Kafka Network层解析,还是有人把它说清楚了
我们知道kafka是基于TCP连接的。其并没有像很多中间件使用netty作为TCP服务器。而是自己基于Java NIO写了一套。
几个重要类
先看下Kafka Client的网络层架构。
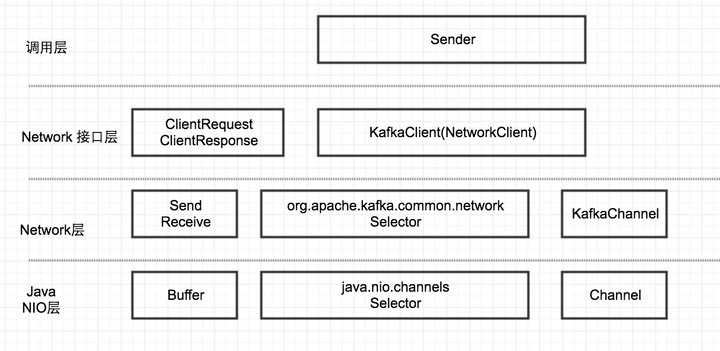
本文主要分析的是Network层。
Network层有两个重要的类:Selector和KafkaChannel。
这两个类和Java NIO层的java.nio.channels.Selector和Channel有点类似。
Selector几个关键字段如下 // jdk nio中的Selector
java.nio.channels.Selector nioSelector;
// 记录当前Selector的所有连接信息
Map<String, KafkaChannel> channels;
// 已发送完成的请求
List<Send> completedSends;
// 已收到的请求
List<NetworkReceive> completedReceives;
// 还没有完全收到的请求,对上层不可见
Map<KafkaChannel, Deque<NetworkReceive>> stagedReceives;
// 作为client端,调用connect连接远端时返回true的连接
Set<SelectionKey> immediatelyConnectedKeys;
// 已经完成的连接
List<String> connected;
// 一次读取的最大大小
int maxReceiveSize;
从网络层来看kafka是分为client端(producer和consumer,broker作为从时也是client)和server端(broker)的。本文将分析client端是如何建立连接,以及收发数据的。server也是依靠Selector和KafkaChannel进行网络传输。在Network层两端的区别并不大。
建立连接
kafka的client端启动时会调用Selector#connect(下文中如无特殊注明,均指org.apache.kafka.common.network.Selector)方法建立连接。
public void connect(String id, InetSocketAddress address, int sendBufferSize, int receiveBufferSize) throws IOException {
if (this.channels.containsKey(id))
throw new IllegalStateException("There is already a connection for id " + id);
// 创建一个SocketChannel
SocketChannel socketChannel = SocketChannel.open();
// 设置为非阻塞模式
socketChannel.configureBlocking(false);
// 创建socket并设置相关属性
Socket socket = socketChannel.socket();
socket.setKeepAlive(true);
if (sendBufferSize != Selectable.USE_DEFAULT_BUFFER_SIZE)
socket.setSendBufferSize(sendBufferSize);
if (receiveBufferSize != Selectable.USE_DEFAULT_BUFFER_SIZE)
socket.setReceiveBufferSize(receiveBufferSize);
socket.setTcpNoDelay(true);
boolean connected;
try {
// 调用SocketChannel的connect方法,该方法会向远端发起tcp建连请求
// 因为是非阻塞的,所以该方法返回时,连接不一定已经建立好(即完成3次握手)。连接如果已经建立好则返回true,否则返回false。一般来说server和client在一台机器上,该方法可能返回true。
connected = socketChannel.connect(address);
} catch (UnresolvedAddressException e) {
socketChannel.close();
throw new IOException("Can't resolve address: " + address, e);
} catch (IOException e) {
socketChannel.close();
throw e;
}
// 对CONNECT事件进行注册
SelectionKey key = socketChannel.register(nioSelector, SelectionKey.OP_CONNECT);
KafkaChannel channel;
try {
// 构造一个KafkaChannel
channel = channelBuilder.buildChannel(id, key, maxReceiveSize);
} catch (Exception e) {
...
