总结关于CPU的一些基本知识
关于CPU和程序的执行
CPU是计算机的大脑。
- 程序的运行过程,实际上是程序涉及到的、未涉及到的一大堆的指令的执行过程。
当程序要执行的部分被装载到内存后,CPU要从内存中取出指令,然后指令解码(以便知道类型和操作数,简单的理解为CPU要知道这是什么指令),然后执行该指令。再然后取下一个指令、解码、执行,以此类推直到程序退出。 - 这个取指、解码、执行三个过程构成一个CPU的基本周期。
每个CPU都有一套自己可以执行的专门的指令集(注意,这部分指令是CPU提供的,CPU-Z软件可查看)。
正是因为不同CPU架构的指令集不同,使得x86处理器不能执行ARM程序,ARM程序也不能执行x86程序。
注:指令集的软硬件层次之分:硬件指令集是硬件层次上由CPU自身提供的可执行的指令集合。软件指令集是指语言程序库所提供的指令,只要安装了该语言的程序库,指令就可以执行。- 由于CPU访问内存以得到指令或数据的时间要比执行指令花费的时间长很多,因此在CPU内部提供了一些用来保存关键变量、临时数据等信息的通用寄存器。
所以,CPU需要提供 一些特定的指令,使得可以从内存中读取数据存入寄存器以及可以将寄存器数据存入内存。 - 除了通用寄存器,还有一些特殊的寄存器。典型的如:
- PC:program counter,表示程序计数器,它保存了将要取出的下一条指令的内存地址,指令取出后,就会更新该寄存器指向下一条指令。
- 堆栈指针:指向内存当前栈的顶端,包含了每个函数执行过程的栈帧,该栈帧中保存了该函数相关的输入参数、局部变量、以及一些没有保存在寄存器中的临时变量。
- PSW:program status word,表示程序状态字,这个寄存器内保存了一些控制位,比如CPU的优先级、CPU的工作模式(用户态还是内核态模式)等。
- 在CPU进行进程切换的时候,需要将寄存器中和当前进程有关的状态数据写入内存对应的位置(内核中该进程的栈空间)保存起来,当切换回该进程时,需要从内存中拷贝回寄存器中。即上下文切换时,需要保护现场和恢复现场。
- 为了改善性能,CPU已经不是单条
取指-->解码-->执行的路线,而是分别为这3个过程分别提供独立的取值单元,解码单元以及执行单元。这样就形成了流水线模式。
例如,流水线的最后一个单元——执行单元正在执行第n条指令,而前一个单元可以对第n+1条指令进行解码,再前一个单元即取指单元可以去读取第n+2条指令。这是三阶段的流水线,还可能会有更长的流水线模式。 - 更优化的CPU架构是superscalar架构(超标量架构)。这种架构将取指、解码、执行单元分开,有大量的执行单元,然后每个取指+解码的部分都以并行的方式运行。比如有2个取指+解码的并行工作线路,每个工作线路都将解码后的指令放入一个缓存缓冲区等待执行单元去取出执行。
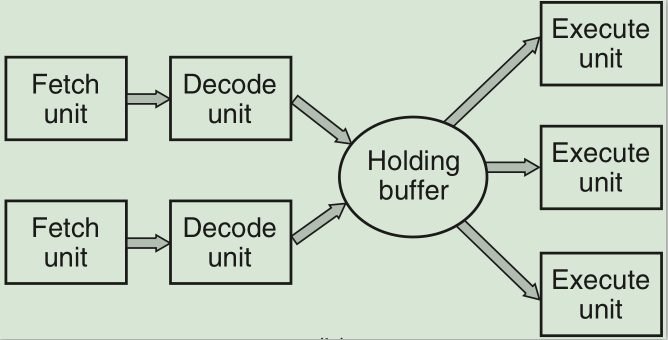
- 除了嵌入式系统,多数CPU都有两种工作模式:内核态和用户态。这两种工作模式是由PSW寄存器上的一个二进制位来控制的。
- 内核态的CPU,可以执行指令集中的所有指令,并使用硬件的所有功能。
- 用户态的CPU,只允许执行指令集中的部分指令。一般而言,IO相关和把内存保护相关的所有执行在用户态下都是被禁止的,此外其它一些特权指令也是被禁止的,比如用户态下不能将PSW的模式设置控制位设置成内核态。
- 用户态CPU想要执行特权操作,需要发起系统调用来请求内核帮忙完成对应的操作。其实是在发起系统调用后,CPU会执行trap指令陷入(trap)到内核。当特权操作完成后,需要执行一个指令让CPU返回到用户态。
除了系统调用会陷入内核,更多的是硬件会引起trap行为陷入内核,使得CPU控制权可以回到操作系统,以便操作系统去决定如何处理硬件异常。

关于CPU的多核和多线程
