在Hadoop上用Python实现WordCount
一、简单说明
本例中我们用Python写一个简单的运行在Hadoop上的MapReduce程序,即WordCount(读取文本文件并统计单词的词频)。这里我们将要输入的单词文本input.txt和Python脚本放到/home/data/python/WordCount目录下。
cd /home/data/python/WordCount
vi input.txt
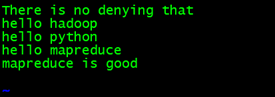
输入:
There is no denying that
hello python
hello mapreduce
mapreduce is good
二、编写Map代码
这里我们创建一个mapper.py脚本,从标准输入(stdin)读取数据,默认以空格分隔单词,然后按行输出单词机器词频到标准输出(stdout),整个Map处理过程不会统计每个单词出现的总次数,而是直接输出“word 1”,以便作为Reduce的输入进行统计,确保该文件是可执行的(chmod +x /home/data/python//WordCount/mapper.py)。
cd /home/data/python//WordCount
vi mapper.py
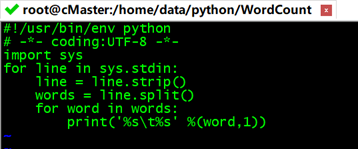
#!/usr/bin/env python
# -*- coding:UTF-8 -*-
import sys
for line in sys.stdin: #sys.stdin为读取数据,遍历读入数据的每一行
line = line.strip() #删除开头和结尾的空格
words = line.split() #以默认空格分隔行单词到words列表
for word in words:
#输出所有单词,格式为“单词,1”以便作为Reduce的输入
print('%s\t%s' %(word,1))
#截图如下:
三、编写Reduce代码
这里我们创建一个reducer.py脚本,从标准输入(stdin)读取mapper.py的结果,然后统计每个单词出现的总次数并输出到标准输出(stdout),
确保该文件是可执行的(chmod +x /home/data/python//WordCount/reducer.py)
cd /home/data/python//WordCount
vi reducer.py
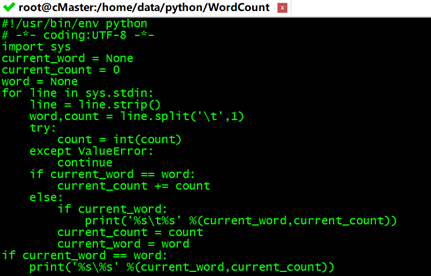
#!/usr/bin/env python
# -*- coding:UTF-8 -*-
import sys
current_word = None #当前单词
current_count = 0 #当前单词频数
word = None
for line in sys.stdin:
line = line.strip() #删除开头和结尾的空格
#解析mapper.py输出作为程序的输入,以tab作为分隔符
word,count = line.split('\t',1)
try:
count = int(count) #转换count从字符型为整型
except ValueError:
continue
#要求mapper.py的输出做排序操作,以便对连接的word做判断,hadoop会自动排序
if current_word == word: #如果当前的单词等于读入的单词
current_count += count #单词频数加1
else:
if current_word: #如果当前的单词不为空则打印其单词和频数
print('%s\t%s' %(current_word,current_count))
current_count = count #否则将读入的单词赋值给当前单词,且更新频数
current_word = word
if current_word == word #输出最后一个word统计
print('%s\%s' %(current_word,current_count))
#截图如下:
四、本地测试代码
我们可以在Hadoop平台运行之前在本地测试,校验mapper.py与reducer.py运行的结果是否正确。注意:测试reducer.py时需要对mapper.py的输出做排序(sort)操作,不过,Hadoop环境会自动实现排序。
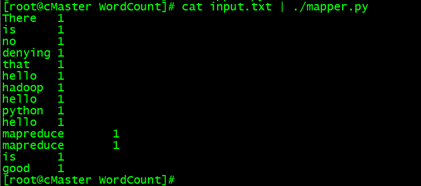
#在本地运行mapper.py:
