vivo统一告警平台设计与实践
一、背景
一套监控系统检测和告警是密不可分的,检测用来发现异常,告警用来将问题信息发送给相应的人。vivo监控系统1.0时代各个监控系统分别维护一套计算、存储、检测、告警收敛逻辑,这种架构下对底层数据融合非常不利,也就无法实现监控系统更广泛场景的应用,所以需要进行整体规划,重新对整个监控系统架构进行调整,在这样的背景下统一监控的目标被确立。
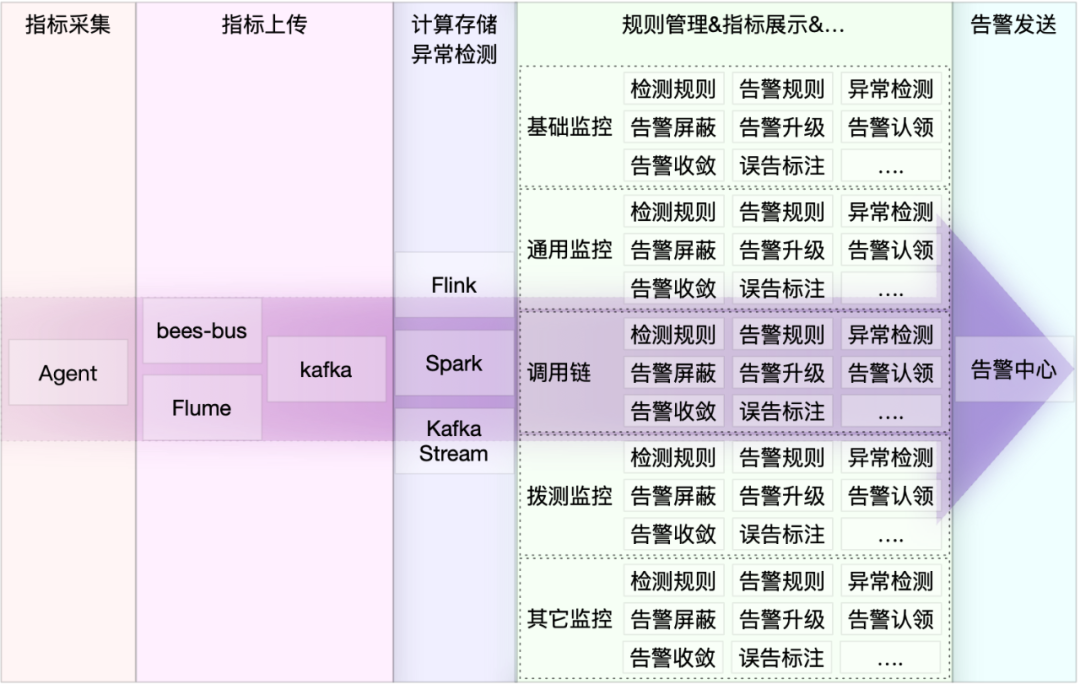
以前监控被划分为基础监控、通用监控、调用链、日志监控、拨测监控等几大系统,统一监控的目标是将各个监控指标数据进行统一计算、统一存储、统一检测、统一告警、统一展示。这里不作赘述,后面会出一期vivo监控系统演进的文章进一步说明。
上面我们说了监控统一的大背景。以前各个监控系统会各自进行告警收敛、消息组装等工作,为了减少冗余,需要将收敛等工作由一个服务统一做处理,与此同时告警中心平台也到了更新迭代的阶段,这样就需要建设一个对内部各业务统一提供告警收敛、消息组装、告警发送的告警平台,有了这个构想,我们准备将各系统告警收敛能力与告警发送能力下沉,将统一告警服务做成一个与各监控服务解偶的通用服务。
二、现状分析
对于1.0时代的监控系统来说,如图1所示各个监控系统要先进行告警收敛,然后分别和老的告警中心进行对接,才能将告警消息发送出来。每一套系统都要单独进行维护一套规则,有很多重复功能建设,而实际这些功能具有高度通用性,完全可以建立合理模型对异常检测服务生成的异常进行统一处理,从而生成问题,然后进行统一的消息组装,最后发送告警消息。
(图1 老监控系统告警流程图)
在监控系统中一个异常从被检测出来到最终发出告警有几个重要概念:
异常
在一个检测窗口(窗口大小可以自定义),一个或几个指标值达到检测规则定义的异常阈值,就产生一个异常。如图2所示,检测规则定义当指标值在一个检测窗口为6的检测周期内,有3个数据点超过阈值就认为有异常,我们简称这个检测规则为6-3,如图所示第一个检测窗口内(蓝色虚线筐内)只有6和7两个点的指标值超过阈值(95),不满足6-3的条件,所以第一个检测窗口没有异常。在第二个检测窗口内(绿色虚线框内)有6、7、8三个点的指标值超过阈值(95),所以第二个窗口就是一个异常。
问题