}
// 将kafkachannel绑定到SelectionKey上
key.attach(channel);
// 放入到map中,id是远端服务器的名称
this.channels.put(id, channel);
// connectct为true代表该连接不会再触发CONNECT事件,所以这里要单独处理
if (connected) {
// OP_CONNECT won't trigger for immediately connected channels
log.debug("Immediately connected to node {}", channel.id());
// 加入到一个单独的集合中
immediatelyConnectedKeys.add(key);
// 取消对该连接的CONNECT事件的监听
key.interestOps(0);
}
}
这里的流程和标准的NIO流程差不多,需要单独说下的是socketChannel#connect方法返回true的场景,该方法的注释中有提到
* <p> If this channel is in non-blocking mode then an invocation of this
* method initiates a non-blocking connection operation. If the connection
* is established immediately, as can happen with a local connection, then
* this method returns <tt>true</tt>. Otherwise this method returns
* <tt>false</tt> and the connection operation must later be completed by
* invoking the {@link #finishConnect finishConnect} method.
也就是说在非阻塞模式下,对于local connection,连接可能在马上就建立好了,那该方法会返回true,对于这种情况,不会再触发之后的connect事件。因此kafka用一个单独的集合immediatelyConnectedKeys将这些特殊的连接记录下来。在接下来的步骤会进行特殊处理。
之后会调用poll方法对网络事件监听:
public void poll(long timeout) throws IOException {
...
// select方法是对java.nio.channels.Selector#select的一个简单封装
int readyKeys = select(timeout);
...
// 如果有就绪的事件或者immediatelyConnectedKeys非空
if (readyKeys > 0 || !immediatelyConnectedKeys.isEmpty()) {
// 对已就绪的事件进行处理,第2个参数为false
pollSelectionKeys(this.nioSelector.selectedKeys(), false, endSelect);
// 对immediatelyConnectedKeys进行处理。第2个参数为true
pollSelectionKeys(immediatelyConnectedKeys, true, endSelect);
}
addToCompletedReceives();
...
}
private void pollSelectionKeys(Iterable<SelectionKey> selectionKeys,
boolean isImmediatelyConnected,
long currentTimeNanos) {
Iterator<SelectionKey> iterator = selectionKeys.iterator();
// 遍历集合
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
// 移除当前元素,要不然下次poll又会处理一遍
iterator.remove();
// 得到connect时创建的KafkaChannel
KafkaChannel channel = channel(key);
...
try {
// 如果当前处理的是immediatelyConnectedKeys集合的元素或处理的是CONNECT事件
if (isImmediatelyConnected || key.isConnectable()) {
// finishconnect中会增加READ事件的监听
if (channel.finishConnect()) {
this.connected.add(channel.id());
this.sensors.connectionCreated.record();
...
} else
continue;
}
// 对于ssl的连接还有些额外的步骤
if (channel.isConnected() && !channel.ready())
channel.prepare();
// 如果是READ事件
if (channel.ready() && key.isReadable() && !hasStagedReceive(channel)) {
NetworkReceive networkReceive;
while ((networkReceive = channel.read()) != null)
addToStagedReceives(channel, networkReceive);
}
// 如果是WRITE事件
if (channel.ready() && key.isWritable()) {
Send send = channel.write();
if (send != null) {
this.completedSends.add(send);
this.sensors.recordBytesSent(channel.id(), send.size());
}
}
// 如果连接失效
if (!key.isValid())
close(channel, true);
} catch (Exception e) {
String desc = channel.socketDescription();
if (e instanceof IOException)
log.debug("Connection with {} disconnected", desc, e);
else
log.warn("Unexpected error from {}; closing connection", desc, e);
close(channel, true);
} finally {
maybeRecordTimePerConnection(channel, channelStartTimeNanos);
}
}
}
因为immediatelyConnectedKeys中的连接不会触发CONNNECT事件,所以在poll时会单独对immediatelyConnectedKeys的channel调用finishConnect方法。在明文传输模式下该方法会调用到PlaintextTransportLayer#finishConnect,其实现如下:
public boolean finishConnect() throws IOException {
// 返回true代表已经连接好了
boolean connected = socketChannel.finishConnect();
if (connected)
// 取消监听CONNECt事件,增加READ事件的监听
