Hadoop学习-hdfs安装及其一些操作
hdfs:分布式文件系统
有目录结构,顶层目录是: /,存的是文件,把文件存入hdfs后,会把这个文件进行切块并且进行备份,切块大小和备份的数量有客户决定。
存文件的叫datanode,记录文件的切块信息的叫namenode
Hdfs的安装
准备四台linux服务器
先在hdp-01上进行下面操作
- 配置域名映射
vim /etc/hosts
主机名:hdp-01 对应的ip地址:192.168.33.61
主机名:hdp-02 对应的ip地址:192.168.33.62
主机名:hdp-03 对应的ip地址:192.168.33.63
主机名:hdp-04 对应的ip地址:192.168.33.64
- 更改本机的域名映射文件
c:/windows/system32/drivers/etc/hosts
|
192.168.33.61 hdp-01 192.168.33.62 hdp-02 192.168.33.63 hdp-03 192.168.33.64 hdp-04 |
- 关闭防火墙
service iptables stop
setenforce 0
- 安装jdk
在linux中 tar –zxvf jdk-8u141-linux-x64.tar.gz –C /root/apps/
然后vim /etc/profile
export JAVA_HOME=/root/apps/ jdk1.8.0_141
export PATH=$PATH:$JAVA_HOME/bin
然后source /etc/profile
Ok
- 安装scp
yum install -y openssh-clients
yum list
yum list | grep ssh
- 配置免密登录(在hdp-01上)
输入ssh-keygen
然后三次回车
然后
ssh-copy-id hdp-02
ssh-copy-id hdp-03
ssh-copy-id hdp-04
- 然后开始安装hadoop
上传压缩包,然后
[root@hdp-01 ~]# tar -zxvf hadoop-2.8.1.tar.gz -C apps/
然后修改配置文件
|
要点提示 |
核心配置参数: 1) 指定hadoop的默认文件系统为:hdfs 2) 指定hdfs的namenode节点为哪台机器 3) 指定namenode软件存储元数据的本地目录 4) 指定datanode软件存放文件块的本地目录 |
1) 修改hadoop-env.sh
export JAVA_HOME=/root/apps/ jdk1.8.0_141
2) 修改core-site.xml
|
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hdp-01:9000</value> </property> </configuration> |
3) 修改hdfs-site.xml
|
<configuration> <property> <name>dfs.namenode.name.dir</name> <value>/root/hdpdata/name/</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/root/hdpdata/data</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>hdp-02:50090</value> </property> </configuration> |
- 然后配置hadoop的环境变量 vi /etc/profile
export HADOOP_HOME=/root/apps/hadoop-2.8.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 讲apps下的东西和/etc/profile和/etc/hosts/都拷贝到其他的机器上
scp -r /root/apps/hadoop-2.8.1 hdp-02:/root/apps/
scp -r /root/apps/hadoop-2.8.1 hdp-03:/root/apps/
scp -r /root/apps/hadoop-2.8.1 hdp-04:/root/apps/
- 初始化元数据目录
hadoop namenode –format(在hdp-01上)
然后启动namenode进程
hadoop-daemon.sh start namenode
然后,在windows中用浏览器访问namenode提供的web端口:50070
http://hdp-01:50070
hadoop内部端口为9000
然后,启动众datanode们(在任意地方)
hadoop-daemon.sh start datanode
增加datanode随时可以,减少可不能瞎搞。。。。
或者一种方便的启动方法
修改hadoop安装目录中/etc/hadoop/slaves(把需要启动datanode进程的节点列入)
|
hdp-01 hdp-02 hdp-03 hdp-04 |
在hdp-01上用脚本:start-dfs.sh 来自动启动整个集群
如果要停止,则用脚本:stop-dfs.sh
hdfs的客户端会读以下两个参数,来决定切块大小、副本数量:
切块大小的参数: dfs.blocksize
副本数量的参数: dfs.replication
上面两个参数应该配置在客户端机器的hadoop目录中的hdfs-site.xml中配置
|
<property> <name>dfs.blocksize</name> <value>64m</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> |
至此完成
hdfs的一些操作
查看目录信息
hadoop fs -ls /
上传文件从/xxx/xx上传到/yy
hadoop fs -put /xxx/xx /yyy
hadoop fs -copyFromLocal /本地文件 /hdfs路径 ## copyFromLocal等价于 put
hadoop fs -moveFromLocal /本地文件 /hdfs路径 ## 跟copyFromLocal的区别是:从本地移动到hdfs中
下载文件到本地
hadoop fs -get /hdfs路径 /local路径
hadoop fs -copyToLocal /hdfs中的路径 /本地磁盘路径 ## 跟get等价
hadoop fs -moveToLocal /hdfs路径 /本地路径 ## 从hdfs中移动到本地
追加内容到已存在的文件
hadoop fs -appendToFile /本地文件 /hdfs中的文件
其他命令和linux的基本差不多只不过前面加hadoop fs –
额外知识
1.
元数据:对数据的描述信息,namenode记录的就叫元数据
2.
