1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
|
copy
# -*- coding:utf-8 -*-
import numpy as np
import numpy.random as npr
from ..fast_rcnn.config import cfg
from bbox import bbox_overlaps, bbox_intersections
DEBUG = False
# 生成基础anchor box
def generate_basic_anchors(sizes, base_size=16):
base_anchor = np.array([0, 0, base_size - 1, base_size - 1], np.int32)
anchors = np.zeros((len(sizes), 4), np.int32)
index = 0
for h, w in sizes:
anchors[index] = scale_anchor(base_anchor, h, w)
index += 1
return anchors
# 根据baseanchor和设定的anchor的高度和宽度进行设定的anchor生成
def scale_anchor(anchor, h, w):
x_ctr = (anchor[0] + anchor[2]) * 0.5
y_ctr = (anchor[1] + anchor[3]) * 0.5
scaled_anchor = anchor.copy()
scaled_anchor[0] = x_ctr - w / 2 # xmin
scaled_anchor[2] = x_ctr + w / 2 # xmax
scaled_anchor[1] = y_ctr - h / 2 # ymin
scaled_anchor[3] = y_ctr + h / 2 # ymax
return scaled_anchor
# 生成anchor box
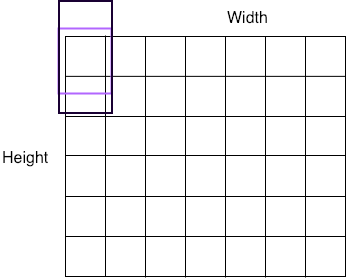
# 此处使用的是宽度固定,高度不同的anchor设置
def generate_anchors(base_size=16, ratios=[0.5, 1, 2],
scales=2 ** np.arange(3, 6)):
heights = [11, 16, 23, 33, 48, 68, 97, 139, 198, 283]
widths = [16]
sizes = []
for h in heights:
for w in widths:
sizes.append((h, w))
return generate_basic_anchors(sizes)
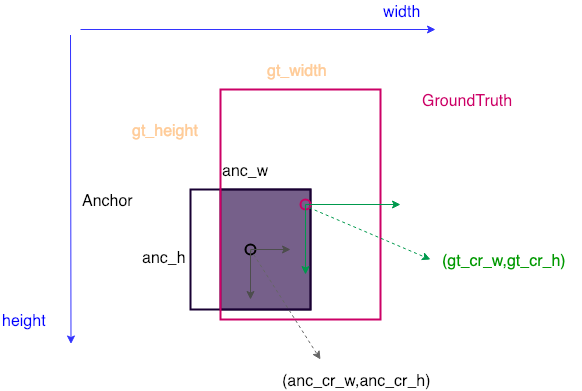
# 生成的anchor和groundtruth之间进行转换,转换方式和论文一致
def bbox_transform(ex_rois, gt_rois):
"""
computes the distance from ground-truth boxes to the given boxes, normed by their size
:param ex_rois: n * 4 numpy array, anchor boxes
