Hibernate教程 ---简单易懂
1 web内容回顾
(1)javaee三层结构
(2)mvc思想
2 hibernate概述
3 hibernate入门案例
4 hibernate配置文件
5 hibernate的api使用
Hibernate概述
什么是hibernate框架(重点)
1 hibernate框架应用在javaee三层结构中 dao层框架
2 在dao层里面做对数据库crud操作,使用hibernate实现crud操作,hibernate底层代码就是jdbc,hibernate对jdbc进行封装,使用hibernate好处,不需要写复杂jdbc代码了,
不需要写sql语句实现
3 hibernate开源的轻量级的框架
4 hibernate版本
Hibernate3.x
Hibernate4.x
Hibernate5.x(学习)
什么是orm思想(重点)
1 hibernate使用orm思想对数据库进行crud操作
2 在web阶段学习 javabean,更正确的叫法 实体类
3 orm:object relational mapping,对象关系映射
文字描述:
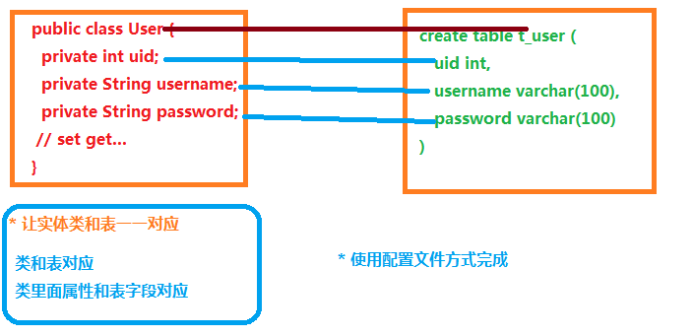
(1)让实体类和数据库表进行一一对应关系
让实体类首先和数据库表对应
让实体类属性 和 表里面字段对应
(2)不需要直接操作数据库表,而操作表对应实体类对象
画图描述

Hibernate入门
搭建hibernate环境(重点)
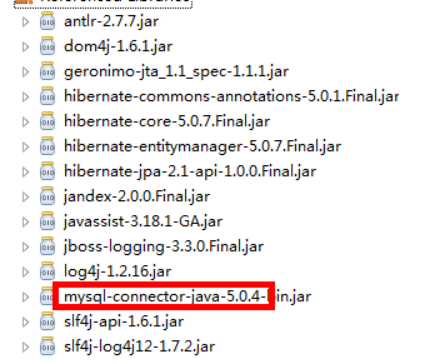
第一步 导入hibernate的jar包
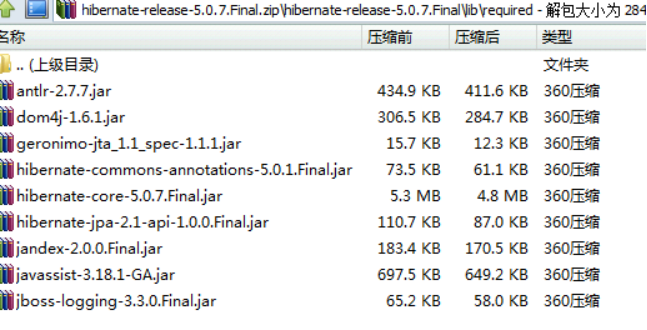
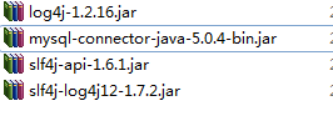
因为使用hibernate时候,有日志信息输出,hibernate本身没有日志输出的jar包,导入其他日志的jar包
不要忘记还有mysql驱动的jar包
第二步创建实体类
- package cn.itcast.entity;
- public class User {
- /*hibernate要求实体类有一个属性唯一的*/
- // private int uid;
- private String uid;
- private String username;
- private String password;
- private String address;
- // public int getUid() {
- // return uid;
- // }
- // public void setUid(int uid) {
- // this.uid = uid;
- // }
- public String getUsername() {
- return username;
- }
- public String getUid() {
- return uid;
- }
- public void setUid(String uid) {
- this.uid = uid;
- }
- public void setUsername(String username) {
- this.username = username;
- }
- public String getPassword() {
- return password;
- }
- public void setPassword(String password) {
- this.password = password;
- }
- public String getAddress() {
- return address;
- }
- public void setAddress(String address) {
- this.address = address;
- }
- }
(1)使用hibernate时候,不需要自己手动创建表,hibernate帮把表创建
第三步 配置实体类和数据库表一一对应关系(映射关系)
使用配置文件实现映射关系
(1)创建xml格式的配置文件
- 映射配置文件名称和位置没有固定要求
- 建议:在实体类所在包里面创建,实体类名称.hbm.xml
(2)配置是是xml格式,在配置文件中首先引入xml约束
- 学过约束dtd、schema,在hibernate里面引入的约束dtd约束