一个连续的周期内产生的所有同类异常的集合,我们称之为问题。如图2所示,第二个检测窗口就是一个异常,同时这个异常也会对应有一个问题A,如果第三个检测窗口也是一个异常,那么这个异常对应的问题也是A,所以问题和异常是一对多的关系。
告警
当一个问题通过告警系统将消息以短信、电话、邮件等方式告知给用户时,我们称之为一条告警。
恢复
当问题对应的异常不满足检测规则定义的异常条件时,就认为所有异常都恢复了,同时问题也认为恢复了,恢复也会发送相应的恢复通知。
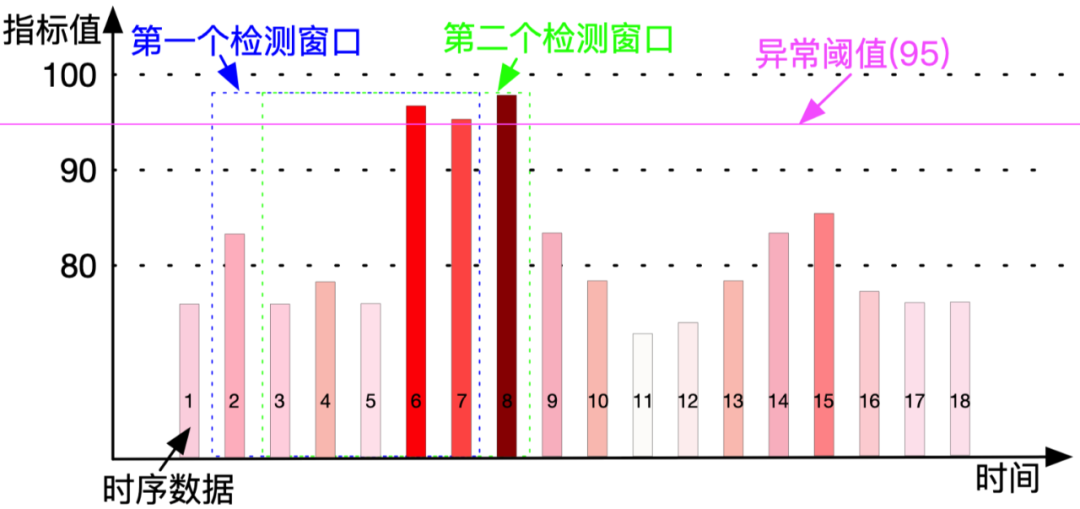
(图2 时序数据异常检测原理图)
三、衡量指标
一个系统我们如何衡量它的好坏,如何提升它,如何管理它?管理学大师彼得·德鲁克曾说“你如果无法度量它,就无法管理它(If you can’t measure it, you can’t manage it)”。从这里可以看出,如果想全面管理提升一个系统,就需要先对它的各项性能指标有一个衡量,知道它的薄弱点在哪里,找到病症所在才能对症下药。
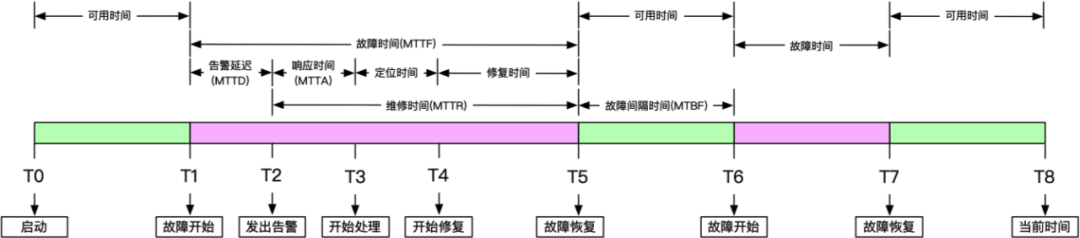
(图3 运维指标时间节点关系图)
图3是监控系统运营指标和对应时间节点关系图,主要体现了MTTD、MTTA、MTTF、MTTR、MTBF等指标与时间节点的对应关系,这些指标对于提升系统性能,帮助运维团队及早发现问题有很高的参考价值。业界有很多云告警平台也很注重这些指标,下面我们着重介绍一下MTTA、MTTR这两个和告警平台关系紧密的指标:
MTTA(Mean time to acknowledge,平均应答时间):
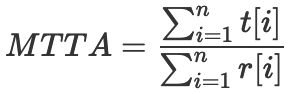
(图4 MTTA计算公式)
t[i] -- 监控系统运行期间第i个服务出现问题后运维团队或者研发人员响应问题的时间;
r[i] -- 监控系统运行期间第i个服务出现问题的总次数。
平均应答时间是运维团队或者研发团队响应所有问题所花费的平均时间。MTTA度量标准用于衡量运维团队或研发团队的响应能力和警报系统的效率。通过跟踪和最小化MTTA,项目管理团队可以优化流程,提高问题解决效率,保障服务可用性,提升用户满意度[1]。
MTTR(Mean Time To Repair,平均维修时间):
