【Dubbo】SPI
什么是SPI
SPI是JDK内置的一种服务提供发现机制。目前市面上很多框架都用它来做服务的扩展发现。简单的说,它是一种动态替换发现的机制。
jdk 实现方式
需要在 classpath 下创建一个目录,该目录命名必须是:META-INF/service
在该目录下创建一个 properties 文件,该文件需要满足以下几个条件 :
- 文件名必须是扩展的接口的全路径名称
- 文件内部描述的是该扩展接口的所有实现类
- 文件的编码格式是 UTF-8
- 通过 java.util.ServiceLoader 的加载机制来发现
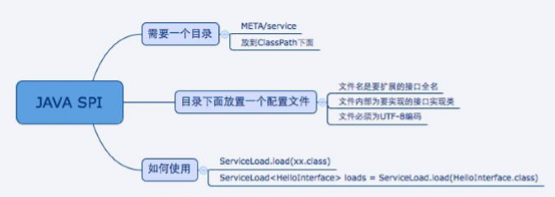
实现机制
样例代码
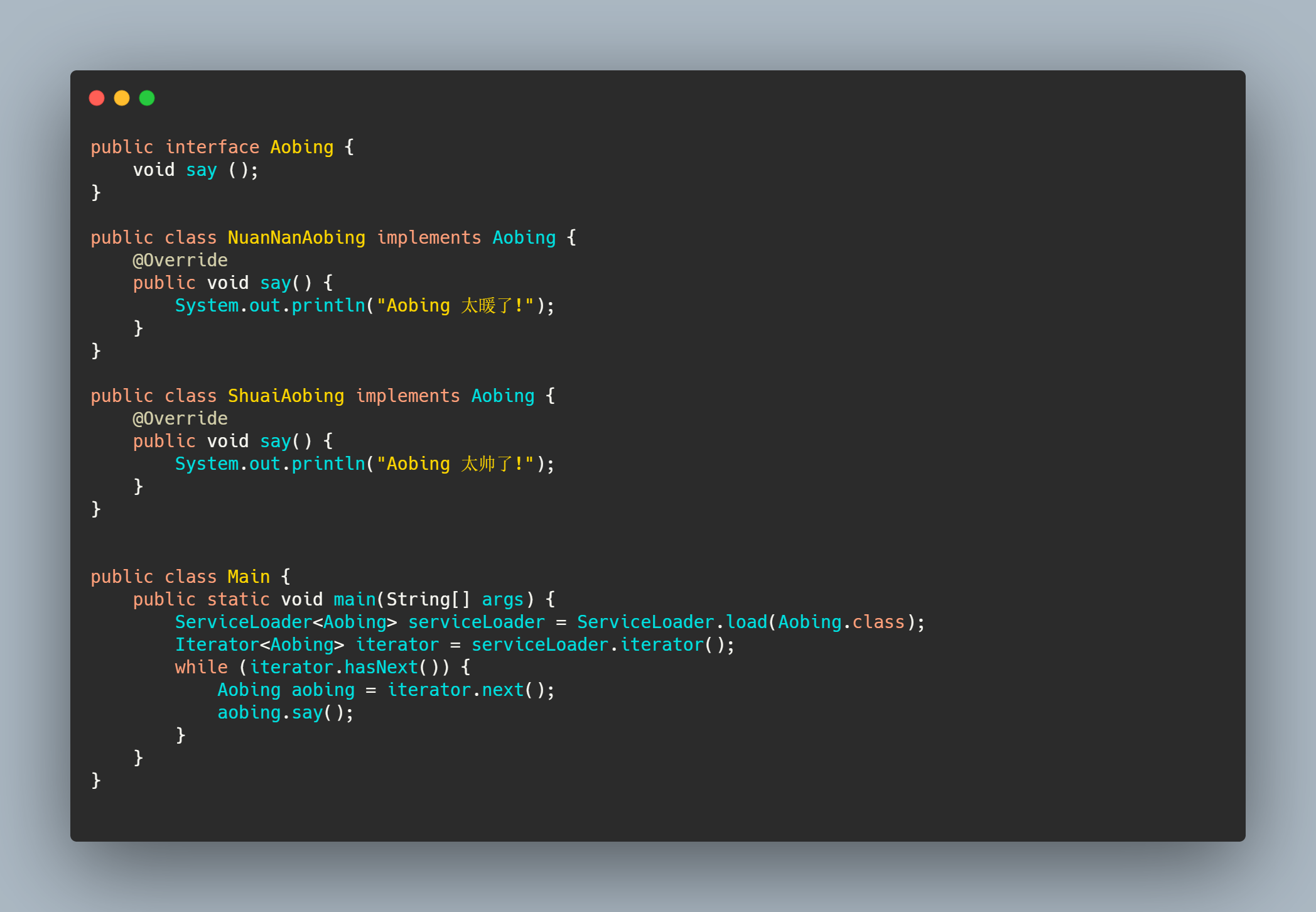
SPI 入口ServiceLoader.load(),先从此处开始分析。
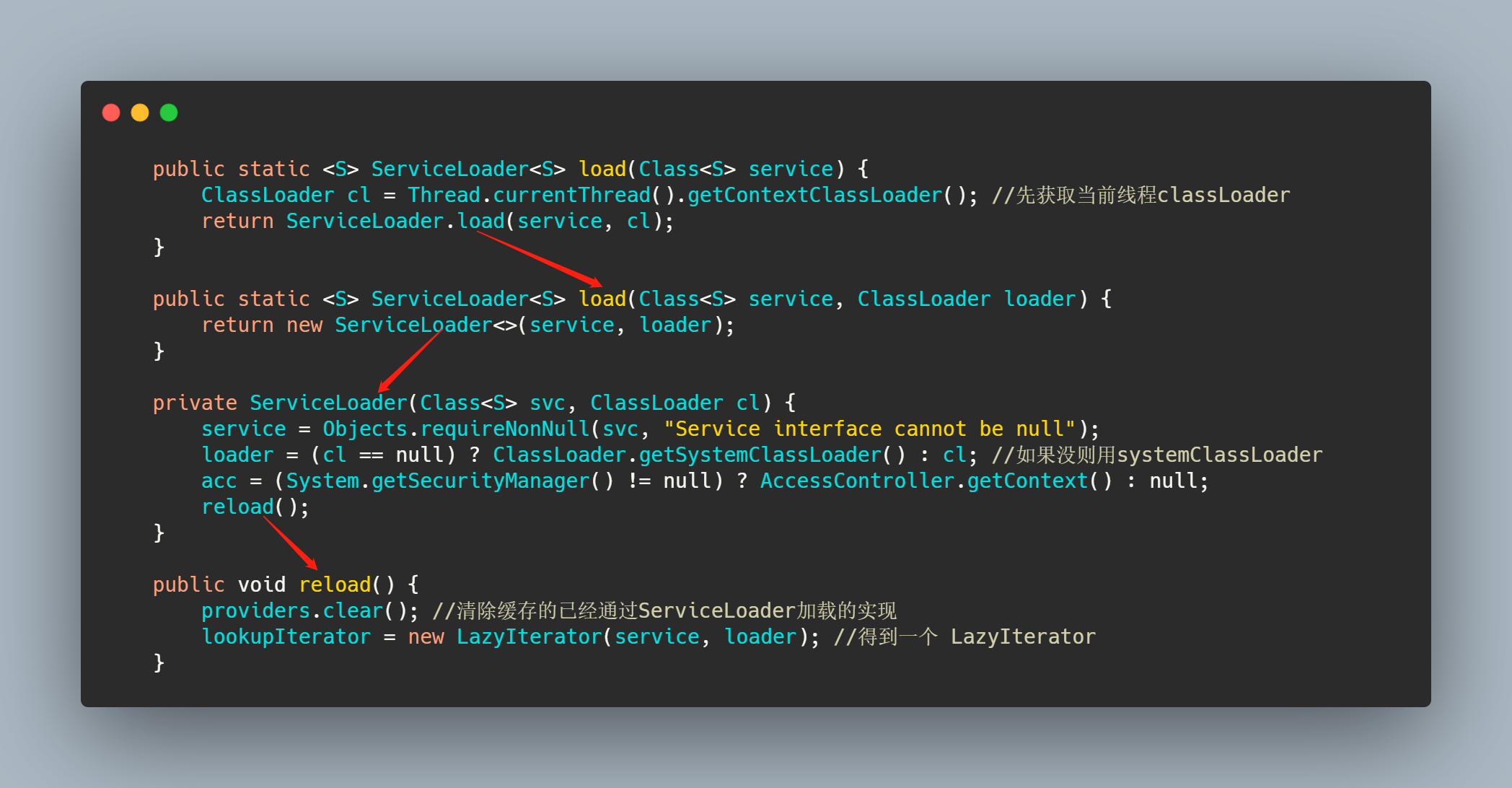
先找当前线程绑定的 ClassLoader,如果没有就用 SystemClassLoader,然后清除一下缓存,再创建一个 LazyIterator。