transformers---BERT
transformers---BERT
BERT模型主要包括两个部分,encoder和decoder,encoder可以理解为一个加强版的word2vec模型,以下是对于encoder部分的内容
预训练任务
- MLM任务
MLM任务通过单词表示来表示上下文关系 - NSP任务
NSP任务通过句子向量表示句间的关系
1. BERT模型的输入
- wordpiece embedding 单词向量
- position embedding 位置编码向量
两种生成方式:- 相对位置编码
\[PE_{(pos,2i)}=sin(\frac{pos}{10000^{\frac{2i}{model}}})
\]\[PE_{(pos,2i+1)}=cos(\frac{pos}{10000^{\frac{2i}{model}}})
\] - 通过模型学习生成
- 相对位置编码
- segment embedding 区分文中的上下句,应用在问答匹配中
2. self-attention
句子向量
\(\downarrow \ \ \ \ \downarrow\)Input Embedding + Position Embedding
\(\downarrow\)- \[X_{embedding}\in R^{batch size\ *\ seq len\ *\ embed dim}
\]\(\downarrow\) 线性映射(学到多重含义,分配三个权重(\(W_Q,W_k,W_v\))
\(Q=Linear(X_{embedding})=X_{embedding}W_Q\)
\(K=Linear(K_{embedding})=K_{embedding}W_K\)
\(V=Linear(V_{embedding})=V_{embedding}W_V\)
\(\downarrow\) multi head atention(\(head size=embed dim/head size\))\(Q,K,V \rightarrow[batch size,seq len,head size,embed dim/h\)
\((Q,K,V)^T \rightarrow[batch size,head size,
seq len,embed dim/h]\)head_size:即多头注意力机制中的head, \(head size=embed dim/head num\)
embed_size:句子中每个字的编码向量的长度
seq_len:句子的长度
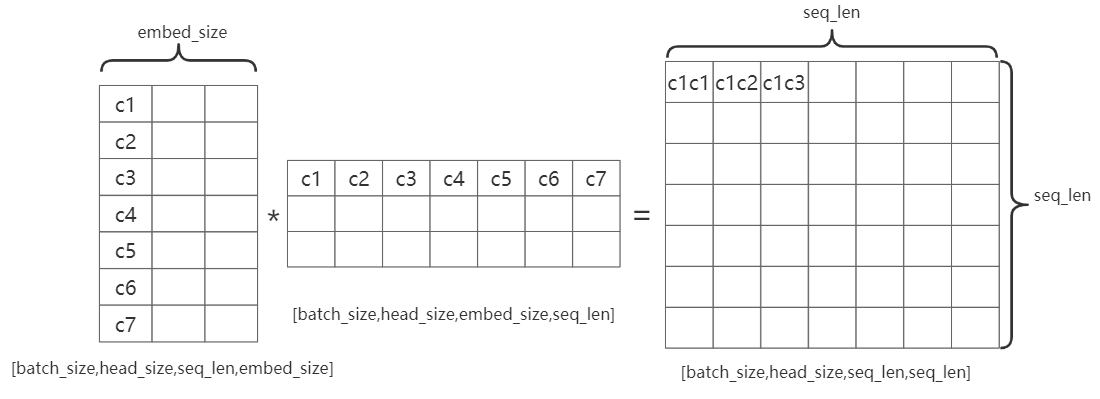
如图:C1C2表示第一个字和第二个字的注意力机制结果
\(Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V\)
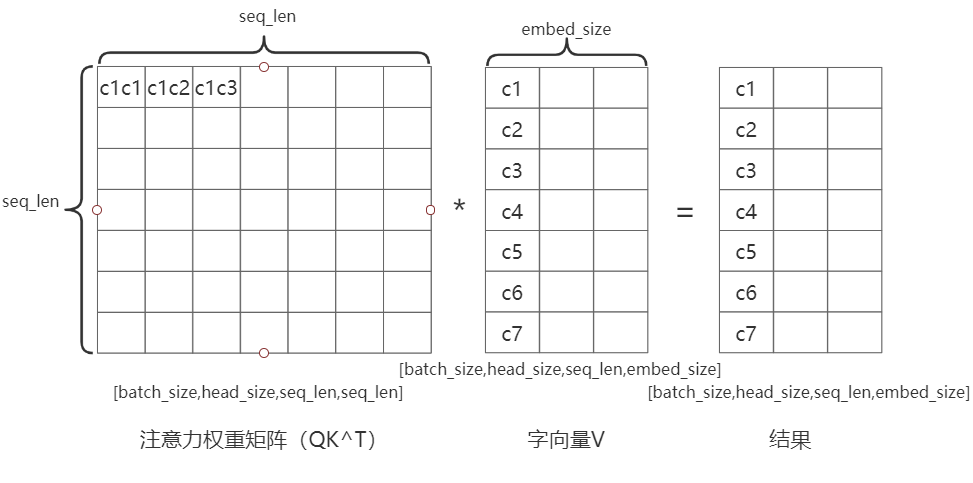
\(\frac{QK^T}{\sqrt{d_k}}\)的第一列和\(V\)的第一行决定了结果中的第一个值,这样保证了结果向量中每个元素包含了该句中所有字的特征note:
Attention mask
在encoder的过程中,输入句子的\(seq len\)是不等长的,此时需要对句子进行补全,如果使用0补全,使用softmax函数\(softmax=\sigma(z)=\frac{e^{z_i}}{\sum^{k}_{j=1}e^{z_j}}\),e=0时,将导致补0的部分参与到运算中
解决办法:给补0的部分添加偏置\(Z_{illeagl}=Z_{illeagl}+bias ,\ bias\rightarrow -\infty\)
此时,\(e^{-\infty}=0 ,\ e^{Z_{illegal}}=0\),便面了无效区参与运算。
3. Layer Normalization 残差连接
- \(X=X_{embedding}+Attention(Q,K,V)\)
transformers---BERT的更多相关文章
- BERT论文解读
本文尽量贴合BERT的原论文,但考虑到要易于理解,所以并非逐句翻译,而是根据笔者的个人理解进行翻译,其中有一些论文没有解释清楚或者笔者未能深入理解的地方,都有放出原文,如有不当之处,请各位多多包含,并 ...