cd /home/data/python/WordCount/
#记得执行: chmod +x /home/data/python//WordCount/mapper.py
cat input.txt | ./mapper.py
#在本地运行reducer.py
#记得执行:chmod +x /home/data/python//WordCount/reducer.py
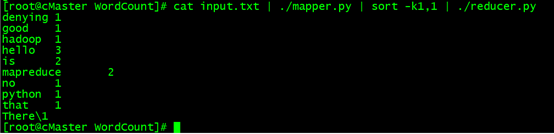
cat input.txt | ./mapper.py | sort -k1,1 | ./reducer.py
#这里注意:利用管道符“|”将输出数据作为mapper.py这个脚本的输入数据,并将mapper.py的数据输入到reducer.py中,其中参数sort -k 1,1是将reducer的输出内容按照第一列的第一个字母的ASCII码值进行升序排序。
五、在Hadoop平台上运行代码
在hadoop运行代码,前提是已经搭建好hadoop集群
1、创建目录并上传文件
首先在HDFS上创建文本文件存储目录,这里我创建为:/WordCound
hdfs dfs -mkdir /WordCound
#将本地文件input.txt上传到hdfs的/WordCount上。
hadoop fs -put /home/data/python/WordCount/input.txt /WordCount
hadoop fs -ls /WordCount #查看在hdfs中/data/WordCount目录下的内容
2、执行MapReduce程序
为了简化我们执行Hadoop MapReduce的命令,我们可以将Hadoop的hadoop-streaming-3.0.0.jar加入到系统环境变量/etc/profile中,在/etc/profile文件中添加如下配置:
首先在配置里导入hadoop-streaming-3.0.0.jar
vi /etc/profile
HADOOP_STREAM=$HADOOP_HOME/share/hadoop/tools/lib/hadoop-streaming-3.0.0.jar
export HADOOP_STREAM
source /etc/profile #刷新配置
#执行以下命令:
hadoop jar $HADOOP_STREAM -file /home/data/python/WordCount/mapper.py -mapper ./mapper.py -file /home/data/python/WordCount/reducer.py -reducer ./reducer.py -input /WordCount -output /output/word1
得到:

然后,输入以下命令查看结果:
hadoop fs -ls /output/word1
hadoop fs -cat /output/word1/part-00000 #查看分析结果
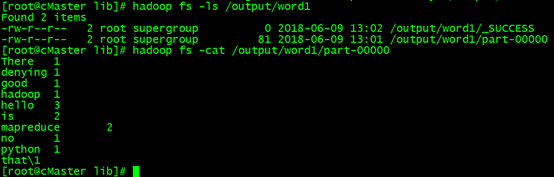
可以发现,结果与之前测试的时候是一致的,那么恭喜你,大功告成!
在Hadoop上用Python实现WordCount的更多相关文章
- 通过hadoop上的hive完成WordCount
1.启动hadoop 打开所有命令:start-all.sh 2.Hdfs上创建文件夹 创建名为PGOne到user/hadoop 3.上传文件至hdfs 创建和修改508.txt文件,里面尽量多写一 ...
- 让python在hadoop上跑起来
duang~好久没有更新博客啦,原因很简单,实习啦-好吧,我过来这边上班表示觉得自己简直弱爆了.第一周,配置环境:第二周,将数据可视化,包括学习了excel2013的一些高大上的技能,例如数据透视表和 ...
- hadoop学习笔记——用python写wordcount程序
尝试着用3台虚拟机搭建了伪分布式系统,完整的搭建步骤等熟悉了整个分布式框架之后再写,今天写一下用python写wordcount程序(MapReduce任务)的具体步骤. MapReduce任务以来H ...
- Hadoop实战3:MapReduce编程-WordCount统计单词个数-eclipse-java-ubuntu环境
之前习惯用hadoop streaming环境编写python程序,下面总结编辑java的eclipse环境配置总结,及一个WordCount例子运行. 一 下载eclipse安装包及hadoop插件 ...