:param gt_rois: n * 4 numpy array, ground-truth boxes
:return: deltas: n * 4 numpy array, ground-truth boxes
"""
ex_widths = ex_rois[:, 2] - ex_rois[:, 0] + 1.0 # anchor width
ex_heights = ex_rois[:, 3] - ex_rois[:, 1] + 1.0 # anchor height
ex_ctr_x = ex_rois[:, 0] + 0.5 * ex_widths # anchor center x
ex_ctr_y = ex_rois[:, 1] + 0.5 * ex_heights # anchor center y
assert np.min(ex_widths) > 0.1 and np.min(ex_heights) > 0.1, \
'Invalid boxes found: {} {}'. \
format(ex_rois[np.argmin(ex_widths), :], ex_rois[np.argmin(ex_heights), :])
gt_widths = gt_rois[:, 2] - gt_rois[:, 0] + 1.0 # gt_box width
gt_heights = gt_rois[:, 3] - gt_rois[:, 1] + 1.0 # gt_box height
gt_ctr_x = gt_rois[:, 0] + 0.5 * gt_widths # gt_box center x
gt_ctr_y = gt_rois[:, 1] + 0.5 * gt_heights # gt_box center y
# warnings.catch_warnings()
# warnings.filterwarnings('error')
targets_dx = (gt_ctr_x - ex_ctr_x) / ex_widths # (gt_c_x-a_c_x)
targets_dy = (gt_ctr_y - ex_ctr_y) / ex_heights
targets_dw = np.log(gt_widths / ex_widths)
targets_dh = np.log(gt_heights / ex_heights)
targets = np.vstack(
(targets_dx, targets_dy, targets_dw, targets_dh)).transpose()
return targets
# 生成anchors
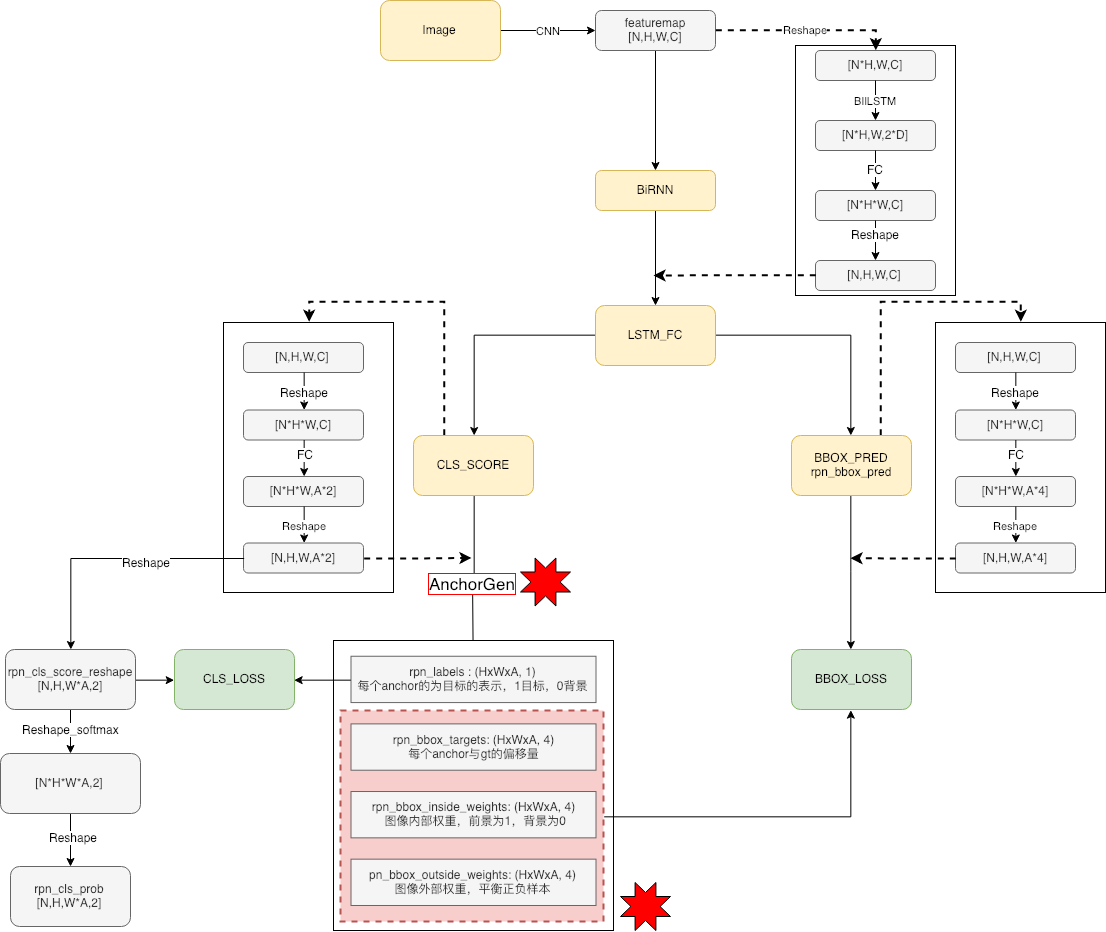
def anchor_target_layer(
rpn_cls_score, gt_boxes, gt_ishard, dontcare_areas, im_info, _feat_stride=[16, ],
anchor_scales=[16, ]):
"""
Assign anchors to ground-truth targets. Produces anchor classification
labels and bounding-box regression targets.
