mimalloc内存分配代码分析
这篇文章中我们会介绍一下mimalloc的实现,其中可能涉及上一篇文章提到的内容,如果不了解的可以先看下这篇mimalloc剖析。首先我们需要了解的是其整体结构,mimalloc的结构如下图所示

- small类型的segment的大小为4M,其负责分配大小小于MI_SMALL_SIZE_MAX的内存块,该segment中一个页的大小均为64KB,因此在一个segment中会包含多个页,每个页中会有多个块
- large类型的segment的大小为4M,其负责分配大小处于MI_SMALL_SIZE_MAX与MI_LARGE_SIZE_MAX之间的内存块,该segment中仅会有一个页,该页占据该segment的剩余所有空间,该页中会有多个块
- huge类型的segment,该类segment的负责分配大小大于MI_LARGE_SIZE_MAX的内存块,该类segment的大小取决于需要分配的内存的大小,该segment中也仅包含一个页,该页中仅会有一个块
struct mi_heap_s {
mi_tld_t* tld;
mi_page_t* pages_free_direct[MI_SMALL_WSIZE_MAX + ];
mi_page_queue_t pages[MI_BIN_FULL + ];
volatile mi_block_t* thread_delayed_free;
uintptr_t thread_id;
uintptr_t cookie;
uintptr_t random;
size_t page_count;
bool no_reclaim;
};
struct mi_tld_s {
unsigned long long heartbeat;
mi_heap_t* heap_backing;
mi_segments_tld_t segments;
mi_os_tld_t os;
mi_stats_t stats;
};
typedef struct mi_segments_tld_s {
// 该队列中所有的segment均有空闲页,由于large与huge类型的segment仅有一个页,因此该队列中所有segment均为small类型
mi_segment_queue_t small_free;
size_t current_size;
size_t peak_size;
size_t cache_count;
size_t cache_size;
// segment的缓存
mi_segment_queue_t cache;
mi_stats_t* stats;
} mi_segments_tld_t;
typedef struct mi_os_tld_s {
uintptr_t mmap_next_probable;
void* mmap_previous;
uint8_t* pool;
size_t pool_available;
mi_stats_t* stats;
} mi_os_tld_t;
mi_malloc
extern inline void* mi_malloc(size_t size) mi_attr_noexcept {
return mi_heap_malloc(mi_get_default_heap(), size);
}
获取线程拥有的堆
static inline mi_heap_t* mi_get_default_heap(void) {
#ifdef MI_TLS_RECURSE_GUARD
if (!_mi_process_is_initialized) return &_mi_heap_main;
#endif
return _mi_heap_default;
}
从堆上分配内存
extern inline void* mi_heap_malloc(mi_heap_t* heap, size_t size) mi_attr_noexcept {
void* p;
if (mi_likely(size <= MI_SMALL_SIZE_MAX)) {
p = mi_heap_malloc_small(heap, size);
}
else {
