scrapy爬取迅雷电影天堂最新电影ed2k
前言
几天没用scrapy爬网站了,正好最近在刷电影,就想着把自己常用的一个电影分享网站给爬取下来保存到本地mongodb中
项目开始
第一步仍然是创建scrapy项目与spider文件
切换到工作目录两条命令依次输入
- scrapy startproject xunleidianying
- scrapy genspider xunleiBT https://www.xl720.com/thunder/years/2019
内容分析
打开目标网站(分类是2019年上映的电影),分析我们需要的数据
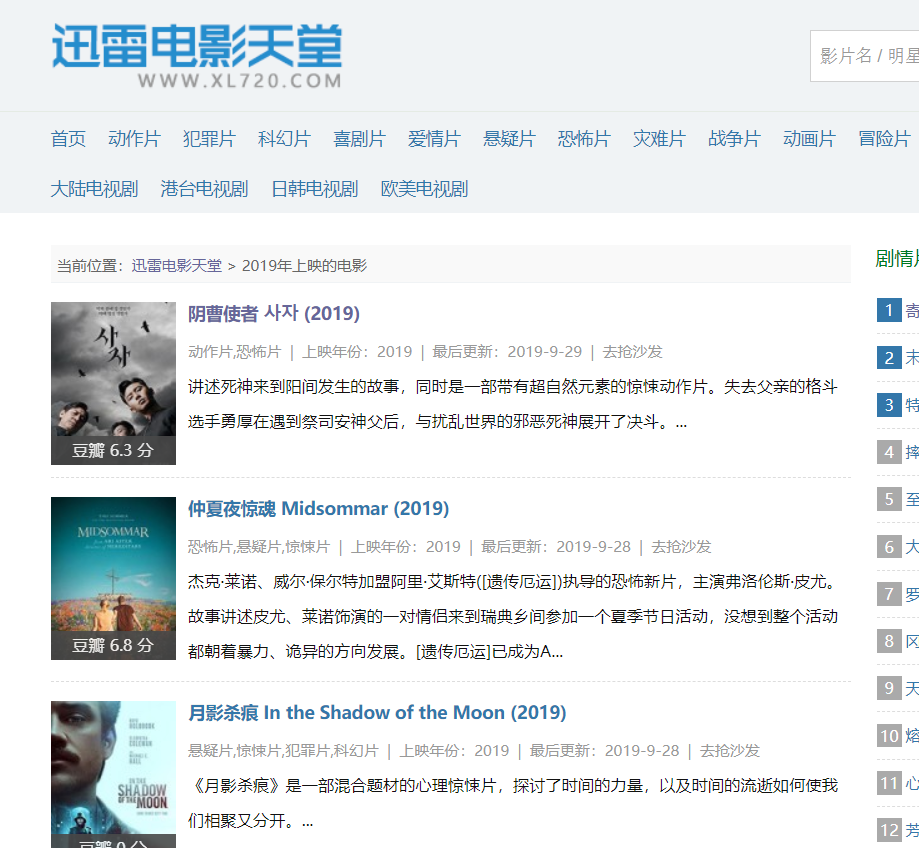
进入页面是列表的形式就像豆瓣电影一样,然后我们点进去具体页面看看
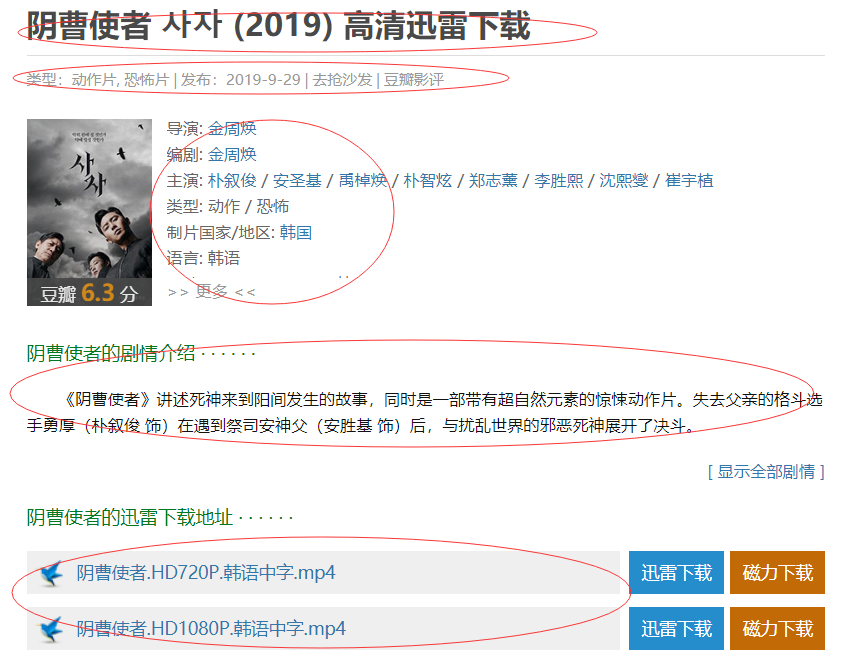
这个页面就是我们需要拿到的内容页面,我们来看我们需要哪些数据(某些数据从第一个页面就可以获得,但是下载地址必须到第二个页面)
- 电影名称
- 电影信息
- 电影内容剧情
- 电影下载地址
分析完成之后就可以首先编写 items.py文件
import scrapy class XunleidianyingItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
information = scrapy.Field()
content = scrapy.Field()
downloadurl = scrapy.Field()
pass
另外别忘了去settings.py中开启 ITEM_PIPELINES 选项
爬虫文件编写
老样子,为了方便测试我们的爬虫,首先编写一个main.py的文件方便IDE调用
main.py:
import scrapy.cmdline
scrapy.cmdline.execute('scrapy crawl xunleiBT'.split())
首先我们先测试直接向目标发送请求是否可以得到响应
爬虫文件 xunleiBT.py编写如下:
# -*- coding: utf-8 -*-
import scrapy class XunleibtSpider(scrapy.Spider):
name = 'xunleiBT'
