开发并行应用的入门门槛.
Hadoop MapReduce构思体现在三个方面:
- 如何对付大数据处理: 分而治之
对相互间不具有计算依赖关系的大数据, 实现并行最自然的方法就是采取分而治之的策略. 并行计算的第一个重要问题是如何划分计算任务或者计算数据以便对划分的子任务或数据块同时进行计算. 不可分拆的计算任务或相互间有依赖关系的数据无法进行并行计算.
- 构建抽象模型: Map和Reduce
MR借鉴了函数式语言中的思想, 用Map和Reduce两个函数提供了高层的并行编程抽象模型.
Map: 对一组数据元素进行某种重复式的处理.
Reduce: 对Map的中间结果进行某种进一步的结果整理.
MapReduce中定义了如下的Map和Reduce两个抽象的编程接口, 由用户去编程实现:
Map: (k1, v1) -> [(k2, v2)]
Reduce: (k2, [v2]) -> [(k3, v3)]
Map和Reduce为我们提供了一个清晰的操作接口抽象描述. 通过以上两个编程接口, 可以看出MR处理的数据类型是<key, value>键值对.
- 统一架构, 隐藏系统层细节
如何提供统一的计算框架, 如果没有统一封装底层细节, 那么我们则需要考虑诸如数据存储, 划分, 分发, 结果手机, 错误恢复等诸多细节. 为此, MR设计并提供了统一的计算框架, 隐藏了绝大多数系统层面的处理细节.
MapReduce最大的亮点在于通过抽象模型和计算框架把需要做什么 (what need to do) 与具体怎么做 (how to do) 分开了, 为我们提供一个抽象和高层的编程接口和框架. 我们仅需要关心其应用层的具体计算问题, 仅需编写少量的处理应用本身计算问题的程序代码. 如何具体完成这个并行计算任务所相关的诸多系统层细节被隐藏起来, 交给计算框架去处理: 从分布代码的执行, 到大到数千小到单个节点集群的自动调度使用.
1.3 MapReduce框架结构
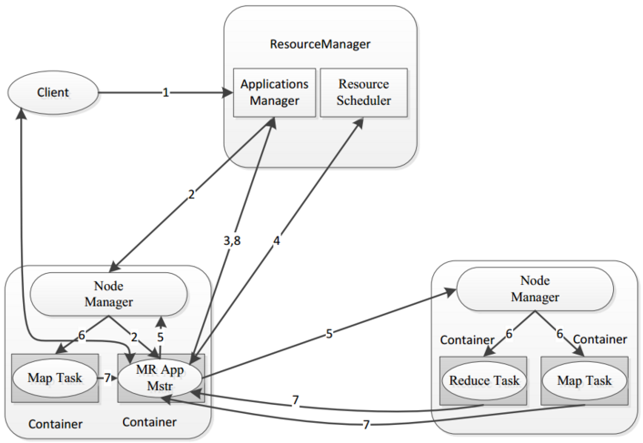
一个完整的MR程序在分布式运行时有三类实例进程:
1) MRAppMaster: 负责整个程序的过程调度及状态协调.
2) MapTask: 负责Map阶段的整个数据处理流程.
3) ReduceTask: 负责Reduce阶段的整个数据处理流程.