最后在reload()函数中调用LazyIterator(),而LazyIterator()实现了Iterator接口,在样例中调用了,iterator() 跟进看其实现。
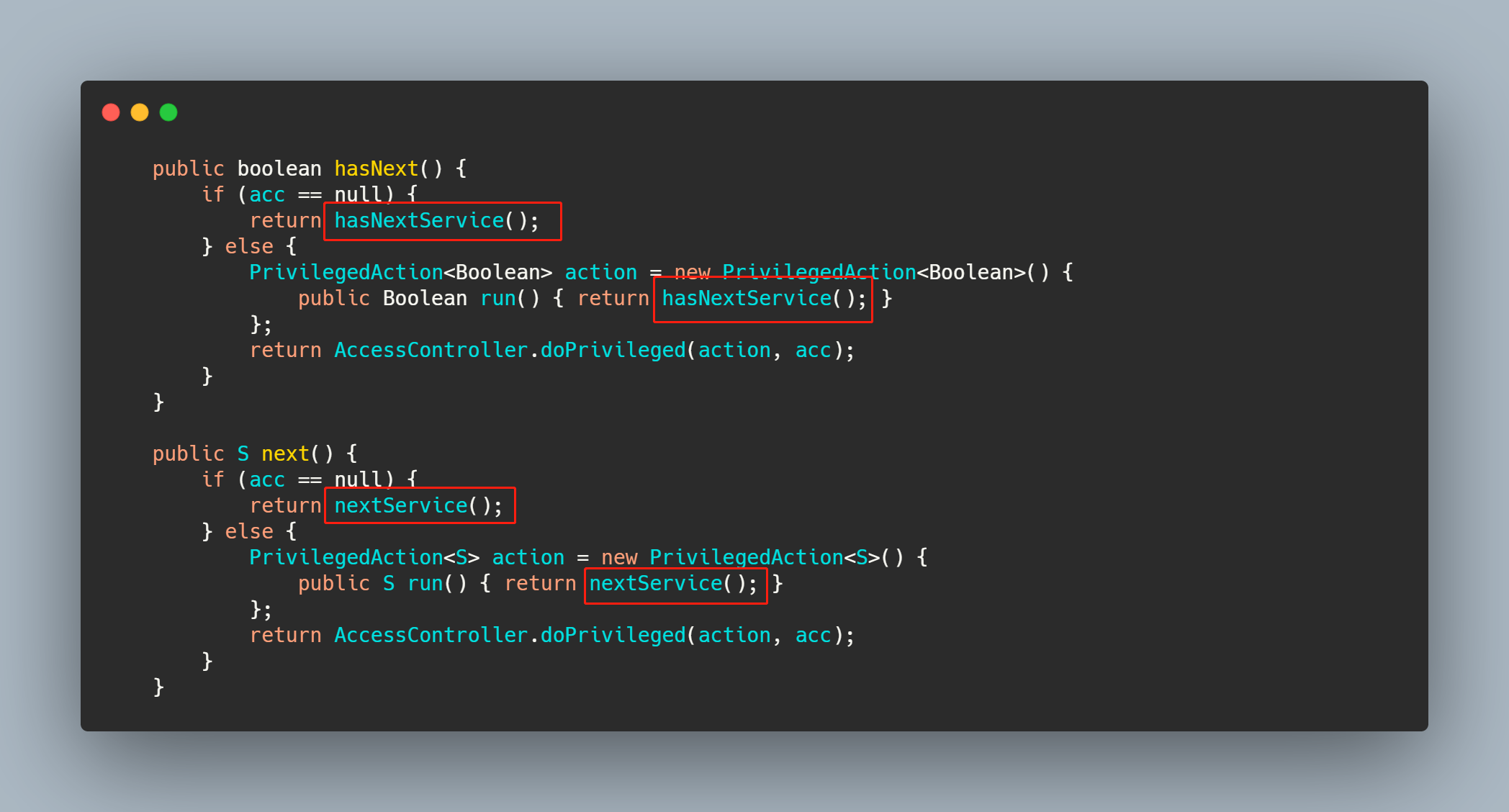
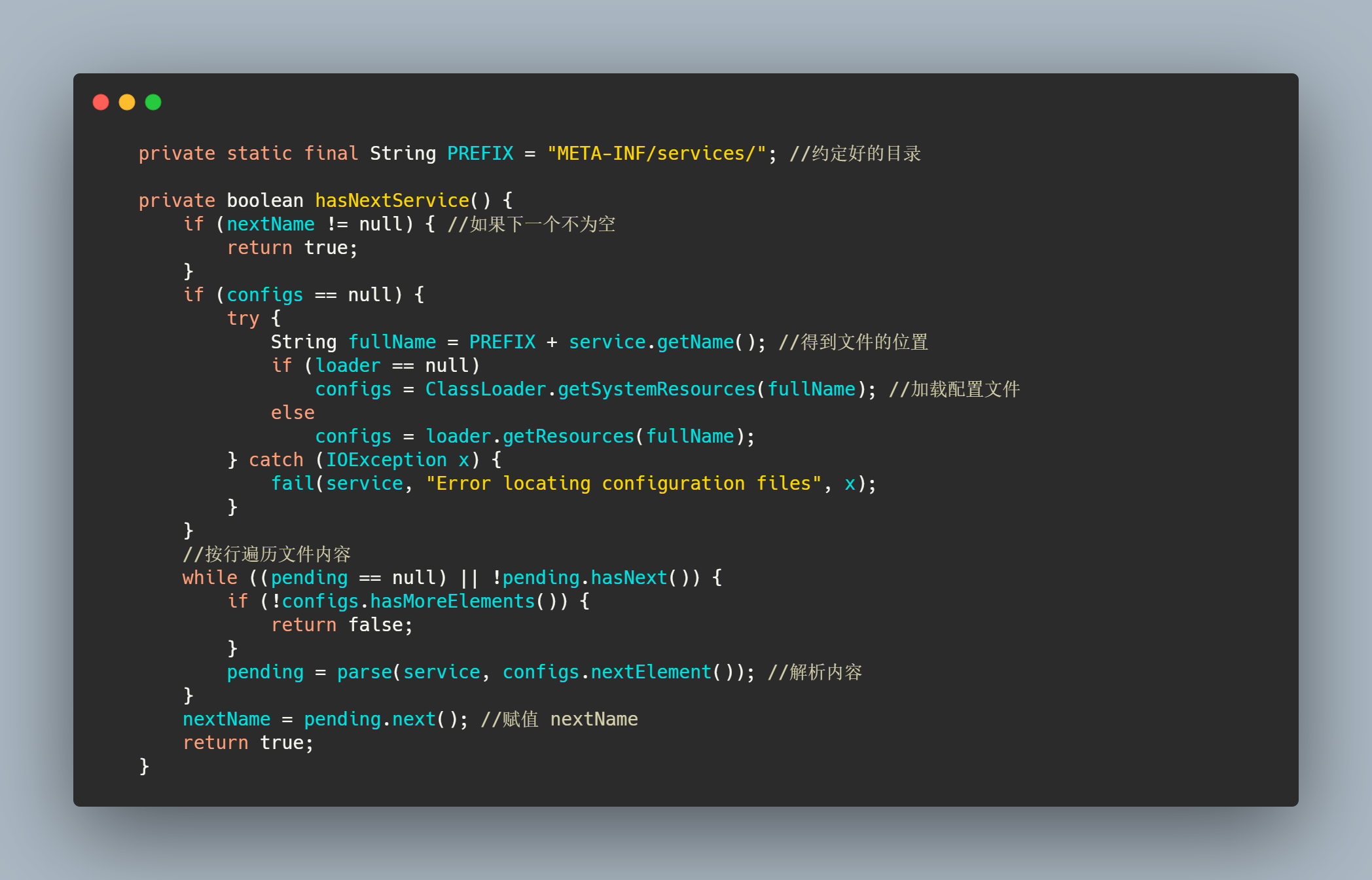
跟进框出的代码,追溯到最终的核心部分,可以分析出,约定好的地方找到接口对应的文件,然后加载文件并且解析文件里面的内容。而nextService()代码干了啥呢?

