波士顿房价预测 - 最简单入门机器学习 - Jupyter
机器学习入门项目分享 - 波士顿房价预测
该分享源于Udacity机器学习进阶中的一个mini作业项目,用于入门非常合适,刨除了繁琐的部分,保留了最关键、基本的步骤,能够对机器学习基本流程有一个最清晰的认识;
项目描述
利用马萨诸塞州波士顿郊区的房屋信息数据训练和测试一个模型,并对模型的性能和预测能力进行测试;
项目分析
数据集字段解释:
RM: 住宅平均房间数量;LSTAT: 区域中被认为是低收入阶层的比率;PTRATIO: 镇上学生与教师数量比例;MEDV: 房屋的中值价格(目标特征,即我们要预测的值);
其实现在回过头来看,前三个特征应该都是挖掘后的组合特征,比如RM,通常在原始数据中会分为多个特征:一楼房间、二楼房间、厨房、卧室个数、地下室房间等等,这里应该是为了教学简单化了;
MEDV为我们要预测的值,属于回归问题,另外数据集不大(不到500个数据点),小数据集上的回归问题,现在的我初步考虑会用SVM,稍后让我们看看当时的选择;
Show Time
Step 1 导入数据
注意点:
- 如果数据在多个csv中(比如很多销售项目中,销售数据和店铺数据是分开两个csv的,类似数据库的两张表),这里一般要连接起来;
- 训练数据和测试数据连接起来,这是为了后续的数据处理的一致,否则训练模型时会有问题(比如用训练数据训练的模型,预测测试数据时报错维度不一致);
- 观察下数据量,数据量对于后续选择算法、可视化方法等有比较大的影响,所以一般会看一下;
- pandas内存优化,这一点项目中目前没有,但是我最近的项目有用到,简单说一下,通过对特征字段的数据类型向下转换(比如int64转为int8)降低对内存的使用,这里很重要,数据量大时很容易撑爆个人电脑的内存存储;
上代码:
# 载入波士顿房屋的数据集
data = pd.read_csv('housing.csv')
prices = data['MEDV']
features = data.drop('MEDV', axis = 1)
# 完成
print "Boston housing dataset has {} data points with {} variables each.".format(*data.shape)
Step 2 分析数据
加载数据后,不要直接就急匆匆的上各种处理手段,加各种模型,先慢一点,对数据进行一个初步的了解,了解其各个特征的统计值、分布情况、与目标特征的关系,最好进行可视化,这样会看到很多意料之外的东西;
基础统计运算
统计运算用于了解某个特征的整体取值情况,它的最大最小值,平均值中位数,百分位数等等,这些都是最简单的对一个字段进行了解的手段;
上代码:
#目标:计算价值的最小值
minimum_price = np.min(prices)# prices.min()
#目标:计算价值的最大值
maximum_price = np.max(prices)# prices.max()
#目标:计算价值的平均值
mean_price = np.mean(prices)# prices.mean()
#目标:计算价值的中值
median_price = np.median(prices)# prices.median()
#目标:计算价值的标准差
std_price = np.std(prices)# prices.std()
特征观察
这里主要考虑各个特征与目标之间的关系,比如是正相关还是负相关,通常都是通过对业务的了解而来的,这里就延伸出一个点,机器学习项目通常来说,对业务越了解,越容易得到好的效果,因为所谓的特征工程其实就是理解业务、深挖业务的过程;
比如这个问题中的三个特征:
- RM:房间个数明显应该是与房价正相关的;
- LSTAT:低收入比例一定程度上表示着这个社区的级别,因此应该是负相关;
- PTRATIO:学生/教师比例越高,说明教育资源越紧缺,也应该是负相关;
上述这三个点,同样可以通过可视化的方式来验证,事实上也应该去验证而不是只靠主观猜想,有些情况下,主观感觉与客观事实是完全相反的,这里要注意;
Step 3 数据划分
为了验证模型的好坏,通常的做法是进行cv,即交叉验证,基本思路是将数据平均划分N块,取其中N-1块训练,并对另外1块做预测,并比对预测结果与实际结果,这个过程反复N次直到每一块都作为验证数据使用过;