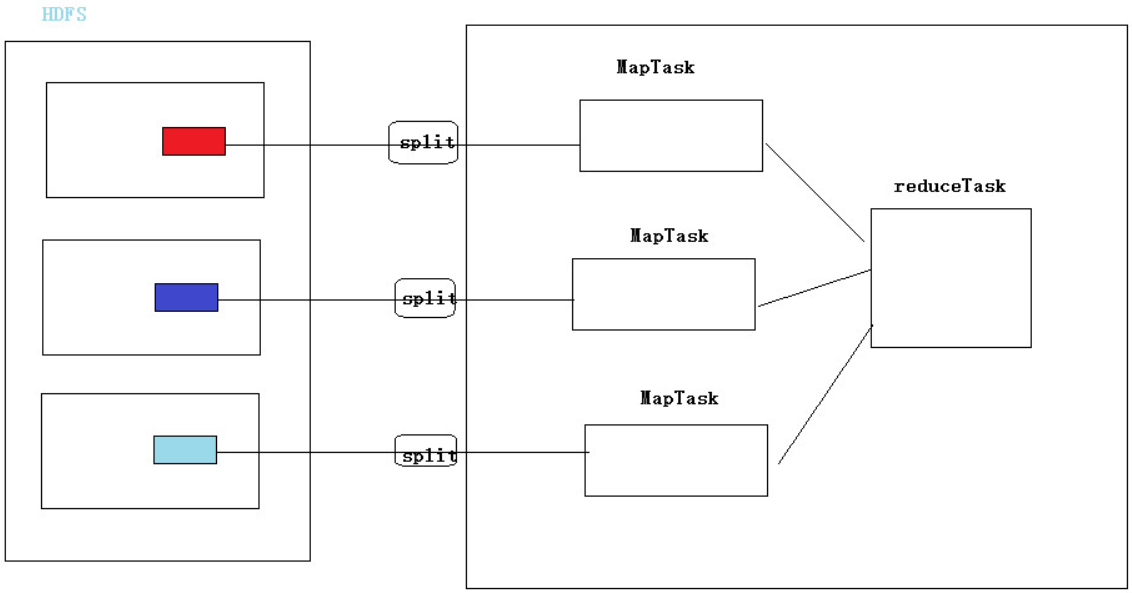
1.4 Map, Reduce, Split总结
2. MapReduce编程规范及示例
2.1 编程规范
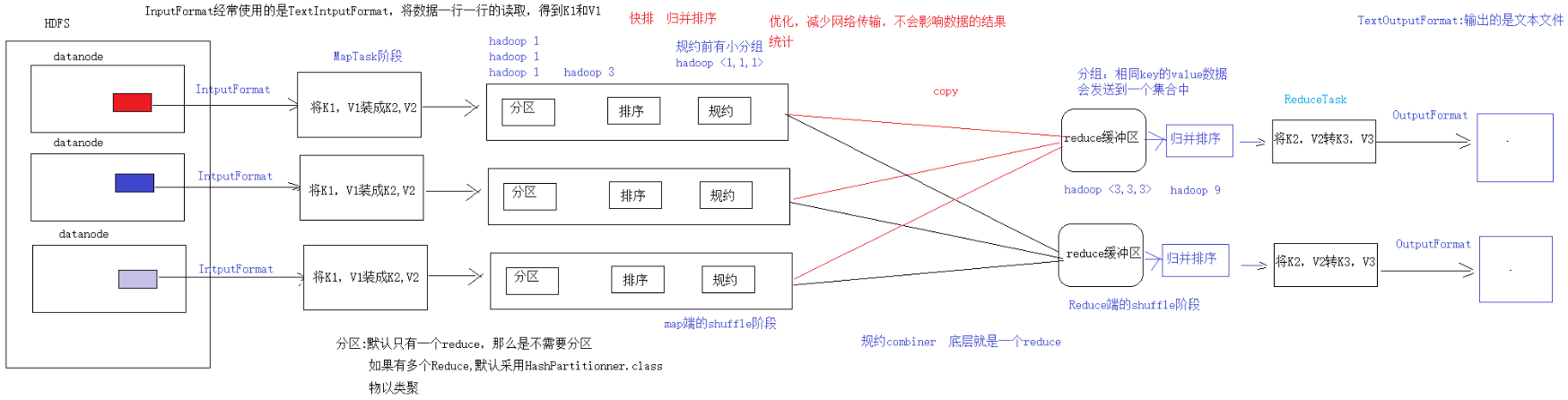
开发步骤一共8步
- MapTask阶段2步
1) 设置InputFormat (通常使用TextInputFormat) 的类型和数据的路径 -- 获取数据的过程 (可以得到K1, V1) .
2) 自定义Mapper -- 将K1, V1转为K2, V2.
- shuffle阶段4步
3) 分区的动作, 如果有多个Reduce才去考虑分区, 默认只有一个Reduce, 分区可以省略.
4) 排序, 默认对K2进行排序 (字典序) -- 管好K2就行.
5) 规约, combiner是一个局部的Reduce, Map端的合并, 是对MR的优化操作, 不会影响任何结果, 减少网络传输, 默认可以省略.
6) 分组, 相同的K (K2) 对应的V会放到同一个集合中 -- 将Map传递的K2, V2变成新的K2, V2.
- Reduce阶段2步
7) 自定义Reducer得到K2, V2转为K3, V3.
8) 设置OutputFormat和数据的路径 -- 生成结果文件.
