ElasticSearch(三):通分词器(Analyzer)进行分词(Analysis)
ElasticSearch(三):通过分词器(Analyzer)进行分词(Analysis)
## Analysis与Analyzer
* Analysis文本分析就是把全文转换成一系列单词的过程,也叫做分词。
* Analysis是通过Analyzer来实现的,它是专门处理分词的组件。可以使用ElasticSearch内置的分词器,也可以按需定制化分词器。
* 除了在数据写入时用分词器转换词条,在匹配查询语句时,也需要用相同的分词器对查询语句进行分析。
Analyzer的组成
分词器是专门处理分词的组件,Analyzer由三个部分组成:
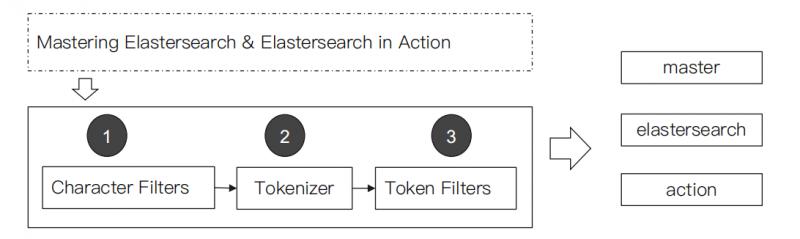
- Character Filters:主要作用是对原始文本进行处理,例如去除HTML标签。
- Tokenizer:主要作用是按照规则来切分单词。
- Token Filter:将切分好的单词进行加工,例如:小写转换、删除停用词、增加同义词。
ElasticSearch的内置分词器
- Standard Analyzer:默认分词器,按词切分,小写处理。
#standard
GET _analyze
{
"analyzer": "standard",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#分词结果:Quick小写处理, brown-foxes被切分为 brown,foxes
{
"tokens" : [
{
"token" : "2",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<NUM>",
"position" : 0
},
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "quick",#小写处理
"start_offset" : 10,
"end_offset" : 15,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "brown",
"start_offset" : 16,
"end_offset" : 21,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "foxes",
"start_offset" : 22,
"end_offset" : 27,
"type" : "<ALPHANUM>",
"position" : 4
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "<ALPHANUM>",
"position" : 5
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "<ALPHANUM>",
"position" : 6
},
{
"token" : "lazy",
"start_offset" : 38,
"end_offset" : 42,
"type" : "<ALPHANUM>",
"position" : 7
},
{
"token" : "dogs",
"start_offset" : 43,
"end_offset" : 47,
"type" : "<ALPHANUM>",
"position" : 8
},
{
"token" : "in",
"start_offset" : 48,
"end_offset" : 50,
"type" : "<ALPHANUM>",
"position" : 9
},
{
"token" : "the",
"start_offset" : 51,
"end_offset" : 54,
"type" : "<ALPHANUM>",
"position" : 10
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "<ALPHANUM>",
"position" : 11
},
{
"token" : "evening",
"start_offset" : 62,
"end_offset" : 69,
"type" : "<ALPHANUM>",
"position" : 12
}
]
}
- Simple Analyzer:按照非字母切分(符号被过滤),小写处理。
#simpe
GET _analyze
{
"analyzer": "simple",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#分词结果:数字2被过滤,Quick小写处理, brown-foxes被切分为 brown,foxes
{
"tokens" : [
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "word",
"position" : 0
},
{
"token" : "quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "word",
"position" : 1
},
{
"token" : "brown",
"start_offset" : 16,
"end_offset" : 21,
"type" : "word",
"position" : 2
},
{
"token" : "foxes",
"start_offset" : 22,
"end_offset" : 27,
"type" : "word",
"position" : 3
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "word",
"position" : 4
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "word",
"position" : 5
},
{
"token" : "lazy",
"start_offset" : 38,
"end_offset" : 42,
"type" : "word",
"position" : 6
},
{
"token" : "dogs",
"start_offset" : 43,
"end_offset" : 47,
"type" : "word",
"position" : 7
},
{
"token" : "in",
"start_offset" : 48,
"end_offset" : 50,
"type" : "word",
"position" : 8
},
{
"token" : "the",
"start_offset" : 51,
"end_offset" : 54,
"type" : "word",
"position" : 9
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "word",
"position" : 10
},
{
"token" : "evening",
"start_offset" : 62,
"end_offset" : 69,
"type" : "word",
"position" : 11
}
]
}
- Stop Analyzer:停用词过滤(is/a/the),小写处理。
#stop
GET _analyze
{
"analyzer": "stop",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#分词结果:2,in,the被过滤,Quick小写处理, brown-foxes被切分为 brown,foxes
{
"tokens" : [
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "word",
"position" : 0
},
{
"token" : "quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "word",
"position" : 1
},
{
"token" : "brown",
"start_offset" : 16,
"end_offset" : 21,
"type" : "word",
"position" : 2
},
{