就是通过文件里填写的全限定名加载类,并且创建其实例放入缓存之后返回实例。整体流程如下:

SPI缺陷
- JDK 标准的 SPI 会一次性加载实例化扩展点的所有实现,什么意思呢?就是如果你在 META-INF/service 下的文件里面加了 N 个实现类,那么 JDK 启动的时候都会一次性全部加载。那么如果有的扩展点实现初始化很耗时或者如果有些实现类并没有用到, 那么会很浪费资源
- 如果扩展点加载失败,会导致调用方报错,而且这个错误很难定位到是这个原因
SPI Demo
Dubbo SPI
Dubbo也用了SPI思想,不过没有用JDK的SPI机制,是自己实现的一套SPI机制。在Dubbo的源码中,很多地方会存在下面这样的三种代码,分别是自适应扩展点、指定名称的扩展点、激活扩展点。
Dubbo SPI 除了可以按需加载实现类之外,增加了 IOC 和 AOP 的特性,还有个自适应扩展机制。
Dubbo 规范如下:
- 指定路径在META-INF/dubbo META-INF/internal META-INF/services 下
- 文件名(全路径)内容 (key,vlaue)
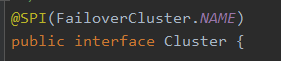
@SPI("dubbo")
public interface Protocol {
int getDefaultPort();
@Adaptive
<T> Exporter<T> export(Invoker<T> invoker) throws RpcException;
