基于Groovy搭建Ngrinder脚本调试环境
介绍
最近公司搭建了一套压力测试平台,引用的是开源的项目 Ngrinder,做了二次开发,在脚本管理方面,去掉官方的SVN,引用的是Git,其他就是做了熔断处理等。
对技术一向充满热情的我,必须先来拥抱下传说中的压测平台。
一、开发脚本环境配置项:
安装JDK1.7+,Git,Maven
二、新建一个maven项目
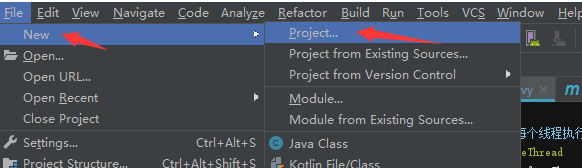




三、创建一个groovy脚本TestRunner.groovy,添加以下内容
这个脚本写的就是,向服务端发送Json 格式请求,比较简单,未涉及到上下文参数化,混合场景配置比例,方法介绍等,到时需要再写2篇专题
import HTTPClient.HTTPResponse
import HTTPClient.NVPair
import net.grinder.plugin.http.HTTPPluginControl
import net.grinder.plugin.http.HTTPRequest
import net.grinder.script.GTest
import net.grinder.scriptengine.groovy.junit.GrinderRunner
import net.grinder.scriptengine.groovy.junit.annotation.BeforeProcess
import net.grinder.scriptengine.groovy.junit.annotation.BeforeThread
import org.junit.Test
import org.junit.runner.RunWith
import static net.grinder.script.Grinder.grinder
import static org.hamcrest.Matchers.is
import static org.junit.Assert.assertThat
// 每个测试类加这注解
@RunWith(GrinderRunner)
class TestRunner{
public static GTest test
public static HTTPRequest request
// 在每个进程启动前执行
@BeforeProcess
static void beforeProcess() {
HTTPPluginControl.getConnectionDefaults().timeout = 8000
test = new GTest(1, "查询贷款数量")
request = new HTTPRequest()
grinder.logger.info("before process.");
}
// 在每个线程执行前执行
@BeforeThread
void beforeThread() {
//监听目标方法,如果打标不会生成该方法的报告
test.record(this,"loanCountTest");
// 延时生成报告
grinder.statistics.delayReports=true;
grinder.logger.info("before thread.");
}
private NVPair[] headers() {
return [
new NVPair("Content-type", "application/json;charset=UTF-8")
];
}
@Test
void loanCountTest(){
def json = "{\"uid\": \"1_1154249\"}";
HTTPResponse result = request.POST("http://hdai.com/query-loaning-count",json.getBytes(), headers());
grinder.logger.info(result.getText());
if (result.statusCode == 301 || result.statusCode == 302) {
grinder.logger.warn("Warning. The response may not be correct. The response code was {}.", result.statusCode);
} else {
assertThat("判断响应结果:",result.statusCode, is(200));
}
}
}
四、拷贝以下内容到新建的 pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>ngrinder</groupId>
<artifactId>loan-xx-perf</artifactId>
<version>0.0.1</version> <properties>
<ngrinder.version>3.4</ngrinder.version>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties> <repositories>
<repository>
<id>ngrinder.maven.repo</id>
<url>https://github.com/naver/ngrinder/raw/ngrinder.maven.repo/releases</url>
</repository>
<repository>
<id>ymm-central-cache</id>
<url>http://maven.aliyun.com/nexus/service/local/repositories/central/content/</url>
</repository>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.ngrinder</groupId>
<artifactId>ngrinder-groovy</artifactId>
<version>${ngrinder.version}</version>
<scope>provided</scope>
</dependency>
</dependencies> <build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<version>2.9</version>
<configuration>
<additionalProjectnatures>
<projectnature>
org.eclipse.jdt.groovy.core.groovyNature
</projectnature>
<projectnature>
org.eclipse.m2e.core.maven2Nature
</projectnature>
</additionalProjectnatures>
</configuration>
</plugin>
</plugins>
</build>
</project>
五、完成后,目录机构如下
resources资源目录下,不能为空,否则上传到 试压机跑压测会报错

