【Java源码】集合类-JDK1.8 哈希表-红黑树-HashMap总结
JDK 1.8 HashMap是数组+链表+红黑树实现的,在阅读HashMap的源码之前先来回顾一下大学课本数据结构中的哈希表和红黑树。
什么是哈希表?
- 在存储结构中,关键值key通过一种关系f和唯一的存储位置相对应,关系f即哈希函数,Hash(k)=f(k)。按这个思想建立的表就是哈希表。
- 当有两个不相等的关键字key1和key2,但f(key1)=f(key2)这两个key地址相同,就发生了冲突现象。
- 冲突不能避免只能减少,通过设计均匀的哈希函数来减少。
常用哈希函数?
1. 直接定址法
Hash(key) = a*key + b (a,b为常数)
取关键字的某种线性关系,实际中使用较少。
2. 初留余数法
Hash(key) = key mod p (p,整数)
即关键字key除以p的余数作为地址。
3.数字分析法,平方取中法,折叠法
处理冲突的方法?
处理冲突就是为这个关键字找到另一个空的哈希地址。
1.开放地址法
- 线性探测法
- 二次探测法
- 双哈希函数探测法
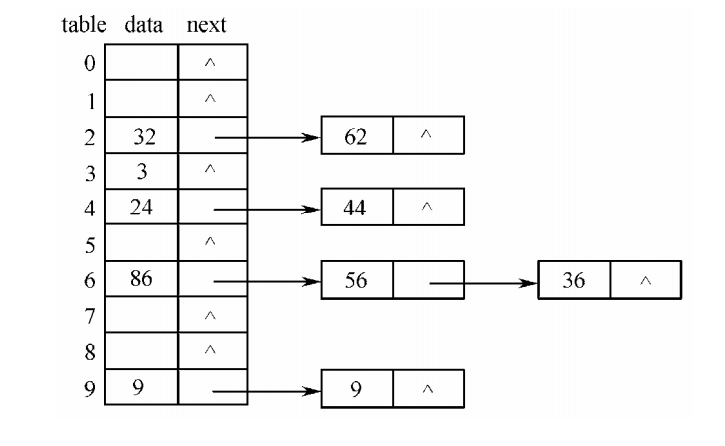
2.拉链法
- 拉链法的基本思想是,根据关键字k,将数据元素存放在哈希基表中的i=hash(k)位置上。如果产生冲突,则创建一个结点存放该数据元素,并将该结点插入到一个链表中。这种由冲突的数据元素构成的链表称为哈希链表。一个哈希基表与若干条哈希链表相连。
- 例如,对于如下的关键字序列:{9,9,24,44,32,86,36,3,62,56}
设哈希函数 hash(k) = k % 10,hash(k)对应哈希基表 table 的下标值 i,采用拉链法的哈希表结构如图:
红黑树
红黑树本质上就是一棵二叉查找树(二叉排序树),红黑树的查找、插入、删除的时间复杂度最坏为O(log n)。
什么是二叉查找树(二叉排序树)?
二叉查找树(Binary Search Tree)也就是二叉排序树。特征性质:
- 任意结点的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 任意结点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 左、右子树也为二叉查找树。
- 按中序遍历可以得到有序序列。
什么是红黑树?
