哈工大知识图谱(Knowledge Graph)课程概述
一.什么是知识图谱
知识(Knowledge)可以理解为 精炼的数据,知识图谱(Knowledge Graph)即是对知识的图形化表示,本质上是一种大规模语义网络 (semantic network) – 富含实体(entity)、 概念(concepts) 及其之间的各种语义关系 (semantic relationships),比如
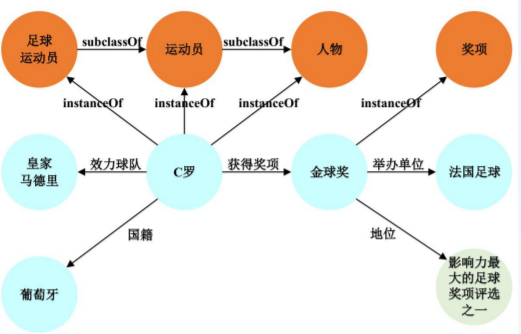
知识图谱和人工智能:

知识图谱的理想状态:
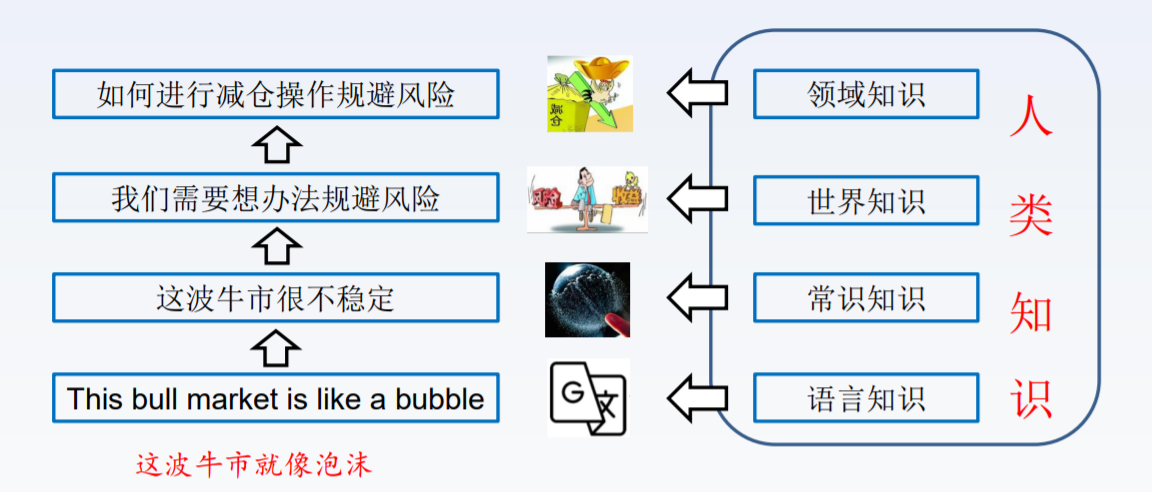
给所有IOT设备和机器人都挂一个背景知识库,因为对于人类来说,对一个事物的理解取决于这个人关于事物的相关背景知识,对自然语言的深度理解也需要复杂知识的支持,比如我们听到一句话“这波牛市就像是泡沫”,我们是如何理解它的呢。当前的NLP亟待从字面含义到言外之意的跃迁
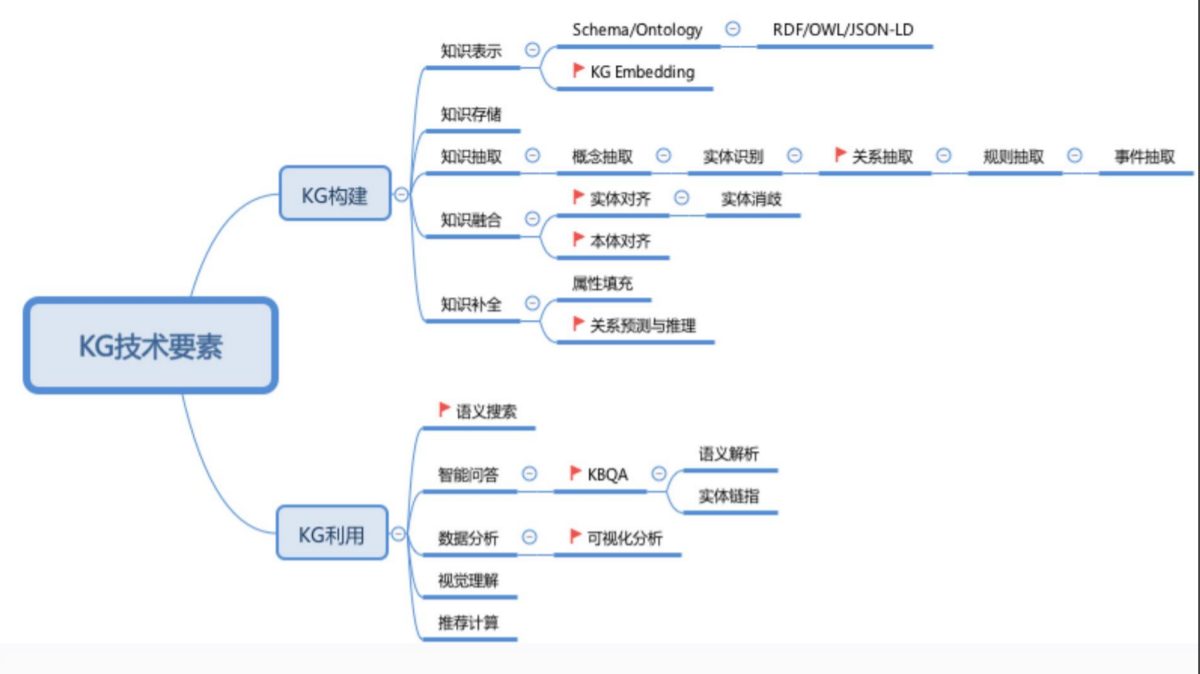
知识图谱的技术要素:
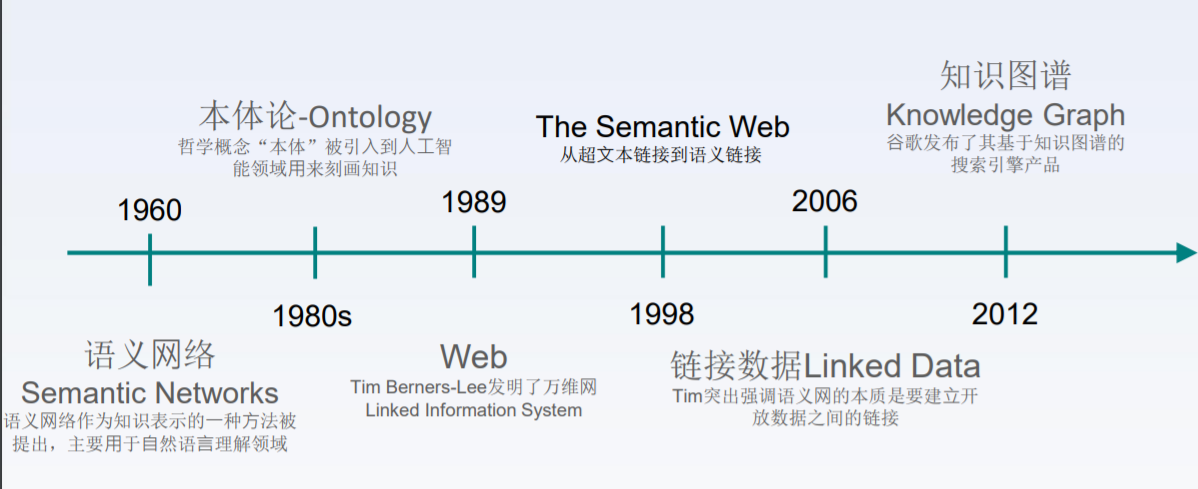
知识图谱的发展历史:WEB的理想 是万物的链接,搜索的理想 是事物的搜索
知识图谱的演变:(从人工到自动,从封闭域到开放域)
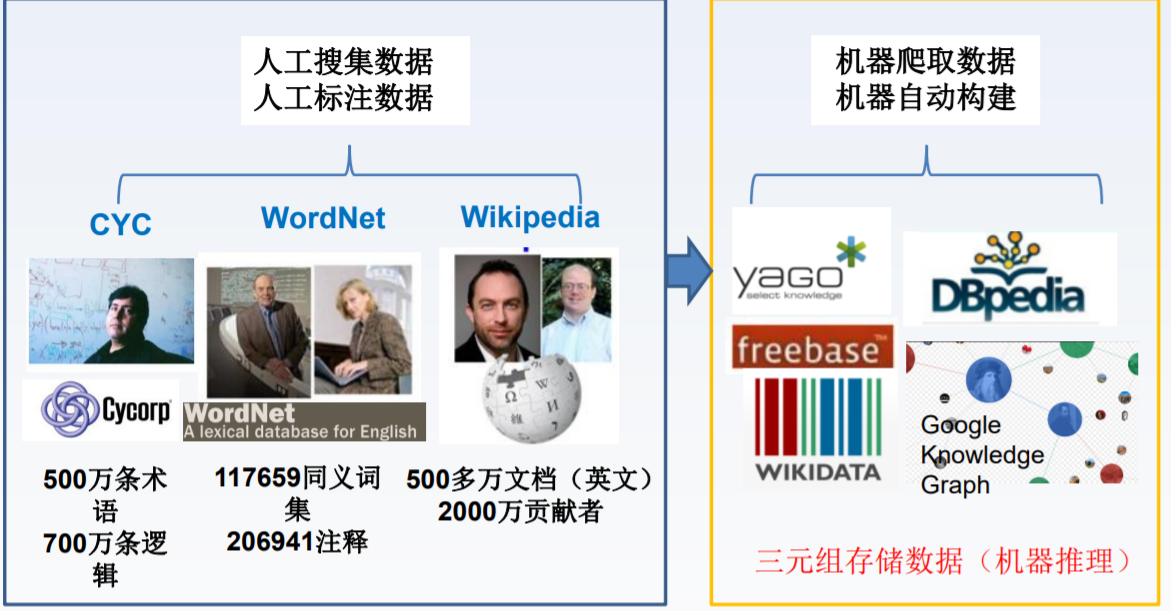
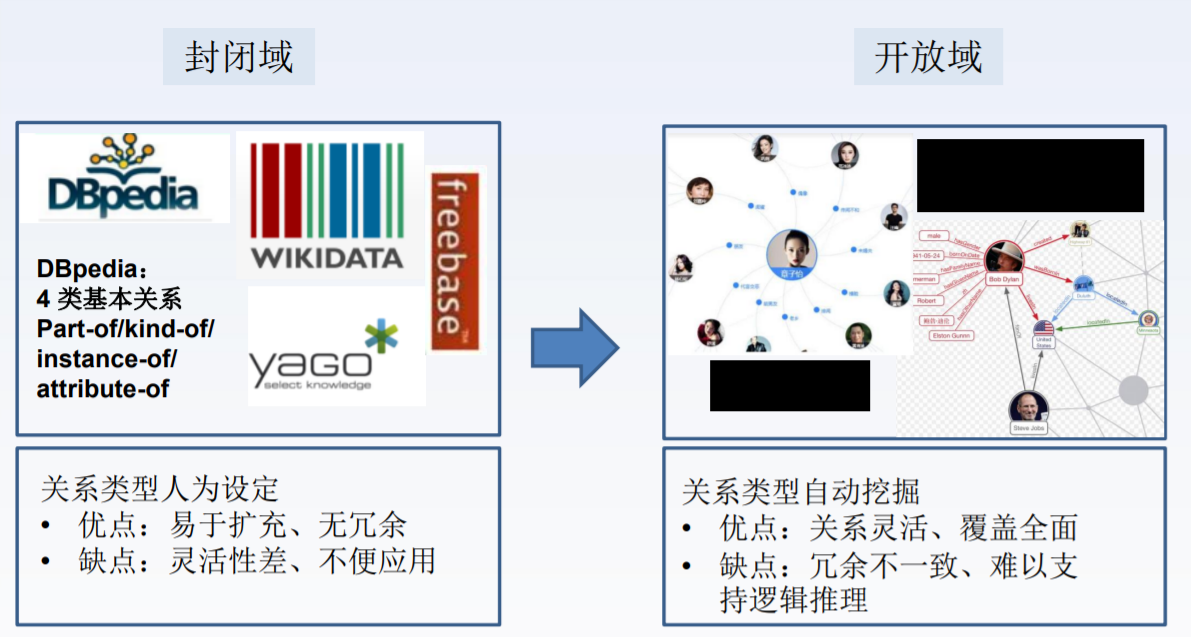 、
、
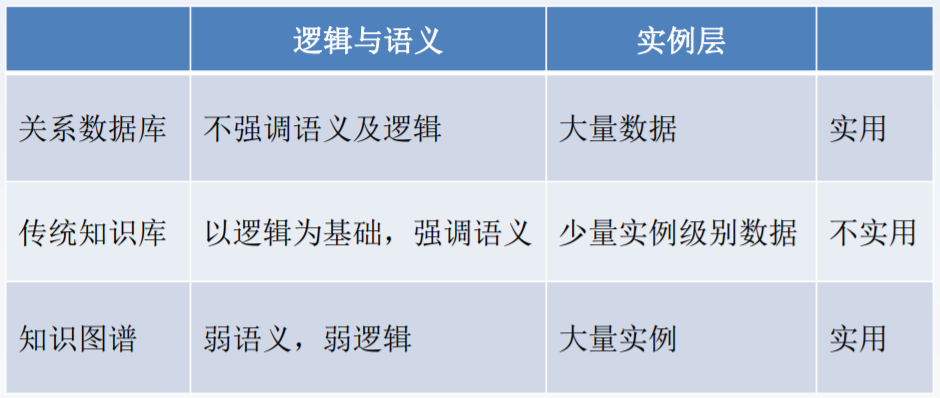
知识图谱vs关系数据库vs传统知识库
二.知识的表示方法(非知识图谱)
1.知识的分类
(1)陈述性知识 (declarative knowledge):用于描述领域内有关概念、事实、事物的属性和状态等。
➢ 太阳从东方升起
➢ 一年有春夏秋冬四个季节
(2)过程性知识 (procedural knowledge):用于指出如何处理与领域相关的信息,以求得问题的解。
➢ 菜谱中的炒菜步骤
➢ 如果信道畅通,请发绿色信号
(3)元知识 (meta knowledge):关于知识的知识,包括怎样使用规则、解释规则、校验规则、解释程序结构等知识。
2.一阶谓词逻辑表示法
(1)一阶谓词逻辑中的基本概念
命题 (proposition):具有真假意义的陈述句
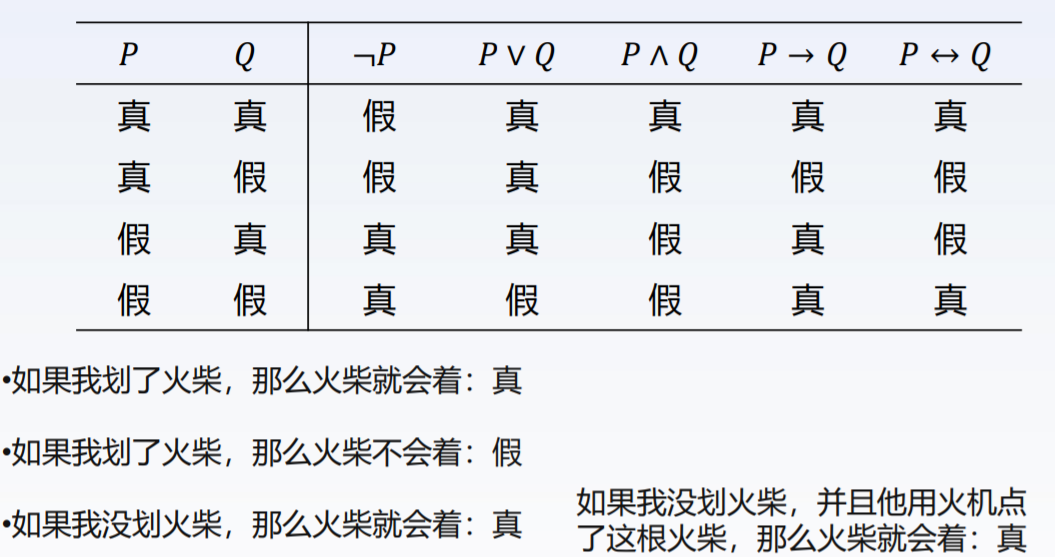
逻辑连接词 (logical connective):与 或 非等,用于将多个原子命题组合成复合命题
逻辑连接词的真值表
个体词:领域内可以独立存在的具体或抽象的客体
谓词(predicate):用来刻画个体性质以及个体之间相互关系的词。
n元谓词:含有n个个体符号的谓词P 1, 2, ⋯ , 。
➢ 一元谓词( = 1):表示1具有性质P。
➢ 多元谓词( ≥ 2):表示1, 2, ⋯ , 具有关系P。