key.interestOps(key.interestOps() & ~SelectionKey.OP_CONNECT | SelectionKey.OP_READ);
return connected;
}
关于immediatelyConnectedKeys更详细的内容可以看看这里。
发送数据
kafka发送数据分为两个步骤:
1.调用Selector#send将要发送的数据保存在对应的KafkaChannel中,该方法并没有进行真正的网络IO。
// Selector#send
public void send(Send send) {
String connectionId = send.destination();
// 如果所在的连接正在关闭中,则加入到失败集合failedSends中
if (closingChannels.containsKey(connectionId))
this.failedSends.add(connectionId);
else {
KafkaChannel channel = channelOrFail(connectionId, false);
try {
channel.setSend(send);
} catch (CancelledKeyException e) {
this.failedSends.add(connectionId);
close(channel, false);
}
}
} //KafkaChannel#setSend
public void setSend(Send send) {
// 如果还有数据没有发送出去则报错
if (this.send != null)
throw new IllegalStateException("Attempt to begin a send operation with prior send operation still in progress.");
// 保存下来
this.send = send;
// 添加对WRITE事件的监听
this.transportLayer.addInterestOps(SelectionKey.OP_WRITE);
}
调用Selector#poll,在第一步中已经对该channel注册了WRITE事件的监听,所以在当channel可写时,会调用到pollSelectionKeys将数据真正的发送出去。
private void pollSelectionKeys(Iterable<SelectionKey> selectionKeys,
boolean isImmediatelyConnected,
long currentTimeNanos) {
Iterator<SelectionKey> iterator = selectionKeys.iterator();
// 遍历集合
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
// 移除当前元素,要不然下次poll又会处理一遍
iterator.remove();
// 得到connect时创建的KafkaChannel
KafkaChannel channel = channel(key);
... try {
... // 如果是WRITE事件
if (channel.ready() && key.isWritable()) {
// 真正的网络写
Send send = channel.write();
// 一个Send对象可能会被拆成几次发送,write非空代表一个send发送完成
if (send != null) {
// completedSends代表已发送完成的集合
this.completedSends.add(send);
this.sensors.recordBytesSent(channel.id(), send.size());
}
}
...
} catch (Exception e) {
...
} finally {
maybeRecordTimePerConnection(channel, channelStartTimeNanos);
}
}
}
当可写时,会调用KafkaChannel#write方法,该方法中会进行真正的网络IO:
public Send write() throws IOException {
Send result = null;
if (send != null && send(send)) {
result = send;
send = null;
}
return result;
}
private boolean send(Send send) throws IOException {
// 最终调用SocketChannel#write进行真正的写
send.writeTo(transportLayer);
if (send.completed())
// 如果写完了,则移除对WRITE事件的监听
transportLayer.removeInterestOps(SelectionKey.OP_WRITE);
return send.completed();
}
接收数据
如果远端有发送数据过来,那调用poll方法时,会对接收到的数据进行处理。
public void poll(long timeout) throws IOException {
...
// select方法是对java.nio.channels.Selector#select的一个简单封装
int readyKeys = select(timeout);
...
// 如果有就绪的事件或者immediatelyConnectedKeys非空
if (readyKeys > 0 || !immediatelyConnectedKeys.isEmpty()) {
// 对已就绪的事件进行处理,第2个参数为false
pollSelectionKeys(this.nioSelector.selectedKeys(), false, endSelect);
// 对immediatelyConnectedKeys进行处理。第2个参数为true
pollSelectionKeys(immediatelyConnectedKeys, true, endSelect);
}
addToCompletedReceives();
...
}
private void pollSelectionKeys(Iterable<SelectionKey> selectionKeys,
boolean isImmediatelyConnected,
long currentTimeNanos) {
Iterator<SelectionKey> iterator = selectionKeys.iterator();
// 遍历集合
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
// 移除当前元素,要不然下次poll又会处理一遍
iterator.remove();
// 得到connect时创建的KafkaChannel
KafkaChannel channel = channel(key);
...
try {
...
// 如果是READ事件
if (channel.ready() && key.isReadable() && !hasStagedReceive(channel)) {
NetworkReceive networkReceive;
// read方法会从网络中读取数据,但可能一次只能读取一个req的部分数据。只有读到一个完整的req的情况下,该方法才返回非null
while ((networkReceive = channel.read()) != null)
// 将读到的请求存在stagedReceives中
addToStagedReceives(channel, networkReceive);
}
...
