爬虫学习(二)--爬取360应用市场app信息
欢迎加入python学习交流群 667279387
爬虫学习
爬虫学习(一)—爬取电影天堂下载链接
爬虫学习(二)–爬取360应用市场app信息
代码环境:windows10, python 3.5
主要用的软件包:SQLAlchemy,re
初学爬虫,没有使用scrapy框架,而是自己简单打了一个框架。代码里面也没有考虑记录日志以及错误处理等方面的内容,只是能简单工作。如果需要可以在此源码的基础上面进行修改。源码下载地址在文章末尾。
1、分析网页源码
本次抓取主要抓取了app名字,下载次数,评分,开发公司,最新版本号,更新时间。
先打开一个具体的软件页面进行查看网页源码
http://zhushou.360.cn/detail/index/soft_id/77208下面是截取含有具体信息的两个网页源码的片段。
<h2 id="app-name"><span title="360手机卫士-一键连免费wifi">360手机卫士-一键连免费wi...</span><cite class="verify_tag"></cite><cite class="white_tag"></cite></h2>
<div class="pf"> <span class="s-1 js-votepanel">8.8<em>分</em></span>
<span class="s-2"><a href="#comment-list" id="comment-num"><span class="js-comments review-count-all" style="margin:0;">0</span>条评价</a></span>
<span class="s-3">下载:187373万次</span>
<span class="s-3">15.82M</span>
<td width="50%"><strong>作者:</strong>北京奇虎科技有限公司</td>
<td width="50%"><strong>更新时间:</strong>2017-09-13</td>
<td><strong>版本:</strong>7.7.4<!--versioncode:257--><!--updatetime:2017-09-13--></td>
<td><strong>系统:</strong>Android 4.0.3以上</td> <td colspan="2"><strong>语言:</strong>中文</td>
本次解析也没有xpath解析,而是直接用正则来匹配。下面是正则匹配时用到的代码。
r_name = re.compile(u"<title>(.*?)_360手机助手</title>", re.DOTALL)
r_download_num = re.compile(u'<span class="s-3">下载:(.*?)次</span>', re.DOTALL)
r_score = re.compile(u'<span class="s-1 js-votepanel">(.*?)<em>分</em>', re.DOTALL)
r_author = re.compile(u"<strong>作者:</strong>(.*?)</td>", re.DOTALL)
r_version = re.compile(u"<strong>版本:</strong>(.*?)<!--", re.DOTALL)
r_update_time = re.compile(u"<strong>更新时间:</strong>(.*?)</td>", re.DOTALL)
下面是解析页面的用法
m = r_name.search(html)
app_name = m.group(m.lastindex).strip()其他字段的解析基本类似。
2、设计数据库字段
这里是利用了SQLAlchemy来实现ORM。
class App360(BaseModel):
__tablename__ = 'app360'
id = Column(Integer, primary_key=True, autoincrement=True)
soft_id = Column(Integer, nullable=False)
name = Column(String(100), nullable=False)
author = Column(String(50), nullable=False)
download_num = Column(String(50), nullable=False)
score = Column(Float, nullable=False)
# comments_num = Column(Integer, nullable=False)
update_time = Column(DateTime, nullable=False)
version = Column(String(50))数据库管理的代码,主要实现了数据库的初始化,以及数据的插入和查询。
class DbManager(object):
def __init__(self, Dbstring):
self.engine = create_engine(Dbstring, echo=True)
self._dbSession = scoped_session(
sessionmaker(
autocommit=False,
autoflush=False,
bind=self.engine
)
)
def init_db(self):
BaseModel.metadata.create_all(self.engine)
def closeDB(self):