函数:又称函词,是从若干个个体到某个个体的映射。(谓词实现的是从个体域中的个体到真或假的映射,而函数实现的是从个体域中的一个(或若干)个体到另 一个个体的映射,无真值可言)
➢ Father 小张 :小张的父亲
➢ Sum 1,2 :1与2的加和
量词(quantifier):是表示个体数量属性的词。
➢ 全称量词:符号化为∀(All)
➢ 存在量词:符号化为∃(Exist)
(2)用谓词逻辑表示知识的一般步骤:
➢ 定义谓词及个体,确定每个谓词及个体的确切含义。
➢ 根据所要表达的事物或概念,为每个谓词中的变量赋以特定的值。
➢ 根据所要表达的知识的语义,用适当的逻辑联结词将各个谓词连接起来形成谓词公式。
实例:用谓词逻辑表示下列知识:
➢ 哈尔滨是一个美丽的城市,但她不是一个沿海城市。
➢ 哈尔滨是黑龙江省的省会。
➢ 每一个省的省会都必定位于这个省。
步骤一:
定义谓词和个体域如下:
➢ BCity():是一个美丽的城市
➢ CCity():是一个沿海城市
➢ PCapitalOf(, ): 是的省会
➢ LocatedIn(, ): 位于
➢ ∈ 城市 , ∈ 省
步骤二:
将个体带入谓词中,得到:
➢ BCity(Harbin)
➢ CCity(Harbin)
➢ PCapitalOf(Harbin,Heilongjiang)
➢ PCapitalOf(, )
➢ LocatedIn(, y)
步骤三:
根据语义,用逻辑联结词连接:
➢ BCity(Harbin)∧ ¬CCity(Harbin)
➢ PCapitalOf(Harbin,Heilongjiang)
➢ ∀x, y PCapitalOf(, )→ LocatedIn(, y)
(3)一阶谓词逻辑的优缺点:
优点: ➢ 精确性:可以较准确地表示知识并支持精确推理。
➢ 通用性:拥有通用的逻辑演算方法和推理规则。
➢ 自然性:是一种接近于人类自然语言的形式语言系统。
➢ 模块化:各条知识相对独立,它们之间不直接发生联 系,便于知识的添加、删除和修改。
缺点: ➢ 表示能力差:只能表示确定性知识,不能表示非确定 性知识、过程性知识和启发式知识。
➢ 管理困难:缺乏知识的组织原则,知识库管理困难。
➢ 效率低:把推理演算与知识含义截然分开,往往使推
3.产生式规则表示法:
目前产生式规则表示法已成为专家系统首选的知识表示方式,也是人工智能中应用最多的一种知识表示方式。
(1)产生式规则中的基本概念
事实:断言一个语言变量的值或断言多个语言变量之间关系的陈述句。
➢ 雪是白的
语言变量:雪
语言变量的值:白的
➢ 小王与小张同岁
语言变量:小王、小张
语言变量之间的关系:同岁
确定性事实:一般用三元组的形式表示为(对象,属性,值)或(关系,对象1,对象2)
不确定性事实:一般用四元组的形式表示为(对象,属性,值,置信度)或(关系,对象1,对象2,置信度)
规则:也称为产生式,通常用于表示事物之间的因果关系。
确定性规则:通常表示为 → 或 IF THEN
不确定性规则:通常表示为 → (置信度)或 IF THEN (置信度)
(2)产生式系统结构
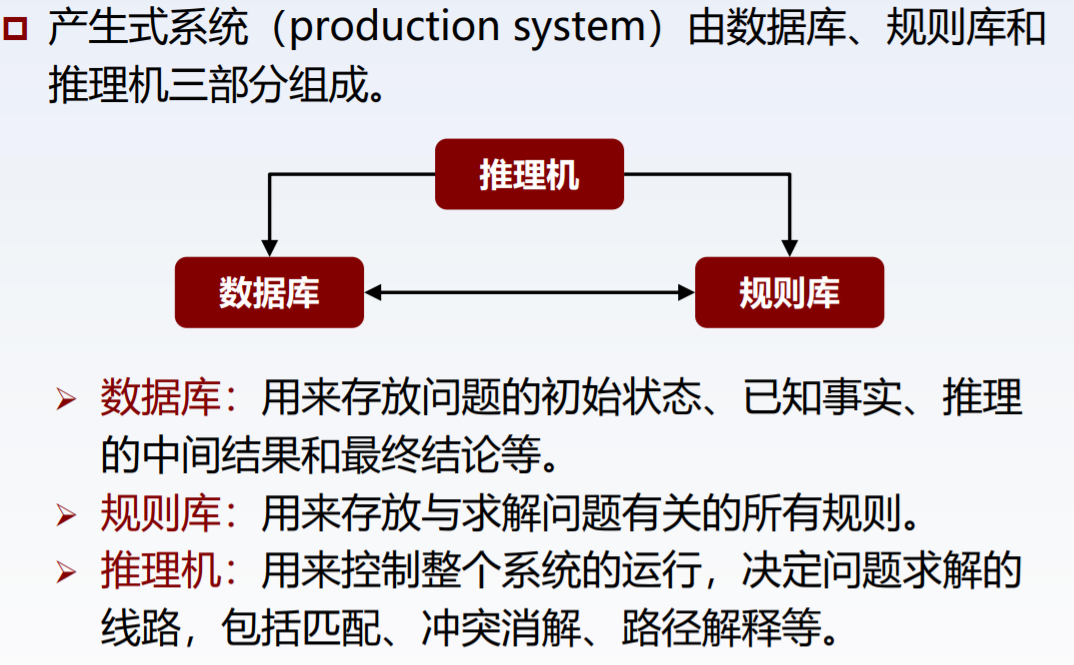
