Oracle 优化器_表连接
概述
在写SQL的时候,有时候涉及到的不仅只有一个表,这个时候,就需要表连接了。Oracle优化器处理SQL语句时,根据SQL语句,确定表的连接顺序(谁是驱动表,谁是被驱动表及 哪个表先和哪个表做链接)、连接方法(下文有详细介绍)及访问单表的方法(是否走索引,及走哪个索引)。
类型
表连接的类型分为两种:内连接和外连接。表连接的类型不同,得到的结果也不相同。不同的SQL语句使用不同的表连接。演示表连接我们用两个表t1和t2 。建表语句及数据如下:
-- 建表语句
CREATE TABLE T1(col1 number,col2 VARCHAR2(1));
CREATE TABLE T2(col2 VARCHAR2(1),col3 VARCHAR2(2));
-- 表1数据
INSERT INTO t1 VALUES(1,'A');
INSERT INTO t1 VALUES(2,'B');
INSERT INTO t1 VALUES(3,'C');
-- 表2 数据
INSERT INTO t2 VALUES('A','A2');
INSERT INTO t2 VALUES('B','B2');
INSERT INTO t2 VALUES('D','D2');
内连接
内连接,表的连接只包含满足条件的记录,Oracle数据库默认的链接方式,只要在SQL语句中没有(+),这里的(+)是Oracle特有的连接符号。或者 left outer join 、 right outer join 、full outer join 那么SQL的连接类型就是内连接。
内连接的写法:
1.Oracle自带(最常用):
SELECT T1.COL1,T1.COL2,T2.COL3 FROM T1,T2 WHERE T1.COL2 = t2.col2;
得到结果如下:

2.标准SQL写法:
SELECT T1.COL1,T1.COL2,T2.COL3 FROM T1 JOIN T2 ON (t1.col2= t2.col2);
结果如下:

3.标准SQL写法2:(这里需要注意的是SQL语句的红色部分,col2 字段前不能加表名)
SELECT T1.COL1,COL2,T2.COL3 FROM t1 join t2 using (col2);
结果如下:
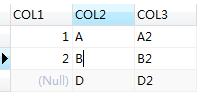
可以看出,三种内连接的写法得到的结果是一样的。运行执行计划,得出的执行计划也是相同的 :
Plan hash value: 1838229974 ---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 30 | 6 (0)| 00:00:01 |
|* 1 | HASH JOIN | | 3 | 30 | 6 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL| T1 | 3 | 15 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| T2 | 3 | 15 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 1 - access("T1"."COL2"="T2"."COL2")
关于join using 标准SQL中有一种特殊的join using ,写法如下:
SELECT t1.col1,col2,t2.col3 FROM t1 NATURAL JOIN t2;
它在当前表结构下,执行结果跟上面的SQL语句执行结果一样,执行计划也相同,但是在其他情况下就不一定相同了。因为它是取两个表中所有表名相同的列进行内连接,有可能有的列仅仅是命名相同,但是我们并不希望按照字段中内容进行过滤,那么这样写的话,就有可能得到一个错误的结果。所以开发中并不常用。
外连接
外连接是对内连接的扩展,执行时,除了将满足内连接条件的值查出来之外,还会包含驱动表中所有不满足连接条件的记录。外连接分为:左外连接、右外连接、全连接三种。下面分别介绍下:
左外连接
语法:
目标表1 left outer join 目标表2 on (连接条件)
或
目标表1 left outer join 目标表2 using(连接列集合)
SQL举例:
SELECT t1.col1,t1.col2,t2.col3 from t1 left outer join t2 on (t1.col2 = t2.col2);
-- 或
SELECT t1.col1,col2,t2.col3 from t1 left outer join t2 using (col2);
-- 或
SELECT T1.COL1,T1.COL2,T2.COL3 FROM T1,T2 WHERE T1.COL2 = t2.col2(+);
这里的第三种写法是Oracle特有的写法。这三种写法的执行结果一样:

执行计划也相同:
Plan hash value: 1823443478 ---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 60 | 6 (0)| 00:00:01 |
|* 1 | HASH JOIN OUTER | | 3 | 60 | 6 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL| T1 | 3 | 45 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| T2 | 3 | 15 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 1 - access("T1"."COL2"="T2"."COL2"(+))
这里因为表1作为驱动表,而表2中不包含col2 为C 的数据,所以在第三行结果中,col3 的值为null。
右外链接
右外链接跟左外连接类似,语法为:
目标表1 right outer join 目标表2 on (连接条件)
或
目标表1 right outer join 目标表2 using(连接列集合)