p = _mi_malloc_generic(heap, size);
}
return p;
}
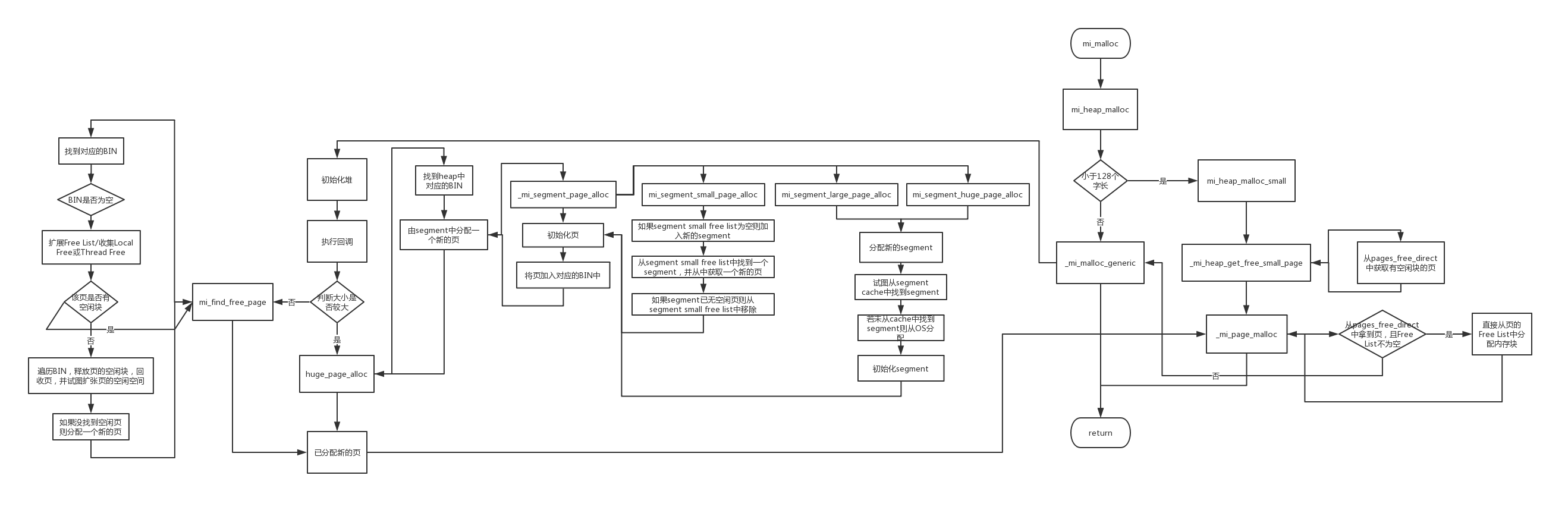
分配Small类型的内存块
extern inline void* mi_heap_malloc_small(mi_heap_t* heap, size_t size) mi_attr_noexcept {
mi_page_t* page = _mi_heap_get_free_small_page(heap,size);
return _mi_page_malloc(heap, page, size);
}
extern inline void* _mi_page_malloc(mi_heap_t* heap, mi_page_t* page, size_t size) mi_attr_noexcept {
mi_block_t* block = page->free;
if (mi_unlikely(block == NULL)) {
return _mi_malloc_generic(heap, size);
}
page->free = mi_block_next(page,block);
page->used++;
...
return block;
}
分配Large或者Huge类型的内存块
- 需要分配small类型的内存块,但是由pages_free_direct获得的页的Free List已经为空
- 需要分配large或者huge类型的内存块
- 如果需要的话进行全局数据/线程相关的数据/堆的初始化
- 调用回调函数(即实现前文所说的deferred free)
- 找到或分配新的页
- 从页中分配内存
void* _mi_malloc_generic(mi_heap_t* heap, size_t size) mi_attr_noexcept
{
if (mi_unlikely(!mi_heap_is_initialized(heap))) {
mi_thread_init();
heap = mi_get_default_heap();
} _mi_deferred_free(heap, false); mi_page_t* page;
if (mi_unlikely(size > MI_LARGE_SIZE_MAX)) {
if (mi_unlikely(size >= (SIZE_MAX - MI_MAX_ALIGN_SIZE))) {
page = NULL;
}
else {
page = mi_huge_page_alloc(heap,size);
}
}
else {
page = mi_find_free_page(heap,size);
}
if (page == NULL) return NULL; return _mi_page_malloc(heap, page, size);
}
初始化
void mi_thread_init(void) mi_attr_noexcept
{
// ensure our process has started already
mi_process_init(); // initialize the thread local default heap
if (_mi_heap_init()) return; // returns true if already initialized ... #endif
}
void mi_process_init(void) mi_attr_noexcept {
// ensure we are called once
if (_mi_process_is_initialized) return;
// access _mi_heap_default before setting _mi_process_is_initialized to ensure
// that the TLS slot is allocated without getting into recursion on macOS
// when using dynamic linking with interpose.