@Adaptive
<T> Invoker<T> refer(Class<T> type, URL url) throws RpcException;
void destroy();
}
Dubbo SPI Demo
首先在 META-INF/dubbo 目录下按接口全限定名建立一个文件,内容如下:
optimusPrime = org.apache.spi.OptimusPrime
bumblebee = org.apache.spi.Bumblebee
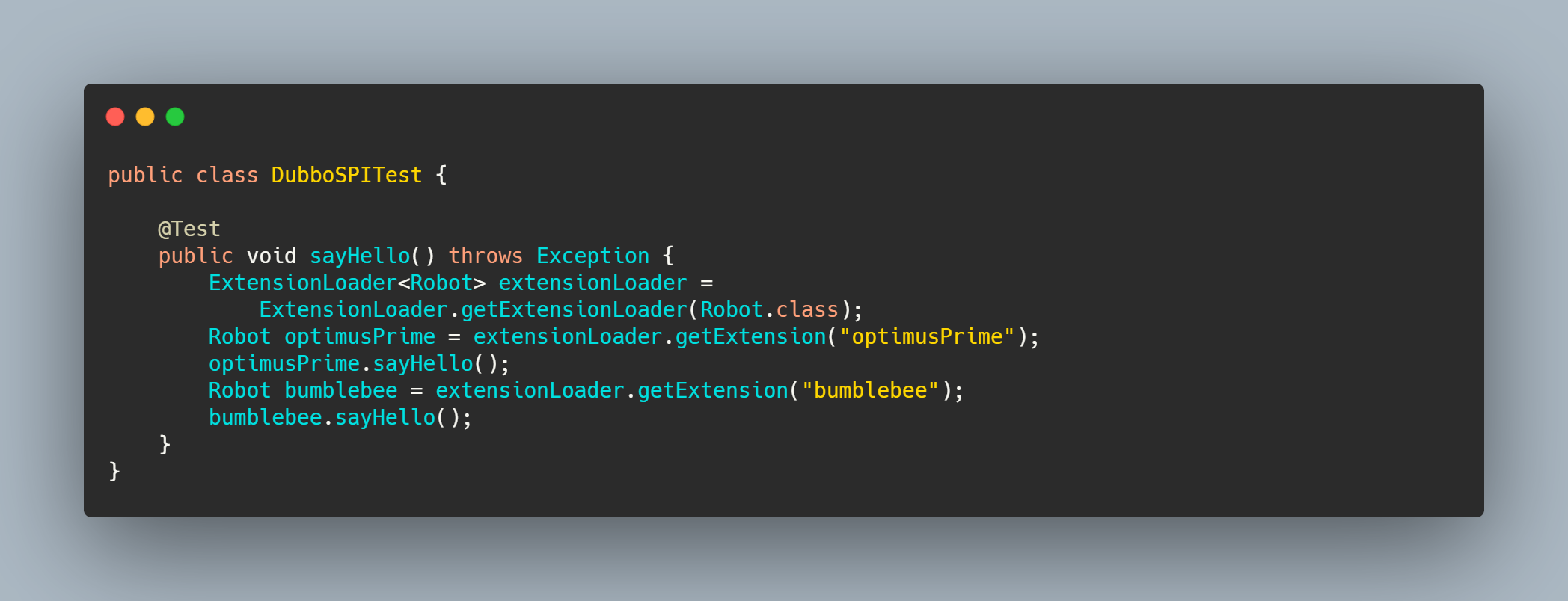
然后在接口上标注@SPI 注解,以表明它要用SPI机制。
下面的示例代码即可加载指定的实现类。
