java面试题-Java集合相关
1. ArrayList 和 Vector 的区别
ArrayList和Vector底层实现原理都是一样得,都是使用数组方式存储数据
Vector是线程安全的,但是性能比ArrayList要低。
ArrayList,Vector主要区别为以下几点:
(1):Vector是线程安全的,源码中有很多的synchronized可以看出,而ArrayList不是。导致Vector效率无法和ArrayList相比;
(2):ArrayList和Vector都采用线性连续存储空间,当存储空间不足的时候,ArrayList默认增加为原来的50%,Vector默认增加为原来的一倍;
(3):Vector可以设置capacityIncrement,而ArrayList不可以,从字面理解就是capacity容量,Increment增加,容量增长的参数。
2.说说 ArrayList,Vector, LinkedList 的存储性能和特性
ArrayList采用的数组形式来保存对象,这种方法将对象放在连续的位置中,所以最大的缺点就是插入和删除的时候比较麻烦,查找比较快;
Vector使用了sychronized方法(线程安全),所以在性能上比ArrayList要差些.
LinkedList采用的链表将对象存放在独立的空间中,而且在每个空间中还保存下一个链表的索引。使用双向链表方式存储数据,按序号索引数据需要前向或后向遍历数据,所以索引数据慢,是插入数据时只需要记录前后项即可,所以插入的速度快。
3.快速失败 (fail-fast) 和安全失败 (fail-safe) 的区别是什么?
1.快速失败
原理是:
迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个modCount变量。集合在被遍历期间如果内容发生变化,就会改变modCount的值。每当迭代器使用hasNext()或next()遍历下一个元素之前,都会先检查modCount变量是否为expectmodCount值。如果是的话就返回遍历;否则抛出异常,终止遍历。
查看ArrayList源码,在next方法执行的时候,会执行checkForComodification()方法。
- @SuppressWarnings("unchecked")
- public E next() {
- checkForComodification();
- int i = cursor;
- if (i >= size)
- throw new NoSuchElementException();
- Object[] elementData = ArrayList.this.elementData;
- if (i >= elementData.length)
- throw new ConcurrentModificationException();
- cursor = i + 1;
- return (E) elementData[lastRet = i];
- }
- final void checkForComodification() {
- if (modCount != expectedModCount)
- throw new ConcurrentModificationException();
- }
这里异常的抛出条件是modCount != expectedModCount这个条件。如果集合发生变化时修改modCount值刚好又设置为了expectedModCount值,则异常不会抛出。因此,不能依赖于这个异常是否抛出而进行并发操作,这个异常只建议用于检测并发修改的bug。
2.安全失败
采用安全失败机制的集合容器,在遍历时不是直接在集合上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。
原理:
由于迭代时是对原集合的拷贝进行遍历,所以在遍历过程中对原集合所做的修改并不能被迭代器检测到,所以不会触发ConcurrentModificationException,例如CopyOnWriteArrayList。
缺点:
基于拷贝内容的优点是避免了ConcurrentModificationException,但同样地,迭代器并不能访问到修改后的内容。即:迭代器遍历的是开始遍历那一刻拿到的集合拷贝,在遍历期间原集合发生的修改迭代器是不知道的。
场景:
Java.util.concurrent包下的容器都是安全失败的,可以在多线程下并发使用,并发修改。
快速失败和安全失败都是对迭代器而言的。快速失败:当在迭代一个集合时,如果有另外一个线程在修改这个集合,就会跑出ConcurrentModificationException,java.util下都是快速失败。安全失败:在迭代时候会在集合二层做一个拷贝,所以在修改集合上层元素不会影响下层。在java.util.concurrent包下都是安全失败。
4.HashMap 的数据结构
HashMap的主干类是一个Entry数组(jdk1.7) ,每个Entry都包含有一个键值队(key-value).
我们可以看一下源码:
- static class Entry<K,V> implements Map.Entry<K,V> {
- final K key;
- V value;
- Entry<K,V> next;//存储指向下一个Entry的引用,单链表结构
- int hash;//对key的hashcode值进行hash运算后得到的值,存储在Entry,避免重复计算
- /**
- * Creates new entry.