allowed_domains = ['https://www.xl720.com/thunder/years/2019']
start_urls = ['https://www.xl720.com/thunder/years/2019/'] def parse(self, response):
print(response.text)
pass
运行 main.py 看看会出现什么
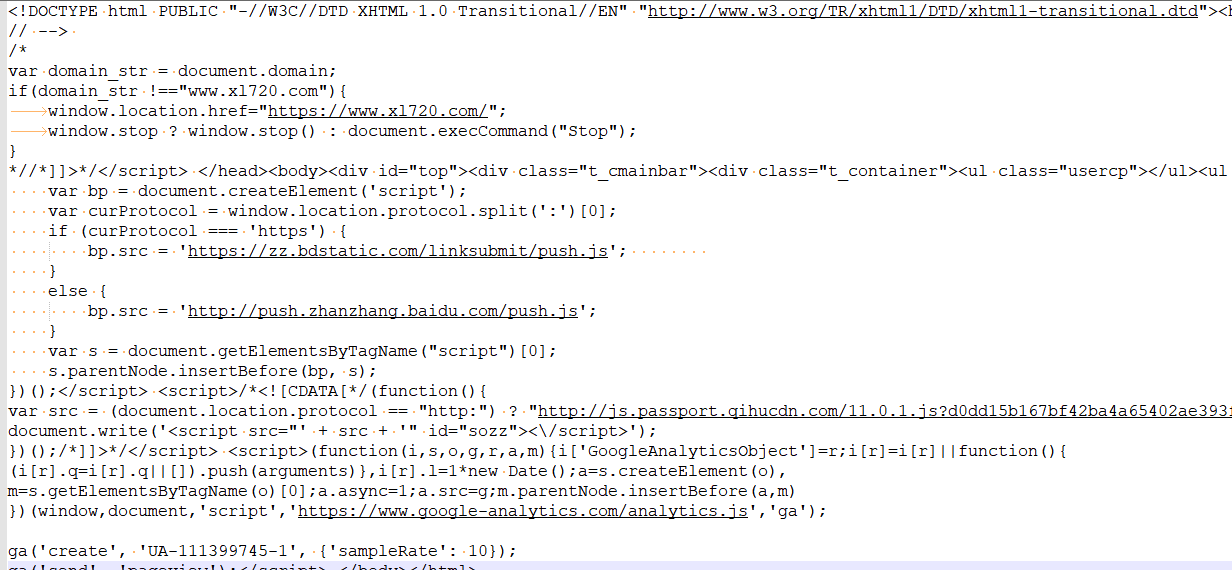
好的,发现直接返回正常的网页也就是我们要的网页,说明该网站没有反爬机制,这样我们就更容易爬取了
然后通过xpath定位页面元素,具体就不再赘述,之前的scarpy教程中都有 继续编写爬虫文件
# -*- coding: utf-8 -*-
import scrapy
#导入编写的 item
from xunleidianying.items import XunleidianyingItem class XunleibtSpider(scrapy.Spider):
name = 'xunleiBT'
allowed_domains = ['www.xl720.com']
start_urls = ['https://www.xl720.com/thunder/years/2019/'] def parse(self, response):
url_list = response.xpath('//h3//@href').getall()
for url in url_list:
yield scrapy.Request(url,callback=self.detail_page)
nextpage_link = response.xpath('//a[@class="nextpostslink"]/@href').get()
if nextpage_link:
yield scrapy.Request(nextpage_link, callback=self.parse) def detail_page(self,response):
# 切记item带括号
BT_item = XunleidianyingItem()
BT_item['name'] = response.xpath('//h1/text()').get()