"token" : "foxes",
"start_offset" : 22,
"end_offset" : 27,
"type" : "word",
"position" : 3
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "word",
"position" : 4
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "word",
"position" : 5
},
{
"token" : "lazy",
"start_offset" : 38,
"end_offset" : 42,
"type" : "word",
"position" : 6
},
{
"token" : "dogs",
"start_offset" : 43,
"end_offset" : 47,
"type" : "word",
"position" : 7
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "word",
"position" : 10
},
{
"token" : "evening",
"start_offset" : 62,
"end_offset" : 69,
"type" : "word",
"position" : 11
}
]
}
- WhiteSpace Analyzer:按照空格切分,不转小写。
#whitespace
GET _analyze
{
"analyzer": "whitespace",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#分词结果:按空格切分
{
"tokens" : [
{
"token" : "2",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
},
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "word",
"position" : 1
},
{
"token" : "Quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "word",
"position" : 2
},
{
"token" : "brown-foxes",
"start_offset" : 16,
"end_offset" : 27,
"type" : "word",
"position" : 3
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "word",
"position" : 4
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "word",
"position" : 5
},
{
"token" : "lazy",
"start_offset" : 38,
"end_offset" : 42,
"type" : "word",
"position" : 6
},
{
"token" : "dogs",
"start_offset" : 43,
"end_offset" : 47,
"type" : "word",
"position" : 7
},
{
"token" : "in",
"start_offset" : 48,
"end_offset" : 50,
"type" : "word",
"position" : 8
},
{
"token" : "the",
"start_offset" : 51,
"end_offset" : 54,
"type" : "word",
"position" : 9
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "word",
"position" : 10
},
{
"token" : "evening.",
"start_offset" : 62,
"end_offset" : 70,
"type" : "word",
"position" : 11
}
]
}
- Keyword Analyzer:不分词,直接将输入当作输出。
#keyword
GET _analyze
{
"analyzer": "keyword",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#分词结果:
{
"tokens" : [
{
"token" : "2 running Quick brown-foxes leap over lazy dogs in the summer evening.",
"start_offset" : 0,
"end_offset" : 70,
"type" : "word",
"position" : 0
}
]
}
- Pattern Analyzer:正则表达式分词,默认\W+(非字符分隔)。
#pattern
GET _analyze
{
"analyzer": "pattern",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#分词结果:
{
"tokens" : [
{
"token" : "2",
"start_offset" : 0,
"end_offset" : 1,
"type" : "word",
"position" : 0
},
{
"token" : "running",
"start_offset" : 2,
"end_offset" : 9,
"type" : "word",
"position" : 1
},
{
"token" : "quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "word",
"position" : 2
},
{
"token" : "brown",
"start_offset" : 16,
"end_offset" : 21,
"type" : "word",
"position" : 3
},
{
"token" : "foxes",
"start_offset" : 22,
"end_offset" : 27,
"type" : "word",
"position" : 4
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "word",
"position" : 5
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "word",
"position" : 6
},
{
"token" : "lazy",
"start_offset" : 38,
"end_offset" : 42,
"type" : "word",
"position" : 7
},
{
"token" : "dogs",
"start_offset" : 43,
"end_offset" : 47,
"type" : "word",
"position" : 8
},
{
"token" : "in",
"start_offset" : 48,
"end_offset" : 50,
"type" : "word",
"position" : 9
},
{
"token" : "the",
"start_offset" : 51,
"end_offset" : 54,
"type" : "word",
"position" : 10
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "word",
"position" : 11
},
{
"token" : "evening",
"start_offset" : 62,
"end_offset" : 69,
"type" : "word",
"position" : 12
}
]
}
- Language:提供了30多种常见语言的分词器。
#english
GET _analyze
{
"analyzer": "english",
"text": "2 running Quick brown-foxes leap over lazy dogs in the summer evening."
