Python爬虫基础——re模块的提取和匹配
re是Python的一个第三方库。
为了能更直观的看出re的效果,我们先新建一个HTML网页文件(可直接复制):
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<footer>
<div>
<div class="email">
Email:re@qq.com
</div>
<div class="tel">
手机号:88888888
</div>
</div>
</footer>
</body>
</html>
## OK,然后我们进入主题。
re主要有三个功能:提取、匹配、替换。
1、提取findall:
re.findall(【正则表达式】, 【被提取的字符串】)
注意:返回的类型是列表
我们应如何取出上文index.html中的Email或者手机号呢:
import re
with open('index.html', 'r', encoding='utf-8') as f:
# 读取index.html
html = f.read()
# 把html中的换行符,去掉,也就是替换成空字符串,因为.不能匹配到换行符
html = re.sub('\n', '', html)
print(html)
# 定义正则表达式,注意括号
pattern_1 = '<div class="email">(.*?)</div>'
# re.findall(【正则表达式】,【被提取的字符串】),返回类型是列表
ret_1 = re.findall(pattern_1, html)
# 字符串.strip(),可以去除首位的空格和换行符
print(ret_1[0].strip())
2、匹配match:
re.match(【正则表达式】, 【被匹配的字符串】)
注意:
如果匹配成功,返回<class 're.Match'>对象;
如果匹配不成功,返回None。
我们应如何编写定义密码的正则表达式呢:
import re
# 英文字母开头,可包括应为字母,数字、下划线,总位数6-16位
password_pattern = r'^[a-zA-Z][a-zA-Z0-9_]{5,15}$'
# 定义三个密码
pass1 = '1234567'
pass2 = 'k123456'
pass3 = 'k123'
# 打印测试结果,匹配成功返回re.Match对象,不成功返回None
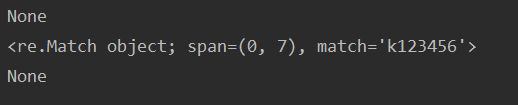
print(re.match(password_pattern, pass1))
print(re.match(password_pattern, pass2))
print(re.match(password_pattern, pass3))
输出结果为:
3、替换sub:
re.sub(【正则表达式】, 【替换成的字符串】, 【被匹配的字符串】)
觉得没看过sub的同学,那只能说明你看笔记不认真了,示范代码请看上上文~~
为我心爱的女孩~~
Python爬虫基础——re模块的提取和匹配的更多相关文章
- Python爬虫基础
前言 Python非常适合用来开发网页爬虫,理由如下: 1.抓取网页本身的接口 相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁:相比其他动态脚本语言,如perl ...
- 孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块
孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块 (完整学习过程屏幕记录视频地址在文末) 从今天起开始正式学习Python的爬虫. 今天已经初步了解了两个主要的模块: ...
- Python爬虫练习(requests模块)
Python爬虫练习(requests模块) 关注公众号"轻松学编程"了解更多. 一.使用正则表达式解析页面和提取数据 1.爬取动态数据(js格式) 爬取http://fund.e ...
- Python爬虫之urllib模块2
Python爬虫之urllib模块2 本文来自网友投稿 作者:PG-55,一个待毕业待就业的二流大学生. 看了一下上一节的反馈,有些同学认为这个没什么意义,也有的同学觉得太简单,关于Beautiful ...
- Python爬虫之urllib模块1
Python爬虫之urllib模块1 本文来自网友投稿.作者PG,一个待毕业待就业二流大学生.玄魂工作室未对该文章内容做任何改变. 因为本人一直对推理悬疑比较感兴趣,所以这次爬取的网站也是平时看一些悬 ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
随机推荐
- RocketMQ一个新的消费组初次启动时从何处开始消费呢?
目录 1.抛出问题 1.1 环境准备 1.2 消息发送者代码 1.3 消费端验证代码 2.探究CONSUME_FROM_MAX_OFFSET实现原理 2.1 CONSUME_FROM_LAST_OFF ...
- Linux(CentOS65)
首先下载VMware,然后下载CentOS镜像文件,VM的版本尽量高一点,因为软件一般都有向下兼容性,如果版本太低,可能匹配不了CentOS. 安装VMTools工具 主要用于虚拟主机显示优化与调整, ...
- c#、ASP.NET core 基础模块之一:linq(原创)
最近做数据查询,发现linq 真的比我 印象中 要强大的多,实用的多,所以 我决定 要与linq 来一场 深入交流, 因为linq的基础用法 可以百度一大摞,我就记录点不一样的,结合我做项目使 ...
- Flutter高仿微信项目开源-具即时通讯IM功能
项目地址:https://github.com/fluttercandies/wechat_flutter wechat_flutter Flutter版本微信 效果图: 下载体验(Android) ...
- springboot+swagger接口文档企业实践(下)
目录 1.引言 2. swagger接口过滤 2.1 按包过滤(package) 2.2 按类注解过滤 2.3 按方法注解过滤 2.4 按分组过滤 2.4.1 定义注解ApiVersion 2.4.2 ...
- Android最大方法数和解决方案
转载请标明出处:http://blog.csdn.net/shensky711/article/details/52329035 本文出自: [HansChen的博客] 什么是64K限制和Linear ...
- HashMap面试题,看这一篇就够了!
目录 序言 一.JDK7中的HashMap底层实现 1.1 基础知识 1.2 put()方法 1.2.1 特殊key值处理 1.2.2 扩容 1.2.3 如何计算bucket下标? 1.2.4 在目标 ...
- FastDFS搭建分布式文件系统
FastDFS搭建分布式文件系统 1. 什么是分布式文件系统 分布式文件系统(Distributed File System)是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网 ...
- 69道Spring面试题及答案
目录 Spring 概述 依赖注入 Spring beans Spring注解 Spring数据访问 Spring面向切面编程(AOP) Spring MVC Spring 概述 1. 什么是spri ...
- Xamarin.Forms学习系列之Syncfusion 制作图形报表
Syncfusion是一家微软生态下的第三方组件/控件供应商,除了用于HTML5和JavaScript的控件外,他们产品还涉及如下领域: WEB ASP.NET MVC ASP.NET WebForm ...