运行结果如下:

Dubbo 源码分析
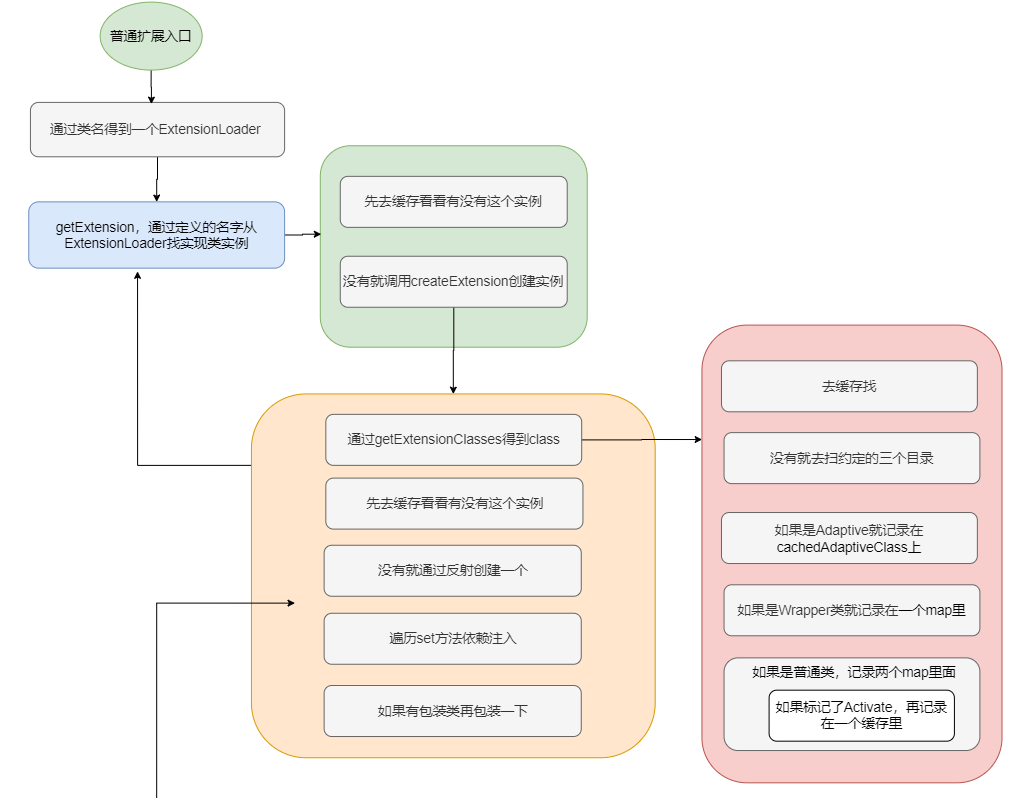
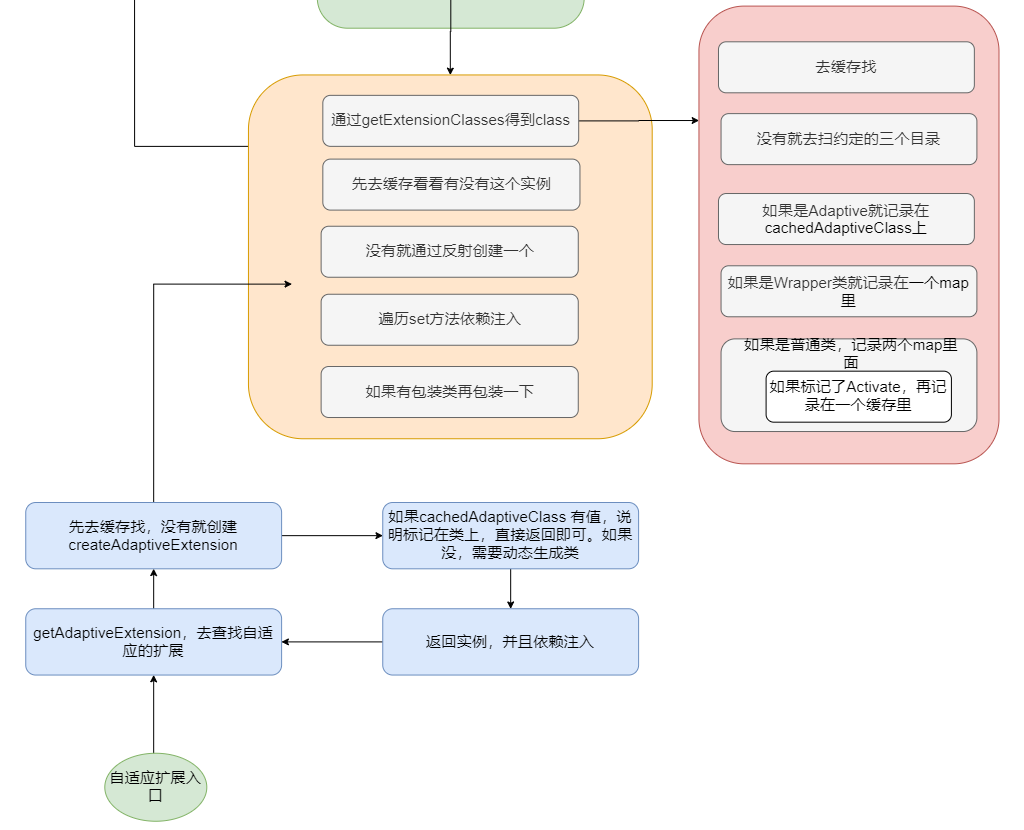
大致流程就是先通过接口类找到一个 ExtensionLoader ,然后再通过 ExtensionLoader.getExtension(name) 得到指定名字的实现类实例。
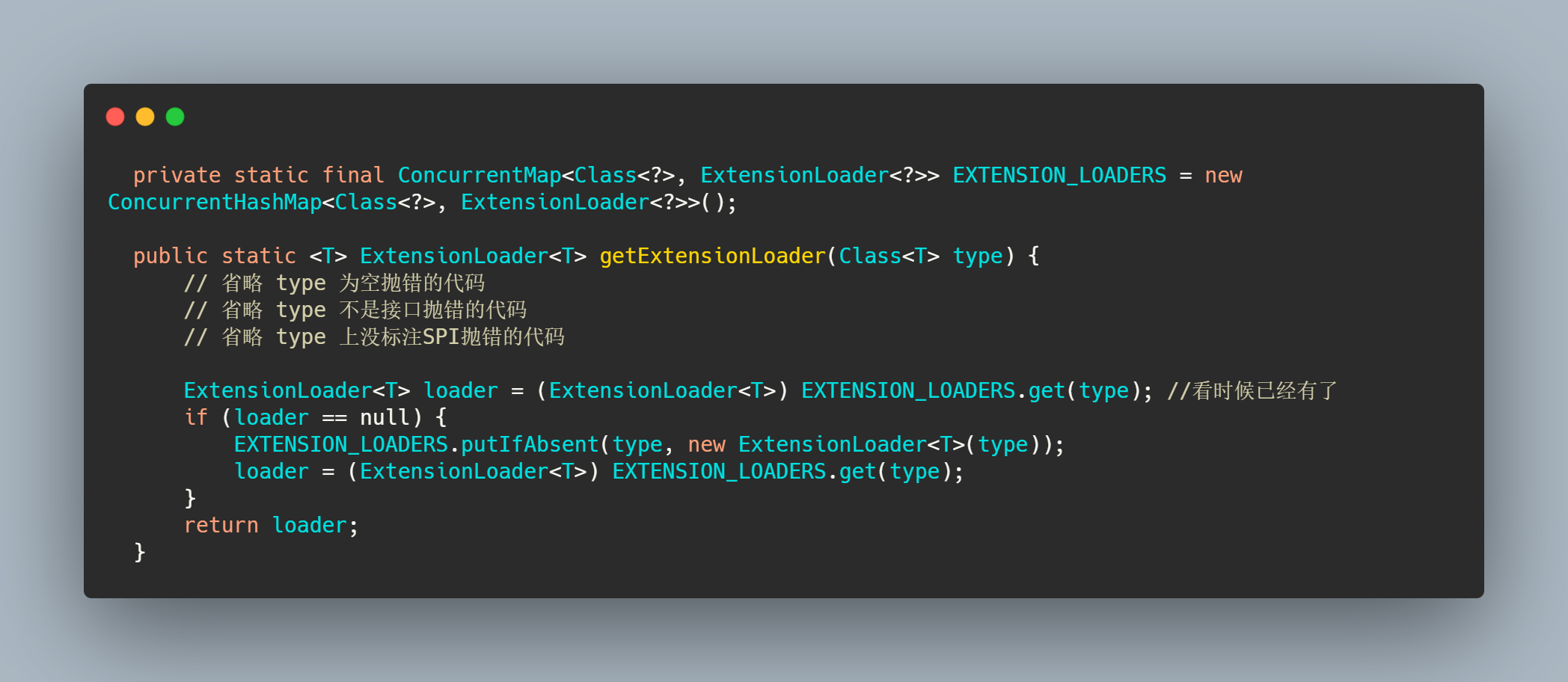
做了一些判断然后从缓存里面找是否已经存在这个类型的 ExtensionLoader ,如果没有就新建一个塞入缓存。最后返回接口类对应的 ExtensionLoader 。getExtension()这个方法就是从类对应的 ExtensionLoader 中通过名字找到实例化完的实现类。