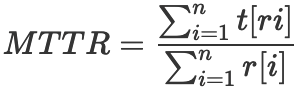
(图5 MTTR计算公式[2])
t[ri] -- 监控系统运行期间第i个服务出现r次告警后服务恢复正常状态的总时间
r[i] -- 监控系统运行期间第i个服务出现告警的总次数
平均修复时间(MTTR)是修复系统并将其恢复到正常功能所需的平均时间。运维或研发人员开始处理异常,MTTR便开始计算,并且一直进行到被中断的服务完全恢复(包括所需的任何测试时间)为止。在IT服务管理行业中,MTTR中的R并不总是表示维修。它也可以表示恢复,响应或解决。尽管这些指标都对应MTTR,但是它们都有各自的含义,因此,要弄清楚要使用哪个MTTR,有助于我们更好的分析理解问题。让我们简要地看一下它们各自的含义:
1)平均恢复时间(Mean time to recovery)是从系统告警中恢复所需的平均时间。这涵盖了从服务异常导致告警到恢复正常的整个过程。MTTR是衡量整个恢复过程速度的指标。
2)平均响应时间(Mean time to respond)表示从出现第一个告警开始到系统从故障中恢复到正常状态所需的平均时间,不包括告警系统中的任何延迟。该MTTR通常用于网络安全中,以衡量团队缓解系统攻击的效率。
3)平均解决时间(Mean time to resolve)表示完全解决系统故障所花费的平均时间,包括检测故障、诊断问题以及确保故障不再发生来解决问题所需的时间。此 MTTR 指标主要用于衡量不可预见事件的解决过程,而不是服务请求。
提升 MTTA 的核心是找对人、找到人[3],只有在最短的时间内找对能处理问题的人才能有效提升MTTR。通常在生产实践过程中我们会遇到“告警泛滥”的问题,大量的告警出现时需要运维人员或者开发同学去解决,对于应激敏感的同学来说很容易出现“狼来了”的现象,只要收到告警就会很紧张,同时当大量的告警信息频发骚扰我们运维人员,会引发告警疲劳,体现为不重要的事件太多,最根本的问题较少,频繁处理普通事件,重要的信息淹没在汪洋大海中。[4]
(图6 告警泛滥问题图[5])
四、功能设计
通过上面两个重要指标的分析,我们总结出要从告警数量、告警收敛、告警升级等方面着手,减少告警发送的数量,提升告警准确性,最终提升解决问题的效率,降低问题恢复时长。下面我们从系统和功能层面说明如何降低告警量,把真正有价值的告警信息发送到用户手中。本文也将重点围绕告警消息收敛进行讲解。