(3)配置映射关系
- <hibernate-mapping>
- <!-- 1 配置类和表对应
- class标签
- name属性:实体类全路径
- table属性:数据库表名称
- -->
- <class name="cn.itcast.entity.User" table="t_user">
- <!-- 2 配置实体类id和表id对应
- hibernate要求实体类有一个属性唯一值
- hibernate要求表有字段作为唯一值
- -->
- <!-- id标签
- name属性:实体类里面id属性名称
- column属性:生成的表字段名称
- -->
- <id name="uid" column="uid">
- <!-- 设置数据库表id增长策略
- native:生成表id值就是主键自动增长
- -->
- <generator class="native"></generator>
- </id>
- <!-- 配置其他属性和表字段对应
- name属性:实体类属性名称
- column属性:生成表字段名称
- -->
- <property name="username" column="username"></property>
- <property name="password" column="password"></property>
- <property name="address" column="address"></property>
- </class>
- </hibernate-mapping>
第四步 创建hibernate的核心配置文件
(1)核心配置文件格式xml,但是核心配置文件名称和位置固定的
- 位置:必须src下面
- 名称:必须hibernate.cfg.xml
(2)引入dtd约束
(3)hibernate操作过程中,只会加载核心配置文件,其他配置文件不会加载
第一部分: 配置数据库信息 必须的
第二部分:配置hibernate信息 可选的
第三部分:把映射文件放到核心配置文件中
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE hibernate-configuration PUBLIC
- "-//Hibernate/Hibernate Configuration DTD 3.0//EN"
- "http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
- <hibernate-configuration>
- <session-factory>
- <!-- 第一部分: 配置数据库信息 必须的 -->
- <property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
- <property name="hibernate.connection.url">jdbc:mysql:///hibernate_day01</property>
- <property name="hibernate.connection.username">root</property>
- <property name="hibernate.connection.password">root</property>
- <!-- 第二部分: 配置hibernate信息 可选的-->
- <!-- 输出底层sql语句 -->
- <property name="hibernate.show_sql">true</property>
- <!-- 输出底层sql语句格式 -->
- <property name="hibernate.format_sql">true</property>
- <!-- hibernate帮创建表,需要配置之后
- update: 如果已经有表,更新,如果没有,创建
- -->
- <property name="hibernate.hbm2ddl.auto">update</property>
- <!-- 配置数据库方言
- 在mysql里面实现分页 关键字 limit,只能使用mysql里面
- 在oracle数据库,实现分页rownum
- 让hibernate框架识别不同数据库的自己特有的语句
- -->
- <property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property>
- <!-- 第三部分: 把映射文件放到核心配置文件中 必须的-->
- <mapping resource="cn/itcast/entity/User.hbm.xml"/>
- </session-factory>
- </hibernate-configuration>
实现添加操作
第一步 加载hibernate核心配置文件
第二步 创建SessionFactory对象
第三步 使用SessionFactory创建session对象
第四步 开启事务
第五步 写具体逻辑 crud操作
第六步 提交事务
第七步 关闭资源
- @Test
- public void testAdd() {
- // 第一步 加载hibernate核心配置文件
- // 到src下面找到名称是hibernate.cfg.xml
- //在hibernate里面封装对象
- Configuration cfg = new Configuration();
- cfg.configure();
- // 第二步 创建SessionFactory对象
- //读取hibernate核心配置文件内容,创建sessionFactory
- //在过程中,根据映射关系,在配置数据库里面把表创建
- SessionFactory sessionFactory = cfg.buildSessionFactory();
- // 第三步 使用SessionFactory创建session对象
- // 类似于连接
- Session session = sessionFactory.openSession();
- // 第四步 开启事务
- Transaction tx = session.beginTransaction();
- // 第五步 写具体逻辑 crud操作
- //添加功能
- User user = new User();
- user.setUsername("小王");
- user.setPassword("250");
- user.setAddress("日本");
- //调用session的方法实现添加
- session.save(user);
- // 第六步 提交事务
- tx.commit();
- // 第七步 关闭资源
- session.close();
- sessionFactory.close();
- }
内容目录
1 实体类编写规则
2 hibernate主键生成策略
(1)native
(2)uuid
3 实体类操作
(1)crud操作
(2)实体类对象状态
4 hibernate的一级缓存
5 hibernate的事务操作
(1)事务代码规范写法
6 hibernate其他的api(查询)
(1)Query
(2)Criteria
(3)SQLQuery
实体类编写规则
1 实体类里面属性私有的
2 私有属性使用公开的set和get方法操作
3 要求实体类有属性作为唯一值(一般使用id值)
4 实体类属性建议不使用基本数据类型,使用基本数据类型对应的包装类
(1)八个基本数据类型对应的包装类
- int – Integer
- char—Character、
- 其他的都是首字母大写 比如 double – Double
(2)比如 表示学生的分数,假如 int score;
- 比如学生得了0分 ,int score = 0;
- 如果表示学生没有参加考试,int score = 0;不能准确表示学生是否参加考试
l 解决:使用包装类可以了, Integer score = 0,表示学生得了0分,
表示学生没有参加考试,Integer score = null;
Hibernate主键生成策略
1 hibernate要求实体类里面有一个属性作为唯一值,对应表主键,主键可以不同生成策略
2 hibernate主键生成策略有很多的值

3 在class属性里面有很多值
(1)native: 根据使用的数据库帮选择哪个值
(2)uuid:之前web阶段写代码生成uuid值,hibernate帮我们生成uuid值
实体类操作
对实体类crud操作
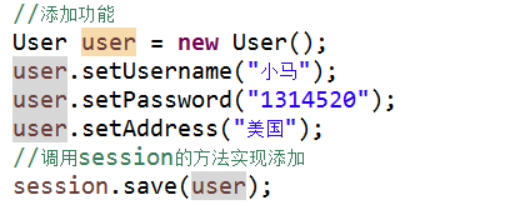
添加操作
1 调用session里面的save方法实现
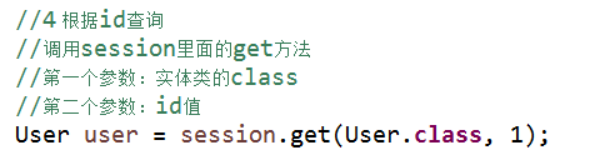
根据id查询
1 调用session里面的get方法实现
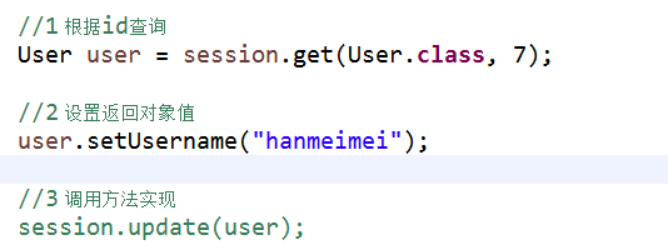
修改操作
1 首先查询,修改值
(1)根据id查询,返回对象

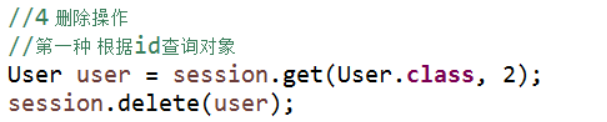
删除操作
1 调用session里面delete方法实现
实体类对象状态(概念)
1 实体类状态有三种
(1)瞬时态:对象里面没有id值,对象与session没有关联