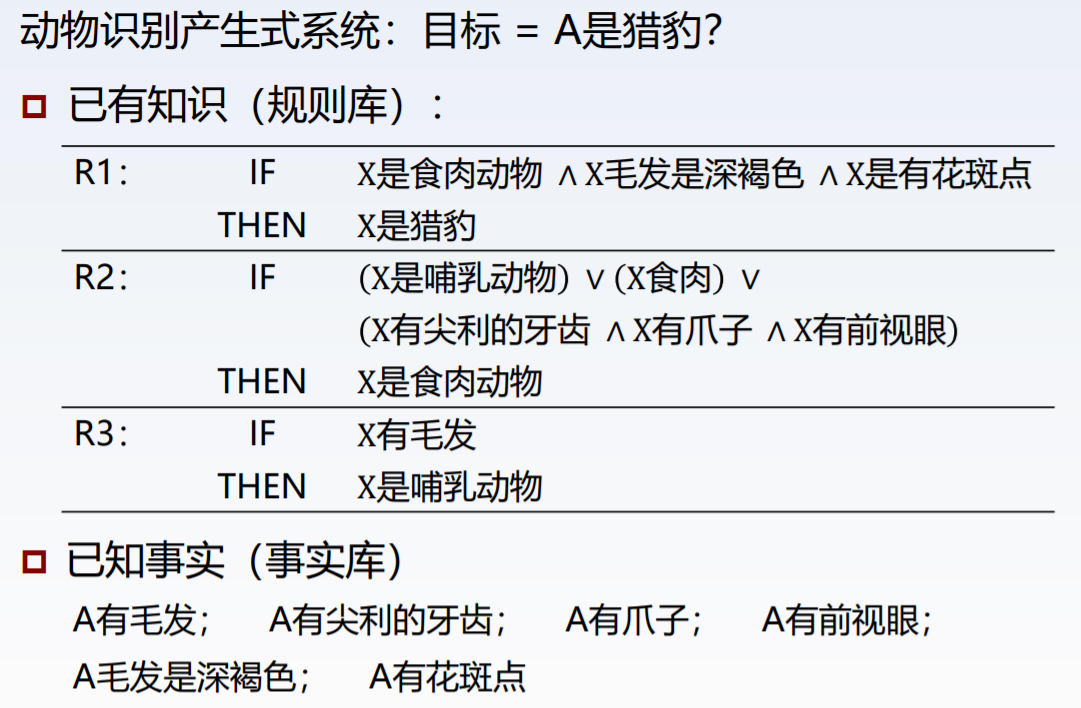
(3)产生式系统优缺点
优点:➢ 有效性:既可以表示确定性知识,又可以表示不确定性知识,有利于启发性和过程性知识的表达。
➢ 自然性:用“如果…,则…”表示知识,直观、自然。
➢ 一致性:所有规则具有相同的格式,并且数据库可被所有规则访问,便于统一处理。
➢ 模块化:各条规则之间只能通过数据库发生联系,不 能相互调用,便于知识的添加、删除和修改。
缺点: ➢ 效率低:求解是反复进行的“匹配—冲突消解—执行” 过程,执行效率低。
(4)框架表示法
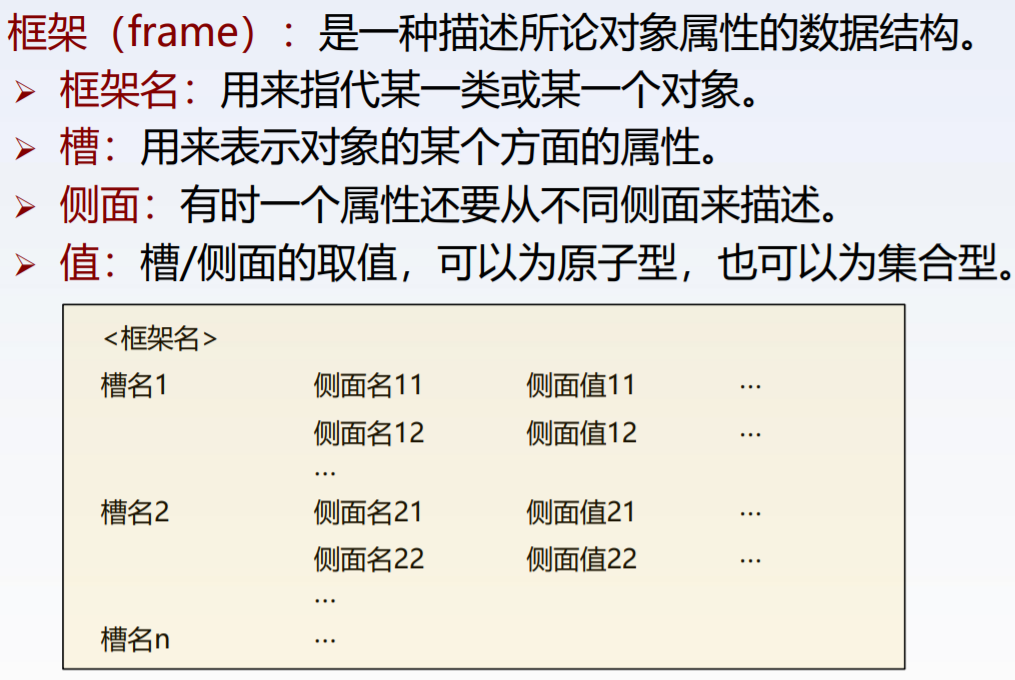
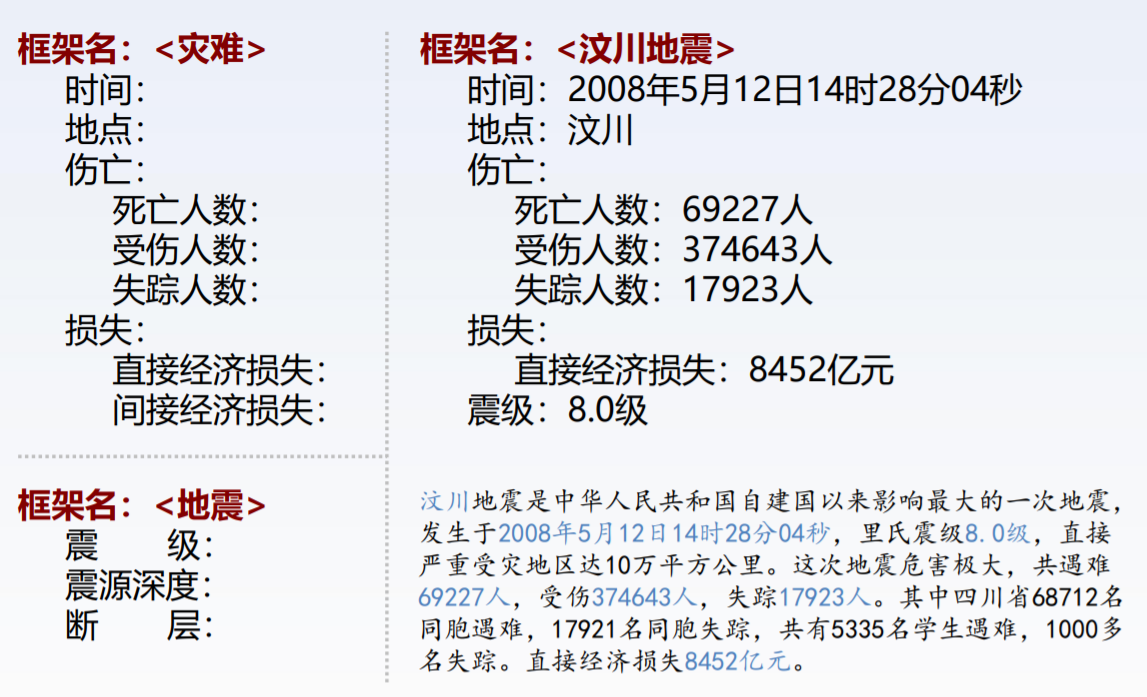
优点: ➢ 结构化:分层次嵌套式结构,既可以表示知识的内部 结构,又可以表示知识之间的联系。
➢ 继承性:下层框架可以从上层框架继承某些属性或值, 也可以进行补充修改,减少冗余信息并节省存储空间。
➢ 自然性:框架理论符合人类认知的思维过程。 ➢ 模块化:每个框架是相对独立的数据结构,便于知识 的添加、删除和修改。
缺点: ➢ 不能表示过程性知识
➢ 缺乏明确的推理机制
4.脚本表示法
脚本是一种与框架类似的知识表示方法,由一组槽组成, 用来表示特定领域内一些事件的发生序列,类似于电影 剧本。脚本表示的知识有明确的时间或因果顺序,必须 是前一个动作完成后才会触发下一个动作。与框架相比, 脚本用来描述一个过程而非静态知识。
(1)脚本组成
进入条件:给出脚本中所描述事件的前提条件。
角色:用来描述事件中可能出现的人物。
道具:用来描述事件中可能出现的相关物体。
场景:用来描述事件发生的真实顺序。一个事件可以由多 个场景组成,而每个场景又可以是其他事件的脚本。
结果:给出在脚本所描述事件发生以后所产生的结果。
(2)脚本实

(3)脚本表示的优缺点
缺点:➢ 相较于框架表示,脚本表示表达能力更受约束,表示范围更窄,不具备对于对象基本属性的描述能力,也难以描述复杂事件发展的可能方向。
优点:➢ 在非常狭小的领域内,脚本表示却可以更细致地刻画步骤和时序关系,适合于表达预先构思好的特定知识 或顺序性动作及事件,如故事情节理解、智能对话系统、机票酒店预订等。
5.语义网表示法
语义网的概念来源于万维网(world wide web),是万维网的变革与延伸,是Web of documents向Web of data的转变,其目标是让机器或设备能够自动识别 和理解万维网上的内容,使得高效的信息共享和机器智能协同成为可能。语义网(semantic web)≠ 语义网络(semantic network)。
语义网体系结构:


Ontology(本体):通过对概念的严格定义和概念与概念之间的关系来确定概念的精确含义,表示共同认可的、可共享的知识,对于ontology来说,author,creator和writer是同一个 概念,而doctor在大学和医院分别表示的是两个概念。因 此在语义网中,ontology具有非常重要的地位,是解决语义层次上Web信息共享和交换的基础。简单理解就是某个领域关于自身和相关关系的描述