上代码:
# 提示: 导入train_test_split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(features, prices, test_size=0.2, random_state=RANDOM_STATE)
print X_train.shape
print X_test.shape
print y_train.shape
print y_test.shape
Step 4 定义评价函数
这里主要是根据问题来定义,比如分类问题用的最多的是准确率(精确率、召回率也有使用,具体看业务场景中更重视什么),回归问题用RMSE(均方误差)等等,实际项目中根据业务特点经常会有需要去自定义评价函数的时候,这里就比较灵活;
Step 5 模型调优
通过GridSearch对模型参数进行网格组合搜索最优,注意这里要考虑数据量以及组合后的可能个数,避免运行时间过长哈;
上代码:
from sklearn.model_selection import KFold,GridSearchCV
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import make_scorer
def fit_model(X, y):
""" 基于输入数据 [X,y],利于网格搜索找到最优的决策树模型"""
cross_validator = KFold()
regressor = DecisionTreeRegressor()
params = {'max_depth':[1,2,3,4,5,6,7,8,9,10]}
scoring_fnc = make_scorer(performance_metric)
grid = GridSearchCV(estimator=regressor, param_grid=params, scoring=scoring_fnc, cv=cross_validator)
# 基于输入数据 [X,y],进行网格搜索
grid = grid.fit(X, y)
# 返回网格搜索后的最优模型
return grid.best_estimator_
可以看到当时项目中选择的是决策树模型,现在看,树模型在这种小数据集上其实是比较容易过拟合的,因此可以考虑用SVM代替,你也可以试试哈,我估计是SVM效果最好;
学习曲线
通过绘制分析学习曲线,可以对模型当前状态有一个基本了解,如下图:
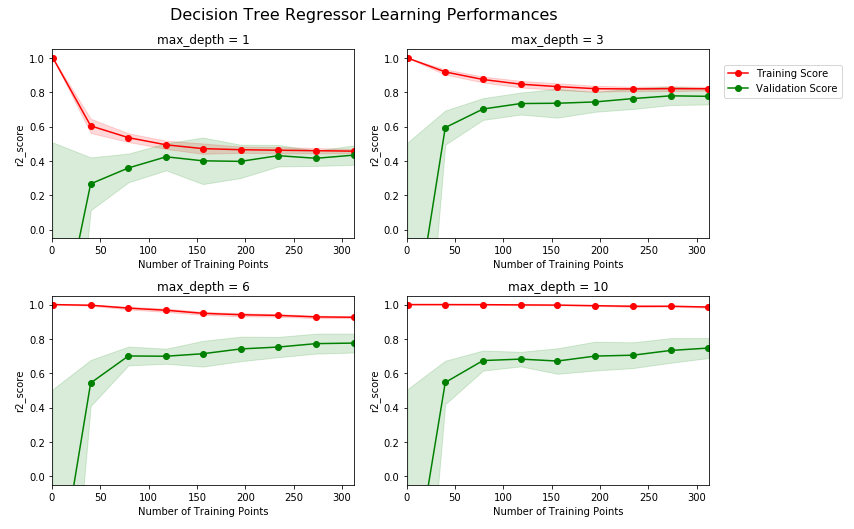
可以看到,超参数max_depth为1和3时,明显训练分数过低,这说明此时模型有欠拟合的情况,而当max_depth为6和10时,明显训练分数和验证分析差距过大,说明出现了过拟合,因此我们初步可以猜测,最佳参数在3和6之间,即4,5中的一个,其他参数一样可以通过学习曲线来进行可视化分析,判断是欠拟合还是过拟合,再分别进行针对处理;
小结
通过以上的几步,可以非常简单、清晰的看到一个机器学习项目的全流程,其实再复杂的流程也是这些简单步骤的一些扩展,而更难的往往是对业务的理解,没有足够的理解很难得到好的结果,体现出来就是特征工程部分做的好坏,这里就需要各位小伙伴们奋发图强了,路漫漫啊;
项目链接
- 通篇浏览可以通过nbviewer来看;
- 项目源文件、数据集文件可以通过GitHub波士顿项目获取,欢迎Follow、Fork、Star;
最后
大家可以到我的Github上看看有没有其他需要的东西,目前主要是自己做的机器学习项目、Python各种脚本工具、数据分析挖掘项目以及Follow的大佬、Fork的项目等:https://github.com/NemoHoHaloAi
波士顿房价预测 - 最简单入门机器学习 - Jupyter的更多相关文章
- 机器学习实战二:波士顿房价预测 Boston Housing
波士顿房价预测 Boston housing 这是一个波士顿房价预测的一个实战,上一次的Titantic是生存预测,其实本质上是一个分类问题,就是根据数据分为1或为0,这次的波士顿房价预测更像是预测一 ...
