pytorch笔记
Tensor create
#创建特定shape value为random值的tensor
input = torch.rand((64,64,3))
Tensor slice
- 以[2,3]矩阵为例,slice后可以得到任意shape的矩阵,并不是说一定会小于2行3列.
import torch
truths=torch.Tensor([[1,2,3],[4,5,6]])
#代表新生成一个[3,]的矩阵,行位置分别取原先矩阵的第1,第0,第1行.
print(truths[[1,0,1],:])
print(truths[[1,0,1]]) #等同于truths[[1,0,1],:]
#代表新生成一个[,4]的矩阵,列位置分别取原先矩阵的第2,第2,第2,第2列
print(truths[:,[2,2,2,2]])
输出

- 用bool型的tensor去切片
import torch
x = torch.tensor([[1,2,3],[4,5,6]])
index = x>2
print(index.type())
x[index]

tensor扩展

Expanding a tensor does not allocate new memory, but only creates a new view on the existing tensor where a dimension of size one is expanded to a larger size by setting the stride to 0. Any dimension of size 1 can be expanded to an arbitrary value without allocating new memory.
并不分配新内存. 只是改变了已有tensor的view. size为1的维度被扩展为更大的size.
>>> x = torch.tensor([[1], [2], [3]])
>>> x.size()
torch.Size([3, 1])
>>> x.expand(3, 4)
tensor([[ 1, 1, 1, 1],
[ 2, 2, 2, 2],
[ 3, 3, 3, 3]])
>>> x.expand(-1, 4) # -1 means not changing the size of that dimension
tensor([[ 1, 1, 1, 1],
[ 2, 2, 2, 2],
[ 3, 3, 3, 3]])
gather
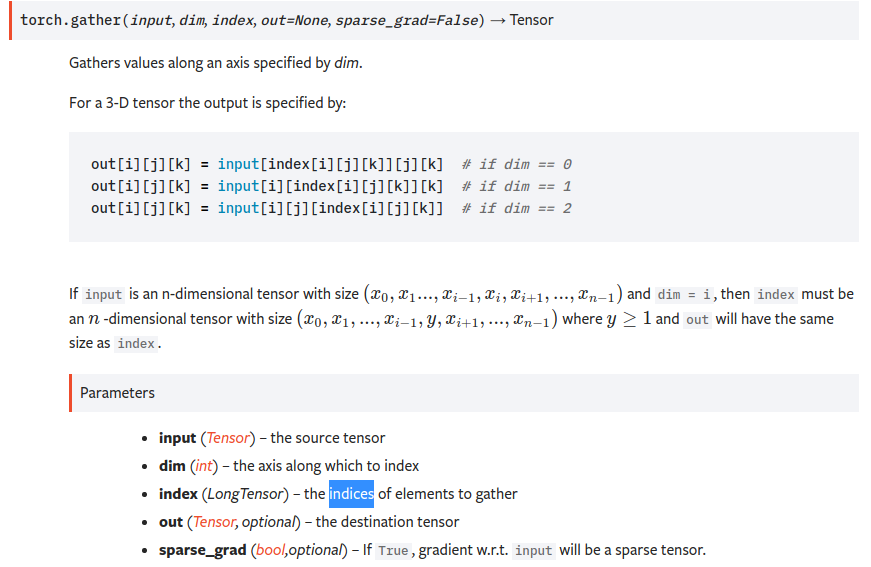
torch.gather(input, dim, index, out=None, sparse_grad=False) → Tensor
即dim维度的下标由index替换.input是n维的,index也得是n维的,tensor在第dim维度上的size可以和input不一致. 最终的output和index的shape是一致的.
即对dim维度的数据按照index来索引.
比如
import torch
t = torch.tensor([[1,2],[3,4]])
index=torch.tensor([[0,0],[1,0]])
torch.gather(t,1,index)
输出
tensor([[1, 1],
[4, 3]])
gather(t,1,index)替换第1维度的数据(即列方向),替换成哪些列的值呢?[[0,0],[1,0]],对第一行,分别为第0列,第0列,对第二行,分别为第1列,第0列.
从而得到tensor([[1, 1],[4, 3]])
sum