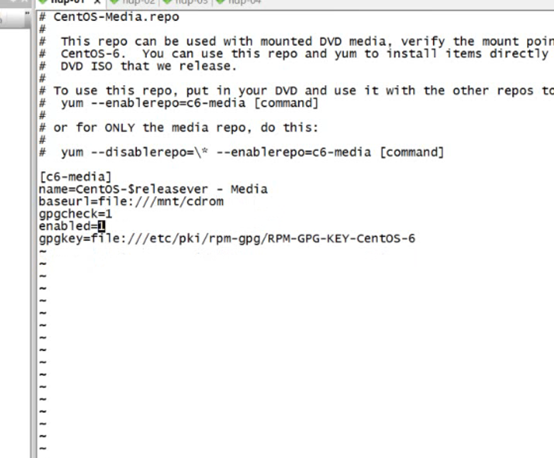
配置yum源配置文件
先将那个磁盘挂载到一个文件夹下比如/mnt/cdrom

然后配置yum
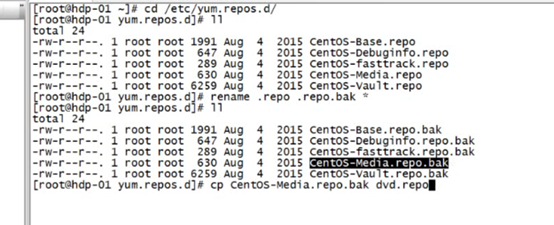
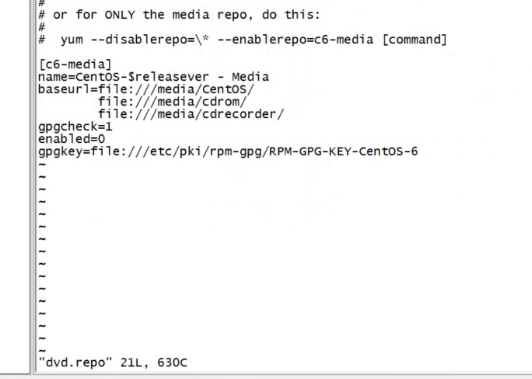
改为这样的
3.
命令netstat –nltp 监听端口号
或者ps –ef是查看进程号
4.
让防火墙每次开机不重启
chkconfig iptables off
service的执行脚本放在 /etc/service下
凡是能使用 service 服务 动作 的指令
都可以在/etc/init.d目录下执行
例如: /etc/init.d/sshd start
使用 service 服务 动作 例子 service papche2 restart
其实是执行了一个脚本
/etc/init.d apache2 restatr
linux服务器启动的时候分为6个等级
0.表示关机
1.单用户模式
2.无网络的多用户模式
3.有网络的多用户模式
4.不可用
5.图形化界面
6.重新启动
具体和默认的启动等级可以在 /etc/inittab目录下查看
查看各个级别下服务开机自启动情况 可以使用 chkconfig --list
增加一个自启动服务 chkconfig --add 服务名 例如 chkconfig --add sshd
减少一个自启动服务 chkconfig --add 服务名 例如 chkconfig --del sshd
chkconfig --level 等级 服务 off/on
chkconfig是当前不生效,Linux重启之后才生效的命令(开机自启动项)
service是即使生效,重启后失效的命令
5.
C语言写的东西和平台是有关系的,在Windows下写的东西放到linux不一定可以
而java可以,因为有java虚拟机
6.
Hdfs的url hdfs://hdp-01:9000/
ll –h
在类 Unix 系统中,/dev/null 称空设备,是一个特殊的设备文件,它丢弃一切写入其中的数据(但报告写入操作成功),读取它则会立即得到一个 EOF。
而使用 cat $filename > /dev/null 则不会得到任何信息,因为我们将本来该通过标准输出显示的文件信息重定向到了 /dev/null 中。
使用 cat $filename 1 > /dev/null 也会得到同样的效果,因为默认重定向的 1 就是标准输出。 如果你对 shell
7
Cat 来拼接两个文件,如在hdfs下的两个block文件
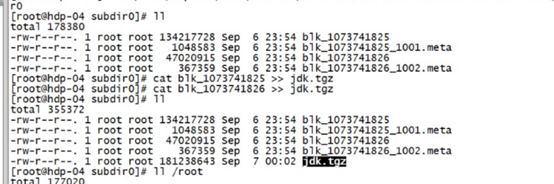
如此拼接就成了一个完整的源文件
源文件的路径在
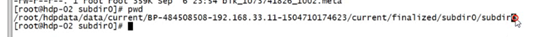
java客户端的api
//官方文档
//http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
//会先默认读取classpath中加载的core-default.xml.hdfs-default.xml core-size.xml....
//这些都是一个个jar包,你也可以在src目录下自己写一个hdfs-site.xml文件
Configuration conf = new Configuration();
conf.set("dfs.replication","2");//指定副本数
conf.set("dfs.blocksize","64m");//指定切块大小
//模拟一个客户端
FileSystem fs = FileSystem.get(new URI("hdfs://hdp-01:9000/"),conf,"root");
然后可以通过fs.xxxxx的方法来使用
Hadoop学习-hdfs安装及其一些操作的更多相关文章
- Hadoop基础-HDFS的API常见操作
Hadoop基础-HDFS的API常见操作 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习HDFS时的一些琐碎的学习笔记, 方便自己以后查看.在调用API ...
