听说:分布式ID不能全局递增?
大家好,我是【架构摆渡人】,一只十年的程序猿。这是实践经验系列的第十一篇文章,这个系列会给大家分享很多在实际工作中有用的经验,如果有收获,还请分享给更多的朋友。
前面有篇文章我们讲到用时间来代替自增ID进行分页排序,原因是因为接入了分布式ID,但是分布式ID不能够保证有序,只能保证全局唯一。
那么今天我们一起来探讨下,究竟能不能实现有序的分布式ID呢?
分布式ID的实现方式
号段模式
号段模式是目前用的比较多的实现分布式ID的方式,号段模式通过预先获取一段范围,然后全部在内存中进行ID的分发,性能极高。
采用号段模式实现的开源框架也有很多,比如美团的Leaf,滴滴的Tinyid。对号段模式实现原理不了解的小伙伴可以查看下面的地址进行深入学习。号段模式想要实现递增比较难,文章后面我们一起聊聊有没有什么方式能够实现。
Leaf: https://github.com/Meituan-Dianping/Leaf
Tinyid: https://github.com/didi/tinyid
Snowflake
Snowflake 是 Twitter 开源的分布式ID生成算法,在国内用的也比较多。比如百度开源的uid-generator就是基于Snowflake算法进行改进。
uid-generator:https://github.com/baidu/uid-generator
Snowflake生成ID性能很好,而且也满足递增的要求。不过依赖机器上的时间,如果时间不一致就会有重复的问题。
Redis Incr
Redis 可以直接使用Incr命令进行数字的递增,从而实现自增的ID。如果使用Redis实现分布式ID需要进行ID的持久化,否则重启后就没了会出现重复的问题。
既然要持久化,那就避免不了使用AOF或者RDB实现持久化。使用RDB可能会丢失数据,导致ID重复发生。使用AOF肯定要配置刷数据的模式为always,每次操作记录都同步到硬盘上,这样才能保证数据不丢失,但是性能较差。当然Redis 4.0还有混合模式(AOF+RDB)可以用也是一种不错的选择。
无论是单机还是集群环境下,某个key必定会路由到某一个节点。虽然Redis单机也能支持10万基本的QPS,假设你的ID需求超过了这个量级,这块就会成为瓶颈,因为你要保证自增,没办法水平扩容。
号段模式想有序怎么办?
号段模式数据不会丢失,性能高,是一个很优秀的方案。但是号段模式没办法实现全局的递增ID,如果要实现全局递增,那么就不能拆分,得有一个固定的节点,所有请求都从这个节点获取ID才行。但是号段模式就是分段的特性,通过分段可以实现水平扩展,提升性能。
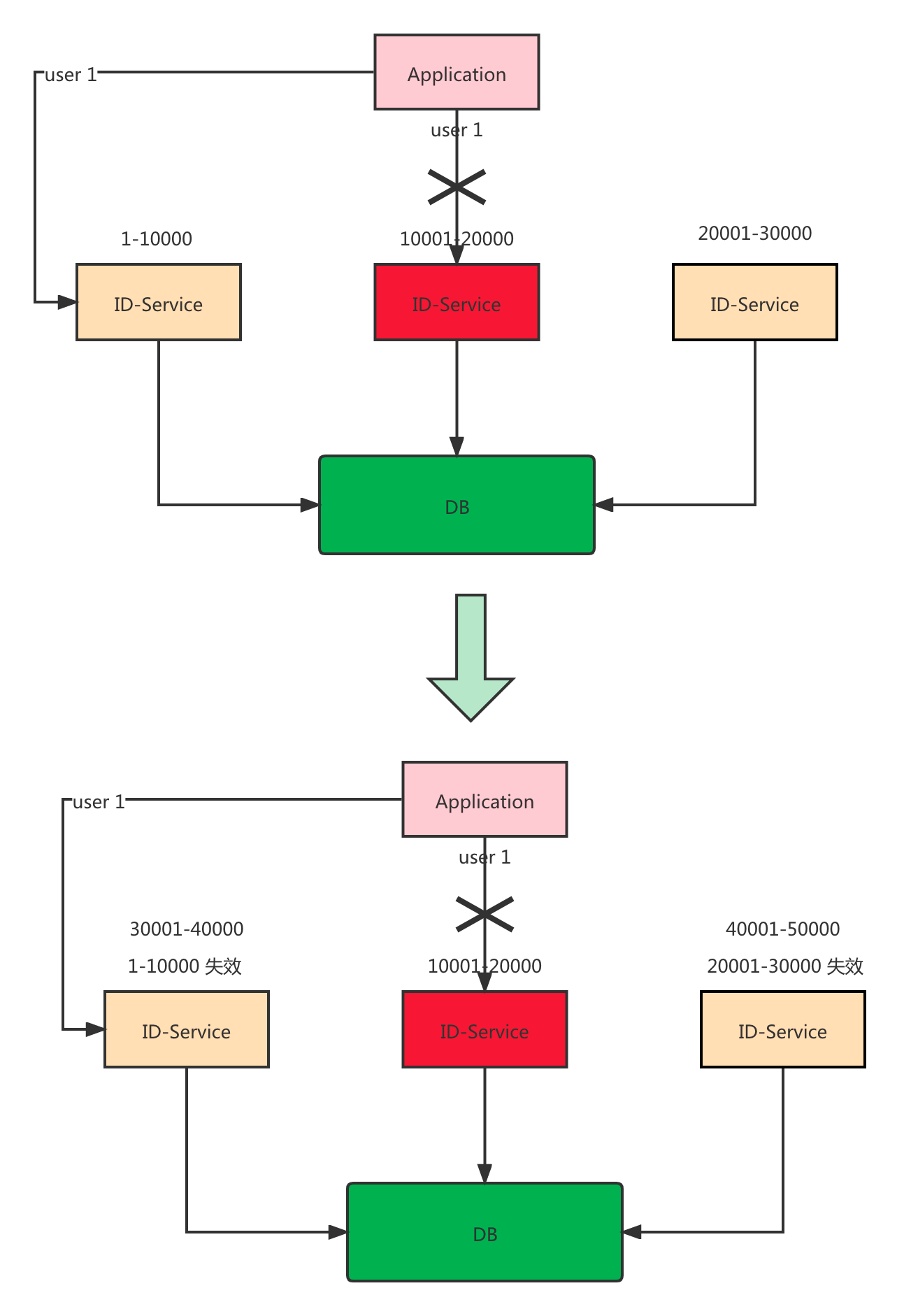