三.知识图谱中的知识表示方法
1.知识图谱中的概念
实体 (entity):现实世界中可区分、可识别的事物或概念。 ➢ 客观对象:人物、地点、机构 ➢ 抽象事件:电影、奖项、赛事
关系 (relation):实体和实体之间的语义关联。
事实 (fact):陈述两个实体之间关系的断言,通常表示为 (head entity, relation, tail entity) 三元组形式。
2.知识图谱的特性
知识图谱不太专注于对知识框架的定义,而专注于如何以工程的方式,从文本中自动抽取或依靠众包的方式获取并 组建广泛的、具有平铺结构的知识实例,最后再要求使用 它的方式具有容错、模糊匹配等机制。 知识图谱的真正魅力在于其图结构,可以在知识图谱上运行搜索、随机游走、网络流等大规模图算法,使知识图谱与图论、概率图等碰撞出火花。
四.实体识别
1.信息抽取
概念:从自然语言文本中抽取指定类型的实体、关系、事件等事实信息, 并形成结构化数据输出的文本处理技术
主要任务:实体识别与抽取,关系抽取,时间抽取,实体消歧
2.命名实体识别(Named Entity Recognition,简称NER)
定义:狭义地讲,命名实体指现实世界中具体或抽象的实体 , 如人(张三)、机构(哈尔滨工业大学)、地点等,通常用唯一的标志符(专有名称)表示。
广义地讲,命名实体还可以包含时间(12:00)、日 期(2017年10月17日)、数量表达式(100)、金钱 (一亿美金)等
任务:一般而言,主要是识别出待处理文本中七类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。两个子任务:实体边界识别和确定实体类别。
特点:时间、日期、货币和百分比的构成有比较明显的规律, 识别起来相对容易。人名、地名、机构名的用字灵活,识别的难度很大。
人名识别在英文中已得到很好的研究,因为英文本身具有一些明显特征(如大小写),但在中文中仍是一个难点,除此之外,中文地名,音译名的识别也难度巨大
方法:(1)基于规则和词典的方法:基于规则的方法多采用语言学专家手工构造规则模板,选用特征包括统计信息、标点符号、关键字、指示词和方向词、位置词(如尾字)、中心词等方法,以模式和字符串相匹配为主要手段,这类系统大多依赖于知识库和词典的建立。
(2)基于统计机器学习的方法主要包括:隐马尔可夫模型(HiddenMarkovMode,HMM)、最大熵(MaxmiumEntropy,ME)、支持向量机(Support VectorMachine,SVM)、条件随机场(ConditionalRandom Fields,CRF)等
(3)混合方法:
a.统计学习方法之间或内部层叠融合。
b. 规则、词典和机器学习方法之间的融合,其核心是融合方法技术。在基于统计的学习方法中引入部分规则,将机器学习和人工知识结合起来。
c. 将各类模型、算法结合起来,将前一级模型的结果作为下一级的训练数据,并用这些训练数据对模型进行训练,得到下一级模型。