(2)持久态:对象里面有id值,对象与session关联

(3)托管态:对象有id值,对象与session没有关联
2 演示操作实体类对象的方法
(1)saveOrUpdate方法:实现添加、实现修改

Hibernate的一级缓存
什么是缓存
1 数据存到数据库里面,数据库本身是文件系统,使用流方式操作文件效率不是很高。
(1)把数据存到内存里面,不需要使用流方式,可以直接读取内存中数据
(2)把数据放到内存中,提供读取效率
Hibernate缓存
1 hibernate框架中提供很多优化方式,hibernate的缓存就是一个优化方式
2 hibernate缓存特点:
第一类 hibernate的一级缓存
(1)hibernate的一级缓存默认打开的
(2)hibernate的一级缓存使用范围,是session范围,从session创建到session关闭范围
(3)hibernate的一级缓存中,存储数据必须 持久态数据
第二类 hibernate的二级缓存
(1)目前已经不使用了,替代技术 redis
(2)二级缓存默认不是打开的,需要配置
(3)二级缓存使用范围,是sessionFactory范围
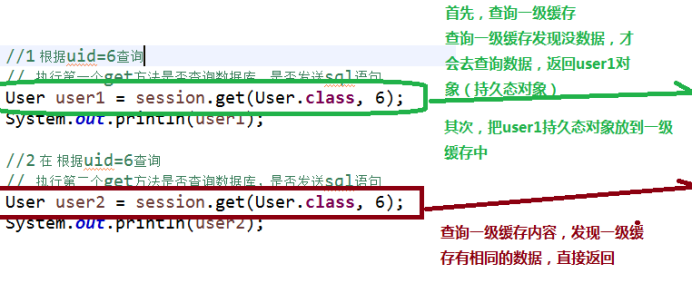
验证一级缓存存在
1 验证方式
(1)首先根据uid=1查询,返回对象
(2)其次再根据uid=1查询,返回对象

第一步执行get方法之后,发送sql语句查询数据库
第二个执行get方法之后,没有发送sql语句,查询一级缓存内容
Hibernate一级缓存执行过程
Hibernate一级缓存特性
1 持久态自动更新数据库
Hibernate事务操作
事务相关概念
1 什么是事务
2 事务特性
3 不考虑隔离性产生问题
(1)脏读
(2)不可重复读
(3)虚读
4 设置事务隔离级别
(1)mysql默认隔离级别 repeatable read
Hibernate事务代码规范写法
1 代码结构
try {
开启事务
提交事务
}catch() {
回滚事务
}finally {
关闭
}
- @Test
- public void testTx() {
- SessionFactory sessionFactory = null;
- Session session = null;
- Transaction tx = null;
- try {
- sessionFactory = HibernateUtils.getSessionFactory();
- session = sessionFactory.openSession();
- //开启事务
- tx = session.beginTransaction();
- //添加
- User user = new User();
- user.setUsername("小马");
- user.setPassword("250");
- user.setAddress("美国");
- session.save(user);
- int i = 10/0;
- //提交事务
- tx.commit();
- }catch(Exception e) {
- e.printStackTrace();
- //回滚事务
- tx.rollback();
- }finally {
- //关闭操作
- session.close();
- sessionFactory.close();
- }
- }
Hibernate绑定session
session类似于jdbc的connection,之前web阶段学过 ThreadLocal
2 帮实现与本地线程绑定session
3 获取与本地线程session
(1)在hibernate核心配置文件中配置

(2)调用sessionFactory里面的方法得到
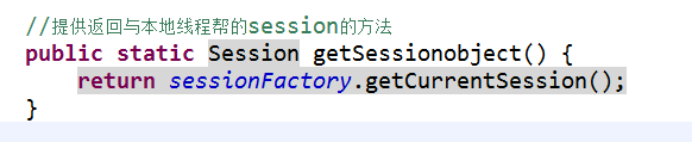
4 获取与本地线程绑定session时候,关闭session报错,不需要手动关闭了

Hibernate的api使用
Query对象
1 使用query对象,不需要写sql语句,但是写hql语句
(1)hql:hibernate query language,hibernate提供查询语言,这个hql语句和普通sql语句很相似
(2)hql和sql语句区别:
- 使用sql操作表和表字段
- 使用hql操作实体类和属性
2 查询所有hql语句:
(1)from 实体类名称
3 Query对象使用
(1)创建Query对象
(2)调用query对象里面的方法得到结果

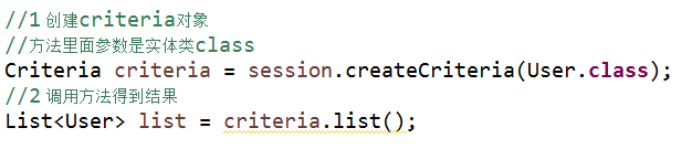
Criteria对象
1 使用这个对象查询操作,但是使用这个对象时候,不需要写语句,直接调用方法实现
2 实现过程
(1)创建criteria对象
(2)调用对象里面的方法得到结果
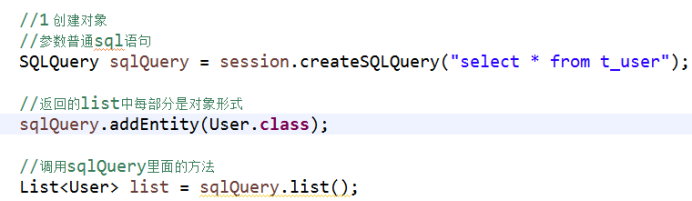
SQLQuery对象
1 使用hibernate时候,调用底层sql实现
2 实现过程
(1)创建对象
(2)调用对象的方法得到结果
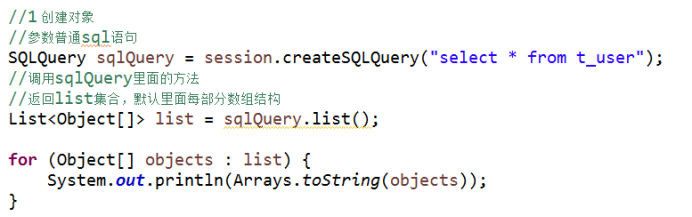
返回list集合每部分是数组