self._dbSession().close()
def getAppWithSoftId(self, soft_id):
db_item = self._dbSession().query(App360).filter(App360.soft_id == soft_id).first()
if db_item:
return db_item
else:
return None
def saveAppItem(self, app_object):
db_item = self._dbSession().query(App360).filter(App360.soft_id == app_object.soft_id).first()
if not db_item:
self._dbSession().add(app_object)
self._dbSession().commit()3、抓取页面
获取到一个页面里出来的所有app的soft_id
r_url = re.compile(u'<a sid="(.*?)" href=', re.DOTALL)
def get_onePage_SoftId(url):
res_html = do_request(url)
soft_ids = r_url.findall(res_html)
return soft_ids获取单个app的详细信息
def get_app_detail(soft_id):
db_item = db.getAppWithSoftId(soft_id)
if not db_item:
url = "http://zhushou.360.cn/detail/index/soft_id/" + str(soft_id)
app_html = do_request(url)
app_item = extract_details(app_html, soft_id)
db.saveAppItem(app_object=app_item)这里简单粗暴的用了多个循环来获取,实际考虑性能的话,此处应该优化 。后续有时间了再学习研究下怎么优化。
for url in start_urls:
for i in range(50):
url = "http://zhushou.360.cn"+url+"?page=%s"%i
ids = get_onePage_SoftId(url)
for id in ids:
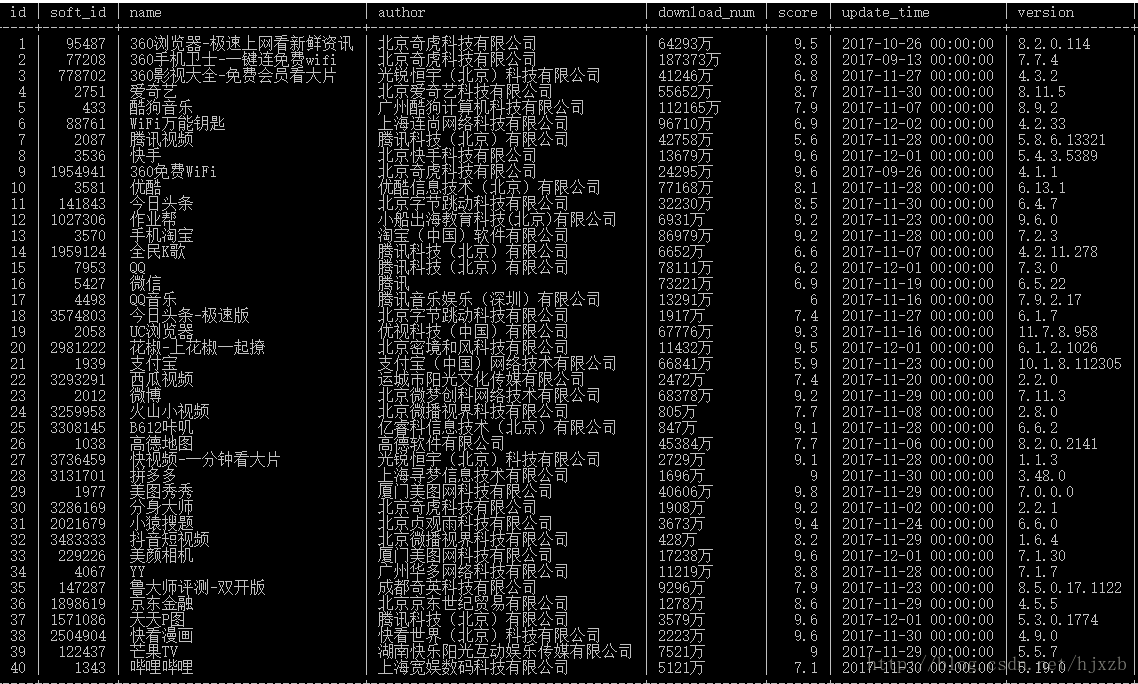
get_app_detail(id)获取到的数据截图如下:
源码下载地址:
链接:https://pan.baidu.com/s/1sl6xPEl 密码:k48g
————————————————————————————
后续经过改进,用了并行处理,快了很多,7000多条记录,大概10来分钟全部下载好了。
from utils import *
from concurrent import futures
from models import DbManager, App360
def get_app_detail(soft_id):
db_item = db.getAppWithSoftId(soft_id)
if not db_item:
url = "http://zhushou.360.cn/detail/index/soft_id/" + str(soft_id)
app_html = do_request(url)
app_item = extract_details(app_html, soft_id)
db.saveAppItem(app_object=app_item)
def get_onePage_SoftId(url):
res_html = do_request(url)
soft_ids = r_url.findall(res_html)
if soft_ids:
return soft_ids
else:
return []
if __name__=="__main__":
# 初始化数据库
DB_CONNECT_STRING = 'mysql+pymysql://root:hillstone@localhost:3306/app?charset=utf8'
db = DbManager(Dbstring=DB_CONNECT_STRING)
db.init_db()
for url in start_urls:
for i in range(50):
one_url = "http://zhushou.360.cn"+url+"?page=%s"%str(i)
#ids = get_onePage_SoftId(url)
executor = futures.ThreadPoolExecutor(max_workers=20)
results = executor.map(get_app_detail, get_onePage_SoftId(one_url))
更新后的代码地址:
https://github.com/Zhanben/python/tree/master/360Spider
如果源码对你有用,请评论下博客说声谢谢吧~
欢迎加入python学习交流群 667279387
爬虫学习(二)--爬取360应用市场app信息的更多相关文章
- Python爬虫学习(二) ——————爬取前程无忧招聘信息并写入excel
作为一名Pythoner,相信大家对Python的就业前景或多或少会有一些关注.索性我们就写一个爬虫去获取一些我们需要的信息,今天我们要爬取的是前程无忧!说干就干!进入到前程无忧的官网,输入关键字&q ...