- CPU的物理个数由主板上的插槽数量决定,每个CPU可以有多核心,每核心可能会有多线程。
- 多核CPU的每核(每核都是一个小芯片),在OS看来都是一个独立的CPU。
- 对于超线程CPU来说,每核CPU可以有多个线程(数量是两个,比如1核双线程,2核4线程,4核8线程),每个线程都是一个虚拟的逻辑CPU(比如windows下是以逻辑处理器的名称称呼的),而每个线程在OS看来也是独立的CPU。
这是欺骗操作系统的行为,在物理上仍然只有1核,只不过在超线程CPU的角度上看,它认为它的超线程会加速程序的运行。
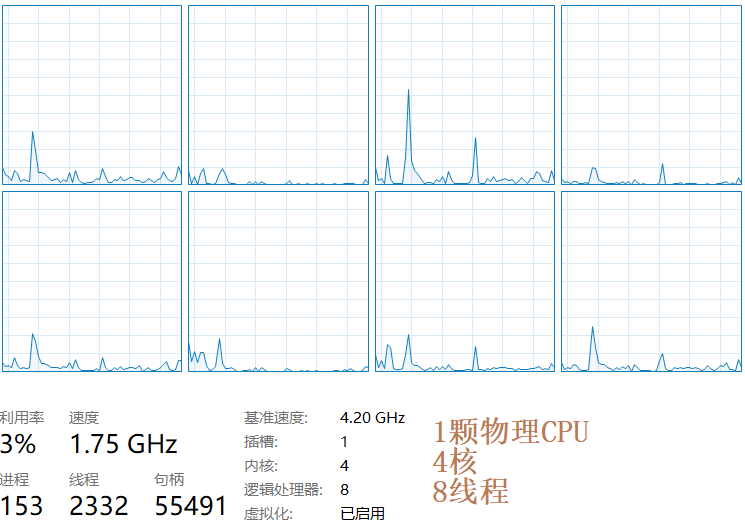
- 要发挥超线程优势,需要操作系统对超线程有专门的优化。
- 多线程的CPU在能力上,比非多线程的CPU核心要更强,但每个线程不足以与独立的CPU核心能力相比较。
- 每核上的多线程CPU都共享该核的CPU资源。
例如,假设每核CPU都只有一个"发动机"资源,那么线程1这个虚拟CPU使用了这个"发动机"后,线程2就没法使用,只能等待。
所以,超线程技术的主要目的是为了增加流水线(参见前文对流水线的解释)上更多个独立的指令,这样线程1和线程2在流水线上就尽量不会争抢该核CPU资源。所以,超线程技术利用了superscalar(超标量)架构的优点。 - 多线程意味着每核可以有多个线程的状态。比如某核的线程1空闲,线程2运行。
- 多线程没有提供真正意义上的并行处理,每核CPU在某一时刻仍然只能运行一个进程,因为线程1和线程2是共享某核CPU资源的。可以简单的认为每核CPU在独立执行进程的能力上,有一个资源是唯一的,线程1获取了该资源,线程2就没法获取。
但是,线程1和线程2在很多方面上是可以并行执行的。比如可以并行取指、并行解码、并行执行指令等。所以虽然单核在同一时间只能执行一个进程,但线程1和线程2可以互相帮助,加速进程的执行。
并且,如果线程1在某一时刻获取了该核执行进程的能力,假设此刻该进程发出了IO请求,于是线程1掌握的执行进程的能力,就可以被线程2获取,即切换到线程2。这是在执行线程间的切换,是非常轻量级的。(WIKI: if resources for one process are not available, then another process can continue if its resources are available) - 多线程可能会出现一种现象:假如2核4线程CPU,有两个进程要被调度,那么只有两个线程会处于运行状态,如果这两个线程是在同一核上,则另一核完全空转,处于浪费状态。更期望的结果是每核上都有一个CPU分别调度这两个进程。
CPU上的高速缓存
- 最高速的缓存是CPU的寄存器,它们和CPU的材料相同,最靠近CPU或最接近CPU,访问它们没有时延(<1ns)。但容量很小,小于1kb。
- 32bit:32*32比特=128字节
- 64bit:64*64比特=512字节
- 寄存器之下,是CPU的高速缓存。分为L1缓存、L2缓存、L3缓存,每层速度按数量级递减、容量也越来越大。
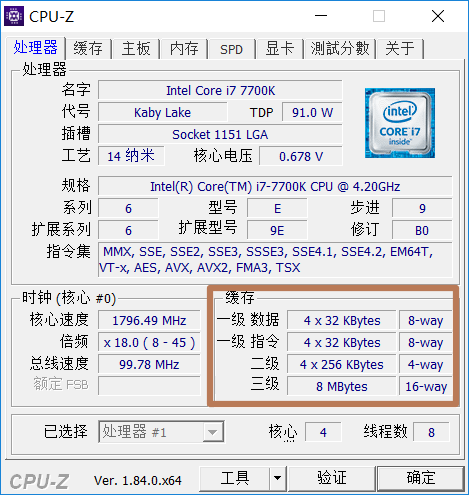
- 每核心都有一个自己的L1缓存。L1缓存分两种:L1指令缓存(L1-icache)和L1数据缓存(L1-dcache)。L1指令缓存用来存放已解码指令,L1数据缓存用来放访问非常频繁的数据。
- L2缓存用来存放近期使用过的内存数据。更严格地说,存放的是很可能将来会被CPU使用的数据。
总结关于CPU的一些基本知识的更多相关文章
- CPU工作状态的知识介绍
转自:http://www.bbwxbbs.com/forum.php?mod=viewthread&tid=2552 近几年,个人计算机的运行速度有了质的飞跃,但是功耗却没能与时俱进,着 ...