SQL 举例:
SELECT t1.col1,t2.col2,t2.col3 from t1 right outer join t2 on (t2.col2 = t1.col2);
-- 或
SELECT t1.col1,col2,t2.col3 from t1 right outer join t2 using (col2);
-- 或
SELECT T1.COL1,T2.COL2,T2.COL3 FROM T1,T2 WHERE T1.COL2(+) = t2.col2;
SQL查询得到的结果和执行计划也是一致的:
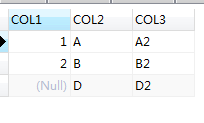
执行计划:
Plan hash value: 1426054487 ---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 60 | 6 (0)| 00:00:01 |
|* 1 | HASH JOIN OUTER | | 3 | 60 | 6 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL| T2 | 3 | 15 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| T1 | 3 | 45 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 1 - access("T1"."COL2"(+)="T2"."COL2")
全连接
语法为:
目标表1 full outer join 目标表2 on (连接条件)
或
目标表1 full outer join 目标表2 using(连接列集合)
SQL举例:
SELECT t1.col1,t1.col2,t2.col3 from t1 full outer join t2 on (t1.col2 = t2.col2);
-- 或
SELECT t1.col1,col2,t2.col3 from t1 full outer join t2 using (col2);
执行结果为:

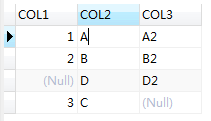
因为第一个语句限定了col2段的值为t1表,所以第三条结果的col2 字段为空。
执行计划相同:
Plan hash value: 53297166 ----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 54 | 6 (0)| 00:00:01 |
| 1 | VIEW | VW_FOJ_0 | 3 | 54 | 6 (0)| 00:00:01 |
|* 2 | HASH JOIN FULL OUTER| | 3 | 60 | 6 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL | T1 | 3 | 45 | 3 (0)| 00:00:01 |
| 4 | TABLE ACCESS FULL | T2 | 3 | 15 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 2 - access("T1"."COL2"="T2"."COL2")
全连接的效果为左连接+右链接,SQL如下:
SELECT t1.col1,t1.col2,t2.col3 from t1 right outer join t2 on (t1.col2 = t2.col2)
union
SELECT t1.col1,t1.col2,t2.col3 from t1 left outer join t2 on (t1.col2 = t2.col2);
执行结果如下;

可以看出得到的执行结果顺序不同,内容一致。但是,执行的时候,数据库的执行计划并不是这样的,下面是这条SQL的执行计划,通过对比跟全连接SQL的执行计划,可以看出,当前SQL是先查出左连接,再查出右连接,最后做了一个取并集的操作。而全连接是在取数据的时候,直接做的是取外连接的操作。
Plan hash value: 2747422401 -----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 6 | 120 | 14 (15)| 00:00:01 |
| 1 | SORT UNIQUE | | 6 | 120 | 14 (15)| 00:00:01 |
| 2 | UNION-ALL | | | | | |
|* 3 | HASH JOIN OUTER | | 3 | 60 | 6 (0)| 00:00:01 |
| 4 | TABLE ACCESS FULL| T2 | 3 | 15 | 3 (0)| 00:00:01 |
| 5 | TABLE ACCESS FULL| T1 | 3 | 45 | 3 (0)| 00:00:01 |
|* 6 | HASH JOIN OUTER | | 3 | 60 | 6 (0)| 00:00:01 |
| 7 | TABLE ACCESS FULL| T1 | 3 | 45 | 3 (0)| 00:00:01 |
| 8 | TABLE ACCESS FULL| T2 | 3 | 15 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 3 - access("T1"."COL2"(+)="T2"."COL2")
6 - access("T1"."COL2"="T2"."COL2"(+))
·特例:natural 在外连接中同样适用,和内连接的方法和弊端也相同。
反连接
见下文
半连接
见下文
方法
在Oracle优化器确定执行计划中表连接的类型之后,就会决定表连接的方法。表连接的方法有四种:1.排序合并连接、2.嵌套循环连接、3.哈希连接、4.笛卡尔积连接。下面我们分别介绍下这四种连接:
1.排序合并连接
排序合并连接,两个表做连接时,用排序和合并两种操作来得到结果集的连接方法。