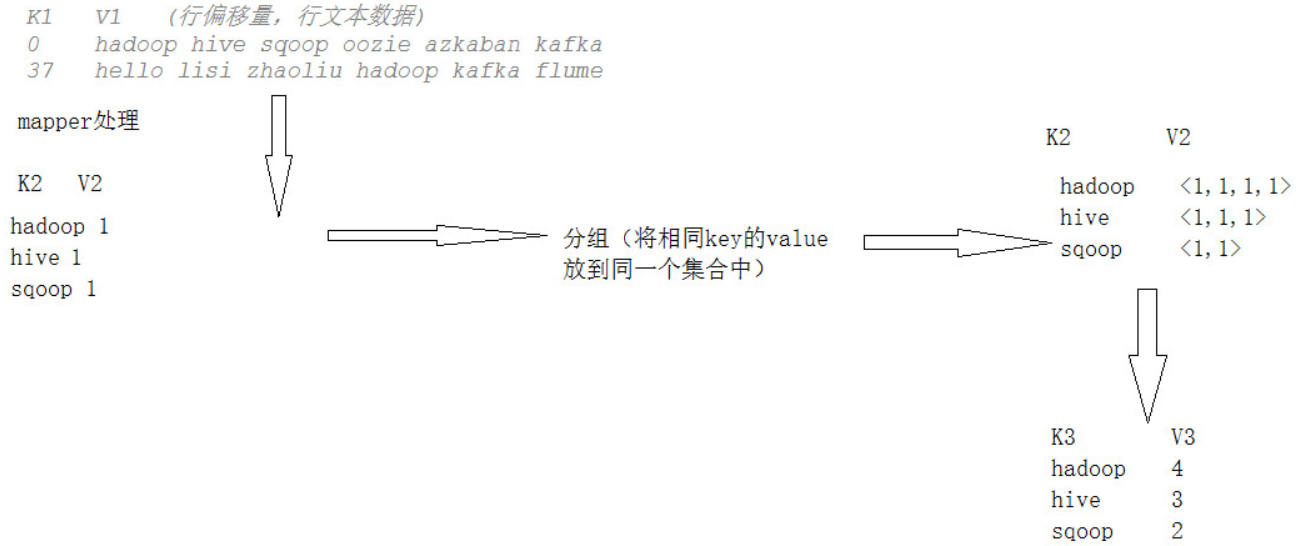
2.2 WordCount案例
3. MapReduce程序运行模式
3.1 本地运行模式
1) MR程序是被提交给LocalJobRunner在本地以单进程的形式运行.
2) 而处理的数据及输出结果可以在本地文件系统, 也可以在HDFS上.
3) 怎么样实现本地运行? 写一个程序, 不要带集群的配置文件
本质是程序的conf中是否有mapreduce.framework.name=local以及yarn.resourcemanager.hostname参数
4) 本地模式非常便于进行业务逻辑的debug, 只要打断点即可.
3.2 集群运行模式
1) 将MR程序提交给yarn集群, 分发到很多的节点上并发执行.
2) 处理的数据和输出结果应该位于HDFS文件系统.
3) 提交集群的实现步骤:
将程序打成jar包, 然后在集群的任意一个节点上用Hadoop命令启动:
hadoop jar wordcount.jar cn.itcast.mr.wordcount.WordCountRunner args
4. 深入MapReduce
4.1 MapReduce的输入和输出
MR框架运转在<key, value>键值对上, 也就是说, 框架把作业的输入看成是一组<key, value>键值对, 同样也产生一组<key, value>键值对作为作业的输出, 这两组键值对可能是不同的.
一个MR作业的输入和输出类型如下图所示: 可以看出在整个标准流程中, 会有三组<key, value>键值对类型的存在.

4.2 Mapper任务执行过程详解
第一阶段: 把输入目录下文件按照一定的标准逐个进行逻辑切片, 形成切片规划. 默认情况下, Split size = Block size. 每一个切片由一个MapTask处理. (getSplits)
第二阶段: 对切片中的数据按照一定的规则解析成<key, value>对. 默认规则是把每一行文本内容解析成键值对. key是每一行的起始位置 (单位是字节) , value是本行的文本内容. (TextInputFormat)
第三阶段: 调用Mapper类中的map方法, 上阶段中每解析出来的一个<k, v>, 调用一次map方法. 每次调用map方法会输出零个或多个键值对.
第四阶段: 按照一定的规则对第三阶段输出的键值对进行分区. 默认是只有一个区. 分区的数量就是Reducer任务运行的数量. 默认只有一个Reducer任务.
第五阶段: 对每个分区中的键值对进行排序. 首先, 按照键进行排序, 对于键相同的键值对, 按照值进行排序. 比如三个键值对<2, 2>, <1, 3>, <2, 1>, 键和值分别是整数. 那么排序后的结果是<1, 3>, <2, 1>, <2, 2>. 如果有第六阶段, 那么进入第六阶段, 如果没有, 直接输出到文件中.