- Python爬虫使用selenium爬取qq群的成员信息(全自动实现自动登陆)
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: python小爬虫 PS:如有需要Python学习资料的小伙伴可以 ...
- Python 爬虫入门(二)——爬取妹子图
Python 爬虫入门 听说你写代码没动力?本文就给你动力,爬取妹子图.如果这也没动力那就没救了. GitHub 地址: https://github.com/injetlee/Python/blob ...
- python爬虫学习(7) —— 爬取你的AC代码
上一篇文章中,我们介绍了python爬虫利器--requests,并且拿HDU做了小测试. 这篇文章,我们来爬取一下自己AC的代码. 1 确定ac代码对应的页面 如下图所示,我们一般情况可以通过该顺序 ...
- 爬虫学习--MOOC爬取豆瓣top250
scrapy框架 scrapy是一套基于Twisted的异步处理框架,是纯python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松实现一个爬虫,用来抓取网页内容或者各种图片. scrapy E ...
- python爬虫学习之爬取全国各省市县级城市邮政编码
实例需求:运用python语言在http://www.ip138.com/post/网站爬取全国各个省市县级城市的邮政编码,并且保存在excel文件中 实例环境:python3.7 requests库 ...
- python - 爬虫入门练习 爬取链家网二手房信息
import requests from bs4 import BeautifulSoup import sqlite3 conn = sqlite3.connect("test.db&qu ...
- [python爬虫] Selenium定向爬取虎扑篮球海量精美图片
前言: 作为一名从小就看篮球的球迷,会经常逛虎扑篮球及湿乎乎等论坛,在论坛里面会存在很多精美图片,包括NBA球队.CBA明星.花边新闻.球鞋美女等等,如果一张张右键另存为的话真是手都点疼了.作为程序员 ...
- 萌新学习Python爬取B站弹幕+R语言分词demo说明
代码地址如下:http://www.demodashi.com/demo/11578.html 一.写在前面 之前在简书首页看到了Python爬虫的介绍,于是就想着爬取B站弹幕并绘制词云,因此有了这样 ...
随机推荐
- go语言教程之浅谈数组和切片的异同
Hello ,各位小伙伴大家好,我是小栈君,上次分享我们讲到了Go语言关于项目工程结构的管理,本期的分享我们来讲解一下关于go语言的数组和切片的概念.用法和区别. 在go语言的程序开发过程中,我们避免 ...
- unittest使用数据驱动ddt
简介 ddt(data driven test)数据驱动测试:由外部数据集合来驱动测试用例,适用于测试方法不变,但需要大量变化的数据进行测试的情况,目的就是为了数据和测试步骤的分离 由于unittes ...
- Http帮助类(史上最详细帮助类)
分享一波干活,HttpHelper(支持设置获取Cookie和设置SSL证书) 代码 /// <summary> /// Http连接操作帮助类 /// </summar ...
- maven安装与在eclipse中配置
需要准备 eclipse maven压缩包 : http://maven.apache.org/download.cgi 1 解压maven压缩包 2 在系统变量中新建变量MAVEN_HOME,值为 ...
- 痞子衡嵌入式:串行EEPROM接口事实标准及SPI EEPROM简介
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是EEPROM接口标准及SPI EEPROM. 痞子衡之前写过一篇文章 <SLC Parallel NOR简介>,介绍过并行N ...
- k8s部署高可用Ingress
部署高可用Ingress 官网地址https://kubernetes.github.io/ingress-nginx/deploy/ 获取ingress的编排文件 wget https://raw. ...
- Cef 因系统时间不正常,导致页面访问空白问题
当我们的系统时间不正常,比如设置一个日期-1999年9月9日,会引发证书问题. 系统时间不正常-IE有概率能访问 触发NavigateError事件,异常代码INET_E_INVALID_CERTIF ...
- 通过阿里云的IOT平台控制ESP8266
通过阿里云的IOT平台控制ESP8266 #include <ESP8266WiFi.h> /* 依赖 PubSubClient 2.4.0 */ #include <PubSubC ...
- 领扣(LeetCode)找树左下角的值 个人题解
给定一个二叉树,在树的最后一行找到最左边的值. 示例 1: 输入: 2 / \ 1 3 输出: 1 示例 2: 输入: 1 / \ 2 3 / / \ 4 5 6 / 7 输出: 7 注意: 您可以假 ...
- Ubuntu 16.04 安装Maven3.3.9
1 下载地址 http://maven.apache.org/download.cgi 2 将下载到的apache-maven-3.3.9-bin.tar.gz文件上传到/temp目录下,然后切换到r ...