sql举例(当前SQL只是为了演示排序合并连接而写的SQL,我还没有想好具体的使用场景,欢迎大家给出):
select t1.col1 ,t1.col2,t2.col2,t2.col3 from t2,t1 where t1.col2>t2.col2
执行结果:
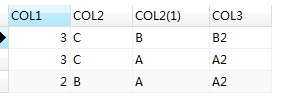
执行计划:
Plan hash value: 412793182 ----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 30 | 8 (25)| 00:00:01 |
| 1 | MERGE JOIN | | 3 | 30 | 8 (25)| 00:00:01 |
| 2 | SORT JOIN | | 3 | 15 | 4 (25)| 00:00:01 |
| 3 | TABLE ACCESS FULL| T2 | 3 | 15 | 3 (0)| 00:00:01 |
|* 4 | SORT JOIN | | 3 | 15 | 4 (25)| 00:00:01 |
| 5 | TABLE ACCESS FULL| T1 | 3 | 15 | 3 (0)| 00:00:01 |
---------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 4 - access(INTERNAL_FUNCTION("T1"."COL2")>INTERNAL_FUNCTION("T2"."COL
2"))
filter(INTERNAL_FUNCTION("T1"."COL2")>INTERNAL_FUNCTION("T2"."COL
2"))
通过执行计划可以看出,排序合并连接执行过程为(先执行t1还是t2的排序跟具体情况相关,当前SQL的执行顺序取决于from 关键字后 t1和t2的位置):
①首先对t1表中的数据按照where条件中的连接列来进行排序(Id 为4 那行的 SORT 操作),排序得到结果集1;
②然后对t2 执行类似的操作(Id 为2 那行的 SORT 操作)。
③最后,对两个结果集进行合并操作(Id为 1 的行的 MERGE 操作),将满足条件的记录作为最终结果。
2.嵌套循环连接
循环嵌套连接,两个表做连接的时候,靠两层嵌套循环(内循环和外循环)来得到连接结果的表连接方法。
举例:
-- 首先,创建一个索引在t2表
create index idx_t2 on t2(col2);
-- 然后执行SQL
select /*+ ordered use_n1(t2)*/ t1.col1 ,t1.col2,t2.col3 from t1,t2 where t1.col2= t2.col2
得到执行结果:
Plan hash value: 1054738919 ---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 30 | 6 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | 3 | 30 | 6 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 3 | 30 | 6 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL | T1 | 3 | 15 | 3 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | IDX_T2 | 1 | | 0 (0)| 00:00:01 |
| 5 | TABLE ACCESS BY INDEX ROWID| T2 | 1 | 5 | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 4 - access("T1"."COL2"="T2"."COL2")
其执行过程类似于两个for循环的感觉 :
①首先,确定哪个表做外循环,哪个表做内循环。
②然后,访问外循环的表数据,得到结果集1;
③最后,遍历结果集1中的每一条记录,然后每条记录作为匹配条件去遍历一遍表2去查看是否有存在匹配的数据。得到返回的数据。
总结:
对于嵌套循环连接,外循环中有多少条记录,内循环就要做多少次遍历数据的操作。适用于外循环的结果集较少,同时内循环建立有索引,且索引选择率较高的场景。
嵌套循环可以快速响应,它可以第一时间返回满足条件的记录,而不用等整个循环执行完毕。
3.哈希连接
哈希链接可以简单理解为(t1,t2表为例):
①根据谓语条件判断两个表哪个表的结果集较小就作为驱动表。
②根据驱动表的列,计算出一个哈希值,进行缓存。
③计算被驱动表,每一行对应列的哈希值,判断是否在缓存中存在该哈希值,如果存在,进一步判断是否对应列内容一致。
⑤将对应的内容输出。
哈希链接实际情况要更加复杂,这里只是大概介绍下。
4.笛卡尔连接
两个表的积成,在两个表做连接时,没有任何连接条件时的表连接方法。
SQL举例:
select t1.col1 ,t1.col2,t2.col3 from t1,t2
执行结果:

执行计划:
Plan hash value: 787647388 -----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 9 | 72 | 9 (0)| 00:00:01 |
| 1 | MERGE JOIN CARTESIAN| | 9 | 72 | 9 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL | T1 | 3 | 15 | 3 (0)| 00:00:01 |
| 3 | BUFFER SORT | | 3 | 9 | 6 (0)| 00:00:01 |
| 4 | TABLE ACCESS FULL | T2 | 3 | 9 | 2 (0)| 00:00:01 |
----------------------------------------------------------------------------- Note