维基百科定义:https://zh.wikipedia.org/wiki/%E7%BA%A2%E9%BB%91%E6%A0%91
红黑树(英语:Red–black tree)是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,典型的用途是实现关联数组。它在1972年由鲁道夫·贝尔发明,被称为"对称二叉B树",它现代的名字源于Leo J. Guibas和Robert Sedgewick于1978年写的一篇论文。红黑树的结构复杂,但它的操作有着良好的最坏情况运行时间,并且在实践中高效:它可以在log n时间内完成查找,插入和删除,这里的n是树中元素的数目。
特征性质:
- 节点是红色或黑色。
- 根结点是黑的。
- 所有叶子都是黑色(叶子是NIL节点)。
- 每个红色节点必须有两个黑色的子节点。(从每个叶子到根的所有路径上不能有两个连续的红色节点。)
- 对于任一结点而言,其到叶结点的每一条路径都包含相同数目的黑结点

JDK 1.8 Map接口
public interface Map<K,V> {
int size(); //返回Map中键值对的个数
boolean isEmpty(); //检查map是否为空
boolean containsKey(Object key); //查看map是否包含某个键
boolean containsValue(Object value); //查看map是否包含某个值
V put(K key, V value); //保存,若原来有这个key则覆盖并返回原来的值
V get(Object key); //根据key获取值, 若没找到,则返回null
V remove(Object key); //根据key删除, 返回key原来的值,若不存在,则返回null
void putAll(Map<? extends K, ? extends V> m); //将m中的所有键值对到当前的Map
void clear(); //清空Map
Set<K> keySet(); //返回Map中所有键
Collection<V> values(); //返回Map中所有值
Set<Map.Entry<K, V>> entrySet(); //返回Map中所有键值对
//内部接口,表示一个键值对
interface Entry<K,V> {
K getKey(); //返回键
V getValue(); //返回值
V setValue(V value); //setvalue
}
}
HashMap特点
- 根据键的hashCode值存储数据,大多数情况下可以直接定位到它的值,因而具有很快的访问速度,但遍历顺序却是不确定的。
- HashMap最多只允许一条记录的键为null,允许多条记录的值为null。
- HashMap非线程安全,即任一时刻可以有多个线程同时写HashMap,可能会导致数据的不一致。如果需要满足线程安全,可以用Collections的synchronizedMap方法使HashMap具有线程安全的能力,或者使用ConcurrentHashMap。
- 负载因子可以修改,也可以大于1,建议不要轻易修改,除非特殊情况。
内部数据结构:
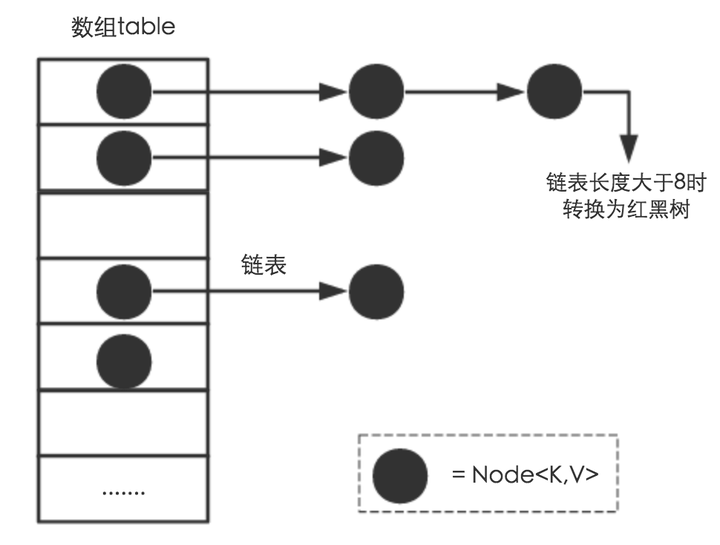
HashMap 类属性
transient Node<k,v>[] table; 这个类属性就是哈希桶数组
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
// 序列号
private static final long serialVersionUID = 362498820763181265L;
// 默认的初始容量是16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 默认的负载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 当桶(bucket)上的结点数大于这个值时会转成红黑树
static final int TREEIFY_THRESHOLD = 8;
// 当桶(bucket)上的结点数小于这个值时树转链表
static final int UNTREEIFY_THRESHOLD = 6;
// 桶中结构转化为红黑树对应的table的最小大小
static final int MIN_TREEIFY_CAPACITY = 64;
// 存储元素的数组,总是2的幂次倍(哈希桶数组)
transient Node<k,v>[] table;
// 存放具体元素的集
transient Set<map.entry<k,v>> entrySet;
// 存放元素的个数,注意这个不等于数组的长度。
transient int size;
// 每次扩容和更改map结构的计数器
transient int modCount;
// 临界值 当实际大小(容量*填充因子)超过临界值时,会进行扩容
int threshold;
// 负载因子
final float loadFactor;
}
内部类Node
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
......
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
....
}
public final boolean equals(Object o) {
......
}
}
构造函数
- 无参构造函数默认长度16,负载因子0.75
/**
* Constructs an empty <tt>HashMap</tt> with the default initial capacity
* (16) and the default load factor (0.75).