沿着第n维度,求和.keepdim表示是否保持维度数目不变.
import torch
t = torch.tensor([[1,2],[3,4]])
a=torch.sum(t,0)
b=torch.sum(t,1,keepdim=True)
print(a.shape,b.shape)
print(a)
print(b)

sort
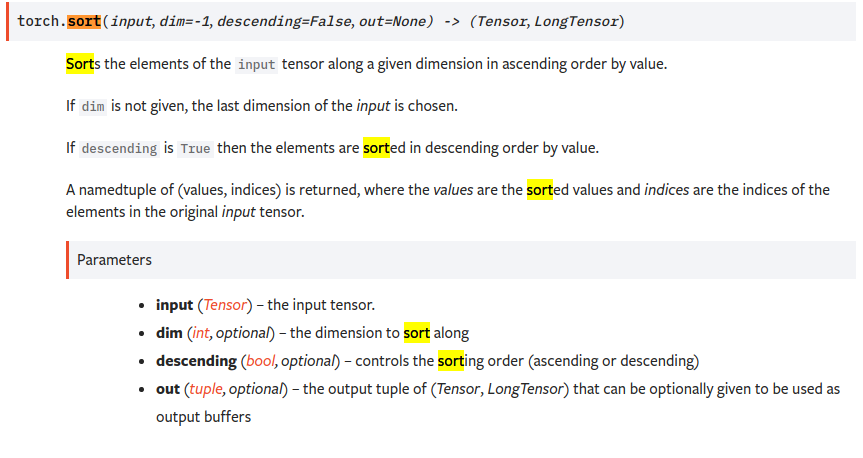
沿着第n个维度的方向排序
import torch
t = torch.tensor([[1,9,7],[8,5,6]])
_sorted,_index = t.sort(1)
print(_sorted)
print(_index)
_sorted,_index = t.sort(0)
print(_sorted)
print(_index)

clamp
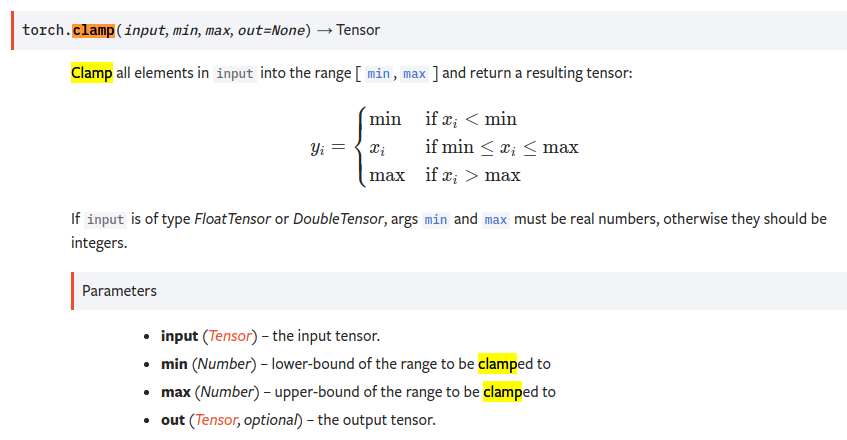
import torch
print()
t = torch.tensor([[1,2,7],[3,4,8]])
res = t.clamp(3,7) #<3的变为3,>7的变为7 中间范围的不变
print(res)
res2 = torch.clamp(t,max=5) #所有大于5的都改为5
print(res2)