- 在Hadoop平台跑python脚本
1.开发IDE,我使用的是PyCharm. 2.运行原理 使用python写MapReduce的“诀窍”是利用Hadoop流的API,通过STDIN(标准输入).STDOUT(标准输出)在 ...
- Hadoop入门实践之从WordCount程序说起
这段时间需要学习Hadoop了,以前一直听说Hadoop,但是从来没有研究过,这几天粗略看完了<Hadoop实战>这本书,对Hadoop编程有了大致的了解.接下来就是多看多写了.以Hado ...
- Hadoop上的中文分词与词频统计实践 (有待学习 http://www.cnblogs.com/jiejue/archive/2012/12/16/2820788.html)
解决问题的方案 Hadoop上的中文分词与词频统计实践 首先来推荐相关材料:http://xiaoxia.org/2011/12/18/map-reduce-program-of-rmm-word-c ...
- hadoop上C++开发两种方式的例子
百度在使用Hadoop过程中同样发现了Hadoop因为Java语言带来的低效问题,并对Hadoop进行扩展. 而在此之前,百度也尝试了 Hadoop PIPES 和 Hadoop Streamming ...
- 【Big Data - Hadoop - MapReduce】初学Hadoop之图解MapReduce与WordCount示例分析
Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算. HDFS是Google File System(GFS) ...
随机推荐
- 章节十六、9-Listeners监听器
一.IInokedMethodListener 1.实现一个类来监听testcase的运行情况. package listenerspackage; import org.testng.IInvoke ...
- 使用 Docker 安装 showdoc
一.简介 ShowDoc 是一个非常适合IT团队在线共享文档的工具,在线访问地址为:https://www.showDoc.cc 本来也可以直接 pull showdoc 镜像到本地,使用 docke ...
- php数据提交POSt
通常情况下用户使用浏览器网页表单向服务器post提交数据,我们使用PHP的$_POST接收用户POST到服务器的数据,并进行适当的处理.但有些情况下,如用户使用客户端软件向服务端php程序发送post ...
- pt-table-sync 配合pt-table-checksum 修复主从不一致
pt-table-sync 配合pt-table-checksum 修复主从不一致. 先执行下面这条语句,打印出要执行的命令,确认无误后再将 --print 改为 --execute 执行.注意 ...
- LoadRuuner资源监控
用ipconfig命令查看IP地址的具体方法.初级工程师面试常面临的问题:网址:http://url.cn/5BaDWvB本机IP:172.0.0.1localhostipconfig命令c查看本机I ...
- .NetCore技术研究-一套代码同时支持.NET Framework和.NET Core
在.NET Core的迁移过程中,我们将原有的.NET Framework代码迁移到.NET Core.如果线上只有一个小型的应用还好,迁移升级完成后,只需要维护.NET Core这个版本的代码. 但 ...
- 从二叉查找树到B+树中间的各种树
高强度训练第十八天总结: 二叉查找树: 二叉查找树就是左结点小于根节点,右结点大于根节点的一种排序树,也叫二叉搜索树.也叫BST,英文Binary Sort Tree. 就长下面这吊样 查找步骤 在二 ...
- 多tomcat服务和nginx负载均衡配置
1.nginx服务安装及配置,详见:linux 配置之安装nginx 2.多个tomcat服务安装及配置,详见:linux 配置多个tomcat 3.关键配置nginx.conf文件 http { i ...
- MangoDB的下载和安装
前面已经简单介绍了MongoDB,今天我们就要正式学习他了,话不多说,咱先来安装. 1.现在MongoDB已经到了4.0版本,咱先去官网下载,MongoDB官网传送门,下载的版本信息如下,点击Do ...
- php常用操作(第二版)
1.多个字段多重排序 function sortArrByManyField(){ $args = func_get_args(); // 获取函数的参数的数组 if(empty($args)){ r ...