- (转) Using the latest advancements in AI to predict stock market movements
Using the latest advancements in AI to predict stock market movements 2019-01-13 21:31:18 This blog ...
- BERT(Bidirectional Encoder Representations from Transformers)
BERT的新语言表示模型,它代表Transformer的双向编码器表示.与最近的其他语言表示模型不同,BERT旨在通过联合调节所有层中的上下文来预先训练深度双向表示.因此,预训练的BERT表示可以通过 ...
- BERT(Bidirectional Encoder Representations from Transformers)理解
BERT的新语言表示模型,它代表Transformer的双向编码器表示.与最近的其他语言表示模型不同,BERT旨在通过联合调节所有层中的上下文来预先训练深度双向表示.因此,预训练的BERT表示可以通过 ...
- 文本分类实战(十)—— BERT 预训练模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
- 【译】BERT表示的可解释性分析
目录 从词袋模型到BERT 分析BERT表示 不考虑上下文的方法 考虑语境的方法 结论 本文翻译自Are BERT Features InterBERTible? 从词袋模型到BERT Mikol ...
- 【译】为什么BERT有3个嵌入层,它们都是如何实现的
目录 引言 概览 Token Embeddings 作用 实现 Segment Embeddings 作用 实现 Position Embeddings 作用 实现 合成表示 结论 参考文献 本文翻译 ...
- 深入理解BERT Transformer ,不仅仅是注意力机制
来源商业新知网,原标题:深入理解BERT Transformer ,不仅仅是注意力机制 BERT是google最近提出的一个自然语言处理模型,它在许多任务 检测上表现非常好. 如:问答.自然语言推断和 ...
- 采用Google预训bert实现中文NER任务
本博文介绍用Google pre-training的bert(Bidirectional Encoder Representational from Transformers)做中文NER(Name ...
- 【中文版 | 论文原文】BERT:语言理解的深度双向变换器预训练
BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding 谷歌AI语言组论文<BERT:语言 ...
随机推荐
- 使用Hugo和GitHub搭建博客
折腾了几天博客的框架终于搭建起来了.研究了一番之后,最终还是选择使用Hugo和GitHub来搭建博客.本文介绍了如何使用Hugo来搭建静态博客网站,并将其部署在GitHub上.使用https://&l ...
- Go与接口:实现接口的条件
接口类型变量 Go是强类型语言,你不能将整数值赋值给浮点型变量.同样,也不能将没有实现接口的类型值赋值给接口类型变量. // 1.定义变量是接口类型 var w io.Writer // 2.将具体类 ...
- ORB_SLAM2 闭环检测段错误
问题描述: Ubuntu14.04运行正常.Ubuntu 16.04下运行时,检测到闭环后有时会段错误,定位发现断错误出现在CorrectLoop()的红色代码处 void LoopClosing:: ...
- JavaScript——字符串——模板字符串
JavaScript--字符串--模板字符串 字符串可以用反引号包裹起来,其中的${expression}表示特殊的含义,JavaScript会将expression代表的变量的值和反引号中的其它普通 ...
- vue 之 后端返回空字符串用 null 和 “”以及 undefind 判断不到的问题
原文: <!-- <span v-if="scope.row.buyer_credit_score != '' || scope.row.buyer_credit_score ! ...
- mysqli的基本使用
简单实例 面向过程方式 // 创建数据库连接 $connect = mysqli_connect('127.0.0.1', 'root', 'root', 'test', 8889); // 判读是否 ...
- docker日常使用指南
docker日常使用指南 目录 docker日常使用指南 前言 1.基础知识 1.1 docker是什么 1.2 与虚拟机(VM)的区别 1.3 镜像与容器 2.安装 2.1 在线安装 2.2 离线安 ...
- adb 常用命令大全(2)- 基础命令
adb 基本语法 adb [-d|-e|-s <serialNumber>] <command> 命令行参数 -d:指定当前唯一通过 USB 连接的 Android 设备为命令 ...
- MongoDB(9)- 文档查询操作之 find() 的简单入门
find() MongoDB 中查询文档使用 find() find() 方法以非结构化的方式来显示所要查询的文档 语法格式 db.collection.find(query, projection) ...
- IPSec协议框架
文章目录 1. IPSec简介 1.1 起源 1.2 定义 1.3 受益 2. IPSec原理描述 2.1 IPSec协议框架 2.1.1 安全联盟 2.1.2 安全协议 报文头结构 2.1.3 封装 ...