[阅读笔记]EfficientDet
EfficientDet
文章阅读
Google的网络结构不错,总是会考虑计算性能的问题,从mobilenet v1到mobile net v2.这篇文章主要对近来的FPN结构进行了改进,实现了一种效果和性能兼顾的BiFPN,同时提供了D0-D7不同的配置,计算量和精度都逐级增大.相比maskrcnn,retinanet,更低的计算量还能达到更好的效果.
BiFPN
主要有亮点:高效的双向不同尺度的特征融合,带权重的特征融合
多尺度特征的融合
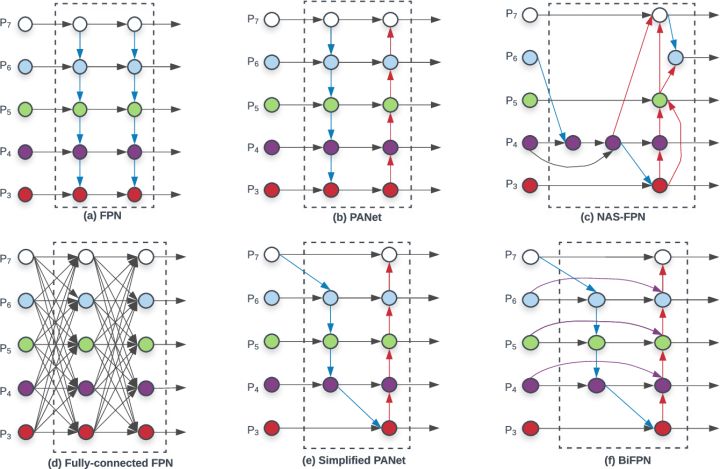
首先是各种FPN结构的演进和比较,(a)普通的FPN只有自顶向下的连接 (b)PANet还加了自底向上的连接,(c)NAS-FPN通过搜索找到一种不规则的连接结构.(d-f)是本文探讨的结构,(d)所有的尺度使用最全的连接,计算也最复杂,(e)PANet简化,去除只有一个输入的结点,(f)本文最终的BiFPN结构
- PANet效果好于FPN和NAS-FPN,计算代价也更高
- 如果一个结点本身没有融合的特征,那么对以特征融合为目标的结构贡献就不大(why?).所以(e)中移除了P3,P7的中间结点
- 同一尺度的输入和输出又加了一个连接,因为计算量不大.得到(f)
- (f)中虚线框内作为一层,会重复多次,以得到high-level feature fusion.
加权融合
从Pyramid attention networks得到启发,不同尺度的特征的贡献是不一样的,所以连接时需要加上权重,而权重通过网络学到的.
文章比较了三种加权的方法,Fast normalized fusion相比Softmax-based fusion方法,效果一致,但速度更快.
网络结构

backbone取自ImageNet-pretrained EfficientNet.P3-P7接本文的BiFPN Layer,重复多次.class and box分支共享权重.
为了适应不同的精度和性能,文章提出了Compound Scaling方法,只需一个参数控制input size, backbone, BiFPN layers和channels, Box/class depth.得到了D0-D7不同计算量的模型.
实验和试验结果
- D0与YOLOv3同样精度下,FLOPs少28x
- D1与RetinaNet , Mask-RCNN比较,参数少8x,FLOP少25x,精度类似.
- D7达到51mAP,同时更快参数更少.
Ablation Study
- 相比Resnet50,EfficientNet B3 backbone提升3mAP.BiFPN比FPN提升4mAP
- 加权比不加权连接,提升0.45mAP.
- Fast Normalized Fusion对比Softmax,表现接近,速度快30%
[阅读笔记]EfficientDet的更多相关文章
- 阅读笔记 1 火球 UML大战需求分析
伴随着七天国庆的结束,紧张的学习生活也开始了,首先声明,阅读笔记随着我不断地阅读进度会慢慢更新,而不是一次性的写完,所以会重复的编辑.对于我选的这本 <火球 UML大战需求分析>,首先 ...
- [阅读笔记]Software optimization resources
http://www.agner.org/optimize/#manuals 阅读笔记Optimizing software in C++ 7. The efficiency of differe ...
- 《uml大战需求分析》阅读笔记05
<uml大战需求分析>阅读笔记05 这次我主要阅读了这本书的第九十章,通过看这章的知识了解了不少的知识开发某系统的重要前提是:这个系统有谁在用?这些人通过这个系统能做什么事? 一般搞清楚这 ...