mi_heap_t* h = _mi_heap_default;
_mi_process_is_initialized = true;
_mi_heap_main.thread_id = _mi_thread_id();
uintptr_t random = _mi_random_init(_mi_heap_main.thread_id) ^ (uintptr_t)h;
#ifndef __APPLE__
_mi_heap_main.cookie = (uintptr_t)&_mi_heap_main ^ random;
#endif
_mi_heap_main.random = _mi_random_shuffle(random);
atexit(&mi_process_done);
mi_process_setup_auto_thread_done();
mi_stats_reset();
_mi_os_init();
}
static void mi_process_done(void) {
// only shutdown if we were initialized
if (!_mi_process_is_initialized) return;
// ensure we are called once
static bool process_done = false;
if (process_done) return;
process_done = true;
#ifndef NDEBUG
mi_collect(true);
#endif
}
static bool _mi_heap_done(void) {
mi_heap_t* heap = _mi_heap_default;
if (!mi_heap_is_initialized(heap)) return true;
// reset default heap
_mi_heap_default = (_mi_is_main_thread() ? &_mi_heap_main : (mi_heap_t*)&_mi_heap_empty);
// todo: delete all non-backing heaps?
// switch to backing heap and free it
heap = heap->tld->heap_backing;
if (!mi_heap_is_initialized(heap)) return false;
// collect if not the main thread
if (heap != &_mi_heap_main) {
_mi_heap_collect_abandon(heap);
}
// merge stats
_mi_stats_done(&heap->tld->stats);
// free if not the main thread
if (heap != &_mi_heap_main) {
_mi_os_free(heap, sizeof(mi_thread_data_t), &_mi_stats_main);
}
#if (MI_DEBUG > 0)
else {
_mi_heap_destroy_pages(heap);
}
#endif
return false;
}
- 调用deferred free回调函数
- 标记当前堆的Full List中的所有页面为Normal,从而让其在释放时加入Thread Free List,因为该segment之后可能会被其他线程接收
- 释放该堆的Thread Delayed Free List中的内存块(不是每页一个的Thread Free List)
- 遍历该堆所拥有的所有页,对每个页调用一次mi_heap_page_collect
- 调用_mi_page_free_collect将页中的Local Free List以及Thread Free List追加到Free List之后
- 如果该页没有正在使用的块则调用_mi_page_free将该页释放回对应的segment中,如果segment中所有的空闲页均被释放则可能直接释放对应的segment回OS或加入堆的缓存中
- 如果该页尚有正在使用的块则将该页标记为abandon,当某个segment中所有的页均被标记为abandon后会将对应的segment加入全局的abandon segment list中(堆中并未保留有哪些segment的信息,因此需要遍历所有页来完成这一操作)
- 释放堆中所有缓存的segment
static void mi_heap_collect_ex(mi_heap_t* heap, mi_collect_t collect)
{
_mi_deferred_free(heap,collect > NORMAL);
if (!mi_heap_is_initialized(heap)) return; // 一些接收abandon list中的segment的代码
... // if abandoning, mark all full pages to no longer add to delayed_free
if (collect == ABANDON) {
for (mi_page_t* page = heap->pages[MI_BIN_FULL].first; page != NULL; page = page->next) {
_mi_page_use_delayed_free(page, false); // set thread_free.delayed to MI_NO_DELAYED_FREE
}
} // free thread delayed blocks.
// (if abandoning, after this there are no more local references into the pages.)