BT_item['information'] = ''.join(response.xpath('//div[@id="info"]//text()').getall())
BT_item['content'] = response.xpath('//div[@id="link-report"]/text()').get()
BT_item['downloadurl'] = response.xpath('//div[@class="download-link"]/a/text() | //div[@class="download-link"]/a/@href').getall()
yield BT_item
ITEM爬取完成后该干什么?当然是入库保存了,编写pipelines.py文件进行入库保存
再次提醒别忘了去settings.py中开启 ITEM_PIPELINES 选项
pipelines.py文件代码如下:
import pymongo
#连接本地数据库
myclient = pymongo.MongoClient("mongodb://localhost:27017/")
#数据库名称
mydb = myclient["movie_BT"]
#数据表名称
mysheet = mydb["movie"] class XunleidianyingPipeline(object):
def process_item(self, item, spider):
data = dict(item)
mysheet.insert(data)
return item
再次运行main.py 等待运行完成后打开数据库查询
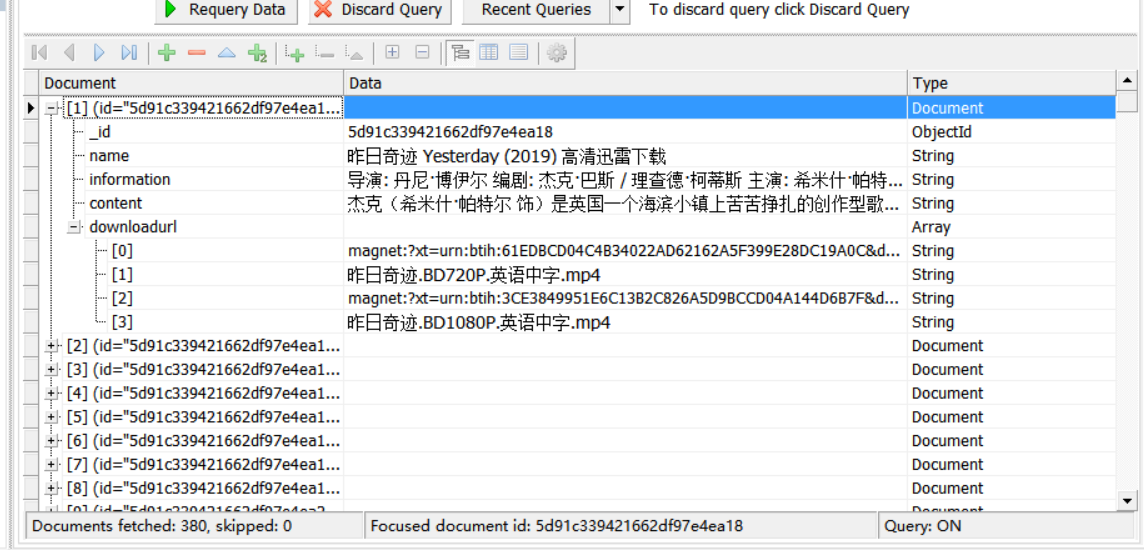
数据保存完成,这次我们一共导入了380个数据,可以愉快的查看电影了
scrapy爬取迅雷电影天堂最新电影ed2k的更多相关文章
- python利用requests和threading模块,实现多线程爬取电影天堂最新电影信息。
利用爬到的数据,基于Django搭建的一个最新电影信息网站: n1celll.xyz (用的花生壳动态域名解析,服务器在自己的电脑上,纯属自娱自乐哈.) 今天想利用所学知识来爬取电影天堂所有最新电影 ...