六、运行报错处理


添加之后就可以运行成功

七、注意:
- 依赖jar 拉取很慢,有可能会出现超时,多尝试下
- 测试脚本必须是Ngrinder标准的Groovy Maven项目,所以 resources资源目录下,不能为空,我这里随便搞了个文件,服务端会校验目录结构
- 目录结构,maven引用等,可以参考Ngrinder官方的例子:https://github.com/naver/ngrinder/wiki/Groovy-Maven-Structure
八、使用感受:
从零开始搭建了一套本地的 脚本开发环境,我觉得还是特别的快,创建maven 自动引入依赖; 语言开发方面只要熟悉java,上手Groovy 很快就能编写脚本; 编写脚本不像Jmeter 或 loadrunner 那样有可视化界面,而是完全用代码来实现,还好的是它提供了很多的工具类,不用重复造轮子。
基于Groovy搭建Ngrinder脚本调试环境的更多相关文章
- 基于Groovy编写Ngrinder脚本常用方法
1.生成随机字符串(import org.apache.commons.lang.RandomStringUtils) 数字:RandomStringUtils.randomNumeric(lengt ...
- ok6410[002] ubuntu1604系统下搭配ckermit和dnw基于RAM的裸机程序调试环境
ubuntu1604系统下搭配ckermit和dnw基于RAM的裸机程序调试环境 系统: ubuntu16.04 裸板: 飞凌公司OK6410开发板 目标:搭建基于ubuntu1604系统和基于RA ...
- 基于Eclipse搭建Hadoop源码环境
Hadoop使用ant+ivy组织工程,无法直接导入Eclipse中.本文将介绍如何基于Eclipse搭建Hadoop源码环境. 准备工作 本文使用的操作系统为CentOS.需要的软件版本:hadoo ...
- Xcode搭建真机调试环境 图文实例
本文介绍的Xcode搭建真机调试环境 图文实例,图文并茂,使我们学习起来更方便些,我们先来看内容. AD: 2013云计算架构师峰会超低价抢票中 Xcode搭建真机调试环境 是本文要介绍的内容,不多说 ...
- vscode加MinGw三步搭建c/c++调试环境
vscode加MinGw三步搭建c/c++调试环境 step1:安装vscode.MinGw 1.1 vscod常规安装:https://code.visualstudio.com/ 1.2 MinG ...
- 通过模拟器和ida搭建Android动态调试环境的问题
这几天在学Android的native层逆向.在按照教程用ida搭建动态调试环境时,第一步是把android_server 放到手机里执行,但是在手机里可以,在genymotion模拟器上就提示 no ...
- 基于Visual Studio Code搭建Golang开发调试环境【非转载】
由于对Docker+kubernetes的使用及持续关注,要理解这个平台的原理,势必需要对golang有一定的理解,基于此开始利用业余时间学习go,基础语法看完之后,搭建开发环境肯定是第一步,虽然能g ...
- 搭建基于qemu + eclipse的kernel调试环境(by quqi99)
作者:张华 发表于:2016-02-06版权声明:能够随意转载.转载时请务必以超链接形式标明文章原始出处和作者信息及本版权声明 ( http://blog.csdn.net/quqi99 ) 使用q ...
- 微信开发 -- 搭建基于ngrok的微信本地调试环境
第一步,安装ngrok客户端 (1)首先先到官网下载个客户端 http://natapp.cn/,选择适合的客户端类型,本人选择的是windows版 (2)下载后,解压,可以看到如下目录: 第二步,开 ...
随机推荐
- asp.net core + layui.js 搭建仓储系统
先放几张网站图片: 第一步先从layui 网站https://www.layui.com/doc/ 下载相关文件,复制到项目 wwwroot 目录下: 然后在 _Layout.cshtml 中引用 l ...
- 如何免费使用GPU跑深度学习代码
从事深度学习的研究者都知道,深度学习代码需要设计海量的数据,需要很大很大很大(重要的事情说三遍)的计算量,以至于CPU算不过来,需要通过GPU帮忙,但这必不意味着CPU的性能没GPU强,CPU是那种综 ...
- 阿里云安装RocketMQ
说明: 我的阿里云是centos 6.9 jdk 1.8.0_192-b12(安装教程参照:https://www.cnblogs.com/kingsonfu/p/9801556.html) mave ...
- springboot + mybatis + mycat整合
1.mycat服务 搭建mycat服务并启动,windows安装参照. 系列文章: [Mycat 简介] [Mycat 配置文件server.xml] [Mycat 配置文件schema.xml] [ ...
- Mycat 配置文件server.xml
server.xml 几乎保存了所有 mycat 需要的系统配置信息. 1.system 标签: 该标签内嵌套的所有 property 标签都与系统配置有关. charset 属性: 该属性用于字符集 ...
- python爬虫遇到会话存储sessionStorage
记录一次爬虫生成链接过程中遇到的sessionStorage存储数据 1.简介 sessionStorage 是HTML5新增的一个会话存储对象,用于临时保存同一窗口(或标签页)的数据,在关闭窗口或标 ...
- LeetCode 题解汇总
前言 现如今,对于技术人员(软开.算法等)求职过程中笔试都是必不可少的(免笔试的除外,大部分人都需要笔试),而笔试一般组成都是选择.填空.简答题.编程题(这部分很重要),所以刷题是必不可少的:对于应届 ...
- 自适应布局display:-webkit-box的用法
在web布局中,我们经常使用的是display:inline-block,display:flex,这些,但其实在进行移动端设备自适应布局中,-webkit-box布局更加合适 不同的浏览器有不同的前 ...
- JQuery 源码解析 · extend()详解
前言:最近想重写一个dropdown插件,于是想到了使用jquey实现插件,于是重温了一波$.extend()的知识,然后总结了这篇笔记 正文: $.extend(src) jQuery.exten ...
- MongoDB 学习笔记之 检测存储引擎
检测存储引擎: db.serverStatus().storageEngine db.serverStatus().wiredTiger (转)WiredTiger测试结果 单纯写的测试结果 结论:W ...