从图1中可以看出各个监控系统中都有很多重复的功能模块,所以针对这些功能模块我们可以将其抽离出来,如图7所示将告警收敛、告警屏蔽、告警升级等能力统一建设在统一告警服务中。这种架构下统一告警服务与检测相关服务完全解耦,在能力上具有一定的通用性。例如其它有告警或消息收敛需求的业务团队想接入统一告警,统一告警要能满足消息收敛发送的需求,同时也要满足消息直接发送的需求。统一告警会提供灵活可配置的消息发送方式,提供简单、多样的功能满足各类需求。
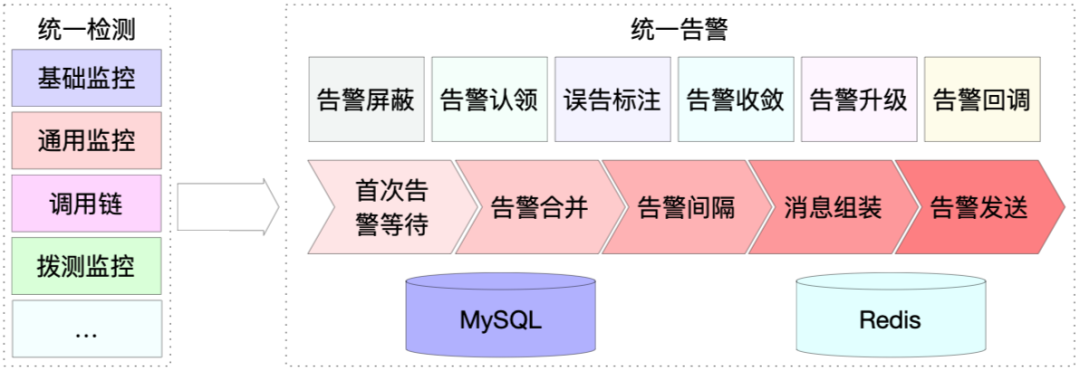
(图7 统一告警系统结构图)
4.1 告警收敛
对于告警平台每天会产生数以万计的告警,这些告警对于运维或开发人员都需要去分析、甄别优先级、并处理故障。数以万计的告警如果不加收敛每条异常都发送告警,势必会增大运维人员的工作压力,当然也不是所有的告警都需要并且有必要发送给运维人员进行处理。所以我们需要对告警通过多种手段进行收敛,下面我们从四个方面介绍一下如何进行告警收敛。
首次告警等待
当一个异常产生之后我们不会立即去做告警,而是通过等待一段时间才会去做告警发送,一般这个时间可以通过系统自定义,这个值如果太大就会影响告警延迟,太小不能提升告警合并效果。例如首次告警等待时间为5s,当一个服务下节点1出现A指标异常,5s内节点2也出现了A指标异常,那么发送告警时节点1和节点2会被合并到一起发送告警通知。
告警间隔
问题在没有恢复前,系统会根据告警间隔的配置每隔一段时间发送一条告警信息,告警间隔用来控制告警发送的频率。
异常收敛维度
异常收敛维度用来将同个维度下的异常合并在一起。例如同个节点路径A下,通过同一个检测规则产生的异常,会在告警发送的时候根据配置的异常收敛维度合并在一起。
消息合并维度
当多个异常收敛成一个问题,在发送告警的时候会涉及到消息合并,消息合并维度就是用来指定哪些维度可以合并。可能这样理解有些晦涩,我们可以通过图8看一下从异常到消息的转换过程。
