JUC之认识ConcurrentHashMap
ConcurrentHashMap为什么广泛使用?回答这个问题之前先要回忆下几个基本的概念涉及hash的几个数据结构及锁优化(关于锁优化参考JMM之Java中锁概念的分类总结 - 池塘里洗澡的鸭子 - 博客园 (cnblogs.com))。
哈希表就是一种以 键-值(key-indexed) 存储数据的结构, 我们只要输入待查找的值即 key, 即可查找到其对应的值。这个key就是hash值。
哈希的思路很简单:如果所有的键都是整数,那么就可以使用一个简单的无序数组来实现——将键作为索引, 值即为其对应的值, 这样就可以快速访问任意键的值。这是对于简单的键的情况, 我们将其扩展到可以处理更加复杂的类型的键。
链式哈希表从根本上说是由一组链表构成。 每个链表都可以看做是一个“桶”,我们将所有的元素通过散列的方式放到具体的不同的桶中。 插入元素时, 首先将其键传入一个哈希函数(该过程称为哈希键) , 函数通过散列的方式告知元素属于哪个“桶”, 然后在相应的链表头插入元素。 查找或删除元素时, 用同们的方式先找到元素的“桶”, 然后遍历相应的链表, 直到发现我们想要的元素。 因为每个“桶”都是一个链表, 所以链式哈希表并不限制包含元素的个数。 然而, 如果表变得太大, 它的性能将会降低。
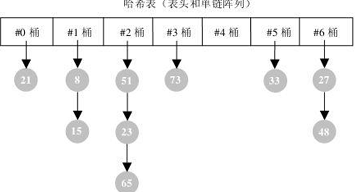
就HashMap而言,其是线程不安全的,在多线程环境下,使用 Hashmap 进行put 操作会引起死循环,导致 CPU 利用率接近 100%,所以在并发情况下不能使用 HashMap。
HashTable 和 HashMap 的实现原理几乎一样,差别在于:
1)HashTable 不允许 key 和 value 为 null
2)HashTable 是线程安全的但是 HashTable 线程安全的策略实现代价却太大了,简单粗暴,get/put 所有相关操作都是 synchronized 的,这相当于给整个哈希表加了一把大锁。多线程访问时候,只要有一个线程访问或操作该对象,那其他线程只能阻塞,相当于将所有的操作串行化,在竞争激烈的并发场景中性能就会非常差。
为解决并发环境线程安全问题ConcurrentHashMap诞生了。
JDK1.7和JDK1.8对ConcurrentHashMap实现原理并不一样,下面分别介绍:
JDK1.7中
ConcurrentHashMap重要的一个设计思想就是利用了锁优化中的减小锁粒度的方法思想。减小锁粒度是指缩小锁定对象的范围,从而减小锁冲突的可能性,从而提高系统的并发能力。减小锁粒度是一种削弱多线程锁竞争的有效手段。对于 HashMap 而言,最重要的两个方法是 get 与 set 方法,如果我们对整个 HashMap 加锁,可以得到线程安全的对象,但是加锁粒度太大。
ConcurrentHashMap在jdk1.7中就从加锁对象入手解决问题,采用了数组+Segment+分段锁的方式实现。它内部细分了若干个小的 HashMap,称之为段(Segment 的大小也被称为 ConcurrentHashMap 的并发度)。默认情况下一个 ConcurrentHashMap 被进一步细分为 16 个段,也就是锁的并发度。
如果需要在 ConcurrentHashMap 中添加一个新的表项,并不是将整个 HashMap 加锁,而是首先根据 hashcode 得到该表项应该存放在哪个段中,然后对该段加锁,并完成 put 操作。在多线程环境中,如果多个线程同时进行 put操作,只要被加入的表项不存放在同一个段中,则线程间可以做到真正的并行。
ConcurrentHashMap结构如下图:

图中观察可知ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成。 Segment 是一种可重入锁 ReentrantLock,在 ConcurrentHashMap 里扮演锁的角色, HashEntry 则用于存储键值对数据。一个 ConcurrentHashMap 里包含一个 Segment 数组, Segment 的结构和 HashMap类似,是一种数组和链表结构, 一个 Segment 里包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素, 每个 Segment 守护一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得它对应的 Segment 锁。同时从上面的结构我们可以了解到,ConcurrentHashMap 定位一个元素的过程需要进行两次 Hash 操作。第一次 Hash 定位到 Segment,第二次 Hash 定位到元素所在的链表的头部。
具体实现技术总结:ReentrantLock+Segment+HashEntry
JDK1.8以后
HashMap其自身进行了优化,采用了数组+链表+红黑树的实现方式来设计(参考JDK中HashMap的实现 - 池塘里洗澡的鸭子 - 博客园 (cnblogs.com)),内部大量采用 CAS 操作(参考Java并发基础之Compare And Swap/Set(CAS) - 池塘里洗澡的鸭子 - 博客园 (cnblogs.com))。其彻底放弃了 Segment 转而采用的是 Node,其设计思想也不再是JDK1.7 中的分段锁思想。
先看看ConcurrentHashMap数据结构:
1.数据结构:取消了 Segment 分段锁的数据结构,取而代之的是数组+链表+红黑树的结构。
2.保证线程安全机制:JDK1.7 采用 segment 的分段锁机制实现线程安全,其中segment 继承自 ReentrantLock。JDK1.8 采用 CAS+Synchronized 保证线程安全。
在ConcurrentHashMap各功能算法中,很多采用 方法确保线程安全。
方法确保线程安全。
3.锁的粒度:原来是对需要进行数据操作的 Segment 加锁,现调整为对每个数组元素加锁(Node)。
4.链表转化为红黑树:定位结点的 hash 算法简化会带来弊端,Hash 冲突加剧,因此在链表节点数量大于 8 时,会将链表转化为红黑树进行存储。
5.查询时间复杂度:从原来的遍历链表 O(n),变成遍历红黑树 O(logN)。
JUC之认识ConcurrentHashMap的更多相关文章
- JUC回顾之-ConcurrentHashMap源码解读及原理理解
ConcurrentHashMap结构图如下: ConcurrentHashMap实现类图如下: segment的结构图如下: package concurrentMy.juc_collections ...