_mi_heap_delayed_free(heap); // collect all pages owned by this thread
mi_heap_visit_pages(heap, &mi_heap_page_collect, &collect, NULL);
mi_assert_internal( collect != ABANDON || heap->thread_delayed_free == NULL ); // collect segment caches
if (collect >= FORCE) {
_mi_segment_thread_collect(&heap->tld->segments);
}
}
Huge类型页面的分配
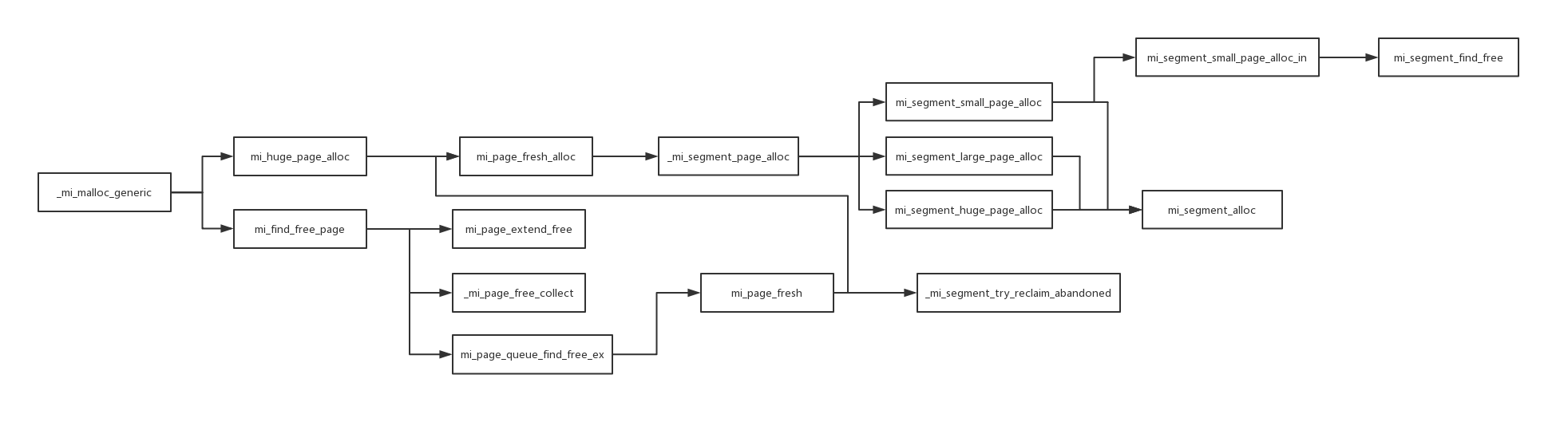
static mi_page_t* mi_page_fresh_alloc(mi_heap_t* heap, mi_page_queue_t* pq, size_t block_size) {
mi_page_t* page = _mi_segment_page_alloc(block_size, &heap->tld->segments, &heap->tld->os);
if (page == NULL) return NULL;
mi_page_init(heap, page, block_size, &heap->tld->stats);
mi_page_queue_push(heap, pq, page);
return page;
}
mi_huge_page_alloc/mi_large_page_alloc
- 计算segment的大小,页的大小
- 从cache中试图找到一个足够大的segment,如果segment中有较多未使用的空间则会将部分空间释放回OS
- 设置segment的元信息
mi_segment_small_page_alloc
Small/Large类型页面的分配
从页中分配内存块
extern inline void* _mi_page_malloc(mi_heap_t* heap, mi_page_t* page, size_t size) mi_attr_noexcept {
mi_block_t* block = page->free;
if (mi_unlikely(block == NULL)) {
return _mi_malloc_generic(heap, size); // slow path
}
mi_assert_internal(block != NULL && _mi_ptr_page(block) == page);
// pop from the free list
page->free = mi_block_next(page,block);
page->used++;
...
return block;
}
总结
以上就是mimalloc中用于内存分配部分的代码的解析了,其中还有很多没有讲到的地方,例如其向OS请求内存部分的代码等等。文章如果有哪里有问题,欢迎提出,对该项目感兴趣的可以去看一下其仓库1,或者参考这篇文章2。
引用
mimalloc内存分配代码分析的更多相关文章
- map的内存分配机制分析
该程序演示了map在形成的时候对内存的操作和分配. 因为自己对平衡二叉树的创建细节理解不够,还不太明白程序所显示的日志.等我明白了,再来修改这个文档. /* 功能说明: map的内存分配机制分析. 代 ...
- list的内存分配机制分析
该程序演示了list在内存分配时候的问题.里面的备注信息是我的想法. /* 功能说明: list的内存分配机制分析. 代码说明: list所管理的内存地址可以是不连续的.程序在不断的push_back ...