}
#分词结果:running转为run,Quick转为quick,brown-foxes 转为brown、fox,in、the过滤等等
{
"tokens" : [
{
"token" : "2",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<NUM>",
"position" : 0
},
{
"token" : "run",
"start_offset" : 2,
"end_offset" : 9,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "quick",
"start_offset" : 10,
"end_offset" : 15,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "brown",
"start_offset" : 16,
"end_offset" : 21,
"type" : "<ALPHANUM>",
"position" : 3
},
{
"token" : "fox",
"start_offset" : 22,
"end_offset" : 27,
"type" : "<ALPHANUM>",
"position" : 4
},
{
"token" : "leap",
"start_offset" : 28,
"end_offset" : 32,
"type" : "<ALPHANUM>",
"position" : 5
},
{
"token" : "over",
"start_offset" : 33,
"end_offset" : 37,
"type" : "<ALPHANUM>",
"position" : 6
},
{
"token" : "lazi",
"start_offset" : 38,
"end_offset" : 42,
"type" : "<ALPHANUM>",
"position" : 7
},
{
"token" : "dog",
"start_offset" : 43,
"end_offset" : 47,
"type" : "<ALPHANUM>",
"position" : 8
},
{
"token" : "summer",
"start_offset" : 55,
"end_offset" : 61,
"type" : "<ALPHANUM>",
"position" : 11
},
{
"token" : "even",
"start_offset" : 62,
"end_offset" : 69,
"type" : "<ALPHANUM>",
"position" : 12
}
]
}
- Custom Analyzer:自定义分词器。
#需要安装analysis-icu插件
POST _analyze
{
"analyzer": "icu_analyzer",
"text": "他说的确实在理”"
}
#返回结果
{
"tokens" : [
{
"token" : "他",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "说的",
"start_offset" : 1,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "确实",
"start_offset" : 3,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "在",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "理",
"start_offset" : 6,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 4
}
]
}
中文分词比较:
POST _analyze
{
"analyzer": "standard",
"text": "他说的确实在理”"
}
#返回结果
{
"tokens" : [
{
"token" : "他",
"start_offset" : 0,
"end_offset" : 1,
"type" : "<IDEOGRAPHIC>",
"position" : 0
},
{
"token" : "说",
"start_offset" : 1,
"end_offset" : 2,
"type" : "<IDEOGRAPHIC>",
"position" : 1
},
{
"token" : "的",
"start_offset" : 2,
"end_offset" : 3,
"type" : "<IDEOGRAPHIC>",
"position" : 2
},
{
"token" : "确",
"start_offset" : 3,
"end_offset" : 4,
"type" : "<IDEOGRAPHIC>",
"position" : 3
},
{
"token" : "实",
"start_offset" : 4,
"end_offset" : 5,
"type" : "<IDEOGRAPHIC>",
"position" : 4
},
{
"token" : "在",
"start_offset" : 5,
"end_offset" : 6,
"type" : "<IDEOGRAPHIC>",
"position" : 5
},
{
"token" : "理",
"start_offset" : 6,
"end_offset" : 7,
"type" : "<IDEOGRAPHIC>",
"position" : 6
}
]
}
ElasticSearch(三):通分词器(Analyzer)进行分词(Analysis)的更多相关文章
- Elasticsearch(10) --- 内置分词器、中文分词器
Elasticsearch(10) --- 内置分词器.中文分词器 这篇博客主要讲:分词器概念.ES内置分词器.ES中文分词器. 一.分词器概念 1.Analysis 和 Analyzer Analy ...
- ElasticSearch7.3 学习之倒排索引揭秘及初识分词器(Analyzer)
一.倒排索引 1. 构建倒排索引 例如说有下面两个句子doc1,doc2 doc1:I really liked my small dogs, and I think my mom also like ...
- es的分词器analyzer
analyzer 分词器使用的两个情形: 1,Index time analysis. 创建或者更新文档时,会对文档进行分词2,Search time analysis. 查询时,对查询语句 ...
- Lucene.net(4.8.0)+PanGu分词器问题记录一:分词器Analyzer的构造和内部成员ReuseStategy
前言:目前自己在做使用Lucene.net和PanGu分词实现全文检索的工作,不过自己是把别人做好的项目进行迁移.因为项目整体要迁移到ASP.NET Core 2.0版本,而Lucene使用的版本是3 ...
