ElasticSearch Cardinality Aggregation聚合计算的误差
使用ES不久,今天发现生产环境数据异常,其使用的ES版本是2.1.2,其它版本也类似。通过使用ES的HTTP API进行查询,发现得到的数据跟javaClient API 查询得到的数据不一致,于是对代码逻辑以及ES查询工具产生了怀疑。通过查阅官方文档找到如下描述:
Precision controledit
This aggregation also supports the
precision_thresholdoption:The
precision_thresholdoption is specific to the current internal implementation of thecardinalityagg, which may change in the future{
"aggs" : {
"author_count" : {
"cardinality" : {
"field" : "author_hash",
"precision_threshold": 100}
}
}
}
The
precision_thresholdoptions allows to trade memory for accuracy, and defines a unique count below which counts are expected to be close to accurate. Above this value, counts might become a bit more fuzzy. The maximum supported value is 40000, thresholds above this number will have the same effect as a threshold of 40000. Default value depends on the number of parent aggregations that multiple create buckets (such as terms or histograms).Counts are approximateedit
Computing exact counts requires loading values into a hash set and returning its size. This doesn’t scale when working on high-cardinality sets and/or large values as the required memory usage and the need to communicate those per-shard sets between nodes would utilize too many resources of the cluster.
This
cardinalityaggregation is based on the HyperLogLog++ algorithm, which counts based on the hashes of the values with some interesting properties:
- configurable precision, which decides on how to trade memory for accuracy,
- excellent accuracy on low-cardinality sets,
- fixed memory usage: no matter if there are tens or billions of unique values, memory usage only depends on the configured precision.
For a precision threshold of
c, the implementation that we are using requires aboutc * 8bytes.The following chart shows how the error varies before and after the threshold:
For all 3 thresholds, counts have been accurate up to the configured threshold (although not guaranteed, this is likely to be the case). Please also note that even with a threshold as low as 100, the error remains under 5%, even when counting millions of items.
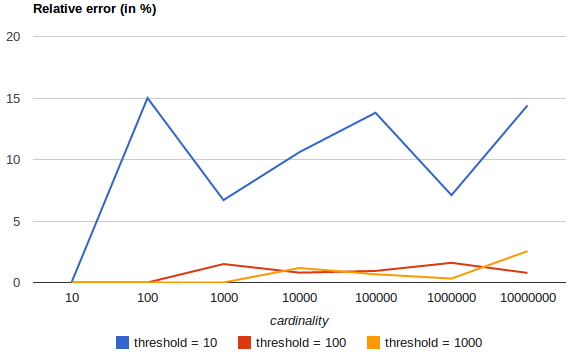
其意思就是:聚合查询存在误差,在5%范围之内,通过调整“precision_threshold”参数进行调整。
于是翻阅查询代码:加入如下部分问题得到解决。该参数在查询时未设置的情况下,默认值为3000。
private void buildSearchQueryForAgg(NativeSearchQueryBuilder nativeSearchQueryBuilder) {
// 设置聚合条件
TermsBuilder agg = AggregationBuilders.terms(aggreName).field(XXX.XXX).size(Integer.MAX_VALUE);
// 查询条件构建
BoolQueryBuilder packBoolQuery = QueryBuilders.boolQuery();
FilterAggregationBuilder packAgg = AggregationBuilders.filter(xxx).filter(packBoolQuery);
packAgg.subAggregation(AggregationBuilders.cardinality(xxx).field(ZZZZ.XXX).precisionThreshold(CARDINALITY_PRECISION_THRESHOLD));//指定精度值
agg.subAggregation(packAgg);
nativeSearchQueryBuilder.addAggregation(agg);
}
ElasticSearch Cardinality Aggregation聚合计算的误差的更多相关文章
- Elasticsearch:aggregation介绍
聚合(aggregation)功能集是整个Elasticsearch产品中最令人兴奋和有益的功能之一,主要是因为它提供了一个非常有吸引力对之前的facets的替代. 在本教程中,我们将解释Elasti ...
- Django Aggregation聚合 django orm 求平均、去重、总和等常用方法
Django Aggregation聚合 在当今根据需求而不断调整而成的应用程序中,通常不仅需要能依常规的字段,如字母顺序或创建日期,来对项目进行排序,还需要按其他某种动态数据对项目进行排序.Djng ...