- JUC集合之 ConcurrentHashMap
ConcurrentHashMap介绍 ConcurrentHashMap是线程安全的哈希表. HashMap, Hashtable, ConcurrentHashMap之间的关联如下: HashMa ...
- Java多线程系列--“JUC集合”04之 ConcurrentHashMap
概要 本章是JUC系列的ConcurrentHashMap篇.内容包括:ConcurrentHashMap介绍ConcurrentHashMap原理和数据结构ConcurrentHashMap函数列表 ...
- 最强Java并发编程详解:知识点梳理,BAT面试题等
本文原创更多内容可以参考: Java 全栈知识体系.如需转载请说明原处. 知识体系系统性梳理 Java 并发之基础 A. Java进阶 - Java 并发之基础:首先全局的了解并发的知识体系,同时了解 ...
- java核心-多线程(1)-知识大纲
Thread,整理一份多线程知识大纲,大写意 1.概念介绍 线程 进程 并发 2.基础知识介绍 Java线程类 Thread 静态方法&实例方法 Runnable Callable Futur ...
- java的各种集合为什么不安全(List、Set、Map)以及代替方案
我们已经知道多线程下会有各种不安全的问题,都知道并发的基本解决方案,这里对出现错误的情况进行一个实际模拟,以此能够联想到具体的生产环境中. 一.List 的不安全 1.1 问题 看一段代码: publ ...
- Java集合多线程安全
线程安全与不安全集合 线程不安全集合: ArrayList LinkedList HashMap HashSet TreeMap TreeSet StringBulider 线程安全集合: Vecto ...
- JUC源码分析-集合篇(一)ConcurrentHashMap
JUC源码分析-集合篇(一)ConcurrentHashMap 1. 概述 <HashMap 源码详细分析(JDK1.8)>:https://segmentfault.com/a/1190 ...
- 【JUC】JDK1.8源码分析之ConcurrentHashMap(一)
一.前言 最近几天忙着做点别的东西,今天终于有时间分析源码了,看源码感觉很爽,并且发现ConcurrentHashMap在JDK1.8版本与之前的版本在并发控制上存在很大的差别,很有必要进行认真的分析 ...
随机推荐
- 第51篇-SharedRuntime::generate_native_wrapper()生成编译入口
当某个native方法被调用时,一开始它会从解释入口进入,也就是我之前介绍的.由InterpreterGenerator::generate_native_entry()函数生成的入口例程.在这个例程 ...
- rocketmq实现延迟队列精确到秒级实现方案1-代理实现
简单的来说,就是rocketmq发送消息到broker的时候,判断是否定时消息, 如果是定时消息,将消息发送到代理服务(这个是一个独立的服务,需要自己开发,定时地把消息发送出去), 当然了消息用什么来 ...
- Cesium中文网——如何开发一款地图下载工具[一]
Cesium中文网:http://cesiumcn.org/ | 国内快速访问:http://cesium.coinidea.com/ Cesium中文网的朋友们的其中一个主题是:自己独立开发一款地图 ...
- 论文翻译:2021_DeepFilterNet: A Low Complexity Speech Enhancement Framework for Full-Band Audio based on Deep Filtering
论文地址:DeepFilterNet:基于深度滤波的全频带音频低复杂度语音增强框架 论文代码:https://github.com/ Rikorose/DeepFilterNet 引用:Schröte ...
- Vue.use()用法
通常我们引入一个第三方组件形式的插件进来时,我们在main.js里面需要Vue.use('该插件名字'),比如引入一个vant组件 那么我们如何自己也来尝试将自己封装的组件以Vue.use()的形式来 ...
- golang中结构体当做函数参数或函数返回值都会被拷贝
1. 结构体做函数的参数或返回值时,都会被重新拷贝一份如果不想拷贝,可以传递结构体指针 package main import "fmt" type Person struct { ...
- StringBuilder类练习
1 package cn.itcast.p2.stringbuffer.demo; 2 3 public class StringBuilderTest { 4 public static void ...
- JavaCV的摄像头实战之二:本地窗口预览
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Linux下查找软件,rpm命令 dpkg命令 apt命令
centos: 1.查询一个包是否被安装 rpm -q < package name> 2.列出已安装软件相关的所有包 rpm -qa < package name> ubun ...
- 【程序18】求s=a+aa+aaa+aaaa+aa...a的值
求s=a+aa+aaa+aaaa+aa-a的值,其中a是一个数字.例如2+22+222+2222+22222(此时共有5个数相加),几个数相加由键盘控制. 知识点:在Python 3里,reduce( ...