Parameters
----------
rpn_cls_score: (1, H, W, Ax2) bg/fg scores of previous conv layer
gt_boxes: (G, 5) vstack of [x1, y1, x2, y2, class]
gt_ishard: (G, 1), 1 or 0 indicates difficult or not
dontcare_areas: (D, 4), some areas may contains small objs but no labelling. D may be 0
im_info: a list of [image_height, image_width, scale_ratios]
_feat_stride: the downsampling ratio of feature map to the original input image
anchor_scales: the scales to the basic_anchor (basic anchor is [16, 16])
----------
Returns
----------
rpn_labels : (HxWxA, 1), for each anchor, 0 denotes bg, 1 fg, -1 dontcare
rpn_bbox_targets: (HxWxA, 4), distances of the anchors to the gt_boxes(may contains some transform)
that are the regression objectives
rpn_bbox_inside_weights: (HxWxA, 4) weights of each boxes, mainly accepts hyper param in cfg
rpn_bbox_outside_weights: (HxWxA, 4) used to balance the fg/bg,
beacuse the numbers of bgs and fgs mays significiantly different
"""
# anchors is the [x_min,y_min,x_max,y_max]
# 生成基本的anchor,一共10个
_anchors = generate_anchors(scales=np.array(anchor_scales))
_num_anchors = _anchors.shape[0] # 10个anchor
# allow boxes to sit over the edge by a small amount
_allowed_border = 0
# 原始图像的信息,图像的高宽及通道数
im_info = im_info[0]
# 在feature-map上定位anchor,并加上delta,得到在实际图像中anchor的真实坐标
"""
Algorithm:
for each (H, W) location i
generate 9 anchor boxes centered on cell i
apply predicted bbox deltas at cell i to each of the 9 anchors
filter out-of-image anchors
measure GT overlap
"""
assert rpn_cls_score.shape[0] == 1, \
'Only single item batches are supported'
# map of shape (..., H, W)
height, width = rpn_cls_score.shape[1:3] # feature-map的高宽
# 1. Generate proposals from bbox deltas and shifted anchors
shift_x = np.arange(0, width) * _feat_stride
shift_y = np.arange(0, height) * _feat_stride
shift_x, shift_y = np.meshgrid(shift_x, shift_y) # in W H order
# 生成feature-map和真实图像上anchor之间的偏移量
# shifts构建网格结构,shape [height*width,4]
shifts = np.vstack((shift_x.ravel(), shift_y.ravel(),
shift_x.ravel(), shift_y.ravel())).transpose()
A = _num_anchors # 10个anchor
K = shifts.shape[0] # feature-map的宽乘高的大小
# 为当前的featuremap每个点生成A个anchor,shape is [K,A,4]
all_anchors = (_anchors.reshape((1, A, 4)) +
shifts.reshape((1, K, 4)).transpose((1, 0, 2)))
all_anchors = all_anchors.reshape((K * A, 4)) # shape is (K*A,4)
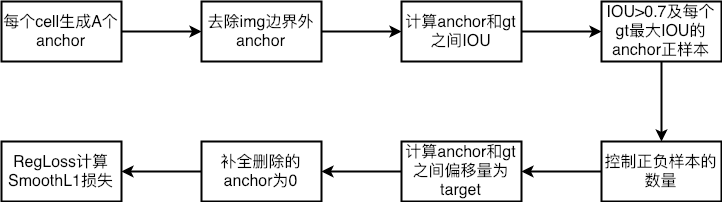
# 在featuremap上每个点生成A个anchor
total_anchors = int(K * A)
# only keep anchors inside the image
# 因为生成的anchor尺寸有大有小,因此在边缘处生成的anchor有可能会超过原始图像的边界,
# 将这些超过边界的anchor去掉,得到的是这些anchor的在all_anchors中的索引
# 仅保留那些还在图像内部的anchor,超出图像的都删掉
# anchors[:]=[x_min,y_min,x_max,y_max]
inds_inside = np.where(
(all_anchors[:, 0] >= -_allowed_border) &
(all_anchors[:, 1] >= -_allowed_border) &
(all_anchors[:, 2] < im_info[1] + _allowed_border) & # width
(all_anchors[:, 3] < im_info[0] + _allowed_border) # height
)[0]
# keep only inside anchors
anchors = all_anchors[inds_inside, :] # 保留那些在图像内的anchor
# 至此,anchor准备好了
# --------------------------------------------------------------
# label: 1 is positive, 0 is negative, -1 is dont care
# (A)
labels = np.empty((len(inds_inside),), dtype=np.float32)
labels.fill(-1) # 初始化label,均为-1