假如一个异常有两个维度名字和性别,当这两个异常经过统一告警,我们会根据配置的收敛策略进行合并,从图中我们可以看到性别被定义为异常收敛维度,通常异常收敛维度的选择一定是两个或两个以上具有相同的属性的异常,这样在消息合并后只取相同属性的同一个值,对应到示例图,我们会将${sex}占位符替换成男。而名字是被定义为告警合并维度,就表示所有异常中名字是都要展示在消息文本中,所以在消息合并的时候我们会将${name}占位符对应的信息一一拼接在消息文本中。
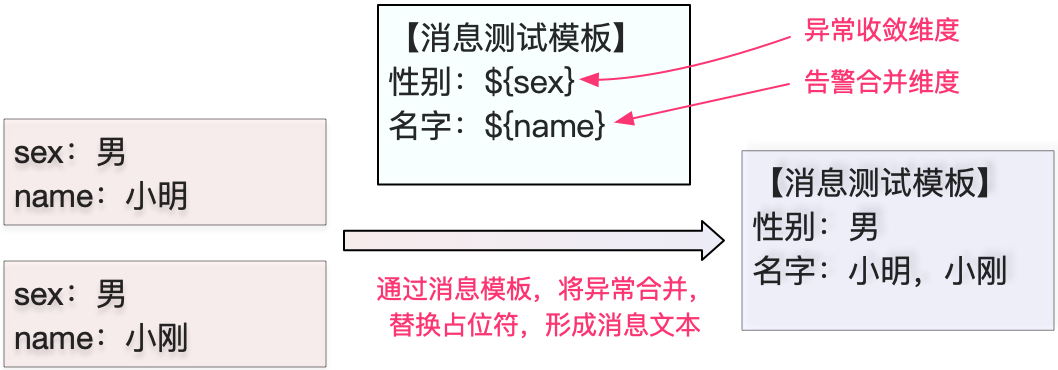
(图8 消息文本替换示意图 )
4.2 告警认领
当出现告警后如果有人认领了该告警,那么后续相同告警只会发送给告警认领人。告警认领主要是为了解决告警有人跟进后,减少将告警发给其他人员,也能从一定程度上解决告警被重复处理的问题。被认领的告警可以取消认领。
4.3 告警屏蔽
对于同一个问题,可以设置告警屏蔽,后续如果有该问题对应的告警产生,那么将不会被发送出去。告警屏蔽能减少故障在定位解决过程中,或者服务在发版变更过程中造成的告警,能有效减少无效告警对运维人员造成的困扰,屏蔽可以设置为周期性的,也可以设置为屏蔽某一时段,当然也可以取消屏蔽。
4.4 告警回调
当告警规则配置了回调,那么当产生告警,就会调用回调接口,使服务或业务恢复正常。告警回调的目的是当某个服务有告警产生,希望系统能够通过一些自动化的配置,使服务恢复到正常状态,缩短故障恢复的时间,也能够紧急情况下第一时间快速恢复服务。
4.5 误告标注
对于一个问题,用户可以通过误告标注备注该异常是否为误告警。误告标注的主要目的是通过标注让系统开发人员知道异常检测过程中,哪写点还需要提升优化,提高告警的准确性,为用户提供真实有效的告警提供保障。
4.6 告警升级
当告警发生一定时间仍没有恢复,那么系统就会根据配置自动进行告警升级处理,然后将告警升级信息通过配置发送给对应的人员。告警升级一定程度上是为了缩短MTTA,当告警长时间未恢复,可以认为故障没有及时得到响应,这时就需要更高级别的人员介入处理。
如图9所示,每天告警系统会发送大量的告警,当然这些告警会分别发送给不同服务的告警接收人。告警并不是越多越好,而是应该第一时间准确反映出服务的异常情况,所以如何提升有效告警,提高告警准确性,减少告警量至关重要。通过以上系统设计和功能设计能够有效减少重复告警发送。
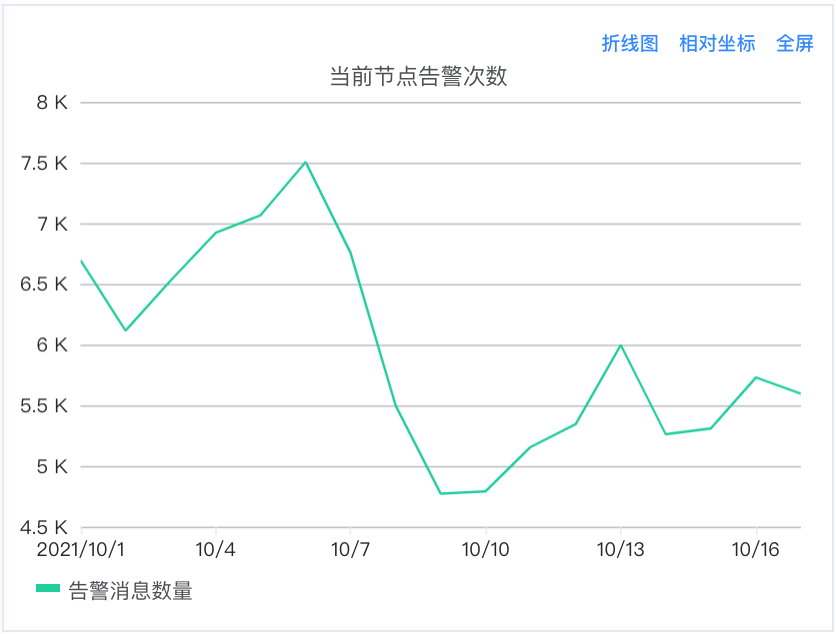