返回list中每部分是对象形式

1 表与表之间关系回顾
(1)一对多(客户和联系人)
(2)多对多(用户和角色)
2 hibernate一对多操作
(1)一对多映射配置
(2)一对多级联保存
(3)一对多级联删除
(4)inverse属性
3 hibernate多对多操作
(1)多对多映射配置
(2)多对多级联保存(重点)
(3)多对多级联删除
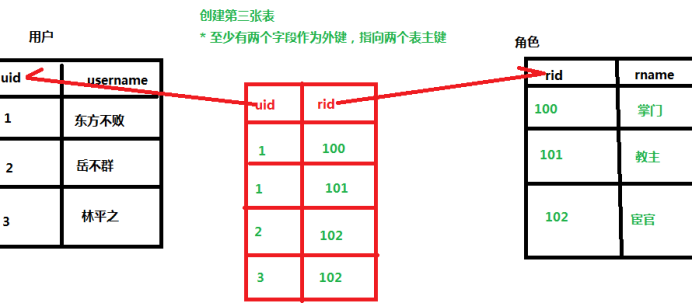
(4)维护第三张表
客户列表功能
1 sessionFactory已经关闭了,不需要关闭


2 dao里面代码
- //使用hibernate实现查询列表
- public List<Customer> findAll() {
- SessionFactory sessionFactory = null;
- Session session = null;
- Transaction tx = null;
- try {
- //得到sessionFactory
- sessionFactory = HibernateUtils.getSessionFactory();
- //得到session
- session = sessionFactory.openSession();
- //开启事务
- tx = session.beginTransaction();
- //查询所有记录
- Criteria criteria = session.createCriteria(Customer.class);
- List<Customer> list = criteria.list();
- //提交事务
- tx.commit();
- return list;
- }catch(Exception e) {
- tx.rollback();
- }finally {
- session.close();
- //sessionFactory不需要关闭
- // sessionFactory.close();
- }
- return null;
- }
表与表之间关系回顾(重点)
1 一对多
(1)分类和商品关系,一个分类里面有多个商品,一个商品只能属于一个分类
(2)客户和联系人是一对多关系
- 客户:与公司有业务往来,百度、新浪、360
- 联系人:公司里面的员工,百度里面有很多员工,联系员工
** 公司和公司员工的关系
- 客户是一,联系人是多
- 一个客户里面有多个联系人,一个联系人只能属于一个客户
(3)一对多建表:通过外键建立关系

2 多对多
(1)订单和商品关系,一个订单里面有多个商品,一个商品属于多个订单
(2)用户和角色多对多关系
- 用户: 小王、小马、小宋
- 角色:总经理、秘书、司机、保安
** 比如小王 可以 是总经理,可以是司机
** 比如小宋 可以是司机,可以是秘书,可以保安
** 比如小马 可以是 秘书,可以是总经理
- 一个用户里面可以有多个角色,一个角色里面可以有多个用户
(3)多对多建表:创建第三张表维护关系
3 一对一
(1)在中国,一个男人只能有一个妻子,一个女人只能有一个丈夫
Hibernate的一对多操作(重点)
一对多映射配置(重点)
以客户和联系人为例:客户是一,联系人是多
第一步 创建两个实体类,客户和联系人
第二步 让两个实体类之间互相表示
(1)在客户实体类里面表示多个联系人
- 一个客户里面有多个联系人
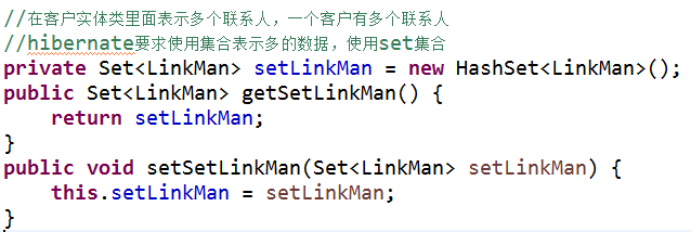
(2)在联系人实体类里面表示所属客户
- 一个联系人只能属于一个客户

第三步配置映射关系
(1)一般一个实体类对应一个映射文件
(2)把映射最基本配置完成
(3)在映射文件中,配置一对多关系
- 在客户映射文件中,表示所有联系人

- 在联系人映射文件中,表示所属客户

第四步创建核心配置文件,把映射文件引入到核心配置文件中

一对多级联操作
级联操作
1 级联保存
(1)添加一个客户,为这个客户添加多个联系人
2 级联删除
(1)删除某一个客户,这个客户里面的所有的联系人也删除
一对多级联保存
1 添加客户,为这个客户添加一个联系人
(1)复杂写法:
- //演示一对多级联保存
- @Test
- public void testAddDemo1() {
- SessionFactory sessionFactory = null;
- Session session = null;
- Transaction tx = null;
- try {
- //得到sessionFactory
- sessionFactory = HibernateUtils.getSessionFactory();
- //得到session
- session = sessionFactory.openSession();
- //开启事务
- tx = session.beginTransaction();
- // 添加一个客户,为这个客户添加一个联系人
- //1 创建客户和联系人对象
- Customer customer = new Customer();
- customer.setCustName("传智播客");
- customer.setCustLevel("vip");
- customer.setCustSource("网络");
- customer.setCustPhone("110");
- customer.setCustMobile("999");
- LinkMan linkman = new LinkMan();
- linkman.setLkm_name("lucy");
- linkman.setLkm_gender("男");
- linkman.setLkm_phone("911");
- //2 在客户表示所有联系人,在联系人表示客户
- // 建立客户对象和联系人对象关系
- //2.1 把联系人对象 放到客户对象的set集合里面
- customer.getSetLinkMan().add(linkman);
- //2.2 把客户对象放到联系人里面
- linkman.setCustomer(customer);
- //3 保存到数据库
- session.save(customer);
- session.save(linkman);
- //提交事务
- tx.commit();
- }catch(Exception e) {
- tx.rollback();
- }finally {
- session.close();
- //sessionFactory不需要关闭
- sessionFactory.close();
- }
- }
(2)简化写法
- 一般根据客户添加联系人
第一步 在客户映射文件中进行配置
- 在客户映射文件里面set标签进行配置