实现方案:BERT+BiLSTM+CRF用于命名实体识别是目前最常见的方案,除此之外还有LSTM+CRF
3.开放域实体识别
不限定实体类别,不限定目标文本,任务:给定某一类别的实体实例,从网页中抽取同一类别其他实体实例,比如给出<中国,美国,俄罗斯>(称为“种子”),找出其他国家<德国,英国,法国……>
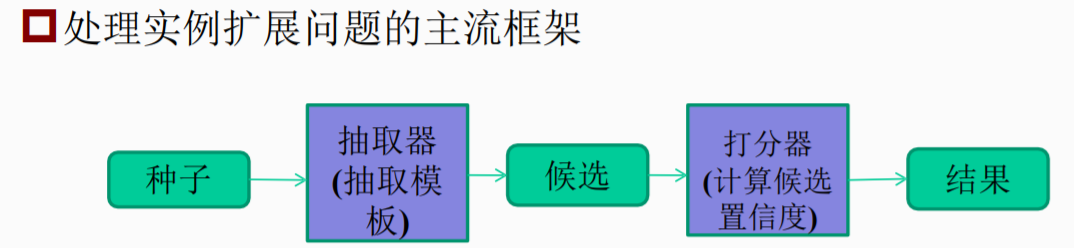
五.实体消歧
命名实体的歧义指的是一个实体指称项(Entity Mention)可对应到多个真实世界实体,确定一个实体指称项所指向的真实世界实体,这就是命名实体消歧
1.基于无监督(聚类)的实体消歧
(1)词袋模型
利用待消歧实体周边的词来构造向量,利用向量空间模型来计算两个实体指称项的相似度,进行聚类
(2)语义特征
词袋模型,没有考虑词的语义信息
可以利用SVD分解挖掘词的语义信息
利用词袋和浅层语义特征(bigram),共同表示指称项 ,利用余弦相似度来计算两个指称项的相似度
(3)社会化网络

(4)维基百科
Wikipedia中相关实体具有链接关系,这种链接关系反映条目之间的语义相关度,用实体上下文的维基条目对于实体进行向量表示,利用维基条目之间的相关度计算指称项之间的相似度(解决数据稀疏问题)
(5)多源异构知识
仅仅考虑Wikipedia一种知识源,覆盖度有限,使用多源异构知识的挖掘与集成
2.基于知识库链接的实体消歧
给定实体指称项和它所在的文本,将其链接到给定知识库中的相应实体上
(1)候选实体的发现
给定实体指称项,链接系统根据知识、规则等信息找到实体指称项的候选实体
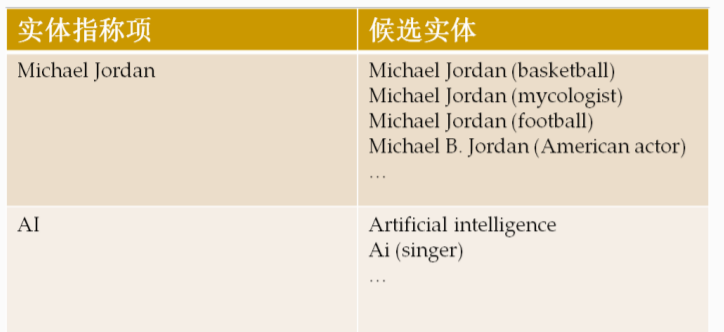
利用Wikipedia信息获取候选实体
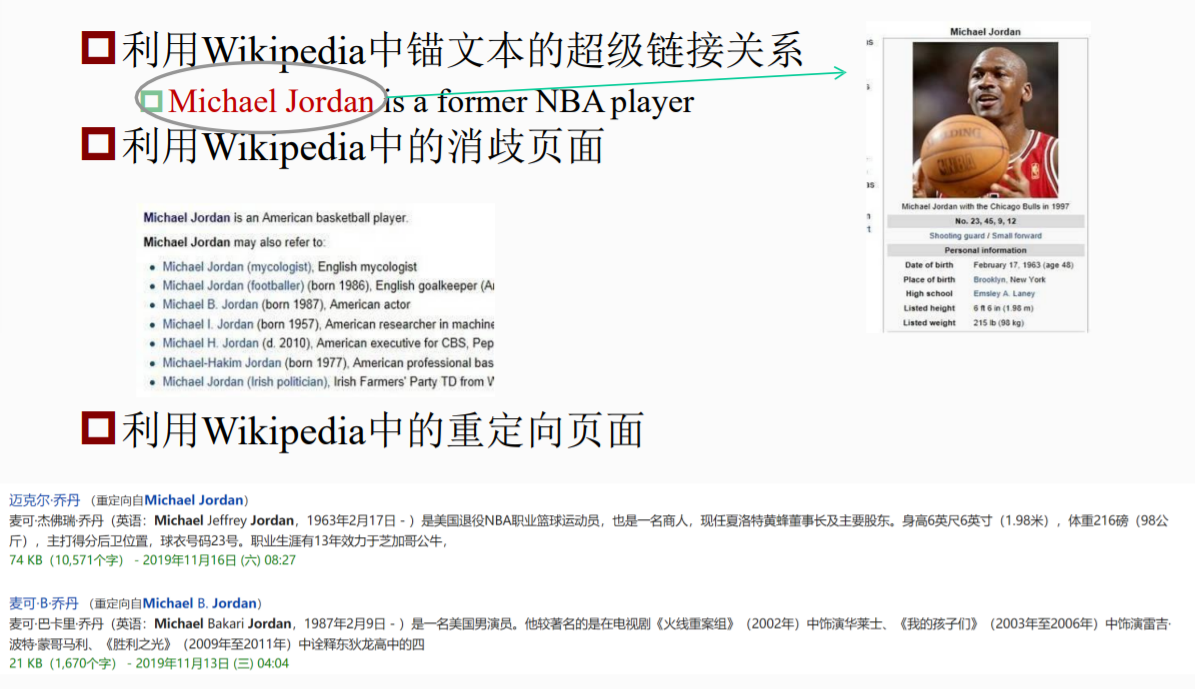
还可以利用上下文获取缩略语候选实体
(2)候选实体的链接

六.关系抽取
1.传统关系抽取
任务:给定实体关系类别,给定语料,抽取目标关系对
评测语料(MUC, ACE, KBP, SemEval):专家标注语料,语料质量高,抽取的目标类别已经定义好,有公认的评价方式
方法:


2.开放域关系抽取
特点:不限定关系类别
不限定目标文本 (Web Page, Wikipedia, Query Log)
难点问题 :如何获取训练语料,如何获取实体关系类别, 如何针对不同类型目标文本抽取关系
需要研究新的抽取方法:按需抽取—Bootstrapping,模板
开放抽取—Open IE
知识监督抽取—Distant Supervisio
七.事件抽取
1.任务描述

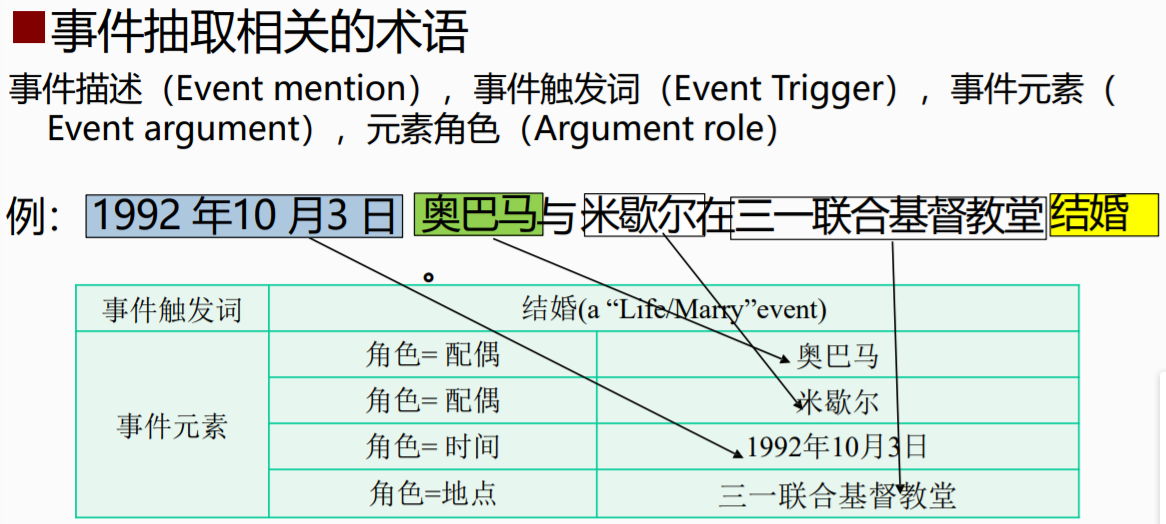
事件发现:从文本中发现事件触发词
事件元素抽取:从本文中识别事件元素并判断元素扮演的角色。
2.典型方法
(1)基于模式匹配的方法
平面模式主要基于词袋等字符串特征构成模式
结构模式更多地考虑了句子的结构信息,融入句法分析特征
(2)基于Bootstrapping的事件元素识别方法

(3)基于Bootstrapping方法的模式学习
