spark的wordcount
在开发环境下实现第一个程序wordcount
1、下载和配置scala,注意不要下载2.13,在spark-core明确支持scala2.13前,使用2.12或者2.11比较好。
https://www.scala-lang.org/download/
2、windows环境下的scala配置,可选
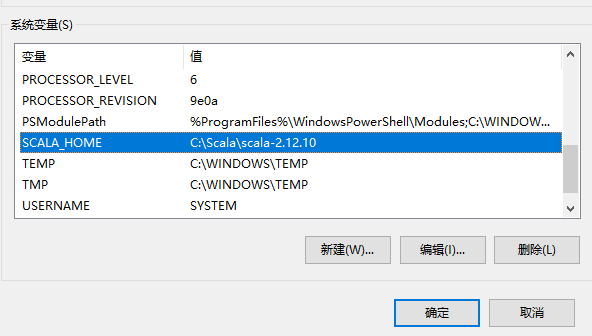

3、开发工具IDEA环境设置,全局环境添加scala的sdk,注意scala的源码要手动下载和添加
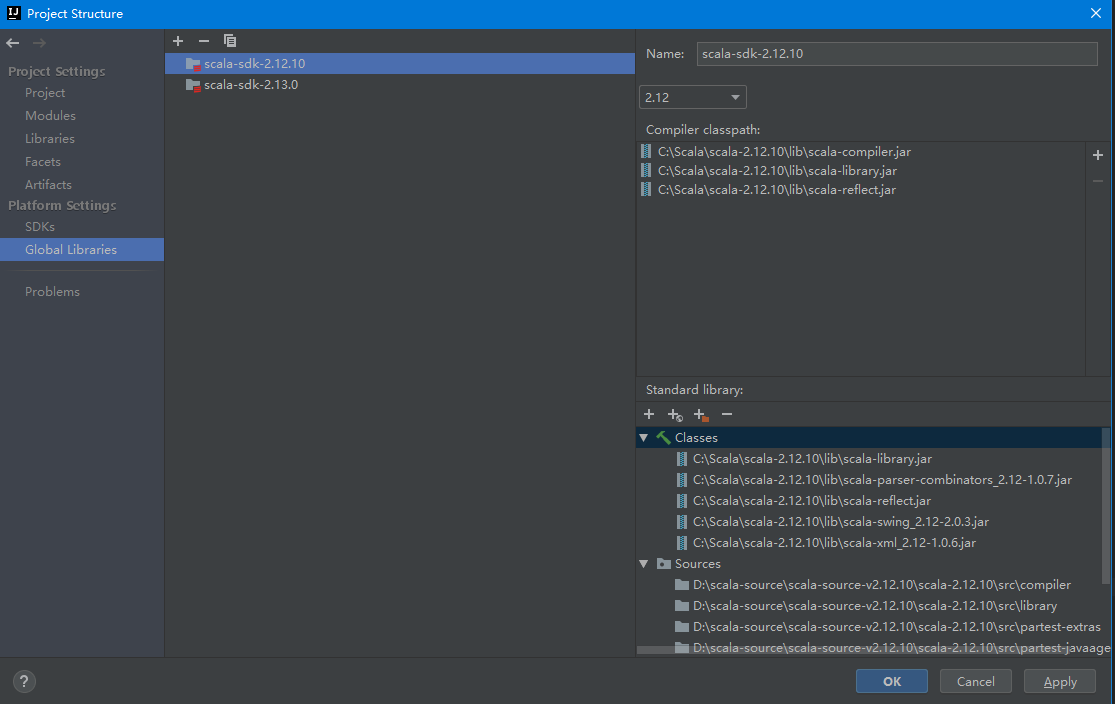
4、在IDEA中新建MAVEN项目,添加scala框架支持

5、在MAVEN工程添加spark-core依赖,注意根据自己需要选择对应的版本,版本不对很可能会出现运行期异常。
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.4</version>
</dependency>
</dependencies>
6、wordcount代码
在项目根目录(与src平级)中新建一个input目录,里面放入需要统计词频的文本文件
package com.home.spark import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext} object WordCount {
def main(args: Array[String]): Unit = {
//获取环境
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkWordCount") //获取上下文
val sc: SparkContext = new SparkContext(conf) //读取每一行
val lines: RDD[String] = sc.textFile("input") //扁平化,将每行数据拆分成单个词(自定义业务逻辑)
val words: RDD[String] = lines.flatMap(_.split(" ")) //结构转换,对每个词获得初始词频
val wordToOne: RDD[(String, Int)] = words.map((_,1)) //词频计数
val wordToSum: RDD[(String, Int)] = wordToOne.reduceByKey(_+_) //按词频数量降序排序
val wordToSorted: RDD[(String, Int)] = wordToSum.sortBy(_._2,false) //数据输出
val result: Array[(String, Int)] = wordToSorted.collect() //打印
result.foreach(println) //关闭上下文
sc.stop()
}
}
spark的wordcount的更多相关文章
- [转] 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? [sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需 ...