第二步创建客户和联系人对象,只需要把联系人放到客户里面就可以了,最终只需要保存客户就可以了
- //演示一对多级联保存
- @Test
- public void testAddDemo2() {
- SessionFactory sessionFactory = null;
- Session session = null;
- Transaction tx = null;
- try {
- //得到sessionFactory
- sessionFactory = HibernateUtils.getSessionFactory();
- //得到session
- session = sessionFactory.openSession();
- //开启事务
- tx = session.beginTransaction();
- // 添加一个客户,为这个客户添加一个联系人
- //1 创建客户和联系人对象
- Customer customer = new Customer();
- customer.setCustName("百度");
- customer.setCustLevel("普通客户");
- customer.setCustSource("网络");
- customer.setCustPhone("110");
- customer.setCustMobile("999");
- LinkMan linkman = new LinkMan();
- linkman.setLkm_name("小宏");
- linkman.setLkm_gender("男");
- linkman.setLkm_phone("911");
- //2 把联系人放到客户里面
- customer.getSetLinkMan().add(linkman);
- //3 保存客户
- session.save(customer);
- //提交事务
- tx.commit();
- }catch(Exception e) {
- tx.rollback();
- }finally {
- session.close();
- //sessionFactory不需要关闭
- sessionFactory.close();
- }
- }
一对多级联删除
1 删除某个客户,把客户里面所有的联系人删除
2 具体实现
第一步 在客户映射文件set标签,进行配置
(1)使用属性cascade属性值 delete

第二步在代码中直接删除客户
(1)根据id查询对象,调用session里面delete方法删除

一对多修改操作(inverse属性)
2 inverse属性
(1)因为hibernate双向维护外键,在客户和联系人里面都需要维护外键,修改客户时候修改一次外键,修改联系人时候也修改一次外键,造成效率问题
(2)解决方式:让其中的一方不维护外键
- 一对多里面,让其中一方放弃外键维护
- 一个国家有总统,国家有很多人,总统不能认识国家所有人,国家所有人可以认识总统
(3)具体实现:
在放弃关系维护映射文件中,进行配置,在set标签上使用inverse属性

Hibernate多对多操作
多对多映射配置
以用户和角色为例演示
第一步 创建实体类,用户和角色
第二步 让两个实体类之间互相表示
(1)一个用户里面表示所有角色,使用set集合
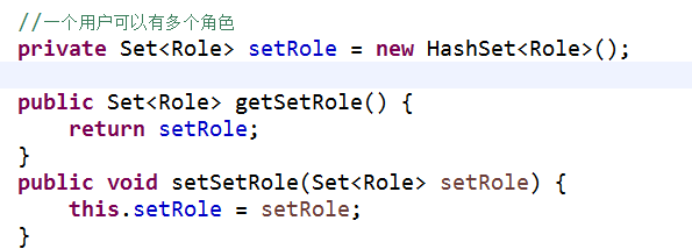
(2)一个角色有多个用户,使用set集合
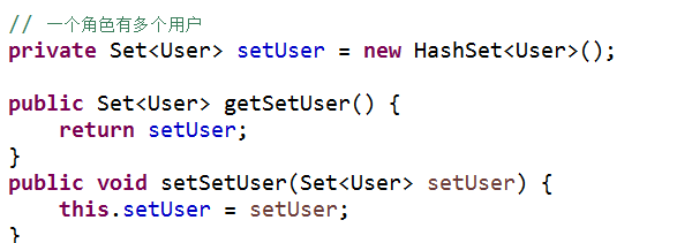
第三步配置映射关系
(1)基本配置
(2)配置多对多关系
- 在用户里面表示所有角色,使用set标签

- 在角色里面表示所有用户,使用set标签

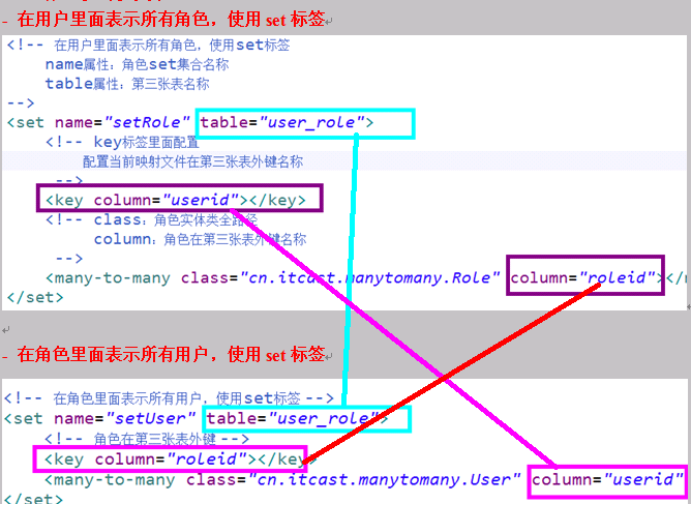
第四步在核心配置文件中引入映射文件

多对多级联保存
根据用户保存角色
第一步 在用户配置文件中set标签进行配置,cascade值save-update
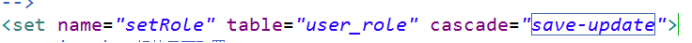
第二步写代码实现
(1)创建用户和角色对象,把角色放到用户里面,最终保存用户就可以了
- //演示多对多修级联保存
- @Test
- public void testSave() {
- SessionFactory sessionFactory = null;
- Session session = null;
- Transaction tx = null;
- try {
- //得到sessionFactory
- sessionFactory = HibernateUtils.getSessionFactory();
- //得到session
- session = sessionFactory.openSession();
- //开启事务
- tx = session.beginTransaction();
- //添加两个用户,为每个用户添加两个角色
- //1 创建对象
- User user1 = new User();
- user1.setUser_name("lucy");
- user1.setUser_password("123");
- User user2 = new User();
- user2.setUser_name("mary");
- user2.setUser_password("456");
- Role r1 = new Role();
- r1.setRole_name("总经理");
- r1.setRole_memo("总经理");
- Role r2 = new Role();
- r2.setRole_name("秘书");
- r2.setRole_memo("秘书");
- Role r3 = new Role();
- r3.setRole_name("保安");
- r3.setRole_memo("保安");
- //2 建立关系,把角色放到用户里面
- // user1 -- r1/r2
- user1.getSetRole().add(r1);
- user1.getSetRole().add(r2);
- // user2 -- r2/r3
- user2.getSetRole().add(r2);
- user2.getSetRole().add(r3);
- //3 保存用户
- session.save(user1);
- session.save(user2);
- //提交事务
- tx.commit();
- }catch(Exception e) {
- tx.rollback();
- }finally {
- session.close();
- //sessionFactory不需要关闭
- sessionFactory.close();
- }
- }
多对多级联删除(了解)
第一步 在set标签进行配置,cascade值delete
第二步 删除用户