- JS数字计算精度误差的解决方法
本篇文章主要是对javascript避免数字计算精度误差的方法进行了介绍,需要的朋友可以过来参考下,希望对大家有所帮助. 如果我问你 0.1 + 0.2 等于几?你可能会送我一个白眼,0.1 + 0. ...
- mssql sqlserver 对不同群组对象进行聚合计算的方法分享
摘要: 下文讲述通过一条sql语句,采用over关键字同时对不同类型进行分组的方法,如下所示: 实验环境:sql server 2008 R2 当有一张明细表,我们需同时按照不同的规则,计算平均.计数 ...
- 开发中使用mongoTemplate进行Aggregation聚合查询
笔记:使用mongo聚合查询(一开始根本没接触过mongo,一点一点慢慢的查资料完成了工作需求) 需求:在订单表中,根据buyerNick分组,统计每个buyerNick的电话.地址.支付总金额以及总 ...
- java使用elasticsearch分组进行聚合查询(group by)-项目中实际应用
java连接elasticsearch 进行聚合查询进行相应操作 一:对单个字段进行分组求和 1.表结构图片: 根据任务id分组,分别统计出每个任务id下有多少个文字标题 .SQL:select id ...
- 小试牛刀ElasticSearch大数据聚合统计
ElasticSearch相信有不少朋友都了解,即使没有了解过它那相信对ELK也有所认识E即是ElasticSearch.ElasticSearch最开始更多用于检索,作为一搜索的集群产品简单易用绝对 ...
- Django Aggregation聚合
在当今根据需求而不断调整而成的应用程序中,通常不仅需要能依常规的字段,如字母顺序或创建日期,来对项目进行排序,还需要按其他某种动态数据对项目进行排序.Djngo聚合就能满足这些要求. 以下面的Mode ...
- MDX Step by Step 读书笔记(七) - Performing Aggregation 聚合函数之 Sum, Aggregate, Avg
开篇介绍 SSAS 分析服务中记录了大量的聚合值,这些聚合值在 Cube 中实际上指的就是度量值.一个给定的度量值可能聚合了来自事实表中上千上万甚至百万条数据,因此在设计阶段我们所能看到的度量实际上就 ...
随机推荐
- Atcoder C - Closed Rooms(思维+bfs)
题目链接:http://agc014.contest.atcoder.jp/tasks/agc014_c 题意:略. 题解:第一遍bfs找到所有可以走的点并标记步数,看一下最少几步到达所有没锁的点,然 ...
- codeforces E. Phone Talks(dp)
题目链接:http://codeforces.com/contest/158/problem/E 题意:给出一些电话,有打进来的时间和持续的时间,如果人在打电话,那么新打进来的电话入队,如果人没有打电 ...
- 第10讲-Java集合框架
第10讲 Java集合框架 1.知识点 1.1.课程回顾 1.2.本章重点 1.2.1 List 1.2.2 Set 1.2.3 Map 2.具体内容 2.1.Java集合框架 2.1.1 为什么需要 ...
- 【Spring】 IOC Base
一.关于容器 1. ApplicationContext和BeanFactory 2. 配置文件 XML方式 Java-configuration 方式 @Configuration 3. 初始化容器 ...
- python实现持久化存储,操作表格,时间戳
import xlrd,xlwt,pickle,time,datetime book = xlrd.open_workbook("练习.xlsx") sheet1 = book.s ...
- Golang 数组 切片 字典 基本知识点
数组 数组的声明 var arrayName [arraySize]dataType eg: var array1 [5]int 在声明数组时,必须指定数组名,数组长度和数组元素的类型. 数组的初始化 ...
- Docker常用命令小记
除了基本的docker pull.docker image.docker ps,还有一些命令及参数也很重要,在此记录下来避免遗忘. 环境信息 以下是本次操作的环境: 操作系统:CentOS Linux ...
- Java 集合转换(数组、List、Set、Map相互转换)
package com.example.test; import java.util.ArrayList; import java.util.Arrays; import java.util.Hash ...
- Mysql学习笔记整理之引擎
mysql的引擎: myisam引擎 Mysql 5.5之前默认的存储引擎 数据.索引分别存储 (数据物理磁盘---索引物理磁盘) .MYD 存储数据 表级索 ...
- php将图片存储在阿里云oss存储上
创建两个方法 1.上传方法 use OSS\OssClient; use think\Config; use OSS\Core\OssException; /** * 存储文件 * * @param ...