- <<UML大战需求分析>>阅读笔记(2)
<<UML大战需求分析>>阅读笔记(2)> 此次读了uml大战需求分析的第三四章,我发现这本书讲的特别的好,由于这学期正在学习设计模式这本书,这本书就讲究对uml图的利用 ...
- uml大战需求分析阅读笔记01
<<UML大战需求分析>>阅读笔记(1) 刚读了uml大战需求分析的第一二章,读了这些内容之后,令我深有感触.以前学习uml这门课的时候,并没有好好学,那时我认为这门课并没有什 ...
- Hadoop阅读笔记(七)——代理模式
关于Hadoop已经小记了六篇,<Hadoop实战>也已经翻完7章.仔细想想,这么好的一个框架,不能只是流于应用层面,跑跑数据排序.单表链接等,想得其精髓,还需深入内部. 按照<Ha ...
- Hadoop阅读笔记(六)——洞悉Hadoop序列化机制Writable
酒,是个好东西,前提要适量.今天参加了公司的年会,主题就是吃.喝.吹,除了那些天生话唠外,大部分人需要加点酒来作催化剂,让一个平时沉默寡言的码农也能成为一个喷子!在大家推杯换盏之际,难免一些画面浮现脑 ...
- Hadoop阅读笔记(五)——重返Hadoop目录结构
常言道:男人是视觉动物.我觉得不完全对,我的理解是范围再扩大点,不管男人女人都是视觉动物.某些场合(比如面试.初次见面等),别人没有那么多的闲暇时间听你诉说过往以塑立一个关于你的完整模型.所以,第一眼 ...
- Hadoop阅读笔记(四)——一幅图看透MapReduce机制
时至今日,已然看到第十章,似乎越是焦躁什么时候能翻完这本圣经的时候也让自己变得更加浮躁,想想后面还有一半的行程没走,我觉得这样“有口无心”的学习方式是不奏效的,或者是收效甚微的.如果有幸能有大牛路过, ...
随机推荐
- 前端flex布局学习笔记
flex布局,即为弹性布局,其为盒模型提供最大的灵活性,任何一个容器都可以指定为flex布局. eg:.box{ display:flex: } 行内元素也可以使用flex布局. 注意:设置flex布 ...
- ARTS-S ISO C
一些简称 ANSI: American National Standards Institute. ANSI是the International Organization for Standardiz ...
- 用Python抢到回家的车票,so easy!
“ 盼望着,盼望着,春节的脚步近了,然而,每年到这个时候,最难的,莫过于一张回家的火车票. 据悉,今年春运期间,全国铁路发送旅客人次同比将增长 8.0%.达到 4.4 亿人次. 2020 年铁 ...
- 记MAC地址、磁盘序列号的获取
import java.io.*; import java.net.Inet4Address; import java.net.InetAddress; import java.net.Network ...
- LAMPSecurity: CTF6 Vulnhub Walkthrough
镜像下载地址: https://www.vulnhub.com/entry/lampsecurity-ctf6,85/ 主机扫描: ╰─ nmap -p- -sV -oA scan 10.10.202 ...
- bossplayersCTF 1: Vulnhub Walkthrough
主机扫描: http://10.10.202.130/ <!--WkRJNWVXRXliSFZhTW14MVkwaEtkbG96U214ak0wMTFZMGRvZDBOblBUMEsK--> ...
- Bash脚本编程之变量与多命令执行
变量基础知识 程序由指令加数据所组成,而变量可以理解为数据来源的一种. 变量名可以理解为指向了某个内存空间的地址,对于变量的赋值可理解为向内存空间写入数据,对于变量的引用可理解为从内存空间读取数据. ...
- webpack 插件 ProvidePlugin 的使用方法和 eslint 配置
ProvidePlugin:自动加载模块,而不必到处 import 或 require .(点击查看官方文档) 使用方法: 配置 webpack.config.js文件里 plugins 属性 new ...
- 深入理解 ZK集群中通过Processor保证数据一致性
入口 书接上篇博客中的ZK集群启动后完成数据的统一性恢复后,来到启动ZkServer的逻辑,接下来的重点工作就是启动不同角色的对应的不同的处理器Processor 如上图查看ZooKeeperServ ...
- 精通awk系列(4):awk用法入门
回到: Linux系列文章 Shell系列文章 Awk系列文章 awk用法入门 awk 'awk_program' a.txt awk示例: # 输出a.txt中的每一行 awk '{print $0 ...