执行步骤:
①访问表t1,得到结果集1
②访问表t2,得到结果集2
③对结果集1和结果集2做合并操作。因为没有表连接条件,所以每一条结果集2都可以合并结果集1中的每一条数据,所以得到的结果集总数为:t1表行数* t2表行数
注:笛卡尔积一般都是因为SQL语句中where条件漏写导致的。笛卡尔积中两表数据很大那么SQL效率会受到严重影响。
反连接
反连接,一种特殊连接类型。查询出表1中不等于表2中某些字段数据的值。
SQL举例:
-- not in
select * from t1 where col2 not in (select col2 from t2); -- <> all
select * from t1 where col2 <> all (select col2 from t2); -- not exists select * from t1 where not exists (select 1 from t2 where col2= t1.col2);
执行计划分别为:
-- not in Plan hash value: 1275484728 ---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 7 | 6 (0)| 00:00:01 |
|* 1 | HASH JOIN ANTI NA | | 1 | 7 | 6 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL| T1 | 3 | 15 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| T2 | 3 | 6 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 1 - access("COL2"="COL2") Note
-- <> all
Plan hash value: 1275484728 ---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 7 | 6 (0)| 00:00:01 |
|* 1 | HASH JOIN ANTI NA | | 1 | 7 | 6 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL| T1 | 3 | 15 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| T2 | 3 | 6 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 1 - access("COL2"="COL2")
-- not exists Plan hash value: 2706079091 ---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 7 | 6 (0)| 00:00:01 |
|* 1 | HASH JOIN ANTI | | 1 | 7 | 6 (0)| 00:00:01 |
| 2 | TABLE ACCESS FULL| T1 | 3 | 15 | 3 (0)| 00:00:01 |
| 3 | TABLE ACCESS FULL| T2 | 3 | 6 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 1 - access("COL2"="T1"."COL2")
对比执行计划,可以看出,not in 和 <> all 的写法,执行计划完全一样,虽然 not exists 的写法的执行计划id为1的行没有NA的字符。但是他们都有 HASH JOIN ANTI 的关键字。说明Oracle都将他们转化为了 如下的等价形式:
select t1.* from t1,t2 where t1.col2 anti= t2.col2;
这里的NA的区别为:当表字段中出现null值后,两者的返回结果就不一致了。
在t1表添加一行:
INSERT into t1 VALUES (4,null);
commit;
执行结果:
not in 和 not exists
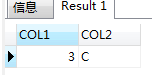
not exists
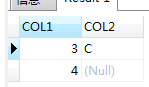
这是因为,前两个对null敏感,一旦遇到null,则当前行记录直接认为不符合。而not exists 对null不敏感,将null作为普通数据处理。
半连接
半连接的关键词为:in any exists ;
SQL举例:
-- in
select * from t1 where col2 in (select col2 from t2); -- any select * from t1 where col2 = any (select col2 from t2); --exists select * from t1 where exists (select 1 from t2 where col2= t1.col2);
执行结果都是

半连接逻辑:
①扫描t1,得到结果集1
②根据结果集1的每条记录扫描t2,只要在t2中找到符合条件的结果,那么立马停止扫描t2,将结果放入待返回的结果集
③ 返回结果集
注:当前博客Oracle 版本为11g,其他版本执行计划可能不一致。
Oracle 优化器_表连接的更多相关文章
- Oracle 优化器_访问数据的方法_单表
Oracle 在选择执行计划的时候,优化器要决定用什么方法去访问存储在数据文件中的数据.我们从数据文件中查询到相关记录,有两种方法可以实现:1.直接访问表记录所在位置.2.访问索引,拿到索引中对应的r ...
- ORACLE优化器RBO与CBO介绍总结
RBO和CBO的基本概念 Oracle数据库中的优化器又叫查询优化器(Query Optimizer).它是SQL分析和执行的优化工具,它负责生成.制定SQL的执行计划.Oracle的优化器有两种,基 ...