(图9 主机监控告警次数图)
五、架构设计
上面我们从系统和功能层名讲解了如何针对老架构下存在的各种问题进行解决,那么对于这个构想我们应该用一套什么架构来实现。
下面我们看下如何设计这套架构。统一告警作为整个监控最后一环,既要满足告警发送能力也要满足业务服务发送通知的需求,所以统一告警的各种能力要具有通用性。统一告警服务要做到与其它服务低耦合,尤其是与已有监控系统做到解偶,这样才能真正把通用能力释放出来。服务要能做到根据业务场景的不同适配不同的业务逻辑,比如有的业务需要做告警收敛,有的业务不需要,那么服务要提供灵活的接入方式以适用业务需要。
如图10所示,统一告警核心逻辑由收敛服务实现,收敛服务可以消费kafka中的异常,也可以通过RestFul接口接收推送过来的异常,异常会先经过异常处理生成一个问题,然后将问题和异常存入MySql库,经过告警收敛模块问题会被推送到Redis延时队列中,延时队列会用来控制消息出队时间,消息从队列取出之后会进行文本组装等操作,最后会通过配置发送出去。
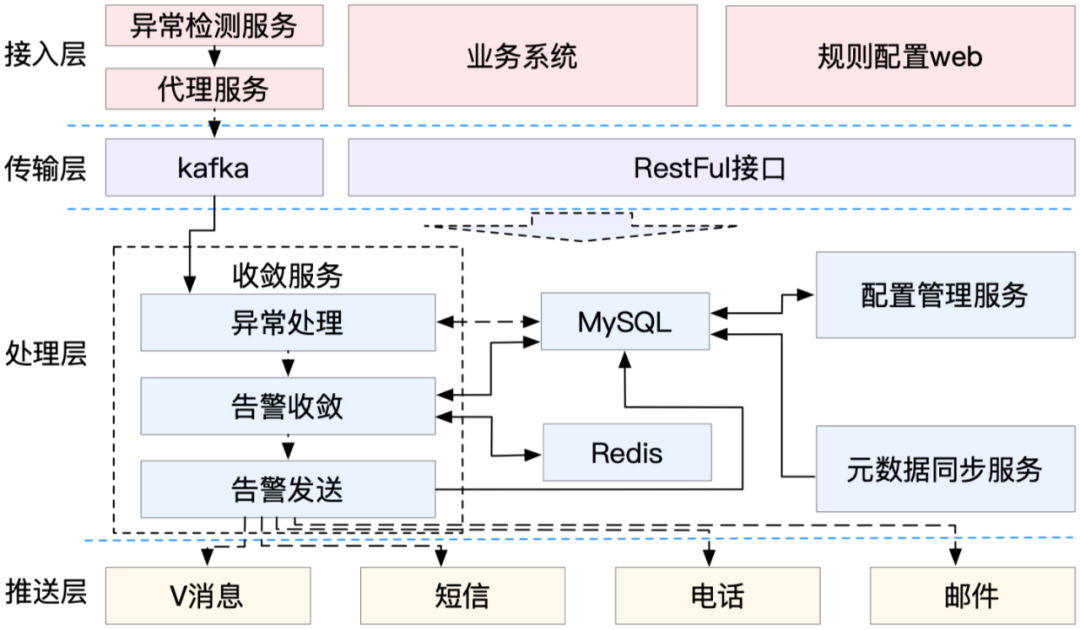
(图10 统一告警架构图)
配置管理服务用来管理应用、事件、告警等配置信息,元数据同步服务用来从其它服务同步告警收敛所需的元数据。
六、核心实现
统一告警的核心是告警收敛,收敛的目的就是减少发送重复的告警消息,避免因为大量的告警对于告警接收人造成告警麻痹。
前文已经说到使用延时队列做告警收敛,延时队列在电商和支付项目中使用较多,比如商品下单后10分钟未支付就要自动取消订单。在告警系统中使用延时队列主要目的是,在一定的时间内尽可能多的将同一个问题对应的异常合并在一起,减少告警发送的数量。举个例,如果一个服务A有三个节点,当发生异常时,一般情况下每个节点的异常都会生成一条告警发送出去,但是经过告警收敛时候我们可以将三个节点的告警合并,由一条告警做通知。
延时队列有很多种方式实现,这里我们选择了Redis实现延时队列,选用 Redis 延时队列主要的原因就是其支持高性能的 score 排序,同时 Redis 的持久化特性,保证了消息的消费和存贮问题。