} catch (Exception e) {
...
} finally {
maybeRecordTimePerConnection(channel, channelStartTimeNanos);
}
}
}
private void addToStagedReceives(KafkaChannel channel, NetworkReceive receive) {
if (!stagedReceives.containsKey(channel))
stagedReceives.put(channel, new ArrayDeque<NetworkReceive>());
Deque<NetworkReceive> deque = stagedReceives.get(channel);
deque.add(receive);
}
在之后的addToCompletedReceives方法中会对该集合进行处理。
private void addToCompletedReceives() {
if (!this.stagedReceives.isEmpty()) {
Iterator<Map.Entry<KafkaChannel, Deque<NetworkReceive>>> iter = this.stagedReceives.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry<KafkaChannel, Deque<NetworkReceive>> entry = iter.next();
KafkaChannel channel = entry.getKey();
// 对于client端来说该isMute返回为false,server端则依靠该方法保证消息的顺序
if (!channel.isMute()) {
Deque<NetworkReceive> deque = entry.getValue();
addToCompletedReceives(channel, deque);
if (deque.isEmpty())
iter.remove();
}
}
}
}
private void addToCompletedReceives(KafkaChannel channel, Deque<NetworkReceive> stagedDeque) {
// 将每个channel的第一个NetworkReceive加入到completedReceives
NetworkReceive networkReceive = stagedDeque.poll();
this.completedReceives.add(networkReceive);
this.sensors.recordBytesReceived(channel.id(), networkReceive.payload().limit());
}
读出数据后,会先放到stagedReceives集合中,然后在addToCompletedReceives方法中对于每个channel都会从stagedReceives取出一个NetworkReceive(如果有的话),放入到completedReceives中。
这样做的原因有两点:
- 对于SSL的连接来说,其数据内容是加密的,所以不能精准的确定本次需要读取的数据大小,只能尽可能的多读,这样会导致可能会比请求的数据读的要多。那如果该channel之后没有数据可以读,会导致多读的数据将不会被处理。
- kafka需要确保一个channel上request被处理的顺序是其发送的顺序。因此对于每个channel而言,每次poll上层最多只能看见一个请求,当该请求处理完成之后,再处理其他的请求。在sever端,每次poll后都会将该channel给
mute掉,即不再从该channel上读取数据。当处理完成之后,才将该channelunmute,即之后可以从该socket上读取数据。而client端则是通过InFlightRequests#canSendMore控制。
代码中关于这段逻辑的注释如下:
/* In the "Plaintext" setting, we are using socketChannel to read & write to the network. But for the "SSL" setting,
* we encrypt the data before we use socketChannel to write data to the network, and decrypt before we return the responses.
* This requires additional buffers to be maintained as we are reading from network, since the data on the wire is encrypted
* we won't be able to read exact no.of bytes as kafka protocol requires. We read as many bytes as we can, up to SSLEngine's
* application buffer size. This means we might be reading additional bytes than the requested size.
* If there is no further data to read from socketChannel selector won't invoke that channel and we've have additional bytes
* in the buffer. To overcome this issue we added "stagedReceives" map which contains per-channel deque. When we are
* reading a channel we read as many responses as we can and store them into "stagedReceives" and pop one response during
* the poll to add the completedReceives. If there are any active channels in the "stagedReceives" we set "timeout" to 0
* and pop response and add to the completedReceives. * Atmost one entry is added to "completedReceives" for a channel in each poll. This is necessary to guarantee that
* requests from a channel are processed on the broker in the order they are sent. Since outstanding requests added
* by SocketServer to the request queue may be processed by different request handler threads, requests on each
* channel must be processed one-at-a-time to guarantee ordering.
*/
End
本文分析了kafka network层的实现,在阅读kafka源码时,如果不把network层搞清楚会比较迷,比如req/resp的顺序保障机制、真正进行网络IO的不是send方法等等。
本人免费整理了Java高级资料,涵盖了Java、Redis、MongoDB、MySQL、Zookeeper、Spring Cloud、Dubbo高并发分布式等教程,一共30G,需要自己领取。
传送门:https://mp.weixin.qq.com/s/JzddfH-7yNudmkjT0IRL8Q
Kafka Network层解析,还是有人把它说清楚了的更多相关文章
- slice层解析
如果说之前的Concat是将多个bottom合并成一个top的话,那么这篇博客的slice层则完全相反,是把一个bottom分解成多个top,这带来了一个问题,为什么要这么做呢?为什么要把一个低层的切 ...