维护第三张表关系
1 用户和角色多对多关系,维护关系通过第三张表维护
2 让某个用户有某个角色
第一步 根据id查询用户和角色
第二步 把角色放到用户里面
(1)把角色对象放到用户set集合
3 让某个用户没有某个角色
第一步 根据id查询用户和角色

第二步从用户里面把角色去掉
(1)从set集合里面把角色移除

Hibernate五种查询方式
1 对象导航查询
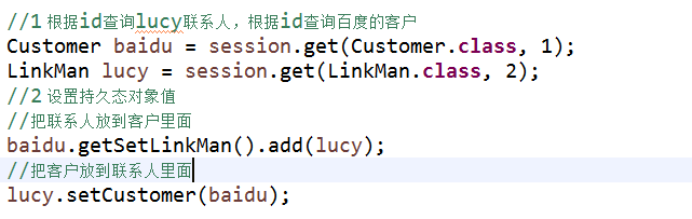
(1)根据id查询某个客户,再查询这个客户里面所有的联系人
2 OID查询
(1)根据id查询某一条记录,返回对象
3 HQL查询
(1)Query对象,写hql语句实现查询
4 QBC查询
(1)Criteria对象
5 本地sql查询
(1)SQLQuery对象,使用普通sql实现查询
对象导航查询
1 查询某个客户里面所有联系人过程,使用对象导航实现
2 代码

OID查询
1 根据id查询记录
(1)调用session里面的get方法实现

HQL查询
1 hql:hibernate query language,hibernate提供一种查询语言,hql语言和普通sql很相似,区别:普通sql操作数据库表和字段,hql操作实体类和属性
2 常用的hql语句
(1)查询所有: from 实体类名称
(2)条件查询: from 实体类名称 where 属性名称=?
(3)排序查询: from 实体类名称 order by 实体类属性名称 asc/desc
3 使用hql查询操作时候,使用Query对象
(1)创建Query对象,写hql语句
(2)调用query对象里面的方法得到结果
Query query = session.createQuery(
“from User user where user.group.name=‘zte’”);
查询所有
1 查询所有客户记录
(1)创建Query对象,写hql语句
(2)调用query对象里面的方法得到结果
2 查询所有: from 实体类名称

条件查询
1 hql条件查询语句写法:
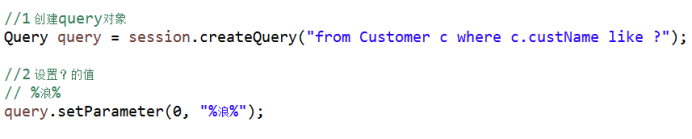
(1) from 实体类名称 where 实体类属性名称=? and实体类属性名称=?
from 实体类名称 where 实体类属性名称 like ?
2 代码


模糊查询
排序查询
1 hql排序语句写法
(1)from 实体类名称 order by 实体类属性名称 asc/desc

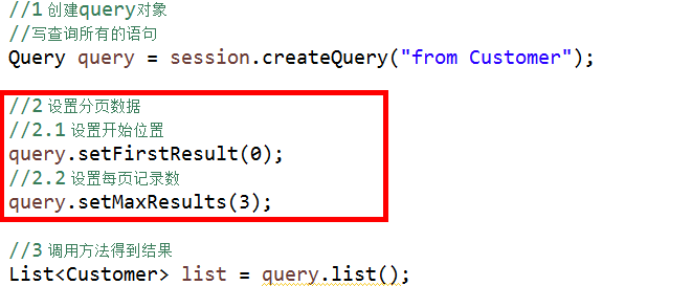
分页查询
1 mysql实现分页
(1)使用关键字 limit实现

2 在hql中实现分页
(1)在hql操作中,在语句里面不能写limit,hibernate的Query对象封装两个方法实现分页操作
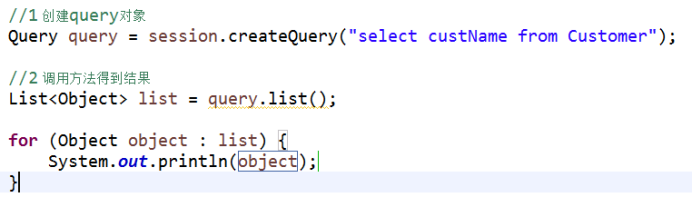
投影查询
1 投影查询:查询不是所有字段值,而是部分字段的值
2 投影查询hql语句写法:
(1)select 实体类属性名称1, 实体类属性名称2 from 实体类名称
(2)select 后面不能写 * ,不支持的
3 具体实现
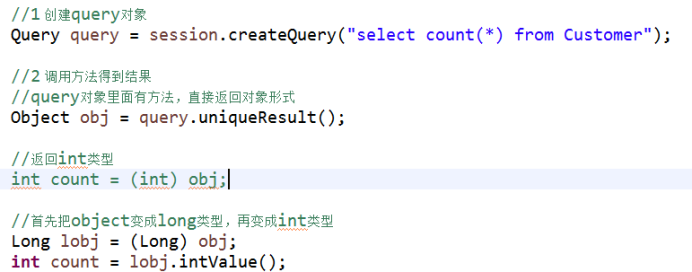
聚集函数使用
1 常用的聚集函数
(1)count、sum、avg、max、min
2 hql聚集函数语句写法
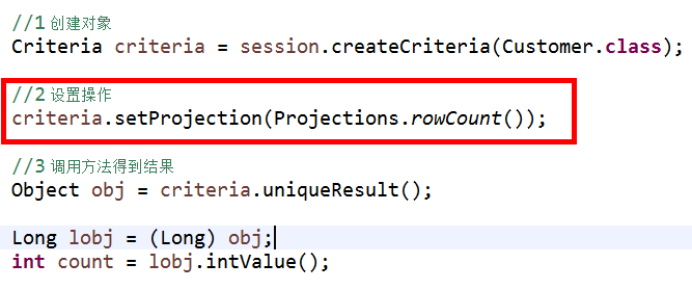
(1)查询表记录数
- select count(*) from 实体类名称
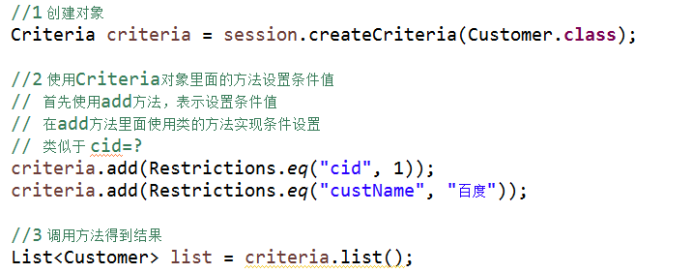
QBC查询
1 使用hql查询需要写hql语句实现,但是使用qbc时候,不需要写语句了,使用方法实现
2 使用qbc时候,操作实体类和属性
3 使用qbc,使用Criteria对象实现
查询所有
1 创建Criteria对象
2 调用方法得到结果