- Tensorflow之多元线性回归问题(以波士顿房价预测为例)
一.根据波士顿房价信息进行预测,多元线性回归+特征数据归一化 #读取数据 %matplotlib notebook import tensorflow as tf import matplotlib. ...
- 《用Python玩转数据》项目—线性回归分析入门之波士顿房价预测(二)
接上一部分,此篇将用tensorflow建立神经网络,对波士顿房价数据进行简单建模预测. 二.使用tensorflow拟合boston房价datasets 1.数据处理依然利用sklearn来分训练集 ...
- 【udacity】机器学习-波士顿房价预测小结
Evernote Export 机器学习的运行步骤 1.导入数据 没什么注意的,成功导入数据集就可以了,打印看下数据的标准格式就行 用个info和describe 2.分析数据 这里要详细分析数据的内 ...
- 【udacity】机器学习-波士顿房价预测
import numpy as np import pandas as pd from Udacity.model_check.boston_house_price import visuals as ...
- chapter02 回归模型在''美国波士顿房价预测''问题中实践
#coding=utf8 # 从sklearn.datasets导入波士顿房价数据读取器. from sklearn.datasets import load_boston # 从sklearn.mo ...
- 第三十六篇 入门机器学习——Jupyter Notebook中的魔法命令
No.1.魔法命令的基本形式是:%命令 No.2.运行脚本文件的命令:%run %run 脚本文件的地址 %run C:\Users\Jie\Desktop\hello.py # 脚本一旦 ...
- 基于sklearn的波士顿房价预测_线性回归学习笔记
> 以下内容是我在学习https://blog.csdn.net/mingxiaod/article/details/85938251 教程时遇到不懂的问题自己查询并理解的笔记,由于sklear ...
- Python之机器学习-波斯顿房价预测
目录 波士顿房价预测 导入模块 获取数据 打印数据 特征选择 散点图矩阵 关联矩阵 训练模型 可视化 波士顿房价预测 导入模块 import pandas as pd import numpy as ...
随机推荐
- Java连载24-break语句、continue语句、输出质数练习
一.break 1.break是Java语言中的关键字,被翻译为“中断/折断” 2.break + ";"可以成为一个单独的完整的java语句: break; 3.break语 ...
- java学习之String类
标签(空格分隔): String类 String 的概述 class StringDemo{ public static void main(String[] args){ String s1=&qu ...
- ubuntu安装elasticsearch及head插件
1.安装elasticsearch,参考http://www.cnblogs.com/hanyinglong/p/5409003.html就可以了 简单描述下: mkdir -p /usr/local ...
- NLP(二十一)根据已有文本LSTM自动生成文本
根据已有文本LSTM自动生成文本 原理 与股票预测类似,用前面的n个字符预测下一个字符 https://www.cnblogs.com/peng8098/p/keras_5.html 代码 from ...
- NLP(十三) 词义消歧
一个词可能有多个词义 例句 解释 She is my date date: 约会,日期 You have taken too many leaves to skip cleaning leaves i ...
- 杭电多校第九场 hdu6425 Rikka with Badminton 组合数学 思维
Rikka with Badminton Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 524288/524288 K (Java/O ...
- CSS特效集锦:视觉魔法的碰撞与融合(二)
引言 长久以来,我认识到.CSS,是存在极限的.正如曾经替你扛下一切的那个男人,也总有他眼含热泪地拼上一切,却也无法帮你做到的事情,他只能困窘地让你看到他的无能为力,怅然若失. 然后和曾经他成长的时代 ...
- 一次写文,多平台直接粘贴&打造最流畅的写作流程
文字爱好者的痛点 这一段可以跳过,解决办法在后面.因为大家既然痛过,也就懂了. 对于很多文字爱好者来说,都希望写一篇文章后,可以实现多平台发布. 国内的很多平台都开始支持 Markdown,除了微信公 ...
- AD 域服务简介(二)- Java 获取 AD 域用户
博客地址:http://www.moonxy.com 关于AD 域服务器搭建及其使用,请参阅:AD 域服务简介(一) - 基于 LDAP 的 AD 域服务器搭建及其使用 一.前言 先简单简单回顾上一篇 ...
- go语言新建多维map集合
1:map中加map var map1 map[string]map[string]string //声明变量 map1 = make(map[string]map[s ...