Pytorch Dataset和Dataloader 学习笔记(二)
Pytorch Dataset & Dataloader
Pytorch框架下的工具包中,提供了数据处理的两个重要接口,Dataset 和 Dataloader,能够方便的使用和加载自己的数据集。
数据的预处理,加载数据并转化为tensor格式
使用Dataset构建自己的数据
使用Dataloader装载数据
【数据】链接:https://pan.baidu.com/s/1gdWFuUakuslj-EKyfyQYLA
提取码:10d4
复制这段内容后打开百度网盘手机App,操作更方便哦
数据的预处理与加载
import torch
import numpy as np
from torch.utils.data import DataLoader, Dataset
## 1. 数据的处理,加载转化为tensor
x_data = 'X.csv'
y_data = 'y.csv'
x = np.loadtxt(x_data, delimiter=' ', dtype=np.float32)
y = np.loadtxt(y_data, delimiter=' ', dtype=np.float32).reshape(-1, 1)
x = torch.from_numpy(x[:, :])
y = torch.from_numpy(y[:, :])
torch.utils.data.Dataset
Dataset抽象类,用于包装构建自己的数据集,该类包括三个基本的方法:
- __init__ 进行数据的读取操作
- __getitem__ 数据集需支持索引访问
- __len__ 返回数据集的长度
## 2. 构建自己的数据集
class Mydataset(Dataset):
def __init__(self, train_data, label_data):
self.train = train_data
self.label = label_data
self.len = len(train_data)
def __getitem__(self, item):
return self.train[item], self.label[item]
def __len__(self):
return self.len
dataset = Mydataset(x, y)
samples = dataset.__len__()
print("总样本数:",samples)
torch.utils.data.Dataloader
Dataloader抽象类,构建可迭代的数据集装载器,从Dataset实例对象中按batch_size装载数据以送入训练。包含以下几个参数:
- batch_size 批大小
- shuffle 装载的batch是否乱序
- drop_last 不足batch大小的最后部分是否舍去
- num_workers 是否多进程读取数据
## 3. 创建数据集装载器
train_loader = DataLoader(dataset=dataset,
batch_size=64,
shuffle=True,
drop_last=True,
num_workers=4)
测试
if __name__ == "__main__":
iteration = 0
for train_data, train_label in train_loader:
print("x: ", train_data, "\ny: ", train_label)
iteration += 1
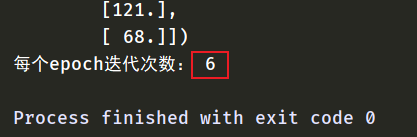
### 这里dataloader中drop_last为True,所以迭代次数应为 samples/batch_size = 6
print("每个epoch迭代次数:",iteration)

完整代码
import torch
import numpy as np
from torch.utils.data import DataLoader, Dataset
## 1. 数据的处理,加载转化为tensor
x_data = 'X.csv'
y_data = 'y.csv'
x = np.loadtxt(x_data, delimiter=' ', dtype=np.float32)
y = np.loadtxt(y_data, delimiter=' ', dtype=np.float32).reshape(-1, 1)
x = torch.from_numpy(x[:, :])
y = torch.from_numpy(y[:, :])
## 2. 构建自己的数据集
class Mydataset(Dataset):
def __init__(self, train_data, label_data):
self.train = train_data
self.label = label_data
self.len = len(train_data)
def __getitem__(self, item):
return self.train[item], self.label[item]
def __len__(self):
return self.len
dataset = Mydataset(x, y)
## 3. 创建数据集装载器
train_loader = DataLoader(dataset=dataset,
batch_size=64,
shuffle=True,
drop_last=True,
num_workers=4)
if __name__ == "__main__":
iteration = 0
samples = dataset.__len__()
print("总样本数:", samples)
for train_data, train_label in train_loader:
print("x: ", train_data, "\ny: ", train_label)
iteration += 1
### 这里dataloader中drop_last为True,所以迭代次数应为 samples/batch_size = 6
print("每个epoch迭代次数:",iteration)
Pytorch Dataset和Dataloader 学习笔记(二)的更多相关文章
- amazeui学习笔记二(进阶开发4)--JavaScript规范Rules
amazeui学习笔记二(进阶开发4)--JavaScript规范Rules 一.总结 1.注释规范总原则: As short as possible(如无必要,勿增注释):尽量提高代码本身的清晰性. ...
- 微信小程序学习笔记二 数据绑定 + 事件绑定
微信小程序学习笔记二 1. 小程序特点概述 没有DOM 组件化开发: 具备特定功能效果的代码集合 体积小, 单个压缩包体积不能大于2M, 否则无法上线 小程序的四个重要的文件 *js *.wxml - ...