# overlaps between the anchors and the gt boxes
# overlaps (ex, gt), shape is A x G
# 计算anchor和gt-box的overlap,用来给anchor上标签
# anchor box and groundtruth box 交集面积/并集面积
# 通过IOU的得分来确定anchor为正样本与否
# overlaps shape is [anchor.shape[0],gt_box.shape[0]]
overlaps = bbox_overlaps(
np.ascontiguousarray(anchors, dtype=np.float),
np.ascontiguousarray(gt_boxes, dtype=np.float))
# 存放每一个anchor和每一个gtbox之间的overlap
# 找到和每一个gtbox,overlap最大的那个anchor
argmax_overlaps = overlaps.argmax(axis=1)
max_overlaps = overlaps[np.arange(len(inds_inside)), argmax_overlaps]
# 找到每个位置上10个anchor中与gtbox,overlap最大的那个
gt_argmax_overlaps = overlaps.argmax(axis=0)
gt_max_overlaps = overlaps[gt_argmax_overlaps,
np.arange(overlaps.shape[1])]
gt_argmax_overlaps = np.where(overlaps == gt_max_overlaps)[0]
if not cfg.TRAIN.RPN_CLOBBER_POSITIVES:
# assign bg labels first so that positive labels can clobber them
# 先给背景上标签,小于0.3overlap的为负样本label为0
labels[max_overlaps < cfg.TRAIN.RPN_NEGATIVE_OVERLAP] = 0
# -----------------------------------#
# 正样本的确定,iou得分大于0.7和每个位置上具有最大IOU得分的anchor
# fg label: for each gt, anchor with highest overlap
# 每个位置上的10个个anchor中overlap最大的认为是前景
labels[gt_argmax_overlaps] = 1
# fg label: above threshold IOU
# overlap大于0.7的认为是前景
labels[max_overlaps >= cfg.TRAIN.RPN_POSITIVE_OVERLAP] = 1
if cfg.TRAIN.RPN_CLOBBER_POSITIVES:
# assign bg labels last so that negative labels can clobber positives
labels[max_overlaps < cfg.TRAIN.RPN_NEGATIVE_OVERLAP] = 0
# preclude dontcare areas
# 这里我们暂时不考虑有doncare_area的存在
if dontcare_areas is not None and dontcare_areas.shape[0] > 0:
# intersec shape is D x A
intersecs = bbox_intersections(
np.ascontiguousarray(dontcare_areas, dtype=np.float), # D x 4
np.ascontiguousarray(anchors, dtype=np.float) # A x 4
)
intersecs_ = intersecs.sum(axis=0) # A x 1
labels[intersecs_ > cfg.TRAIN.DONTCARE_AREA_INTERSECTION_HI] = -1
# 这里我们暂时不考虑难样本的问题
# preclude hard samples that are highly occlusioned, truncated or difficult to see
if cfg.TRAIN.PRECLUDE_HARD_SAMPLES and gt_ishard is not None and gt_ishard.shape[0] > 0:
assert gt_ishard.shape[0] == gt_boxes.shape[0]
gt_ishard = gt_ishard.astype(int)
gt_hardboxes = gt_boxes[gt_ishard == 1, :]
if gt_hardboxes.shape[0] > 0:
# H x A
hard_overlaps = bbox_overlaps(
np.ascontiguousarray(gt_hardboxes, dtype=np.float), # H x 4
np.ascontiguousarray(anchors, dtype=np.float)) # A x 4
hard_max_overlaps = hard_overlaps.max(axis=0) # (A)
labels[hard_max_overlaps >= cfg.TRAIN.RPN_POSITIVE_OVERLAP] = -1
max_intersec_label_inds = hard_overlaps.argmax(axis=1) # H x 1
labels[max_intersec_label_inds] = -1 #
# subsample positive labels if we have too many
# 对正样本进行采样,如果正样本的数量太多的话
# 限制正样本的数量不超过128个,排除的置位dont_Care类
# TODO 这个后期可能还需要修改,毕竟如果使用的是字符的片段,那个正样本的数量是很多的。
num_fg = int(cfg.TRAIN.RPN_FG_FRACTION * cfg.TRAIN.RPN_BATCHSIZE)
fg_inds = np.where(labels == 1)[0]
if len(fg_inds) > num_fg:
disable_inds = npr.choice(
fg_inds, size=(len(fg_inds) - num_fg), replace=False) # 随机去除掉一些正样本
labels[disable_inds] = -1 # 变为-1
# subsample negative labels if we have too many
# 对负样本进行采样,如果负样本的数量太多的话
# 正负样本总数是256,限制正样本数目最多128,
# 如果正样本数量小于128,差的那些就用负样本补上,凑齐256个样本
num_bg = cfg.TRAIN.RPN_BATCHSIZE - np.sum(labels == 1)
bg_inds = np.where(labels == 0)[0]
if len(bg_inds) > num_bg:
disable_inds = npr.choice(
bg_inds, size=(len(bg_inds) - num_bg), replace=False)