号段模式只能实现局部递增,比如我订单表接入了分布式ID,如果用号段模式,那么就会出现我下第一单的ID是20001,接着下第二单,ID可能就是10003。如果此时用的是ID降序排序,就会出现顺序错乱的问题,这也是之前文章里面为什么要用高精度的时间来排序。
这种情况下,是否只要保证同一个用户下的数据是递增的就可以,这就是局部递增。如果要想实现局部递增需要考虑下面几个问题:
- 固定路由
用户维度的递增,就需要将用户的请求路由到固定的ID服务节点,这样取出来的ID就是局部递增。

- ID服务某个节点挂掉或者重启
假设用户A一直是路由到 id-service-b 上面,此时 id-service-b 挂掉了,那就需要重新找个新的节点进行路由,问题来了,路由到新的节点,假设是 id-service-c。
而此时 id-service-c 上面的ID 段可能比 id-service-b大,如果大的话就没问题,还是递增。如果小的话就有问题了呀,所以这个问题要解决。
如何解决上面的问题呢?
个人感觉这个问题不太好解决,因为路由到某一个节点的用户是N,也不可能对这些用户现有的ID进行查询,判断是否大于即将路由的服务的ID段。整个逻辑太复杂了。
有一个简单的方式,就是当有固定路由需求的ID要进行路由切换的时候,全局加锁(此时并发量大的话会影响使用方的RT),将这个ID对应的所有段都清除,这样重新路由的时候就又申请了新的段,新的段肯定大于之前的段,也就是递增。
总结
其实要想实现某个需求,背后的方式有很多。如何去选择适合,最优的方案这个是比较考验大家平时的积累和技术的广度。你得知道每种方案的原理是什么,差异点在哪,哪种成本更低,哪种能够完全符合业务需求。
原创:架构摆渡人(公众号ID:jiagoubaiduren),欢迎分享,转载请保留出处。
本文已收录至学习网站 http://cxytiandi.com/ ,里面有Spring Boot, Spring Cloud,分库分表,微服务,面试等相关内容。
听说:分布式ID不能全局递增?的更多相关文章
- 分布式ID生成方法-趋势有序的全局唯一ID
一.需求缘起 几乎所有的业务系统,都有生成一个记录标识的需求,例如: (1)消息标识:message-id (2)订单标识:order-id (3)帖子标识:tiezi-id 这个记录标识往往就是数据 ...
- 冰河开源了全网首个完全开源的分布式全局有序序列号(分布式ID)框架!!
写在前面 mykit-serial框架的设计参考了李艳鹏大佬开源的vesta框架,并彻底重构了vesta框架,借鉴了雪花算法(SnowFlake)的思想,并在此基础上进行了全面升级和优化.支持嵌入式( ...