- WPF的Binding学习笔记(二)
原文: http://www.cnblogs.com/pasoraku/archive/2012/10/25/2738428.htmlWPF的Binding学习笔记(二) 上次学了点点Binding的 ...
- AJax 学习笔记二(onreadystatechange的作用)
AJax 学习笔记二(onreadystatechange的作用) 当发送一个请求后,客户端无法确定什么时候会完成这个请求,所以需要用事件机制来捕获请求的状态XMLHttpRequest对象提供了on ...
- [Firefly引擎][学习笔记二][已完结]卡牌游戏开发模型的设计
源地址:http://bbs.9miao.com/thread-44603-1-1.html 在此补充一下Socket的验证机制:socket登陆验证.会采用session会话超时的机制做心跳接口验证 ...
- JMX学习笔记(二)-Notification
Notification通知,也可理解为消息,有通知,必然有发送通知的广播,JMX这里采用了一种订阅的方式,类似于观察者模式,注册一个观察者到广播里,当有通知时,广播通过调用观察者,逐一通知. 这里写 ...
- java之jvm学习笔记二(类装载器的体系结构)
java的class只在需要的时候才内转载入内存,并由java虚拟机的执行引擎来执行,而执行引擎从总的来说主要的执行方式分为四种, 第一种,一次性解释代码,也就是当字节码转载到内存后,每次需要都会重新 ...
- Java IO学习笔记二
Java IO学习笔记二 流的概念 在程序中所有的数据都是以流的方式进行传输或保存的,程序需要数据的时候要使用输入流读取数据,而当程序需要将一些数据保存起来的时候,就要使用输出流完成. 程序中的输入输 ...
- 《SQL必知必会》学习笔记二)
<SQL必知必会>学习笔记(二) 咱们接着上一篇的内容继续.这一篇主要回顾子查询,联合查询,复制表这三类内容. 上一部分基本上都是简单的Select查询,即从单个数据库表中检索数据的单条语 ...
随机推荐
- php 获取某年后的日期
比如两年后:date('Y-m-d',strtotime('+2 year')) 月份year改成month
- python-内置函数-compile,eval,exec
#将字符串,编译成python代码 compile()#执行,有返回值,执行表达式并获取结果 eval()#执行python代码,无返回值,接收:代码或者字符串 exec() s = "pr ...
- IOCP实现高并发以及与传统socke编程的对比
前言 传统socket编程中服务端一般为每一个客户端创建一个线程(一对一).这样虽然可以使程序的结构简单明了并且方便对数据处理,但是这些都是建立在创建多个线程的基础上,也就是以牺牲线程为代价.一旦有大 ...
- Go的Waitgroup和锁
学 Go 的时候知道 Go 语言支持并发,最简单的方法是通过 go 关键字开启 goroutine 即可.可在工作中,用的是 sync 包的 WaitGroup,然而这样还不够,当多个 gorouti ...
- Kubernetes入门,使用minikube 搭建本地k8s 环境
这是一篇 K8S 的 HelloWorld,在学习K8S官方文档时搭建环境搭建的一个记录,照着文档下来还是比较顺利的. 一.安装kubectl 下载 kubectl curl -LO "ht ...
- readdir_r()读取目录内容
readdir()在多线程操作中不安全,Linux提供了readdir_r()实现多线程读取目录内容操作. #include <stdio.h> #include <stdlib.h ...
- Zoho:SaaS行业的“紫色奶牛”
以下文章来源于:中国软件网,作者王锦宝 蓝天白云的映衬下,一群黑白相间的奶牛在绿草场自由玩耍,这种田园牧歌场景看久了,总会引起审美疲劳.假如突然出现一头紫色奶牛,你肯定会眼前一亮,把所有注意力集中到紫 ...
- 2.HTML案例二 头条页面
4 HTML案例-头条页面 4.1 案例效果 4.2 案例分析 4.2.1 div布局的进阶 想要将div布局成案例效果,首先需要对多个div进行区分,再分别设置每一个div自身的效果. 1)div的 ...
- [BD] HBase
NoSQL数据库 关系型数据库:用表格的行-列来保存数据,OLTP,写入多,行式存储 非关系型数据库:只用来存储数据,业务逻辑由应用程序处理,OLAP,查询多,列式存储 常见NoSQL数据库 Redi ...
- body元素的常用属性
一.bgcolor属性 a.bgcolor 设置文档的背景颜色. b.用法 <body bgcolor="red"> body的常用属性! </body> ...