各种损失函数
https://blog.csdn.net/zhangxb35/article/details/72464152
有用link:
pytorch笔记的更多相关文章
- [Pytorch] pytorch笔记 <三>
pytorch笔记 optimizer.zero_grad() 将梯度变为0,用于每个batch最开始,因为梯度在不同batch之间不是累加的,所以必须在每个batch开始的时候初始化累计梯度,重置为 ...
- [Pytorch] pytorch笔记 <二>
pytorch笔记2 用到的关于plt的总结 plt.scatter scatter(x, y, s=None, c=None, marker=None, cmap=None, norm=None, ...
- [Pytorch] pytorch笔记 <一>
pytorch笔记 - torchvision.utils.make_grid torchvision.utils.make_grid torchvision.utils.make_grid(tens ...
- 【转载】 pytorch笔记:06)requires_grad和volatile
原文地址: https://blog.csdn.net/jiangpeng59/article/details/80667335 作者:PJ-Javis 来源:CSDN --------------- ...
- pytorch笔记:09)Attention机制
刚从图像处理的hole中攀爬出来,刚走一步竟掉到了另一个hole(fire in the hole*▽*) 1.RNN中的attentionpytorch官方教程:https://pytorch.or ...
- [pytorch笔记] 调整网络学习率
1. 为网络的不同部分指定不同的学习率 class LeNet(t.nn.Module): def __init__(self): super(LeNet, self).__init__() self ...
- [pytorch笔记] torch.nn vs torch.nn.functional; model.eval() vs torch.no_grad(); nn.Sequential() vs nn.moduleList
1. torch.nn与torch.nn.functional之间的区别和联系 https://blog.csdn.net/GZHermit/article/details/78730856 nn和n ...
- Pytorch笔记 (3) 科学计算1
一.张量 标量 可以看作是 零维张量 向量 可以看作是 一维张量 矩阵 可以看作是 二维张量 继续扩展数据的维度,可以得到更高维度的张量 ————> 张量又称 多维数组 给定一个张量数据 ...
- Pytorch笔记 (2) 初识Pytorch
一.人工神经网络库 Pytorch ———— 让计算机 确定神经网络的结构 + 实现人工神经元 + 搭建人工神经网络 + 选择合适的权重 (1)确定人工神经网络的 结构: 只需要告诉Pytorc ...
- PyTorch笔记之 Dataset 和 Dataloader
一.简介 在 PyTorch 中,我们的数据集往往会用一个类去表示,在训练时用 Dataloader 产生一个 batch 的数据 https://pytorch.org/tutorials/begi ...
随机推荐
- Webpack 打包太慢? 试试 Dllplugin
webpack在build包的时候,有时候会遇到打包时间很长的问题,这里提供了一个解决方案,让打包如丝般顺滑~ 1. 介绍 在用 Webpack 打包的时候,对于一些不经常更新的第三方库,比如 rea ...
- 配置树莓派3的openwrt中的网络
在上一篇中讲到openwrt的编译安装: http://www.cnblogs.com/yeqluofwupheng/p/7296218.html 但是烧写进去,启动系统后发现它的默认配置是路由器,所 ...
- 夯实Java基础系列5:Java文件和Java包结构
目录 Java中的包概念 包的作用 package 的目录结构 设置 CLASSPATH 系统变量 常用jar包 java软件包的类型 dt.jar rt.jar *.java文件的奥秘 *.Java ...
- samba + OPENldap 搭建文件共享服务器
samba + OPENldap 搭建文件共享服务器 这里我使用的是 samba(文件共享服务) v4.9.1 + OPENldap(后端数据库软件) v2.4.44 + smbldap-tools( ...
- 使用freemarker做邮件发送模板
1.解析工具类 package com.example.springbootfreemarker.utils; import freemarker.template.Configuration; im ...
- springboot2.0+ 使用拦截器导致静态资源被拦截
在spring1.0+的版本中,配置拦截器后是不会拦截静态资源的.其配置如下: @Configuration public class WebMvcConfig extends WebMvcConfi ...
- linux常用开发命令总结
linux常用命令 文件操作命令 1. cd 目录名/目录名 切换目录 cd .. 切换到上一级目录 (change dictionary) Ctrl+C强制退出命令行,回到上一级 2.ls ...
- 微信小程序项目-你是什么垃圾?
垃圾分类特别火也不知道北京什么时候也开始执行,看见之前上海市民被灵魂拷问了以后垃圾真的不知道如何丢了,作为程序员就做一个小程序造福人类吧. 效果图: 一.全局的app.json和app.wxss加入了 ...
- 痞子衡嵌入式:史上最强i.MX RT学习资源汇总(持续更新中...)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是i.MX RT学习资源. 类别 资源 简介 官方汇总 i.MXRT产品主页 恩智浦官方i.MXRT产品主页,最权威的资料都在这里,参考手 ...
- FFmpeg(三) 编解码相关函数理解
一.编解码基本流程 主要流程: 打开视频解码器(音频一样) 软解码.硬解码 进行编解码 下面先来看打开视频解码器 ①avcodec_register_all()//初始化解码 ②先找到解码器. 找解码 ...