- Hadoop学习-HDFS篇
HDFS设计基础与目标 硬件错误是常态.因此需要冗余 流式数据访问.即数据批量读取而非随机读写,Hadoop擅长做的是数据分析而不是事务处理(随机性的读写数据等). 大规模数据集 简单一致性模型.为了 ...
- Hadoop 学习 HDFS
1.HDFS的设计 HDFS是什么:HDFS即Hadoop分布式文件系统(Hadoop Distributed Filesystem),以流式数据访问模式来存储超大文件,运行于商用硬件集群上,是管理网 ...
- Hadoop学习笔记之二 文件操作
HDFS分布式文件系统:优点:支持超大文件存储.流式访问.一次写入多次读取.缺点:不适应大量小文件.不适应低时延的数据访问.不适应多用户访问任意修改文件. 1.hadoop用于大数据处理,在数据量较小 ...
- Hadoop学习笔记——安装Hadoop
sudo mv /home/common/下载/hadoop-2.7.2.tar.gz /usr/local sudo tar -xzvf hadoop-2.7.2.tar.gz sudo mv ha ...
- hadoop学习;hdfs操作;执行抛出权限异常: Permission denied;api查看源代码方法;源代码不停的向里循环;抽象类通过debug查找源代码
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/u010026901/article/details/26587251 eclipse快捷键alt+s ...
- hadoop的hdfs中的javaAPI操作
package cn.itcast.bigdata.hdfs; import java.net.URI; import java.util.Iterator; import java.util.Map ...
- hadoop学习;安装jdk,workstation虚拟机v2v迁移;虚拟机之间和跨物理机之间ping网络通信;virtualbox的centos中关闭防火墙和检查服务启动
JDK 在Ubuntu下的安装 与 环境变量的配置 前期准备工作: 找到 JDK 和 配置TXT文件 并拷贝到桌面下 不是目录 而是文件拷贝到桌面下 以下的命令部分就直接复制粘贴就能够了 1.配 ...
- Hadoop(7)-HDFS客户端的API操作
1 客户端环境准备 根据自己电脑的操作系统拷贝对应的编译后的hadoop jar包到非中文路径 配置HADOOP_HOME的环境变量,并且在path中配置hadoop的bin 重启电脑 2. Hdfs ...
随机推荐
- Delphi 的RTTI机制浅探3(超长,很不错)
转自:http://blog.sina.com.cn/s/blog_53d1e9210100uke4.html 目录========================================== ...
- WebRequest请求错误(服务器提交了协议冲突. Section=ResponseHeader Detail=CR 后面必须是 LF)
WebRequest请求错误(服务器提交了协议冲突. Section=ResponseHeader Detail=CR 后面必须是 LF)解决办法,天津config文件,增加一个配置如下 <?x ...
- delphi LPT1端口打印与开钱箱
{设置打印机}Assignfile(RPrinter,'LPT1'); {准备写文件}Rewrite(RPrinter); {向后倒纸}//Writeln(RPrinter,chr($b)+chr(2 ...
- LINUX下QT FOR ARM开发环境搭建过程 (使用qt-x11-opensource-src-4.5.2.tar.gz进行编译)
在PC上,我们需要得到两个版本的Qt,分别是:Qt-4.5.2和QtEmbedded-4.5.2-arm.前者包括了Qt Designer等基本工具,用于在PC上对程序的开发调试,使我们能确保程序放到 ...
- Codility----PermMissingElem
Task description A zero-indexed array A consisting of N different integers is given. The array conta ...
- 高性能嵌入式核心板新标杆!米尔推出基于NXP i.MX8M处理器的MYC-JX8MX核心板
随着嵌入式及物联网技术的飞速发展,高性能计算的嵌入式板卡已经成为智能产品的基础硬件平台.为响应行业应用和满足客户需求,米尔电子推出基于NXP公司i.MX8M系列芯片的开发平台MYD-JX8MX系列开发 ...
- React性能优化之PureComponent 和 memo使用分析
前言 关于react性能优化,在react 16这个版本,官方推出fiber,在框架层面优化了react性能上面的问题.由于这个太过于庞大,我们今天围绕子自组件更新策略,从两个及其微小的方面来谈rea ...
- kafka 名词概念
ProducerConsumerBrokerTopicPartitionConsumer Group分布式 Broker Kafka集群包含一个或多个服务器,这种服务器被称为brokerTop ...
- 重磅发布:阿里开源 OpenJDK 长期支持版本 Alibaba Dragonwell
原文地址:https://yq.aliyun.com/articles/694603 本文作者:阿里开源 本文来自云栖社区合作伙伴"阿里系统软件技术",了解相关信息可以关注&qu ...
- 长春理工大学第十四届程序设计竞赛(重现赛)H
H .Arithmetic Sequence 题目链接:https://ac.nowcoder.com/acm/contest/912/H 题目 数竞选手小r最喜欢做的题型是数列大题,并且每一道都能得 ...