如图11所示,一个问题通过一系列校验去重之后放入redis延时队列,队列中到期时间最小的问题会被排到最前面,同时有一个监听任务不断查看队列中是否有过期的任务,如果有过期的任务会被取出,取出的消息会经过消息组装等操作最终形成一条消息文本,然后根据配置通过不同的通道发送出去。
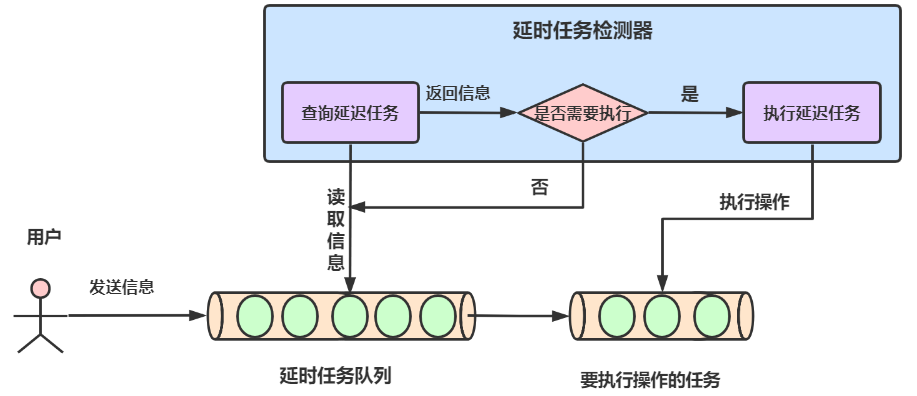
(图11 延时任务执行原理图[6])
七、未来展望
基于统一告警服务定位来看,告警服务要能简单、高效、准确的告诉运维或者开发人员,哪里有故障需要去处理。所以对于后续服务的建设,应该考虑如何进一步减少人为的配置,增强告警智能化收敛的能力,同时还要增强根因定位的能力,以上通过AI的加持能够很好的解决此类问题。目前各大厂商都在向着AIOps探索前进,并且已经有一些产品投入使用,但是AIOps何时大规模落地,就目前来看还需要一段时间。相较于AI的使用,当前最紧迫的就是让统一告警串联起上下游服务,从而打通数据,为数据流转铺平道路,增强服务的自动化程度,并且支持从更高维度实现告警发送,为故障的发现和解决提供更准确的信息。
八、参考资料
[1]What are MTTR, MTBF, MTTF, and MTTA? A guide to Incident Management metrics
[2]平均修复时间[Z].
作者:vivo互联网服务器团队-Chen Ningning
vivo统一告警平台设计与实践的更多相关文章
- vivo互联网机器学习平台的建设与实践
vivo 互联网产品团队 - Wang xiao 随着广告和内容等推荐场景的扩展,算法模型也在不断演进迭代中.业务的不断增长,模型的训练.产出迫切需要进行平台化管理.vivo互联网机器学习平台主要业务 ...
- vivo 全球商城:商品系统架构设计与实践
一.前言 随着用户量级的快速增长,vivo官方商城v1.0的单体架构逐渐暴露出弊端:模块愈发臃肿.开发效率低下.性能出现瓶颈.系统维护困难. 从2017年开始启动的v2.0架构升级,基于业务模块进行垂 ...
- vivo 基于 JaCoCo 的测试覆盖率设计与实践
作者:vivo 互联网服务器团队- Xu Shen 本文主要介绍vivo内部研发平台使用JaCoCo实现测试覆盖率的实践,包括JaCoCo原理介绍以及在实践过程中遇到的新增代码覆盖率统计问题和频繁发布 ...