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
- 指定容量,负载因子0.75
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
- 指定容量和指定负载因子
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
重要函数
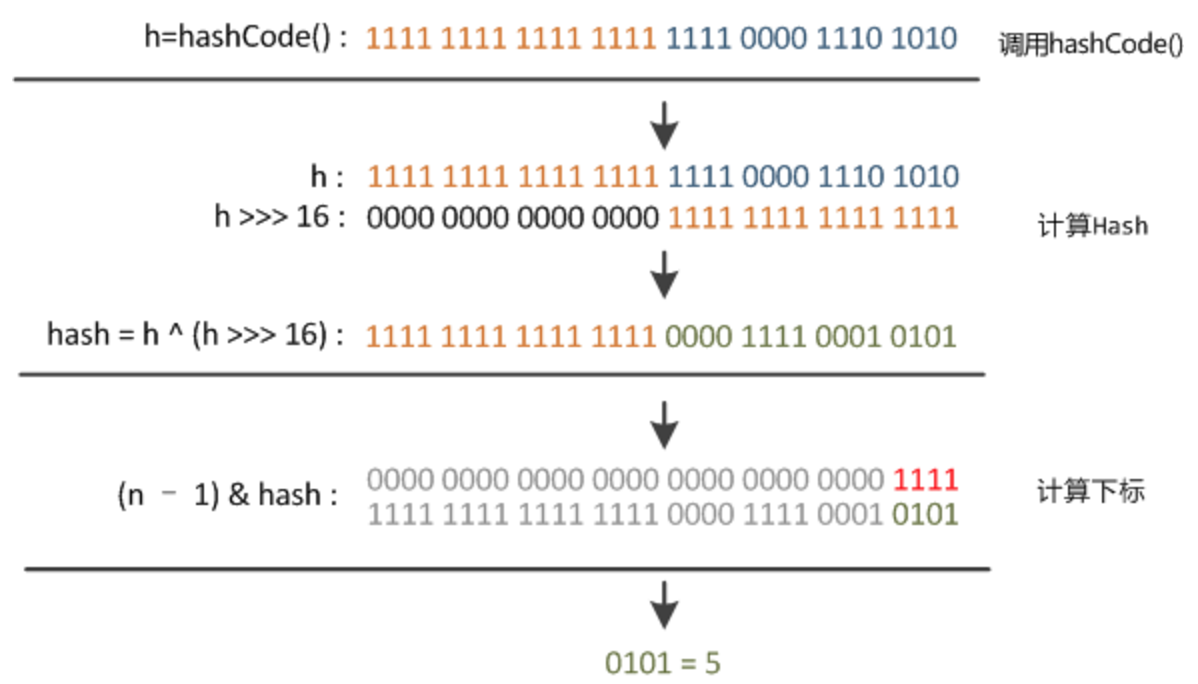
内部hash方法(获得的hash值用于putVal方法中确定哈希桶数组索引位置)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- 第一步调用object的hashCode:h = key.hashCode() 取hashCode值
- h ^ (h >>> 16) 首先进行无符号右移(>>>)运算,再通过异或运算(^)得到hash值。
put方法,put内部调用的是putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
//首先确定table是不是为空,如果为空进行扩容
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//取模运算,确定哈希桶数组索引位置
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//节点key存在,直接覆盖value
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//判断是否是红黑树
else if (p instanceof TreeNode)
//如果是红黑树,则直接在树中插入键值对
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
//为链表
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//判断链表长度是否大于8,大于8把链表转换为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//key已经存在直接覆盖value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
- i = (n - 1) & hash;通过取模运算,确定哈希桶数组索引位置。位运算(&)效率要比取模运算(%)高很多,主要原因是位运算直接对内存数据进行操作,不需要转成十进制,因此处理速度非常快。
注意:a % b == a & (b - 1) 前提:b 为 2^n
- 下面是hash到确定数组位置的过程图:
HashMap 如何进行扩容
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 超过最大值就不再扩充
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 没超过最大值,扩充为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的resize上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
// 把每个bucket都移动到新的buckets中
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
// 链表优化重hash的代码块
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 原索引
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// 原索引+oldCap
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// 原索引放到bucket里
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// 原索引+oldCap放到bucket里
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
注意事项
扩容是一个特别耗性能的操作,所以当使用HashMap的时候,估算map的大小,初始化的时候给一个大致的数值,避免map进行频繁的扩容。
参考:
- JDK1.8 源码
- 《数据结构与算法》
- 维基百科
- 美团:Java 8系列之重新认识HashMap
【Java源码】集合类-JDK1.8 哈希表-红黑树-HashMap总结的更多相关文章
- 菜鸟nginx源码剖析数据结构篇(四)红黑树ngx_rbtree_t[转]
菜鸟nginx源码剖析数据结构篇(四)红黑树ngx_rbtree_t Author:Echo Chen(陈斌) Email:chenb19870707@gmail.com Blog:Blog.csdn ...