第六阶段: 对数据进行局部聚合处理, 也就是combiner处理. 键相等的键值对会调用一次reduce方法. 经过这一阶段, 数据量会减少. 本阶段默认是没有的.
4.3 Reducer任务执行过程详解
第一阶段: Reducer任务会主动从Mapper任务复制其输出的键值对. Mapper任务可能会有很多, 因此Reducer会复制多个Mapper的输出.
第二阶段: 把复制到Reducer本地数据, 全部进行合并, 即把分散的数据合并成一个大的数据. 再对合并后的数据排序.
第三阶段: 对排序后的键值对调用reduce方法. 键相等的键值对调用一次reduce方法, 每次调用会产生零个或者多个键值对. 最后把这些输出的键值对写入到HDFS文件中.
在整个MR程序的开发过程中, 我们最大的工作是覆盖map函数和覆盖reduce函数.
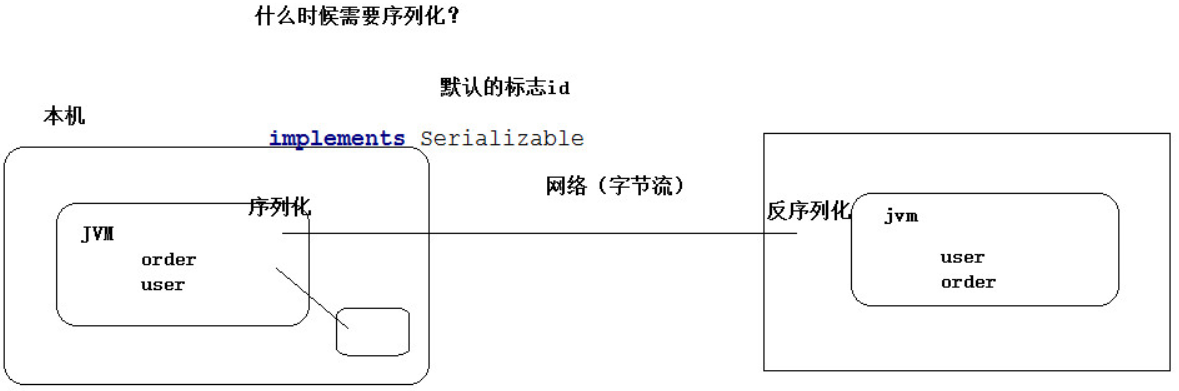
5. MapReduce的序列化
5.1 概述
序列化是指把结构化对象转化为字节流.
反序列化是序列化的逆过程. 把字节流转化为结构化对象.
当要在进程间传递对象或持久化对象的时候, 就需要序列化对象成字节流, 反之当要将接收到或从磁盘读取的字节流转换成对象, 就要进行反序列化.
Java序列化是一个重量级序列化框架, 一个对象被序列化后, 会附带很多额外的信息, 不便于在网络中高效传输. 所以, Hadoop自己开发了一套序列化机制 (Writable) , 不用像Java对象类一样传输多层的父子关系, 需要哪个属性就传输哪个属性值, 大大的减少网络传输的开销.
Writable是Hadoop的序列化格式, Hadoop定义了这样一个Writable接口. 一个类要支持可序列化只需要实现这个接口即可.
public interface Wriable {
void wirte (DataOutput out) throws IOException;
void readFields (DataInput in) throws IOException;
}
5.2 Writable序列化接口
如需将自定义的bean放在key中传输, 则还需要实现comparable接口, 因为MR框中的shuffle过程一定会对key进行排序, 此时, 自定义的bean实现的接口应该是:
public class FlowBean implements WritableComparable<FlowBean>
compareTo方法用于将当前对象与方法的参数进行比较:
- 如果指定的数与参数相等返回 0
- 如果指定的数小于参数返回 -1
- 如果指定的数大于参数返回 1
例如: o1.compareTo(o2)
返回正数的话, 当前对象 (调用compareTo方法的对象o1) 要排在比较对象 (compareTo传参对象o2) 后面, 返回负数的话, 放在前面.
6. MapReduce的排序初步
6.1 需求
在得出统计每一个用户 (手机号) 所耗费的总上行流量, 下行流量, 总流量结果的基础之上再加一个需求: 将统计结果按照总流量倒序排序.
6.2 分析
基本思路: 实现自定义的bean来封装流量信息, 并将bean作为map输出的key来传输.
MR程序在处理数据的过程中会对数据排序 (map输出的kv对传输到reduce之前, 会排序), 排序的依据是map输出的key. 所以, 我们如果要实现自己需要的排序规则, 则可以考虑将排序因素放到key中, 让key实现接口: WritableComparable, 然后重写key的compareTo方法.