- Redis 在 vivo 推送平台的应用与优化实践
一.推送平台特点 vivo推送平台是vivo公司向开发者提供的消息推送服务,通过在云端与客户端之间建立一条稳定.可靠的长连接,为开发者提供向客户端应用实时推送消息的服务,支持百亿级的通知/消息推送,秒 ...
- 工作流引擎在vivo营销自动化中的应用实践 | 引擎篇03
作者:vivo 互联网服务器团队- Cheng Wangrong 本文是<vivo营销自动化技术解密>的第4篇文章,分析了在营销自动化业务引入工作流技术的背景和工作流引擎的介绍,同时介绍了 ...
- 《开源安全运维平台OSSIM最佳实践》
<开源安全运维平台OSSIM最佳实践> 经多年潜心研究开源技术,历时三年创作的<开源安全运维平台OSSIM最佳实践>一书即将出版.该书用80多万字记录了,作者10多年的IT行业 ...
- 携程实时计算平台架构与实践丨DataPipeline
文 | 潘国庆 携程大数据平台实时计算平台负责人 本文主要从携程大数据平台概况.架构设计及实现.在实现当中踩坑及填坑的过程.实时计算领域详细的应用场景,以及未来规划五个方面阐述携程实时计算平台架构与实 ...
- vivo推送平台架构演进
本文根据Li Qingxin老师在"2021 vivo开发者大会"现场演讲内容整理而成.公众号回复[2021VDC]获取互联网技术分会场议题相关资料. 一.vivo推送平台介绍 1 ...
- ML平台_微博深度学习平台架构和实践
( 转载至: http://www.36dsj.com/archives/98977) 随着人工神经网络算法的成熟.GPU计算能力的提升,深度学习在众多领域都取得了重大突破.本文介绍了微博引入深度学 ...
随机推荐
- Pandas高级教程之:时间处理
目录 简介 时间分类 Timestamp DatetimeIndex date_range 和 bdate_range origin 格式化 Period DateOffset 作为index 切片和 ...
- 【Azure 云服务】Azure Cloud Service 为 Web Role(IIS Host)增加自定义字段 (把HTTP Request Header中的User-Agent字段增加到IIS输出日志中)
问题描述 把Web Role服务发布到Azure Cloud Service后,需要在IIS的输出日志中,把每一个请求的HTTP Request Header中的User-Agent内容也输出到日志中 ...
- SQL SERVER数据库权限分配
1,新建 只能访问某一个表的只读用户. --添加只允许访问指定表的用户: exec sp_addlogin '用户名','密码','默认数据库名' ...
- golang []byte和string的高性能转换
golang []byte和string的高性能转换 在fasthttp的最佳实践中有这么一句话: Avoid conversion between []byte and string, since ...
- NX二次开发-调内部函数UGS::UICOMP_enum::set_width(int)更改BlockUI的枚举控件宽度
版本 NX11+VS2013 内容说明 这个内部函数的设置方法,我之前不会,是QQ群里的一位大佬分享出来的. 关于这块,我也百度搜了一下,找到了几个相关的. 1.直接手动修改BlockUI界面 在低版 ...
- docsify + Gitee Pages服务搭建开源项目网站
前言 base-admin从开源至今,已经收获了2k Stat,而我们一直都没有一份像样的在线文档,最近写了一个博客园随笔备份Java脚本,将博客随笔备份到本地,格式是md文档格式,就有意去找将md文 ...
- Java并行任务框架Fork/Join
Fork/Join是什么? Fork意思是分叉,Join为合并.Fork/Join是一个将任务分割并行运行,然后将最终结果合并成为大任务的结果的框架,父任务可以分割成若干个子任务,子任务可以继续分割, ...
- Linux常用命令介绍(满足日常操作)
大家好,今天来给大家分享一些Linux的常用命令,希望对大家有用 命令行的基本格式: 命令字 [选项] [参数] 其中,命令字.选项.参数之间用空格分开,多余的空格将被忽略.[ ]括起来的 ...
- 局域网(以太网与IEEE 802.3、IEEE 802.11、)
文章转自:https://blog.csdn.net/weixin_43914604/article/details/105016637 学习课程:<2019王道考研计算机网络> 学习目的 ...
- Shadertoy 教程 Part 4 - 绘制多个2D图形和混入
Note: This series blog was translated from Nathan Vaughn's Shaders Language Tutorial and has been au ...