- */
- Entry(int h, K k, V v, Entry<K,V> n) {
- value = v;
- next = n;
- key = k;
- hash = h;
- }
所以,HashMap的整体结果如下
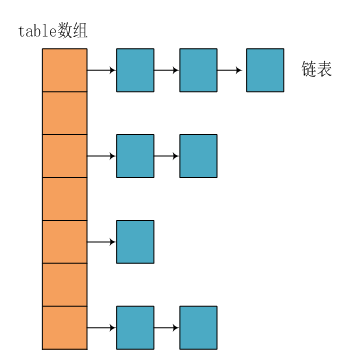
简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
5.HashMap 的工作原理
HashMap基于hashing原理,我们通过put()和get()方法存储和获取对象,当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,让后找到bucket位置来存储值对象。当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回对象。
我们看一下put()源码:
- public V put(K key, V value) {
- //当key为null,调用putForNullKey方法,保存null与table第一个位置中,这是HashMap允许为null的原因
- if (key == null)
- return putForNullKey(value);
- //计算key的hash值
- int hash = hash(key.hashCode()); //计算key hash 值在 table 数组中的位置
- int i = indexFor(hash, table.length); //从i出开始迭代 e,找到 key 保存的位置
- for (Entry<K, V> e = table[i]; e != null; e = e.next) {
- Object k;
- //判断该条链上是否有hash值相同的(key相同)
- //若存在相同,则直接覆盖value,返回旧value
- if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
- V oldValue = e.value; //旧值 = 新值
- e.value = value;
- e.recordAccess(this);
- return oldValue; //返回旧值
- }
- }
- //修改次数增加1
- modCount++;
- //将key、value添加至i位置处
- addEntry(hash, key, value, i);
- return null;
- }
通过源码我们可以清晰看到HashMap保存数据的过程为:首先判断key是否为null,若为null,则直接调用putForNullKey方法。若不为空则先计算key的hash值,然后根据hash值搜索在table数组中的索引位置,如果table数组在该位置处有元素,则通过比较是否存在相同的key,若存在则覆盖原来key的value,否则将该元素保存在链头(最先保存的元素放在链尾)。若table在该处没有元素,则直接保存。
get()源码:
- public V get(Object key) {
- // 若为null,调用getForNullKey方法返回相对应的value
- if (key == null)
- return getForNullKey();
- // 根据该 key 的 hashCode 值计算它的 hash 码
- int hash = hash(key.hashCode());
- // 取出 table 数组中指定索引处的值
- for (Entry<K, V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
- Object k;
- //若搜索的key与查找的key相同,则返回相对应的value
- if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
- return e.value;
- }
- return null;
- }
在这里能够根据key快速的取到value除了和HashMap的数据结构密不可分外,还和Entry有莫大的关系,在前面就提到过,HashMap在存储过程中并没有将key,value分开来存储,而是当做一个整体key-value来处理的,这个整体就是Entry对象。同时value也只相当于key的附属而已。在存储的过程中,系统根据key的hashcode来决定Entry在table数组中的存储位置,在取的过程中同样根据key的hashcode取出相对应的Entry对象。
6.Hashmap 什么时候进行扩容呢?