7. MapReduce的分区Partitioner
7.1 需求
将流量汇总统计结果按照手机归属地不同省份输出到不同文件中.
7.2 分析
Mapreduce中会将map输出的kv对, 按照相同key分组, 然后分发给不同的reducetask.
默认的分发规则为: 根据key的hashcode%reducetask数来分发.
所以: 如果要按照我们自己的需求进行分组, 则需要改写数据分发 (分组) 组件Partitioner, 自定义一个CustomPartitioner继承抽象类: Partitioner, 然后在job对象中, 设置自定义partitioner: job.setPartitionerClass(CustomPartitioner.class) .
8. MapReduce的Combiner
每一个map都可能会产生大量的本地输出, Combiner的作用就是对map端的输出先做一次合并, 以减少在map和reduce节点之间的数据传输量, 以提高网络IO性能, 是MR的一种优化手段之一.
- Combiner是MR程序中Mapper和Reducer之外的一种组件.
- Combiner组件的父类就是Reducer.
- Combiner和reducer的区别在于运行的位置:
Combiner是在每一个maptask所在的节点运行.
Reducer是接收全局所有Mapper的输出结果.
- Combiner的意义就是对每一个maptask的输出进行局部汇总, 以减小网络传输量.
- 具体实现步骤:
1) 自定义一个combiner继承Reducer, 重写reduce方法
2) 在job中设置: job.setCombinerClass(CustomCombiner.class) .
- Combiner能够应用的前提是不能影响最终的业务逻辑, 而且, Combiner的输出kv应该跟reducer的输入kv类型要对应起来.
Hadoop_MapReduce_03的更多相关文章
随机推荐
- 【02】对象的Getter and Setter
java和C#非常相似,它们大部分的语法是一样的,但尽管如此,也有一些地方是不同的. 为了更好地学习java或C#,有必要分清它们两者到底在哪里不同. 我们这次要来探讨对象的Getter and Se ...
- 如何运用DDD - 实体
目录 如何运用DDD - 实体 概述 何为实体 似曾相识 你确定它真的需要ID吗 运用实体 结合值对象 为实体赋予它的行为 尝试转移一部分行为给值对象 愿景是美好的 现实是残酷的 总结 如何运用DDD ...
- 队列&生产者消费者模型
队列 ipc机制:进程通讯 管道:pipe 基于共享的内存空间 队列:pipe+锁 queue from multiprocessing import Process,Queue ### 案例一 q ...
- oracle创建jobs定时任务报错:PLS-00306: wrong number or types of arguments in call to 'JOB'
原脚本: begin sys.dbms_job.submit(job => job, what => 'xxx;', ...
- MyBatis的配置与使用(增,删,改,查)
---恢复内容开始--- Mybatis入门介绍 一.MyBatis介绍 什么是MyBtis? MyBatis 是一个简化和实现了 Java 数据持久化层(persistence layer)的开源框 ...
- 鲲鹏性能优化十板斧之前言 | 鲲鹏处理器NUMA简介与性能调优五步法
鲲鹏处理器NUMA简介 随着现代社会信息化.智能化的飞速发展,越来越多的设备接入互联网.物联网.车联网,从而催生了庞大的计算需求.但是功耗墙问题以功耗和冷却两大限制极大的影响了单核算力的发展.为了满足 ...
- 基于SCN增量恢复DG同步
问题描述:做scn恢复备库的测试,吭哧了几天,今天终于可以记录一下,遇到了很多坑,作为初学者可以更好地理解DG,主要先关闭备库,在主库做归档丢失备库无法同步,备库产生GAP,然后增量备份恢复备库,版本 ...
- JWT攻击手册:如何入侵你的Token
JSON Web Token(JWT)对于渗透测试人员而言,可能是一个非常吸引人的攻击途径.因为它不仅可以让你伪造任意用户获得无限的访问权限,而且还可能进一步发现更多的安全漏洞,如信息泄露,越权访问, ...
- [TimLinux] Python __hash__ 可哈希集合
规则: __hash__ 应该返回一个整数,hash()函数计算基础类型的hash值 可哈希集合:set(), forzenset(), dict() 三种数据结构操作要求 key 值唯一,判断唯一的 ...
- 【解决】error pulling image configuration: Get https:// ...... x509: certificate has expired or is not yet valid
[问题]进行镜像拉取时报错 [分析] 很多人会被第一句所蒙蔽,按照网上教程进行修改etc/sysconfig/docker,之后发现还是没有用. 其实这里重点是最后一句"certificat ...