- Oracle优化器介绍
Oracle优化器介绍 本文讲述了Oracle优化器的概念.工作原理和使用方法,兼顾了Oracle8i.9i以及最新的10g三个版本.理解本文将有助于您更好的更有效的进行SQL优化工作. RBO优化器 ...
- 看懂Oracle执行计划、表连接方式
看懂Oracle执行计划 原文:https://www.cnblogs.com/Dreamer-1/p/6076440.html 最近一直在跟Oracle打交道,从最初的一脸懵逼到现在的略有所知,也 ...
- Oracle 优化器
http://blog.csdn.net/it_man/article/details/8185370一.优化器基本知识 Oracle在执行一个SQL之前,首先要分析一下语句的执行计划,然后再按执 ...
- [转]ORACLE优化器RBO与CBO的区别
RBO和CBO的基本概念 Oracle数据库中的优化器又叫查询优化器(Query Optimizer).它是SQL分析和执行的优化工具,它负责生成.制定SQL的执行计划.Oracle的优化器有两种,基 ...
- oracle执行计划之-表连接方式
转载自:http://blog.csdn.net/tianlesoftware/article/details/5826546 在多表联合查询的时候,如果我们查看它的执行计划,就会发现里面有多表之间的 ...
- oracle优化器使用(oracle11g)
一:优化器介绍 优化器(optimizer)是oracle数据库内置的一个核心子系统.优化器的目的是按照一定的判断原则来得到它认为的目标SQL在当前的情形下的最高效的执行路径,也就是为了得到目标SQL ...
- Oracle优化器
本文参照:https://www.cnblogs.com/Dreamer-1/p/6076440.html 读优化器之前建议先读: https://www.cnblogs.com/zhougongji ...
随机推荐
- 1.Go语言copy函数、sort排序、双向链表、list操作和双向循环链表
1.1.copy函数 通过copy函数可以把一个切片内容复制到另一个切片中 (1)把长切片拷贝到短切片中 package main import "fmt" func main() ...
- 利用模板生成html页面(NVelocity)
公司的网站需要有些新闻,每次的新闻格式都是一样的,而不想每次都查询操作,所以想把这些新闻的页面保存成静态的html,之后搜索了下就找到了这个模板引擎,当然其他的模板引擎可以的,例如:Razor,自己写 ...
- vue中使用vue-amap(高德地图)
因为项目要求调用高德地图,就按照官方文档按部就班的捣鼓,这一路上出了不少问题. 前言: vue-cli,node环境什么的自己安装设置推荐一个博客:https://blog.csdn.net/wula ...
- 自定义 EditText 样式
极力推荐文章:欢迎收藏 Android 干货分享 阅读五分钟,每日十点,和您一起终身学习,这里是程序员Android 本篇文章主要介绍 Android 开发中的部分知识点,通过阅读本篇文章,您将收获以 ...
- leetcode bug free
---不包含jiuzhang ladders中出现过的题.如出现多个方法,则最后一个方法是最优解. 目录: 1 String 2 Two pointers 3 Array 4 DFS &&am ...
- 循环while和for
1.循环语句的基本操作 #while循环使用,其中break是用来结束当前循环的 count = 0 while True: print(count) count += 1 if count == 3 ...
- intellij idea 2019 安装使用教程
一.安装 idea 2019.2 链接:https://pan.baidu.com/s/1acx_P23W463it9PGAYUIBw 提取码:4bky 双击运行idea.exe 点击Next ...
- 从0到1发布一个npm包
从0到1发布一个npm包 author: @TiffanysBear 最近在项目业务中有遇到一些问题,一些通用的方法或者封装的模块在PC.WAP甚至是APP中都需要使用,但是对于业务的PC.WAP.A ...
- 四、Ansible的Galaxy包管理器
一.什么是Ansible Galaxy? Ansible Galaxy是Ansible的第三方插件管理和安装工具,其实就是包管理软件.作用类似于Ubuntu的apt,Centos的yum,Python ...
- Delegate,Block,Notification, KVC,KVO,Target-Action
Target-Action: 目标-动作机制,所有的UIControl及子类都是这个机制:原理:在对象产生某个事件的特定时刻,给一个对象发送一个消息:类内部target去执行action方法 Dele ...