- 细聊分布式ID生成方法
细聊分布式ID生成方法 https://mp.weixin.qq.com/s?__biz=MjM5ODYxMDA5OQ==&mid=403837240&idx=1&sn=ae9 ...
- spring boot / cloud (十六) 分布式ID生成服务
spring boot / cloud (十六) 分布式ID生成服务 在几乎所有的分布式系统或者采用了分库/分表设计的系统中,几乎都会需要生成数据的唯一标识ID的需求, 常规做法,是使用数据库中的自动 ...
- 分布式ID方案有哪些以及各自的优劣势,我们当如何选择
作者介绍 段同海,就职于达达基础架构团队,主要参与达达分布式ID生成系统,日志采集系统等中间件研发工作. 背景 在分布式系统中,经常需要对大量的数据.消息.http请求等进行唯一标识,例如:在分布式系 ...
- 分布式Id教程
转自:https://baijiahao.baidu.com/s?id=1584913615817222458&wfr=spider&for=pc 一,题记 所有的业务系统,都有生成I ...
- Leaf:美团分布式ID生成服务开源
Leaf是美团基础研发平台推出的一个分布式ID生成服务,名字取自德国哲学家.数学家莱布尼茨的一句话:“There are no two identical leaves in the world.”L ...
- 分布式ID设计方案
分布式ID的定义: 全局唯一 有序性 有意义 高可用 紧凑性 序列号的可预测性 方案1:使用数据库递增的顺序 最常见的方式.利用数据库,全数据库唯一. 优点: 1)简单,代码方便,性能可以接受. 2) ...
- 分布式ID生成器解决方案
一.分布式系统带来ID生成挑战 在复杂的系统中,往往需要对大量的数据如订单,账户进行标识,以一个有意义的有序的序列号来作为全局唯一的ID; 而分布式系统中我们对ID生成器要求又有哪些呢? 全局唯一性: ...
随机推荐
- mysql加强(4)~多表查询
mysql加强(4)~多表查询:笛卡尔积.消除笛卡尔积操作(等值.非等值连接),内连接(隐式连接.显示连接).外连接.自连接 一.笛卡尔积 1.什么是笛卡尔积: 数学上,有两个集合A={a,b},B= ...
- SIFT,SuperPoint在图像特征提取上的对比实验
SIFT,SuperPoint都具有提取图片特征点,并且输出特征描述子的特性,本篇文章从特征点的提取数量,特征点的正确匹配数量来探索一下二者的优劣. 视角变化较大的情况下 原图1 原图2 SuperP ...
- 如何在 VS Code 中搭建 Qt 开发环境
前言 VS Code 高大上的界面.强大的智能联想和庞大的插件市场,着实让人对他爱不释手.虽然可以更改 Qt Creator 的主题,但是 Qt Creator 的代码体验实在差劲.下面就来看看如何在 ...
- 「NOI十联测」反函数
30pts 令(为1,)为-1: 暴力枚举每个点为起始点的路径,一条路径是合法的当且仅当路径权值和为0且路径上没有出现过负数. 将所有答案算出. 100pts 使用点分治. 要求知道经过重心root的 ...
- 「CTSC 2011」幸福路径
[「CTSC 2011」幸福路径 蚂蚁是可以无限走下去的,但是题目对于精度是有限定的,只要满足精度就行了. \({(1-1e-6)}^{2^{25}}=2.6e-15\) 考虑使用倍增的思想. 定义\ ...
- Redis哨兵模式高可用解决方案
一.序言 Redis高可用有两种模式:哨兵模式和集群模式,本文基于哨兵模式搭建一主两从三哨兵Redis高可用服务. 1.目标与收获 一主两从三哨兵Redis服务,基本能够满足中小型项目的高可用要求,使 ...
- git rm 与 git rm --cached 的区别
感谢原文作者:book_02 原文链接:https://www.jianshu.com/p/1c442fd398b7 git rm : 同时从工作区和索引中删除文件.即本地的文件也被删除了. git ...
- Redis-46面试题
1.什么是 Redis?简述它的优缺点? Redis 的全称是:Remote Dictionary.Server,本质上是一个 Key-Value 类型的内存数据库,很像 memcached,整个数据 ...
- shell 的here document 用法 (cat << EOF) (转)
什么是Here Document Here Document 是在Linux Shell 中的一种特殊的重定向方式,它的基本的形式如下 cmd << delimiter Here Docu ...
- rm, git rm, git rm --cached 区别与关系
HEAD, staging area, working copy在上篇<Git命令之回退篇 git revert git reset>已经讲过,不明白请自行传送过去. 1. rm 是仅仅删 ...