labels[disable_inds] = -1
# print "was %s inds, disabling %s, now %s inds" % (
# len(bg_inds), len(disable_inds), np.sum(labels == 0))
# 至此, 上好标签,开始计算rpn-box的真值
# --------------------------------------------------------------
bbox_targets = np.zeros((len(inds_inside), 4), dtype=np.float32)
# 根据anchor和gtbox计算得真值(anchor和gtbox之间的偏差)
bbox_targets = _compute_targets(anchors, gt_boxes[argmax_overlaps, :])
# 内部权重,前景就给1,其他是0
bbox_inside_weights = np.zeros((len(inds_inside), 4), dtype=np.float32)
bbox_inside_weights[labels == 1, :] = np.array(
cfg.TRAIN.RPN_BBOX_INSIDE_WEIGHTS)
bbox_outside_weights = np.zeros((len(inds_inside), 4), dtype=np.float32)
if cfg.TRAIN.RPN_POSITIVE_WEIGHT < 0:
# 此处使用uniform权重,也就是正样本是1,负样本是0
# uniform weighting of examples (given non-uniform sampling)
# num_examples = np.sum(labels >= 0) + 1
# positive_weights = np.ones((1, 4)) * 1.0 / num_examples
# negative_weights = np.ones((1, 4)) * 1.0 / num_examples
positive_weights = np.ones((1, 4)) # 前景为1
negative_weights = np.zeros((1, 4)) # 背景为0
else:
assert ((cfg.TRAIN.RPN_POSITIVE_WEIGHT > 0) &
(cfg.TRAIN.RPN_POSITIVE_WEIGHT < 1))
positive_weights = (cfg.TRAIN.RPN_POSITIVE_WEIGHT /
(np.sum(labels == 1)) + 1)
negative_weights = ((1.0 - cfg.TRAIN.RPN_POSITIVE_WEIGHT) /
(np.sum(labels == 0)) + 1)
# 外部权重,前景是1,背景是0
# bbox_outside_weights初始化为0,将label中为0的位置赋值bbox_outside_weights为0,labels为1的位置赋值为1
bbox_outside_weights[labels == 1, :] = positive_weights
bbox_outside_weights[labels == 0, :] = negative_weights
# map up to original set of anchors
# 一开始是将超出图像范围的anchor直接丢掉的,现在在加回来
# inds_inside 是原始anchor中的索引
labels = _unmap(labels, total_anchors, inds_inside, fill=-1) # 这些anchor的label是-1,也即dontcare
bbox_targets = _unmap(bbox_targets, total_anchors, inds_inside, fill=0) # 这些anchor的真值是0,也即没有值
bbox_inside_weights = _unmap(bbox_inside_weights, total_anchors,
inds_inside, fill=0) # 内部权重以0填充
bbox_outside_weights = _unmap(bbox_outside_weights, total_anchors,
inds_inside, fill=0) # 外部权重以0填充
# labels
labels = labels.reshape((1, height, width, A)) # reshap一下label
rpn_labels = labels
# bbox_targets
bbox_targets = bbox_targets.reshape((1, height, width, A * 4)) # reshape
rpn_bbox_targets = bbox_targets
# bbox_inside_weights
bbox_inside_weights = bbox_inside_weights.reshape((1, height, width, A * 4))
rpn_bbox_inside_weights = bbox_inside_weights
# bbox_outside_weights
bbox_outside_weights = bbox_outside_weights.reshape((1, height, width, A * 4))
rpn_bbox_outside_weights = bbox_outside_weights
rpn_data=(rpn_labels, rpn_bbox_targets, rpn_bbox_inside_weights, rpn_bbox_outside_weights)
return rpn_data
# 将排除掉边界之外的anchors之后的anchor补全回来
def _unmap(data, count, inds, fill=0):
""" Unmap a subset of item (data) back to the original set of items (of
size count) """
if len(data.shape) == 1:
ret = np.empty((count,), dtype=np.float32)
ret.fill(fill)
ret[inds] = data
else:
ret = np.empty((count,) + data.shape[1:], dtype=np.float32)
ret.fill(fill)
ret[inds, :] = data
return ret
# 计算anchor和gt之间的矩形框的偏差
def _compute_targets(ex_rois, gt_rois):
"""Compute bounding-box regression targets for an image."""
assert ex_rois.shape[0] == gt_rois.shape[0]
assert ex_rois.shape[1] == 4
assert gt_rois.shape[1] == 5
return bbox_transform(ex_rois, gt_rois[:, :4]).astype(np.float32, copy=False)
|