scrapy获取汽车之家数据
1、创建scrapy项目
>scrapy startproject scrapy_carhome
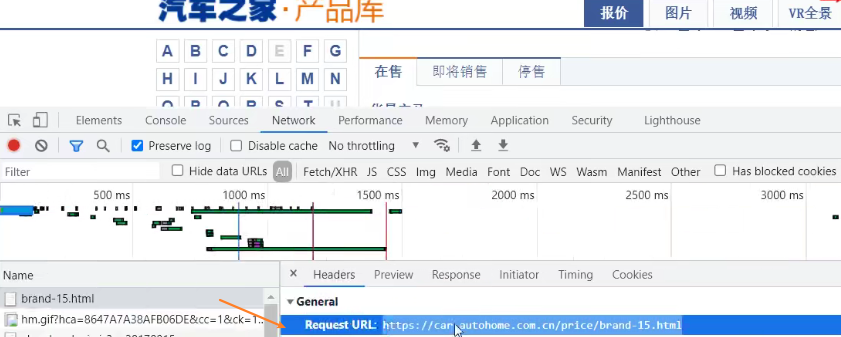
2、找到对应接口
3、创建爬虫文件
> cd scrapy_carhome\scrapy_carhome\spiders
scrapy_carhome\scrapy_carhome\spiders> scrapy genspider car https://car.autohome.com.cn/price/brand-15.html
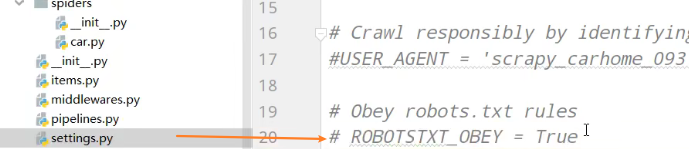
4、注释robots协议
//div[@class="main-title"]/a/text()
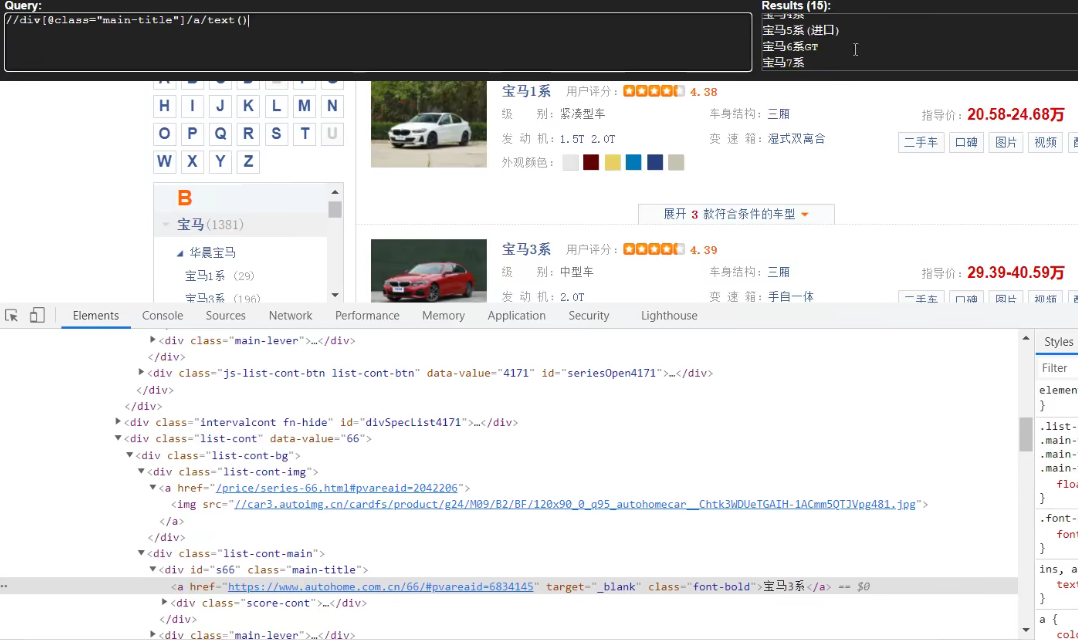
//div[@class="main-lever"]//span/span/text()

car.py
import scrapy class CarSpider(scrapy.Spider):
name = 'car'
allowed_domains = ['https://car.autohome.com.cn/price/brand-15.html']
# 注意如果你的请求的接口是html为结尾的 那么是不需要加/的
start_urls = ['https://car.autohome.com.cn/price/brand-15.html'] def parse(self, response):
name_list = response.xpath('//div[@class="main-title"]/a/text()')
price_list = response.xpath('//div[@class="main-lever"]//span/span/text()')
# 遍历列表
for i in range(len(name_list)):
name = name_list[i].extract()
price = price_list[i].extract()
print(name,price)
运行爬虫文件
scrapy_carhome\scrapy_carhome\spiders>scrapy crawl car



scrapy获取汽车之家数据的更多相关文章
- PuppeteerSharp+AngleSharp的爬虫实战之汽车之家数据抓取
参考了DotNetSpider示例, 感觉DotNetSpider太重了,它是一个比较完整的爬虫框架. 对比了以下各种无头浏览器,最终采用PuppeteerSharp+AngleSharp写一个爬虫示 ...