这里我们再来复习put的流程:当我们想一个HashMap中添加一对key-value时,系统首先会计算key的hash值,然后根据hash值确认在table中存储的位置。若该位置没有元素,则直接插入。否则迭代该处元素链表并依此比较其key的hash值。如果两个hash值相等且key值相等(e.hash == hash && ((k = e.key) == key || key.equals(k))),则用新的Entry的value覆盖原来节点的value。如果两个hash值相等但key值不等 ,则将该节点插入该链表的链头。具体的实现过程见addEntry方法,如下:
- void addEntry(int hash, K key, V value, int bucketIndex) {
- //获取bucketIndex处的Entry
- Entry<K, V> e = table[bucketIndex];
- //将新创建的 Entry 放入 bucketIndex 索引处,并让新的 Entry 指向原来的 Entry
- table[bucketIndex] = new Entry<K, V>(hash, key, value, e);
- //若HashMap中元素的个数超过极限了,则容量扩大两倍
- if (size++ >= threshold)
- resize(2 * table.length);
- }
这个方法中有两点需要注意:
一是链的产生。这是一个非常优雅的设计。系统总是将新的Entry对象添加到bucketIndex处。如果bucketIndex处已经有了对象,那么新添加的Entry对象将指向原有的Entry对象,形成一条Entry链,但是若bucketIndex处没有Entry对象,也就是e==null,那么新添加的Entry对象指向null,也就不会产生Entry链了。
二、扩容问题。
随着HashMap中元素的数量越来越多,发生碰撞的概率就越来越大,所产生的链表长度就会越来越长,这样势必会影响HashMap的速度,为了保证HashMap的效率,系统必须要在某个临界点进行扩容处理。该临界点在当HashMap中元素的数量等于table数组长度*加载因子。但是扩容是一个非常耗时的过程,因为它需要重新计算这些数据在新table数组中的位置并进行复制处理。所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
7.HashSet怎样保证元素不重复
都知道HashSet中不能存放重复的元素,有时候可以用来做去重操作。但是其内部是怎么保证元素不重复的呢?
打开HashSet源码,发现其内部维护一个HashMap:
- public class HashSet<E>
- extends AbstractSet<E>
- implements Set<E>, Cloneable, java.io.Serializable
- {
- static final long serialVersionUID = -5024744406713321676L;
- private transient HashMap<E,Object> map;
- private static final Object PRESENT = new Object();
- public HashSet() {
- map = new HashMap<>();
- }
...
}
HashSet的构造方法其实就是在内部实例化了一个HashMap对象,其中还会看到一个static final的PRESENT变量;
想知道为什么HashSet不能存放重复对象,那么第一步看看它的add方法进行的判重,代码如下
- public boolean add(E e) {
- return map.put(e, PRESENT)==null;
- }
其实看add()方法,这时候答案已经出来了:HashMap的key是不能重复的,而这里HashSet的元素又是作为了map的key,当然也不能重复了。
顺便看一下HashMap里面又是怎么保证key不重复的,代码如下:
- public V put(K key, V value) {
- if (table == EMPTY_TABLE) {
- inflateTable(threshold);
- }
- if (key == null)
- return putForNullKey(value);
- int hash = hash(key);
- int i = indexFor(hash, table.length);
- for (Entry<K,V> e = table[i]; e != null; e = e.next) {
- Object k;
- if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
- V oldValue = e.value;
- e.value = value;
- e.recordAccess(this);
- return oldValue;
- }
- }
- modCount++;
- addEntry(hash, key, value, i);
- return null;
- }
其中最关键的一句:
- if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
调用了对象的hashCode和equals方法进行判断,所以又得到一个结论:若要将对象存放到HashSet中并保证对象不重复,应根据实际情况将对象的hashCode方法和equals方法进行重写
java面试题-Java集合相关的更多相关文章
- 拼多多、饿了么、蚂蚁金服Java面试题大集合
自己当初找工作时参加过众多一线互联网公司的Java研发面试,这段时间处于寒冬,然而前几天跳槽找工作,两天面了3家,已经拿了两个offer,觉得可以和大家分享下: 下面为拼多多.饿了么.蚂蚁金服.哈啰出 ...
- 2017年java面试题【集合篇】
Java是一门面向对象编程语言,不仅吸收了C++语言的各种优点,还摒弃了C++里难以理解的多继承.指针等概念,因此Java语言具有功能强大和简单易用两个特征. 这里有10个经典的Java面试题,也为大 ...
- [ Java面试题 ]Java 开发岗面试知识点解析
如背景中介绍,作者在一年之内参加过多场面试,应聘岗位均为 Java 开发方向. 在不断的面试中,分类总结了 Java 开发岗位面试中的一些知识点. 主要包括以下几个部分: Java 基础知识点 Jav ...