- kafka.network.AbstractServerThread中的线程协作机制
这个虚类是kafka.network.Acceptor和kafka.network.Processor的父类,提供了一个抽象的Sever线程. 它的有趣之处在于为子类的启动和停止提供了线程间的协作机制 ...
- kafka Network
Kafka network Processor SocketServer.Processor override def run() { startupComplete() try { while (i ...
- Kafka设计解析(四)Kafka Consumer设计解析
转载自 技术世界,原文链接 Kafka设计解析(四)- Kafka Consumer设计解析 目录 一.High Level Consumer 1. Consumer Group 2. High Le ...
- json两层解析
public class Demo { public static void main(String[] args) { try { // 创建连接 服务器的连接地址 URL url = new UR ...
- Caffe_Scale层解析
Caffe Scale层解析 前段时间做了caffe的batchnormalization层的解析,由于整体的BN层实现在Caffe是分段实现的,因此今天抽时间总结下Scale层次,也会后续两个层做合 ...
- ASP.NET SignalR2持久连接层解析
越是到年底越是感觉浑身无力,看着啥也不想动,只期盼着年终奖的到来以此来给自己打一针强心剂.估摸着大多数人都跟我一样犯着这样浑身无力的病,感觉今年算是没挣到啥钱,但是话也不能这么说,搞得好像去年挣到钱了 ...
- Euclideanloss_layer层解析
这里说一下euclidean_loss_layer.cpp关于该欧式loss层的解析,代码如下: #include <vector> #include "caffe/layers ...
- Kafka工作原理解析以及主要配置详解
Kafka工作原理解析以及主要配置详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 无论是是Kafka集群,还是producer和consumer都依赖于Zookeeper集群保 ...
随机推荐
- Java生鲜电商平台-SpringCloud微服务架构高并发参数优化实战
Java生鲜电商平台-SpringCloud微服务架构高并发参数优化实战 一.写在前面 在Java生鲜电商平台平台中相信不少朋友都在自己公司使用Spring Cloud框架来构建微服务架构,毕竟现在这 ...
- 自定义栈Stack 和 队列Queue
自定义栈 接口 package com.test.custom; public interface IStack<E> { E pop(); void push(E e); E peek( ...
- log4cxx日志库在Windows+VS2017上的编译使用
项目中用到了log4cxx,但是Debug版本运行时老是提示找不到Properities::setProperty?怀疑是提供的库有问题,所以尝试源码来重新编译一下.log4cxx官方主页:https ...
- QML::Rectangle组件
QML的Rectangle组件,描绘一个矩形,一个可视化的对象. 外加设置属性来达到我们想要的效果.常用的有矩形的颜色,边框颜色,圆角等设置. Rectangle{ x:10//这里的坐标是相对于它的 ...
- JavaScript初探 四 (程序结构)
JavaScript 结构 JavaScript 程序结构 JavaScript支持几乎和C语言一样的程序结构 分支结构 循环结构 分支结构 条件分支 if-else if语句:判断条件为true则执 ...
- 配置flutter For IOS
https://www.cnblogs.com/lovestarfish/p/10628205.html 第一步,下载flutter最新版,解压到自己的目录里: 提供网址:https://flutte ...
- 微信小程序json与xml互相转换
1.首先在目录结构中引入必要的js文件 https://files.cnblogs.com/files/qianyou304/x2j.rar 2.js中代码如下:(部分)json 2 xml var ...
- python中Socket的使用
说明 前一段时间学习python网络编程,完成简单的通过python实现网络通信的功能.现在,将python中Socket 通信的基本实现过程做一个记录备份. Socket通信 python 中的so ...
- 获取BOM标准用量
Select dbms_aw.eval_number(listagg(' 1' || sys_connect_by_pat ...
- httpd虚拟主机起不来!!
前几天在公司,练习负载均衡配置.在配置虚拟主机的web服务(apache) ,创建好虚拟主机的配置文件 ss -tnl 查看监控端口80已起来,通过本地浏览器访问一直显示默认的欢迎页... 一个下午 ...