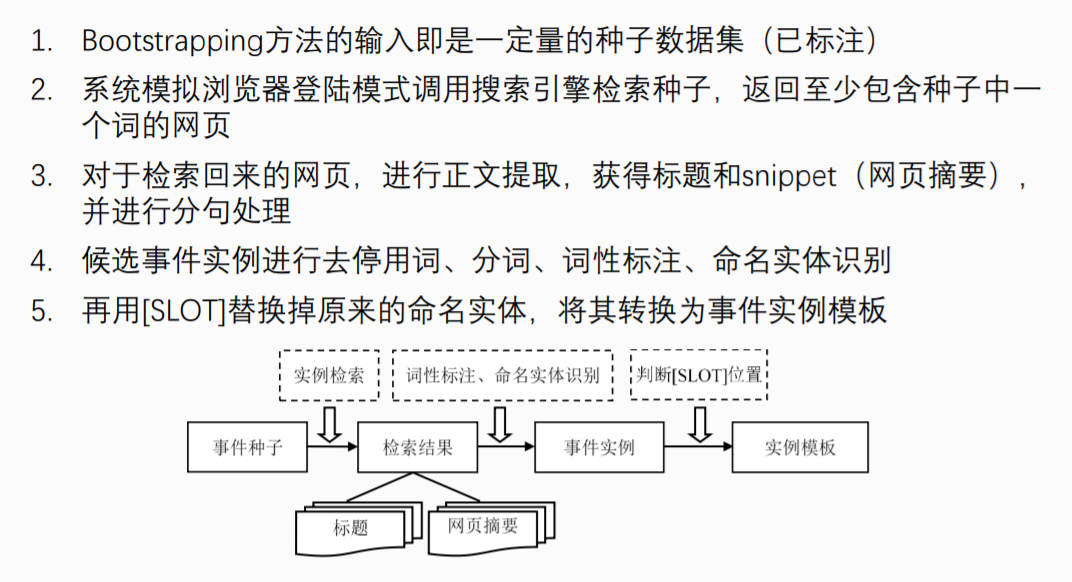

(4)基于机器学习的方法
目前主要采用统计机器学习的方法,将事件实例转换成高维 空间中的特征向量或直接用离散结构来表示,在标注语料库上训练生成模型,然后再识别事件及其元素
基于特征向量方法:利用最大熵、朴素贝叶斯和支持向量机等( Ralph Grishman 2005, Ahn 2006, Ji 2008, Ji 2009, Liao 2010 Hong 2011)
基于结构的方法:依存树结构、自定义联合结构等( McClosky et al. 2011 ,Li et al.2013,Li et al. 2014 )
基于神经网络的方法:多层感知机、卷积神经网络、循环神经网络等 (Chen et al. 2015,Feng et al. 2016, Liu et al. 2017,Chen et al. 2017,Liu et al. 2017 )
3.事件表示学习
(1)传统限定域事件抽取及表示

(2)开放域事件抽取基于人工语义词典的解决方案
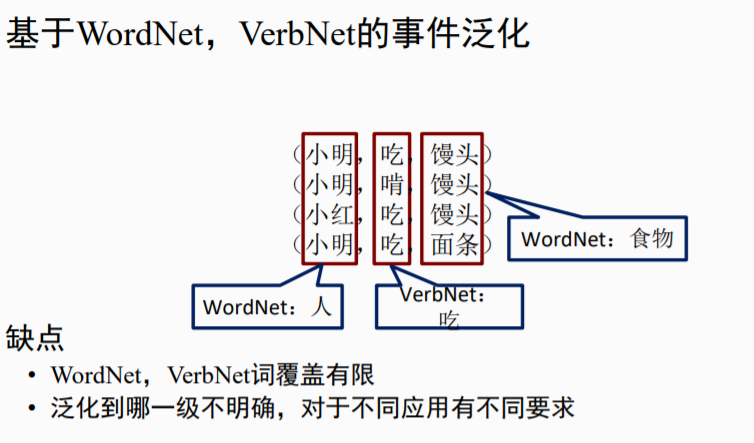
(3)基于事件分布式表示学习的解决方案
embedding方法,低维度,稠密,实数值向量表示
(4)知识驱动的事件表示学习
• 缺乏知识造成的歧义
• 具有相同或相似的词但是语义不同的事件,学到相似的事件向量
• 不具有相同或相似的词但是语义相同的事件,学到不相邻的事件向量
• 举例 乔布斯离开苹果 vs 约翰离开星巴克
(5)常识知识(情感、意图)增强的事件表示学习
事件是对客观事实的表达,然而客观事件的发生会对人类的主观 情感产生影响,不同的事件其背后的意图也有所不同(Xiao Ding, Kuo Liao, Ting Liu, Junwen Duan, Zhongyang Li. Event Representation Learning Enhanced with External Commonsense Knowledge. EMNLP, 2019.)
八.事理图谱
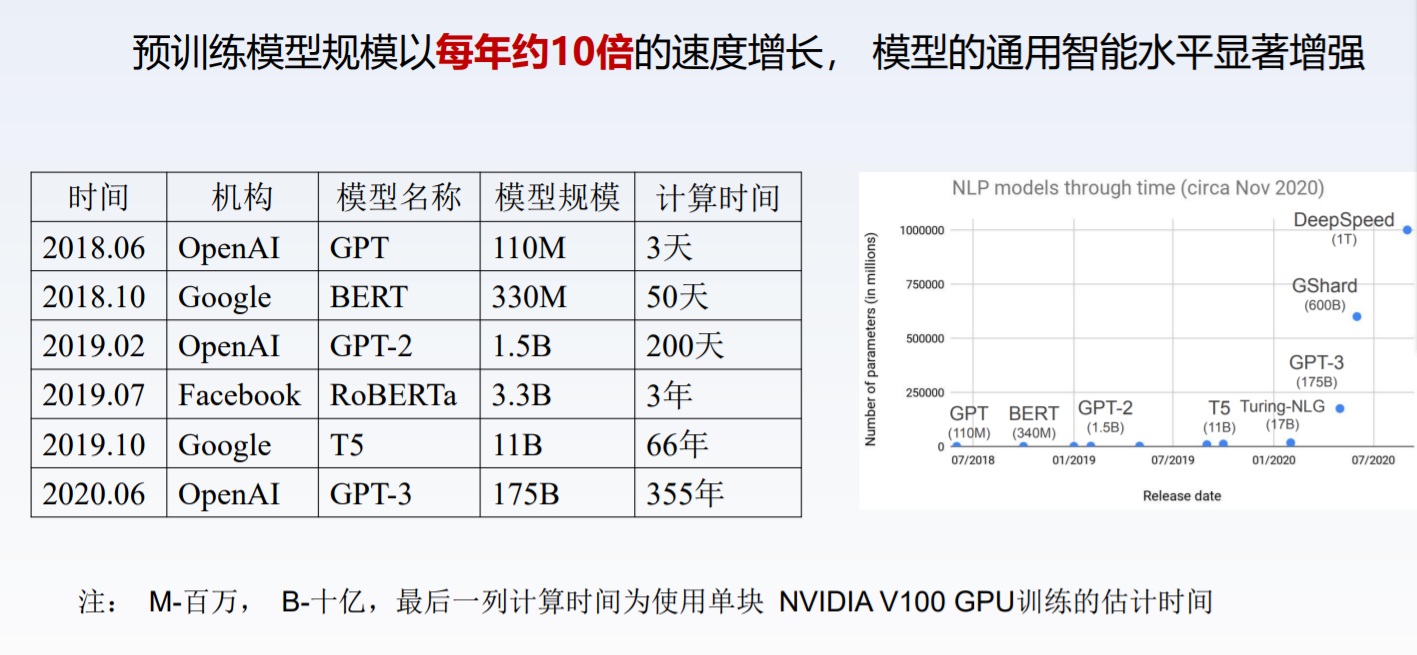
1.大规模预训练模型的发展

2.什么是事理图谱
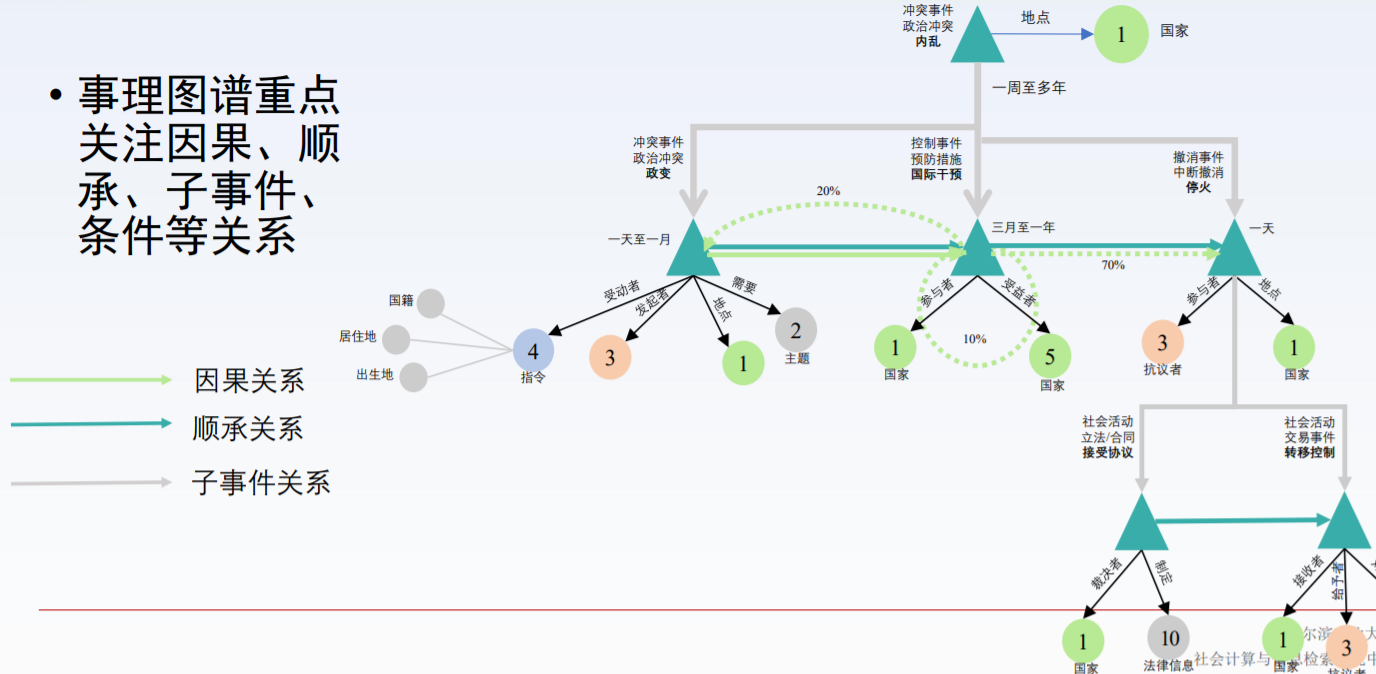
定义:事理图谱(Eventic Graph(EG))是一个事理逻辑知识库,描述了事件之间的演化规律和模式。结构上事理图谱是一个有向有环图,节点代表事件,有向边代表事件之间的顺承、因果、条件和上下位等逻辑关系。
形式化定义:EG是一个有向图,E=(V, R),V是顶点集合, ∈ V表 示的是一个事件或者事理(泛化后的事件),R是边的集合, ∈ 表示事件之间的因果、顺承、条件等逻辑关系
事理图谱可应用于事件预测、 常识推理、消费意图挖掘、 对话生成、问答系统、辅助决策等任务中

3.事理图谱的构建

九.结语
这篇文章仅是知识图谱的简要概述,学习之路还很漫长,与君共勉
哈工大知识图谱(Knowledge Graph)课程概述的更多相关文章