- vector的内存分配机制分析
该程序初步演示了我对vector在分配内存的时候的理解.可能有误差,随着理解的改变,改代码可以被修改. /* 功能说明: vector的内存分配机制分析. 代码说明: vector所管理的内存地址是连 ...
- S5PV210的内存分配研究分析
S5PV210内存一般会使用SDRAM和DDR2 (DDR SDRAM),SDRAM的uboot启动网络已经有很多资料的,对于DDR2还有有很多疑惑,如果有错误的地方,请大家一定指出,醍醐灌顶,不胜感 ...
- java 字符串内存分配的分析与总结
经常在网上各大版块都能看到对于java字符串运行时内存分配的探讨,形如:String a = "123",String b = new String("123" ...
- java内存分配和String类型的深度解析
[尊重原创文章出自:http://my.oschina.net/xiaohui249/blog/170013] 摘要 从整体上介绍java内存的概念.构成以及分配机制,在此基础上深度解析java中的S ...
- 【转】java内存分配和String类型的深度解析
一.引题 在java语言的所有数据类型中,String类型是比较特殊的一种类型,同时也是面试的时候经常被问到的一个知识点,本文结合java内存分配深度分析关于String的许多令人迷惑的问题.下面是本 ...
- 详解Go中内存分配
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com 本文使用的go的源码15.7 介绍 Go 语言的内存分配器就借鉴了 TCMalloc 的 ...
- Netty源码分析第5章(ByteBuf)---->第7节: page级别的内存分配
Netty源码分析第五章: ByteBuf 第六节: page级别的内存分配 前面小节我们剖析过命中缓存的内存分配逻辑, 前提是如果缓存中有数据, 那么缓存中没有数据, netty是如何开辟一块内存进 ...
随机推荐
- .net core 利用Selenium和PhantomJS后台生成EChart图片
1.引用 NuGet安装: Selenium.Support Selenium.WebDriver Selenium.WebDriver.PhantomJS.CrossPlatform (分布Lin ...
- Devart Blog
How to combine data from several sources using SQL and VirtualQueryhttp://blog.devart.com/how-to-com ...
- ECSHOP 数据库结构说明
ECSHOP 数据库结构说明 (适用版本v2.7.3) 1.account_log 用户账目日志表 字段 类型 Null/默认 注释 log_id mediumint(8) 否 / 自增 ID 号 u ...
- HDFS的几点改进
HDFS(Hadoop Distributed File System)是一个运行在商用机器上面的分布式文件系统,其设计思想来自于google著名的Google File System论文. HDFS ...
- 为什么需要使用Git客户端?(使用msysgit)
Git 是 Linux Torvalds 为了帮助管理 Linux® 内核开发而开发的一个开放源码的版本控制软件.正如所提供的文档中说的一样,“Git 是一个快速.可扩展的分布式版本控制系统,它具有极 ...
- postgresql Java JDBC 一次性传入多个参数到 in ( ?) - multple/list parameters
经常不清楚需要传入多少个参数到 IN () 里面,下面是简单方法: 方法 1 - in ( SELECT * FROM unnest(?)) ) Integer[] ids={1,2,3}; ...
- 基于 libevent 开发的 C++ 11 高性能网络服务器 evpp(360的作品)
evpp是一个基于libevent开发的现代化C++11高性能网络服务器,自带TCP/UDP/HTTP等协议的异步非阻塞式的服务器和客户端库. 特性: 现代版的C++11接口 非阻塞异步接口都是C++ ...
- Access Violation分成两大类:运行期和设计期(很全的解释)
用Delphi开发程序时,我们可以把遇到的Access Violation分成两大类:运行期和设计期. 一.设计期的Access Violation 1.硬件原因 在启动或关闭Delphi IDE以 ...
- 逆向工程mybatis-geneator.xml
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE generatorConfiguration ...
- HTML连载10-details标签&summary标签&marquee标签
1.详情(details)与概要(summary)标签 (1)作用:我们希望用尽可能少的空间来表达更多的信息,利用summary标签来描述概要信息,用details标签来描述详情信息 (2)格式: ...