- Spark 实现wordcount
配置完spark之后,使用spark实现wordcount,这一部分完全参考<深入理解Spark:核心思想与源码分析> 依然使用hadoop wordcountTest的那几个txt文件 ...
- 用SBT编译Spark的WordCount程序
问题导读: 1.什么是sbt? 2.sbt项目环境如何建立? 3.如何使用sbt编译打包scala? sbt介绍 sbt是一个代码编译工具,是scala界的mvn,可以编译scala,java等,需要 ...
- 编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本]
编写Spark的WordCount程序并提交到集群运行[含scala和java两个版本] 1. 开发环境 Jdk 1.7.0_72 Maven 3.2.1 Scala 2.10.6 Spark 1.6 ...
- spark 例子wordcount topk
spark 例子wordcount topk 例子描述: [单词计算wordcount ] [词频排序topk] 单词计算在代码方便很简单,基本大体就三个步骤 拆分字符串 以需要进行记数的单位为K,自 ...
- 1.spark的wordcount解析
一.Eclipse(scala IDE)开发local和cluster (一). 配置开发环境 要在本地安装好java和scala. 由于spark1.6需要scala 2.10.X版本的.推荐 2 ...
- .Net for Spark 实现 WordCount 应用及调试入坑详解
.Net for Spark 实现WordCount应用及调试入坑详解 1. 概述 iNeuOS云端操作系统现在具备物联网.视图业务建模.机器学习的功能,但是缺少一个计算平台产品.最近在调研使用 ...
- Spark版wordcount,并根据词频进行排序
import org.apache.spark.{SparkConf, SparkContext}/** * Created by loushsh on 2017/10/9. */object Wor ...
- Spark开发wordcount程序
1.java版本(spark-2.1.0) package chavin.king; import org.apache.spark.api.java.JavaSparkContext; import ...
- 在IDEA中编写Spark的WordCount程序
1:spark shell仅在测试和验证我们的程序时使用的较多,在生产环境中,通常会在IDE中编制程序,然后打成jar包,然后提交到集群,最常用的是创建一个Maven项目,利用Maven来管理jar包 ...
随机推荐
- Dynamics 365 Online通过OAuth 2 Client Credential授权(Server-to-Server Authentication)后调用Web API
微软动态CRM专家罗勇 ,回复332或者20190505可方便获取本文,同时可以在第一间得到我发布的最新博文信息,follow me! 本文很多内容来自 John Towgood 撰写的Dynamic ...
- C#后台架构师成长之路-高阶知识体系核心
了解了这些东西,熟悉了运用基本都是高工级别的了,其他修修补补就行了.... 1.三种预定义特性:attributeUsage.Conditional.obsolete,允许创建自定义特性,派生自Sys ...
- 使用 TSPITR 恢复删除的表空间的步骤 (Doc ID 1277795.1)
Steps To Recover A Dropped Tablespace Using TSPITR (Doc ID 1277795.1) APPLIES TO: Oracle Database - ...
- django之ORM字段及参数
目录 ORM字段及参数 orm常用字段 字段合集 自定义char字段 字段参数 外键字段的参数 ORM字段及参数 orm常用字段 字段名 说明 AutoField 如果自己没有定义主键id,djang ...
- Django—开发具体流程
1.创建Django项目 [root@localhost ~]# django-admin startproject 项目名 [root@localhost ~]# django-admin star ...
- Java之匿名对象
匿名对象概念 创建对象时,只有创建对象的语句,却没有把对象地址值赋值给某个变量.虽然是创建对象的简化写法,但是应用场景非常有限.匿名对象 :没有变量名的对象. 格式: new 类名(参数列表): // ...
- NOIP 2016 组合数问题
洛谷 P2822 组合数问题 洛谷传送门 JDOJ 3139: [NOIP2016]组合数问题 D2 T1 JDOJ传送门 Description 组合数Cnm表示的是从n个物品中选出m个物品的方案数 ...
- rsync的简介及使用
1.rsync的基础概述 1.什么是备份 相当于给源文件增加一个副本,但是备份只会备份当前状态的数据,当你在写数据是,不会备份新写入的数据,除非自己手动在备份一次. 2.为什么要做备份 1.需要备份一 ...
- Net中的并发锁
object _lock 锁的概念,这里不做详细阐述.先从最经典的应用场景来说,单例模式在不考虑静态构造函数实现的方式下,用锁实现是必须的.比如: public class Singleton { p ...
- Mybatis关联查询之三
MyBatis的关联查询之自关联 自关联 一.entity实体类 public class City { private Integer cid; private String cname; priv ...