- Lucene.net(4.8.0) 学习问题记录一:分词器Analyzer的构造和内部成员ReuseStategy
前言:目前自己在做使用Lucene.net和PanGu分词实现全文检索的工作,不过自己是把别人做好的项目进行迁移.因为项目整体要迁移到ASP.NET Core 2.0版本,而Lucene使用的版本是3 ...
- Elasticsearch修改分词器以及自定义分词器
Elasticsearch修改分词器以及自定义分词器 参考博客:https://blog.csdn.net/shuimofengyang/article/details/88973597
- 【Lucene3.6.2入门系列】第05节_自定义停用词分词器和同义词分词器
首先是用于显示分词信息的HelloCustomAnalyzer.java package com.jadyer.lucene; import java.io.IOException; import j ...
- Lucene学习-深入Lucene分词器,TokenStream获取分词详细信息
Lucene学习-深入Lucene分词器,TokenStream获取分词详细信息 在此回复牛妞的关于程序中分词器的问题,其实可以直接很简单的在词库中配置就好了,Lucene中分词的所有信息我们都可以从 ...
- 自然语言处理之中文分词器-jieba分词器详解及python实战
(转https://blog.csdn.net/gzmfxy/article/details/78994396) 中文分词是中文文本处理的一个基础步骤,也是中文人机自然语言交互的基础模块,在进行中文自 ...
- 【ELK】【docker】【elasticsearch】2.使用elasticSearch+kibana+logstash+ik分词器+pinyin分词器+繁简体转化分词器 6.5.4 启动 ELK+logstash概念描述
官网地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html#docker-cli-run-prod ...
随机推荐
- Android 调用 WebService
1.WebService简介 PS:如果看完上面简介还不是很清楚的话,那么就算了,之前公司就用C#搭的一个WebService! 本节我们并不讨论如何去搭建一个WebService,我们仅仅知道如何去 ...
- 题解:2018级算法第二次上机 Zexal的竞赛
题目描述: 样例: 实现解释: 一道需要一点思考的动态规划题目 知识点:动态规划,数据记录 首先将题目描述调整:分别输入不同分数的题目总分(便于后续计算),当获得了i分数的总分后无法获得i-1和i+1 ...
- 【Python3爬虫】我爬取了七万条弹幕,看看RNG和SKT打得怎么样
一.写在前面 直播行业已经火热几年了,几个大平台也有了各自独特的“弹幕文化”,不过现在很多平台直播比赛时的弹幕都基本没法看的,主要是因为网络上的喷子还是挺多的,尤其是在观看比赛的时候,很多弹幕不是喷选 ...
- Kubernetes之Flannel介绍
Flannel是CoreOS团队针对Kubernetes设计的一个网络规划服务,简单来说,它的功能是让集群中的不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址. 在Kubernetes ...
- 微信小程序前端页面书写
微信小程序前端页面书写 WXML(WeiXin Markup Language)是框架设计的一套标签语言,结合基础组件.事件系统,可以构建出页面的结构. 一.数据绑定 1. 普通写法 <view ...
- 机器学习:不平衡信息有序平均加权最近邻算法IFROWANN
一 背景介绍 不平衡信息,特点是少数信息更珍贵,多数信息没有代表性.所以一般的分类算法会被多数信息影响,而忽略少数信息的重要性. 解决策略: 1.数据级别 (1)上采样:增加稀有类成本数 (2)下采样 ...
- 在VM上安装OpenWrt
1.选择'自定义',点击'下一步' 2.'硬件兼容性'默认,点击'下一步' 3.'稍后安装操作系统',点击'下一步' 4.客户机操作系统'Linux' 版本'CentOS 64位',点击'下一步' 说 ...
- 设置H5页面文字不可复制
* { moz-user-select: -moz-none; -moz-user-select: none; -o-user-select: none; -khtml-user-select: no ...
- 史上最详细的IDEA优雅整合Maven+SSM框架(详细思路+附带源码)
目录 前言: 1. 搭建整合环境 2.Spring框架代码的编写 3.SpringMVC框架代码的编写 4. Spring整合SpringMVC的框架 5.MyBatis框架代码的编写 6. Spri ...
- matlab 7遇到的错误 解决方法
安装路径 参考D:\matlab7 安装最后一步弹出 未找到解决方法.不过没有发现有何影响. 安装完成后出现 1. To configure Real-Time Windows Target you ...