- python爬虫——汽车之家数据
相信很多买车的朋友,首先会在网上查资料,对比车型价格等,首选就是"汽车之家",于是,今天我就给大家扒一扒汽车之家的数据: 一.汽车价格: 首先获取的数据是各款汽车名称.价格范围以及 ...
- scrapy获取当当网中数据
yield 1. 带有 yield 的函数不再是一个普通函数,而是一个生成器generator,可用于迭代 2. yield 是一个类似 return 的关键字,迭代一次遇到yield时就返回yiel ...
- 爬虫实战:汽车之家配置页面 破解伪元素和混淆JS
本篇介绍如何破解汽车之家配置页面的伪元素和混淆的JS. ** 温馨提示:如需转载本文,请注明内容出处.** 本文链接:https://www.cnblogs.com/grom/p/9242156.ht ...
- 汽车之家店铺数据抓取 DotnetSpider实战[一]
一.背景 春节也不能闲着,一直想学一下爬虫怎么玩,网上搜了一大堆,大多都是Python的,大家也比较活跃,文章也比较多,找了一圈,发现园子里面有个大神开发了一个DotNetSpider的开源库,很值得 ...
- 汽车之家店铺商品详情数据抓取 DotnetSpider实战[二]
一.迟到的下期预告 自从上一篇文章发布到现在,大约差不多有3个月的样子,其实一直想把这个实战入门系列的教程写完,一个是为了支持DotnetSpider,二个是为了.Net 社区发展献出一份绵薄之力,这 ...
- 汽车之家店铺数据抓取 DotnetSpider实战
一.背景 春节也不能闲着,一直想学一下爬虫怎么玩,网上搜了一大堆,大多都是Python的,大家也比较活跃,文章也比较多,找了一圈,发现园子里面有个大神开发了一个DotNetSpider的开源库,很值得 ...
- python3 爬取汽车之家所有车型数据操作步骤(更新版)
题记: 互联网上关于使用python3去爬取汽车之家的汽车数据(主要是汽车基本参数,配置参数,颜色参数,内饰参数)的教程已经非常多了,但大体的方案分两种: 1.解析出汽车之家某个车型的网页,然后正则表 ...
- Python 爬取汽车之家口碑数据
本文仅供学习交流使用,如侵立删!联系方式见文末 汽车之家口碑数据 2021.8.3 更新 增加用户信息参数.认证车辆信息等 2021.3.24 更新 更新最新数据接口 2020.12.25 更新 添加 ...
随机推荐
- MFC获取文件路径和文件夹路径
MFC的界面中,需要实现这样两个功能: 1.在界面上加一个按钮,单击按钮弹出一个对话框选择文件,在工程中获得文件的路径: 2.在界面上加一个按钮,单击按钮弹出一个对话框选择文件夹,在工程中获取文件夹的 ...
- Apache Struts2 S2-013远程代码执行漏洞复现
墨者学院开的靶场 进入环境 Struts2-013好家伙,框架直接写脸上,怕人看不出来= = 看了看源码什么的啥都没发现= = 去了解了一下这个漏洞,爬回来继续做 漏洞原理 struts2的标签中&l ...
- js高阶
1. 面向对象编程介绍 1.1 两大编程思想 --- 面向过程 --- 面向对象 1.2 面向过程编程 POP 面向过程就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候在一 ...
- WPF实现聚光灯效果
WPF开发者QQ群: 340500857 | 微信群 -> 进入公众号主页 加入组织 前言 效果仿照 CSS聚光灯效果 实现思路: 1. 设置底部Canvas背景色 #222222 . 2. ...
- 怎样将.h文件添加到项目中
作为C++的初学者,在运行别人的程序时,第一个遇到的问题就是无法将程序中写到的.h文件包含到项目中来.下面来写一下处理方法.本文以easyx.h为例进行说明 首先右键你的工程 选择Properties ...
- Vulnhub实战-DockHole_1靶机👻
Vulnhub实战-DockHole_1靶机 靶机地址:https://www.vulnhub.com/entry/darkhole-1,724/ 1.描述 我们下载下来这个靶机然后在vmware中打 ...
- PAT (Basic Level) Practice (中文)1014 福尔摩斯的约会 (20分)
1014 福尔摩斯的约会 (20分) 带侦探福尔摩斯接到一张奇怪的字条:我们约会吧! 3485djDkxh4hhGE 2984akDfkkkkggEdsb s&hgsfdk d&Hys ...
- 安装早期老版本 Visual Studio
安装早期老版本 Visual Studio https://visualstudio.microsoft.com/zh-hans/vs/older-downloads/
- 为什么阿里巴巴开发手册中强制要求 POJO 类使用包装类型?NPE问题防范
封面:学校内的秋天 背景:写这个的原因,也是我这两天凑巧看到的,虽然我一直有 alibaba Java 开发手册,也看过不少次,但是一直没有注意过这个问题 属于那种看过,但又没完全看过 一起来看看吧冲 ...
- Hadoop集群的配置(一)
摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得.以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问题.但是网上一些文档大多互相抄 ...