- 学习笔记之知识图谱 (Knowledge Graph)
Knowledge Graph - Wikipedia https://en.wikipedia.org/wiki/Knowledge_Graph The Knowledge Graph is a k ...
- 百度大脑UNIT3.0详解之知识图谱与对话
如今,越来越多的企业想要在电商客服.法律顾问等领域做一套包含行业知识的智能对话系统,而行业或领域知识的积累.构建.抽取等工作对于企业来说是个不小的难题,百度大脑UNIT3.0推出「我的知识」版块专门为 ...
- 1. 通俗易懂解释知识图谱(Knowledge Graph)
1. 通俗易懂解释知识图谱(Knowledge Graph) 2. 知识图谱-命名实体识别(NER)详解 3. 哈工大LTP解析 1. 前言 从一开始的Google搜索,到现在的聊天机器人.大数据风控 ...
- Multi-Task Feature Learning for Knowledge Graph Enhanced Recommendation(知识图谱)
知识图谱(Knowledge Graph,KG)可以理解成一个知识库,用来存储实体与实体之间的关系.知识图谱可以为机器学习算法提供更多的信息,帮助模型更好地完成任务. 在推荐算法中融入电影的知识图谱, ...
- 知识图谱顶刊综述 - (2021年4月) A Survey on Knowledge Graphs: Representation, Acquisition, and Applications
知识图谱综述(2021.4) 论文地址:A Survey on Knowledge Graphs: Representation, Acquisition, and Applications 目录 知 ...
- Semantic Parsing(语义分析) Knowledge base(知识图谱) 对用户的问题进行语义理解 信息检索方法
简单说一下所谓Knowledge base(知识图谱)有两条路走,一条是对用户的问题进行语义理解,一般用Semantic Parsing(语义分析),语义分析有很多种,比如有用CCG.DCS,也有用机 ...
- 使用图数据库 Nebula Graph 数据导入快速体验知识图谱 OwnThink
前言 本文由 Nebula Graph 实习生@王杰贡献. 最近 @Yener 开源了史上最大规模的中文知识图谱--OwnThink(链接:https://github.com/ownthink/Kn ...
- 使用图数据库 Nebula Graph 数据导入快速体验知识图谱
本文由 Nebula Graph 实习生@王杰贡献. 最近 @Yener 开源了史上最大规模的中文知识图谱——OwnThink(链接:https://github.com/ownthink/Knowl ...
- 2. 知识图谱-命名实体识别(NER)详解