- CPU的高速缓存存储器知识整理
基于缓存的存储器层次结构 基于缓存的存储器层次结构行之有效,是因为较慢的存储设备比较快的存储设备更便宜,还因为程序往往展示局部性: 时间局部性:被引用过一次的存储器的位置很可能在不远的将来被再次引用. ...
- CPU与GPU基础知识与品牌
1 CPU信息 ubuntu系统: lscpu 序号 属性 描述 1 架构 x86_64 2 CPU 运行模式 32-bit, 64-bit 3 字节序 Little Endian 4 CPU内核数量 ...
- 电路相关知识--读<<继电器是如何成为CPU的>>
电路相关知识–读<<继电器是如何成为CPU的>> */--> *///--> *///--> 电路相关知识–读<<继电器是如何成为CPU的> ...
- 关于CPU Cache -- 程序员需要知道的那些事
本文将介绍一些作为程序猿或者IT从业者应该知道的CPU Cache相关的知识.本章从"为什么会有CPU Cache","CPU Cache的大致设计架构",&q ...
- 关于CPU Cache -- 程序猿需要知道的那些事
本文将介绍一些作为程序猿或者IT从业者应该知道的CPU Cache相关的知识 文章欢迎转载,但转载时请保留本段文字,并置于文章的顶部 作者:卢钧轶(cenalulu) 本文原文地址:http://ce ...
- [转帖]关于CPU Cache -- 程序猿需要知道的那些事
关于CPU Cache -- 程序猿需要知道的那些事 很早之前读过作者的blog 记得作者在facebook 工作.. 还写过mysql相关的内容 大拿 本文将介绍一些作为程序猿或者IT从业者应该知道 ...
- Linux下查看CPU信息[/proc/cpuinfo]
最近在研究linux系统负载的时候,接触到一些关于CPU信息查看的知识,和大家分享一下.通过对/proc/cpuinfo文件中的参数的分析,也学到了不少东西. 在linux操作系统中,CPU的信息在启 ...
- 关于High CPU及基本排查
在实际的网络中,总会存在设备出现high CPU的情况,这种情况下,往往会让网络管理员比较着急,因为如果CPU持续high,可能导致设备的性能降低,严重还可能导致设备down掉. 本篇记录,主要记录一 ...
随机推荐
- WPF绘制深度不同颜色的3D模型填充图和线框图
原文:WPF绘制深度不同颜色的3D模型填充图和线框图 在机械测量过程中,测量的数据需要进行软件处理.通常测量一个零件之后,需要重建零件的3D模型,便于观察测量结果是否与所测工件一致. 重建的3D模型需 ...
- String 源码分析
Java 源码阅读 - String String 类型看起来简单,实际上背后的复杂性基本可以涵盖了整个 Java 设计,涉及到设计模式(不可变对象).缓存(String Pool 的理念).JVM( ...
- jquery获取选中的值和设置单选扭选中
<!DOCTYPE html><html><head><meta http-equiv="Content-Type" content=&q ...
- liunx 查看php 安装的扩展
/usr/local/php5/bin/php -i |less 查看配置文件在哪里,编译参数 /usr/local/php5/bin/php -m |less 查看php加载的模块
- Android项目实战(四十):在线生成按钮Shape的网站
原文:Android项目实战(四十):在线生成按钮Shape的网站 AndroidButton Make 右侧设置按钮的属性,可以即时看到效果,并即时生成对应的.xml 代码,非常高效(当然熟练的话 ...
- 深入理解SQL Server 2005 中的 COLUMNS_UPDATED函数
原文:深入理解SQL Server 2005 中的 COLUMNS_UPDATED函数 概述 COLUMNS_UPDATED函数能够出现在INSERT或UPDATE触发器中AS关键字后的任何位置,用来 ...
- 未在本地计算机上注册“microsoft.ACE.oledb.12.0” 解决方法
今日写一个浏览Excel文件的代码,忽然发现提示如下错误,表示很惊讶,因为我的另外一台电脑不会,但是这台就包这个异常. 解决方法: 去http://download.microsoft.com/dow ...
- oracle解析
Oracle数据库中的CURSOR分为两种类型:Shared Cursor 和 Session Cursor 1,Shared Cursor Oracle里的第一种类型的Cursor就是Shared ...
- 为新项目添彩的 10+ 超有用 JavaScript 库
快速使用Romanysoft LAB的技术实现 HTML 开发Mac OS App,并销售到苹果应用商店中. <HTML开发Mac OS App 视频教程> 土豆网同步更新:http: ...
- 【Qt】无边框窗体中带有ActiveX组件时的一个BUG
无意中发现的一个BUG,Qt5.1.1正式版首先创建一个GUI工程,拖入一个QAxWidget控件(为了使ActiveX生效,需要在.pro文件中加入CONFIG += qaxcontainer)接着 ...