条件查询
1 没有语句,使用封装的方法实现

排序查询


分页查询
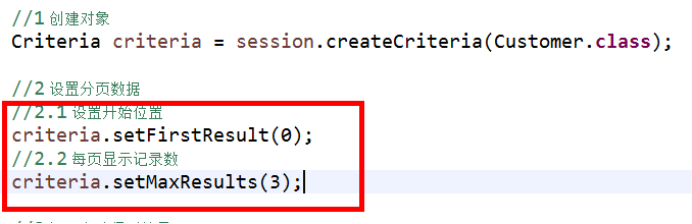
开始位置计算公式:(当前页-1)*每页记录数
统计查询
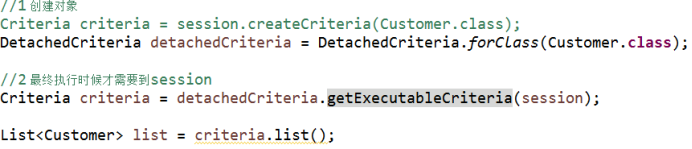
离线查询
1 servlet调用service,service调用dao
(1)在dao里面对数据库crud操作
(2)在dao里面使用hibernate框架,使用hibernate框架时候,调用session里面的方法实现功能
本地SQL查询
SQLQuery sql=session.createSQLQuery("select * from user where id=1 ");
sql.addEntity(User.class);
List<User> list=sql.list();
System.out.println(list);
HQL多表查询
Mysql里面多表查询
1 内连接

2 左外连接

3 右外连接

HQL实现多表查询
Hql多表查询
(1)内连接
(2)左外连接
(3)右外连接
(4)迫切内连接
(5)迫切左外连接
HQL内连接
1 内连接查询hql语句写法:以客户和联系人为例
(1)from Customer c inner join c.setLinkMan

返回list,list里面每部分是数组形式
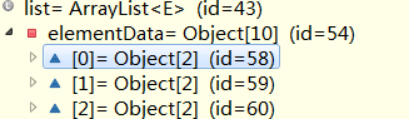
2 演示迫切内连接
(1)迫切内连接和内连接底层实现一样的
(2)区别:使用内连接返回list中每部分是数组,迫切内连接返回list每部分是对象
(3)hql语句写法
- from Customer c inner join fetch c.setLinkMan

HQL左外连接
1 左外连接hql语句:
(1)from Customer c left outer join c.setLinkMan
(2)迫切左外连接from Customer c left outer join fetch c.setLinkMan
2 左外连接返回list中每部分是数组,迫切左外连接返回list每部分是对象


1 右外连接hql语句:
(1)from Customer c right outer join c.setLinkMan
Hibernate检索策略
检索策略的概念
1 hibernate检索策略分为两类:
(1)立即查询:根据id查询,调用get方法,一调用get方法马上发送语句查询数据库

(2)延迟查询:根据id查询,还有load方法,调用load方法不会马上发送语句查询数据,只有得到对象里面的值时候才会发送语句查询数据库
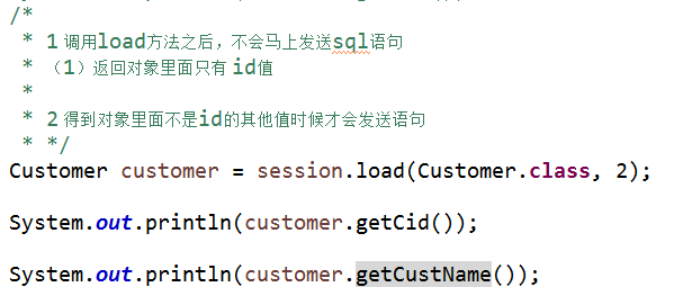
2 延迟查询分成两类:
(1)类级别延迟:根据id查询返回实体类对象,调用load方法不会马上发送语句
(2)关联级别延迟:
- 查询某个客户,再查询这个客户的所有联系人,查询客户的所有联系人的过程是否需要延迟,这个过程称为关联级别延迟
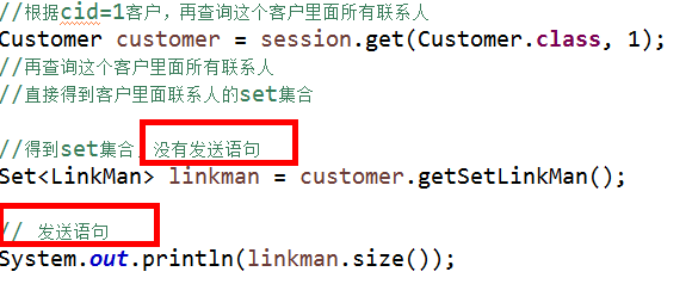
关联级别延迟操作
1 在映射文件中进行配置实现
(1)根据客户得到所有的联系人,在客户映射文件中配置
2 在set标签上使用属性
(1)fetch:值select(默认)
(2)lazy:值
- true:延迟(默认)
- false:不延迟
- extra:极其延迟