- Java面试题之jsp相关
一.jsp有哪些内置对象?作用分别是什么? 分别有什么方法? 本帖隐藏的内容 答:JSP共有以下9个内置的对象: request 用户端请求,此请求会包含来自GET/POST请求的参数 respons ...
- Java面试题之weblogic相关问题
WebLogic是美国Oracle公司出品的一个application server确切的说是一个基于JAVAEE架构的中间件,BEA WebLogic是用于开发.集成.部署和管理大型分布式Web应用 ...
- JAVA面试题——JAVA编程题1(2015.07.22——湛耀)
实现代码很简单: package com.xiaozan.shopping; import java.util.Arrays; public class ShoppingCart { ...
- Java 面试题 —— java 源码
1. 静态工厂方法 静态工厂方法不必在每次调用它们的时候都创建一个新的对象: Boolean.valueOf(boolean): public final class Boolean { public ...
- Java面试题-Java容器
一.Java容器分类 Java容器划分为两个概念Collection.Map Collection: 一个独立元素的序列,这些元素都服从一条或多条规则.List必须按照插入的顺序保存元素,不关心是否重 ...
- JAVA面试题——JAVA编程题1(2015.07.22)
实现代码很简单: package com.xiaozan.shopping; import java.util.Arrays; public class ShoppingCart { ...
随机推荐
- git基础命令详解
一些必须要知道的概念 git的三个工作区域:工作目录.暂存区.git仓库. 工作目录:其实就是本地文件磁盘上的文件或目录: 暂存区:是一个文件,保存了下次提交的文件列表信息,一般在git仓库目录中: ...
- .NET实时2D渲染入门·动态时钟
.NET实时2D渲染入门·动态时钟 从小以来"坦克大战"."魂斗罗"等游戏总令我魂牵梦绕.这些游戏的基础就是2D实时渲染,以前没意识,直到后来找到了Direct ...
- PBO项目的组织
前言: 最近发现PMI的英文官网已经公布了第五版PMBOK的初稿,针对第四版而言的确有了不少变动.了解这些变动,对理解项目管理知识的整理和发展,以及掌握PMP考试的变化方向都是很重要的.当然,变动尤其 ...
- [Noip1997] 棋盘问题(2)
题目描述 在N×NN \times NN×N的棋盘上(1≤N≤10)(1≤N≤10)(1≤N≤10),填入1,2,…,N21,2,…,N^21,2,…,N2共N2N^2N2个数,使得任意两个相邻的数之 ...
- java-try,return和finally相遇时的各种情况
今天碰到了这样一个问题:使用try,return和finally会碰到的各种情况1,try中有return时,执行顺序:2,try和finally中都有return时,执行顺序:3,运算代码在fina ...
- hadoop-3.1.2启动httpfs
最近有一个需求,要求使用httpfs读取数据,一开始看到httpfs这个词,第一感觉是不是多了个f,是不是https,后来百度一下,其实不然. httpfs其实是使用http协议访问hdfs文件系统: ...
- 元素定位之css选择器(2)
理论学习地址:https://www.runoob.com/cssref/css-selectors.html 定位思路: 先在单元素范围内选择查找id或name,定位不到的话往上查扩大范围 使用实例 ...
- 百万年薪python之路 -- 前端CSS基础介绍
一. CSS介绍 CSS定义 CSS(Cascading Style Sheet,层叠样式表)定义如何显示HTML元素,给HTML设置样式,让它更加美观. 语法结构 div{ color: green ...
- NVDLA中Winograd卷积的设计
在AI芯片:高性能卷积计算中的数据复用曾提到,基于变换域的卷积计算--譬如Winograd卷积--并不能适应算法上对卷积计算多变的需求.但Winograd卷积依旧出现在刚刚公开的ARM Ethos-N ...
- 《编写可维护的JavaScript》 笔记
<编写可维护的JavaScript> 笔记 我的github iSAM2016 概述 本书的一开始介绍了大量的编码规范,并且给出了最佳和错误的范例,大部分在网上的编码规范看过,就不在赘述 ...