1. 通俗易懂解释知识图谱(Knowledge Graph) 2. 知识图谱-命名实体识别(NER)详解 3. 哈工大LTP解析 1. 前言 在解了知识图谱的全貌之后,我们现在慢慢的开始深入的学习知识 ...
随机推荐
- Linux中MySQL的安装以及卸载
一.MySQL MySQL是一种开放源代码的关系型数据库管理系统,开发者为瑞典MySQL AB公司.在2008年1月16号被Sun公司收购.而2009年,SUN又被Oracle收购.目前 MySQL被 ...
- tomcat漏洞总结
描述 Tomcat是Apache 软件基金会(Apache Software Foundation)的Jakarta 项目中的一个核心项目,由Apache.Sun 和其他一些公司及个人共同开发而成.由 ...
- 使用 baget 搭建私有 nuget 私有服务
现在几乎所有语言都提供包管理工具,比如 JavaScript 的 npm ,Java 的 Maven ,Dart 的 pub ..Net 程序当然是 NuGet .NuGet 也出现很多年了,奇怪的是 ...
- Dockerfile简介及基于centos7的jdk镜像制作
Dockerfile简介 dockerfile 是一个文本格式的配置文件, 用户可以使用 Dockerfile 来快速创建自定义的镜像, 另外,使用Dockerfile去构建镜像好比使用pom去构建m ...
- [考试总结]noip模拟44
这个真的是一个 \(nb\) 题. 考试快要结束的时候,在机房中只能听到此起彼伏的撕吼. 啊---------- 然后人们预测这自己的得分. \(\color{red}{\huge{0}}\) \(\ ...
- 《Go语言圣经》阅读笔记:第三章基础数据类型
第三章 基础数据类型 Go语言将数据类型分为四类: 基础类型 数字 整数 浮点数 复数 字符串 布尔 复合类型 数据 结构体 引用类型 指针 切片 字典 函数 通道 接口类型 在此章节中先介绍基础类型 ...
- log4J日志输出修改
1. log4j.rootLogger=DEBUG,INFO, console, log, error ###Console ### log4j.appender.console = org.apac ...
- MySQL查询之内连接,外连接查询场景的区别与不同
前言 我在写sql查询的时候,用的最多的就是where条件查询,这种查询也叫内连查询inner join,当然还有外连查询outer join,左外连接,右外连接查询,常用在多对多关系中,那他们区别和 ...
- 解决git bash闪退问题 报openssl错误
问题描述:今天安装git之后发现Git Bash工具闪退. 于是试了各种办法之后,最后终于解决. 背景描述:git 下载地址:https://git-scm.com/download/win 下载成功 ...
- cmd中输出换行和转义字符
cmd 中输出换行和转义字符 今天想写一个安装 Windows 任务的 bat 脚本,在命令行界面输出换行和转义一些字符,居然搜索了好久才搜到正确操作,因此记录一下. 在命令行界面输出换行 echo. ...