- scrapy爬取豆瓣电影top250
# -*- coding: utf-8 -*- # scrapy爬取豆瓣电影top250 import scrapy from douban.items import DoubanItem class ...
- Python爬虫爬取BT之家找电影资源
一.写在前面 最近看新闻说圣城家园(SCG)倒了,之前BT天堂倒了,暴风影音也不行了,可以说看个电影越来越费力,国内大厂如企鹅和爱奇艺最近也出现一些幺蛾子,虽然目前版权意识虽然越来越强,但是很多资源在 ...
- scrapy 动态网页处理——爬取鼠绘海贼王最新漫画
简介 scrapy是基于python的爬虫框架,易于学习与使用.本篇文章主要介绍如何使用scrapy爬取鼠绘漫画网海贼王最新一集的漫画. 源码参见:https://github.com/liudaol ...
- 以豌豆荚为例,用 Scrapy 爬取分类多级页面
本文转载自以下网站:以豌豆荚为例,用 Scrapy 爬取分类多级页面 https://www.makcyun.top/web_scraping_withpython17.html 需要学习的地方: 1 ...
- scrapy爬取海量数据并保存在MongoDB和MySQL数据库中
前言 一般我们都会将数据爬取下来保存在临时文件或者控制台直接输出,但对于超大规模数据的快速读写,高并发场景的访问,用数据库管理无疑是不二之选.首先简单描述一下MySQL和MongoDB的区别:MySQ ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- 小说免费看!python爬虫框架scrapy 爬取纵横网
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 风,又奈何 PS:如有需要Python学习资料的小伙伴可以加点击下方 ...
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
随机推荐
- js中尺寸类样式
js中尺寸类样式 一:鼠标尺寸类样式 都要事件对象的配合 Tip:注意与浏览器及元素尺寸分开,鼠标类尺寸样式都是X,Y,浏览器及元素的各项尺寸时Height,Width 1:检测相对于浏览器的位置:e ...
- Linux shell 内部命令与外部命令有什么区别以及怎么辨别
内部命令实际上是shell程序的一部分,其中包含的是一些比较简单的linux系统命令,这些命令由shell程序识别并在shell程序内部完成运行,通常在linux系统加载运行时shell就被加载并驻留 ...
- Delphi - Indy TIdHTTP方式创建程序外壳 - 实现可执行程序的自动升级
Delphi 实现可执行程序的自动升级 准备工作: 1:Delphi调用TIdHTTP方式开发程序,生成程序打包外壳 说明:程序工程命名为ERP_Update 界面布局如下: 代码实现如下: unit ...
- crontab使用方法
一.crontab基本用法 1.1 cron服务 cron是一个linux下 的定时执行工具,可以在无需人工干预的情况下运行作业. service crond start //启动服务 service ...
- unicode的编码与解码
- 1 PY环境与变量
一 环境与文件形式 1.环境搭建http://jingyan.baidu.com/article/eae07827f7f2d01fec5485f7.html 2. python 则进入交互模式 ex ...
- LeetCode - 字符串数字相乘与相加
43. 字符串相乘 给定两个以字符串形式表示的非负整数 num1 和 num2,返回 num1 和 num2 的乘积,它们的乘积也表示为字符串形式. 示例 1: 输入: num1 = "2& ...
- 详解JAVA字符串类型switch的底层原理
基础 我们现在使用的Java的版本,基本上是都支持String类型的.当然除了String类型,还有int.char.byte.short.enum等等也都是支持的.然而在其底部实现中,还是基于 整型 ...
- ubuntu命令行配置静态IP
(1)首先我们使用ifconfig命令查询一下网卡名称 提示:如果提示没有ifconfig命令,首先应该下载一个net-tools 仅需执行命令:apt install net-tools (2)编辑 ...
- java对象与json字符串的互相转换
java对象与json字符串的互相转换 1.采用 net.sf.json.JSONObject maven依赖包: <dependency> <groupId>net.sf.j ...