- Java HashMap源码分析(含散列表、红黑树、扰动函数等重点问题分析)
写在最前面 这个项目是从20年末就立好的 flag,经过几年的学习,回过头再去看很多知识点又有新的理解.所以趁着找实习的准备,结合以前的学习储备,创建一个主要针对应届生和初学者的 Java 开源知识项 ...
- 死磕Java之聊聊HashSet源码(基于JDK1.8)
HashSet的UML图 HashSet的成员变量及其含义 public class HashSet<E> extends AbstractSet<E> implements ...
- 死磕Java之聊聊HashMap源码(基于JDK1.8)
死磕Java之聊聊HashMap源码(基于JDK1.8) http://cmsblogs.com/?p=4731 为什么面试要问hashmap 的原理
- 深入Java源码剖析之Set集合
Java的集合类由Collection接口和Map接口派生,其中: List代表有序集合,元素有序且可重复 Set代表无序集合,元素无序且不可重复 Map集合存储键值对 那么本篇文章将从源码角度讨论一 ...
- Java源码解读(一)——HashMap
HashMap作为常用的一种数据结构,阅读源码去了解其底层的实现是十分有必要的.在这里也分享自己阅读源码遇到的困难以及自己的思考. HashMap的源码介绍已经有许许多多的博客,这里只记录了一些我看源 ...
- 【java集合框架源码剖析系列】java源码剖析之HashSet
注:博主java集合框架源码剖析系列的源码全部基于JDK1.8.0版本.本博客将从源码角度带领大家学习关于HashSet的知识. 一HashSet的定义: public class HashSet&l ...
- 【java集合框架源码剖析系列】java源码剖析之HashMap
前言:之所以打算写java集合框架源码剖析系列博客是因为自己反思了一下阿里内推一面的失败(估计没过,因为写此博客已距阿里巴巴一面一个星期),当时面试完之后感觉自己回答的挺好的,而且据面试官最后说的这几 ...
- Java源码系列2——HashMap
HashMap 的源码很多也很复杂,本文只是摘取简单常用的部分代码进行分析.能力有限,欢迎指正. HASH 值的计算 前置知识--位运算 按位异或操作符^:1^1=0, 0^0=0, 1^0=0, 值 ...
随机推荐
- HDU-4432-Sum of divisors ( 2012 Asia Tianjin Regional Contest )
Sum of divisors Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) ...
- Virtualization of iSCSI storage
This invention describes methods, apparatus and systems for virtualization of iSCSI storage. Virtual ...
- VirtualBox虚拟机网络环境Host-Only(对Win10和VirtualBox都有截图)
之前在选择配置虚拟机网络环境的时候 桥接也是不错的,但是自己在使用的时候由于访问频繁会出现断网现象.所以就开始使用Host-Only模式.开始并不是很明白为什么这么设置,也挖了很多坑.经常出现虚拟机无 ...
- intel edison with grove lcd
由intel xdk,例如,下面的过程能够打印Hello world至grove lcd上 var mraa = require ('mraa'); var LCD = require ('jsupm ...
- js -- 捆绑
1.环境配置 主要參考网址: http://cocos2d.cocoachina.com/bbs/forum.php?mod=viewthread&tid=10226&extra=pa ...
- ImageNet 数据集
1. top-5 error rate ImageNet 图像通常有 1000 个可能的类别,对每幅图像你可以猜 5 次结果(即同时预测5个类别标签),当其中有任何一次预测对了,结果都算对(事实上一个 ...
- SIIA CODIE AWARDS 2017
Business Technology Best Advertising or Campaign Management Platform Albert, Albert Choozle, Choozle ...
- Android blueZ HCI(一个):hciconfig实施和经常使用
关键词:hciconfighcitool hcidump笔者:xubin341719(欢迎转载,请明确说明,请尊重版权,谢谢.)欢迎指正错误,共同学习.共同进步! . Android blueZ H ...
- Nucleus PLUS系统架构和组件
(一个)方法论和软件组件 1.软件组件(Software Component)定义 从一般意义上来说.组件(Component)是系统中能够明白辨识的组成部分,一个不透明的功能实现体.软件开发中,组件 ...
- Delphi跨平台Socket通讯库
盒子中的souledge大侠发布了新的Socket库,以下为原文: 我之前写过一个iocp的框架,放到googlecode上了. 由于当时的delphi版本尚无法跨平台,所以该框架只能运行在Windo ...