(1)调用get之后,发送两条sql语句

(1)极其懒惰,要什么值给什么值
批量抓取
1 查询所有的客户,返回list集合,遍历list集合,得到每个客户,得到每个客户的所有联系人
(1)上面操作代码,发送多条sql语句
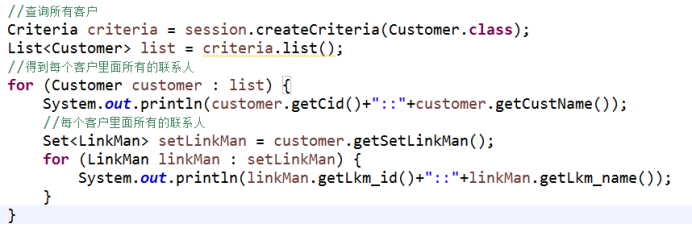
2 在客户的映射文件中,set标签配置
(1)batch-size值,值越大发送语句越少


Hibernate教程 ---简单易懂的更多相关文章
- centos7安装puppet详细教程(简单易懂,小白也可以看懂的教程)
简介: Puppet是一种linux.unix平台的集中配置管理系统,使用ruby语言,可配置文件.用户.cron任务.软件包.系统服务等.Puppet把这些系统实体称之为资源,它的设计目标是简化对这 ...
- BAT脚本编写教程(比较易懂和全面)
这篇文章主要介绍了BAT脚本编写教程,比较易懂和全面.适合有一定编程基础的人 作者不详.敬意! echo.@.call.pause.rem(小技巧:用::代替rem)是批处理文件最常用的几个命令, ...
- Jmeter教程 简单的压力测试
Jmeter教程 简单的压力测试:http://www.cnblogs.com/TankXiao/p/4059378.html
- Hibernate框架简单应用
Hibernate框架简单应用 Hibernate的核心组件在基于MVC设计模式的JAVA WEB应用中,Hibernate可以作为模型层/数据访问层.它通过配置文件(hibernate.proper ...
- 【repost】让你一句话理解闭包(简单易懂)
接触javascript很久了,每次理解闭包都似是而非,最近在找Web前端的工作,所以需要把基础夯实一下. 本文是参照了joy_lee的博客 闭包 在她这篇博客的基础上以批注的形式力争把我的理解阐述出 ...
- ssh架构之hibernate(一)简单使用hibernate完成CRUD
1.Hibernate简介 Hibernate是一个开放源代码的对象关系映射(ORM)框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个全自动的orm框架,h ...
- jmeter教程--简单的做压力测试
Jmeter是一个非常好用的压力测试工具. Jmeter用来做轻量级的压力测试,非常合适,只需要十几分钟,就能把压力测试需要的脚本写好. 什么是压力测试 顾名思义:压力测试,就是 被测试的系统,在 ...
- BAT脚本编写教程简单入门篇
BAT脚本编写教程简单入门篇 批处理文件最常用的几个命令: echo表示显示此命令后的字符 echo on 表示在此语句后所有运行的命令都显示命令行本身 echo off 表示在此语句后所有运行的命 ...
- 【转】JS回调函数--简单易懂有实例
JS回调函数--简单易懂有实例 初学js的时候,被回调函数搞得很晕,现在回过头来总结一下什么是回调函数. 我们先来看看回调的英文定义:A callback is a function that is ...
随机推荐
- HTML(一)简介,元素
HTML简介 html实例: <!DOCTYPE html> 菜鸟教程 我的第一个标题 我的第一个段落 实例解析: <!DOCTYPE html> 声明为 HTML5 文档,不 ...
- 在IIS下部署PHP
没有.net ramework 4.0 的要先安装 dotNetFx40_Full_x86_x64.exe PHP压缩包 推荐用5.6.29版 IIS下PHP压缩包下载地址:"http:// ...
- POJ-2387 Til the Cows Come Home ( 最短路 )
题目链接: http://poj.org/problem?id=2387 Description Bessie is out in the field and wants to get back to ...
- atcoder C - Snuke and Spells(模拟+思维)
题目链接:http://agc017.contest.atcoder.jp/tasks/agc017_c 题解:就是简单的模拟一下就行.看一下代码就能理解 #include <iostream& ...
- 牛客多校第六场 J Heritage of skywalkert 随即互质概率 nth_element(求最大多少项模板)
链接:https://www.nowcoder.com/acm/contest/144/J来源:牛客网 skywalkert, the new legend of Beihang University ...
- PAT 天梯杯 L2-014 列车调度
火车站的列车调度铁轨的结构如下图所示. Figure 两端分别是一条入口(Entrance)轨道和一条出口(Exit)轨道,它们之间有N条平行的轨道.每趟列车从入口可以选择任意一条轨道进入,最后从出口 ...
- [NOI2001]炮兵阵地 题解
题意 我们先来了解一下基本的位运算 于( \(\bigwedge\) ),或 (\(\bigvee\) ) 异或(\(\bigoplus\)) 在下面我们用(&)代表于,(|)代表或 一道状压 ...
- POJ 3083 Children of the Candy Corn (DFS + BFS)
POJ-3083 题意: 给一个h*w的地图. '#'表示墙: '.'表示空地: 'S'表示起点: 'E'表示终点: 1)在地图中仅有一个'S'和一个'E',他们为位于地图的边墙,不在墙角: 2)地图 ...
- [DP]换钱的方法数
题目三 给定数组arr, arr中所有的值都为整数且不重复.每个值代表一种面值的货币,每种面值的货币可以使用任意张,在给定一个整数aim代表要找的钱数,求换钱有多少种方法. 解法一 --暴力递归 用0 ...
- vuex-class用法
vuex-class可以包装vuex的写法,使代码简化 Installation $ npm install --save vuex-class Example import Vue from 'vu ...