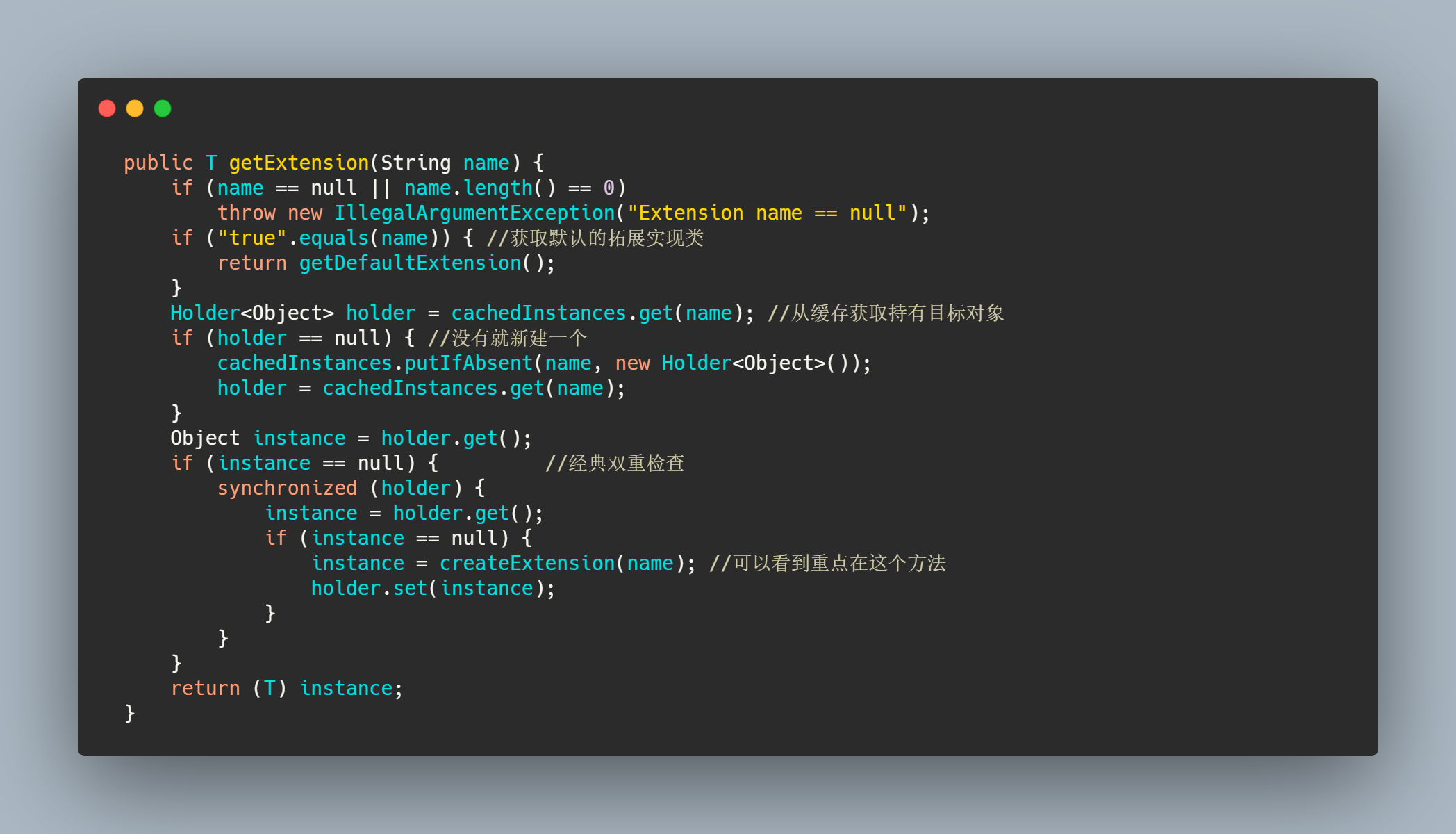
其中重点是createExtension()。
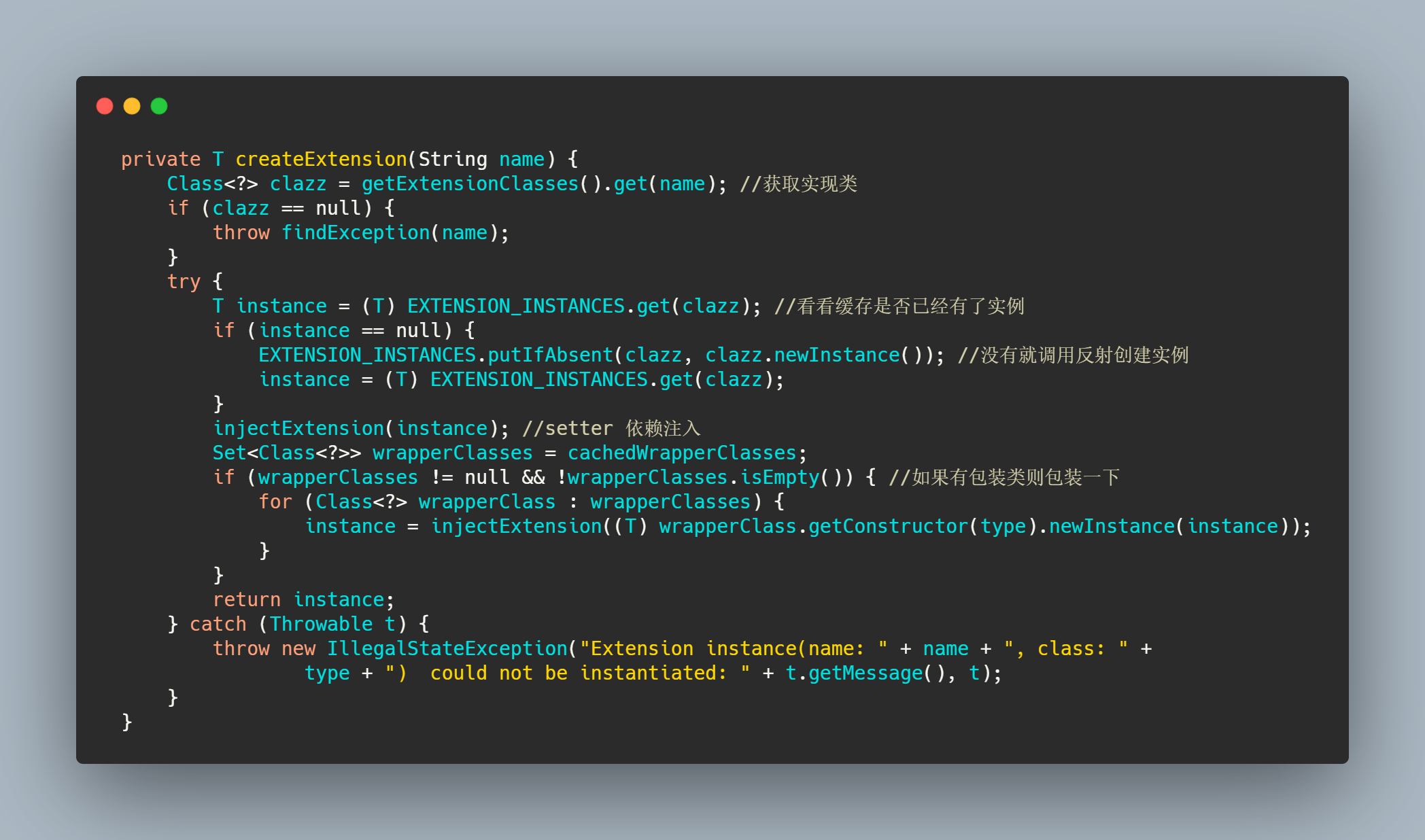
整体逻辑很清晰,先找实现类,判断缓存是否有实例,没有就反射建个实例,然后执行 set 方法依赖注入。如果有找到包装类的话,再包一层。
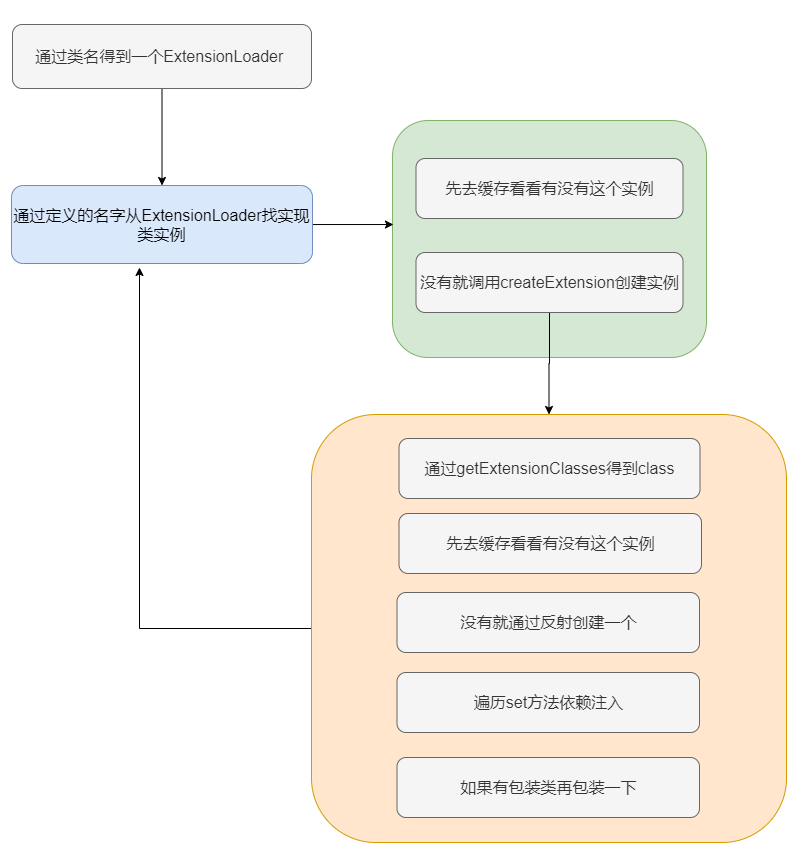
getExtensionClasses方法进去也是先去缓存中找,如果缓存是空的,那么调用 loadExtensionClasses,我们就来看下这个方法。
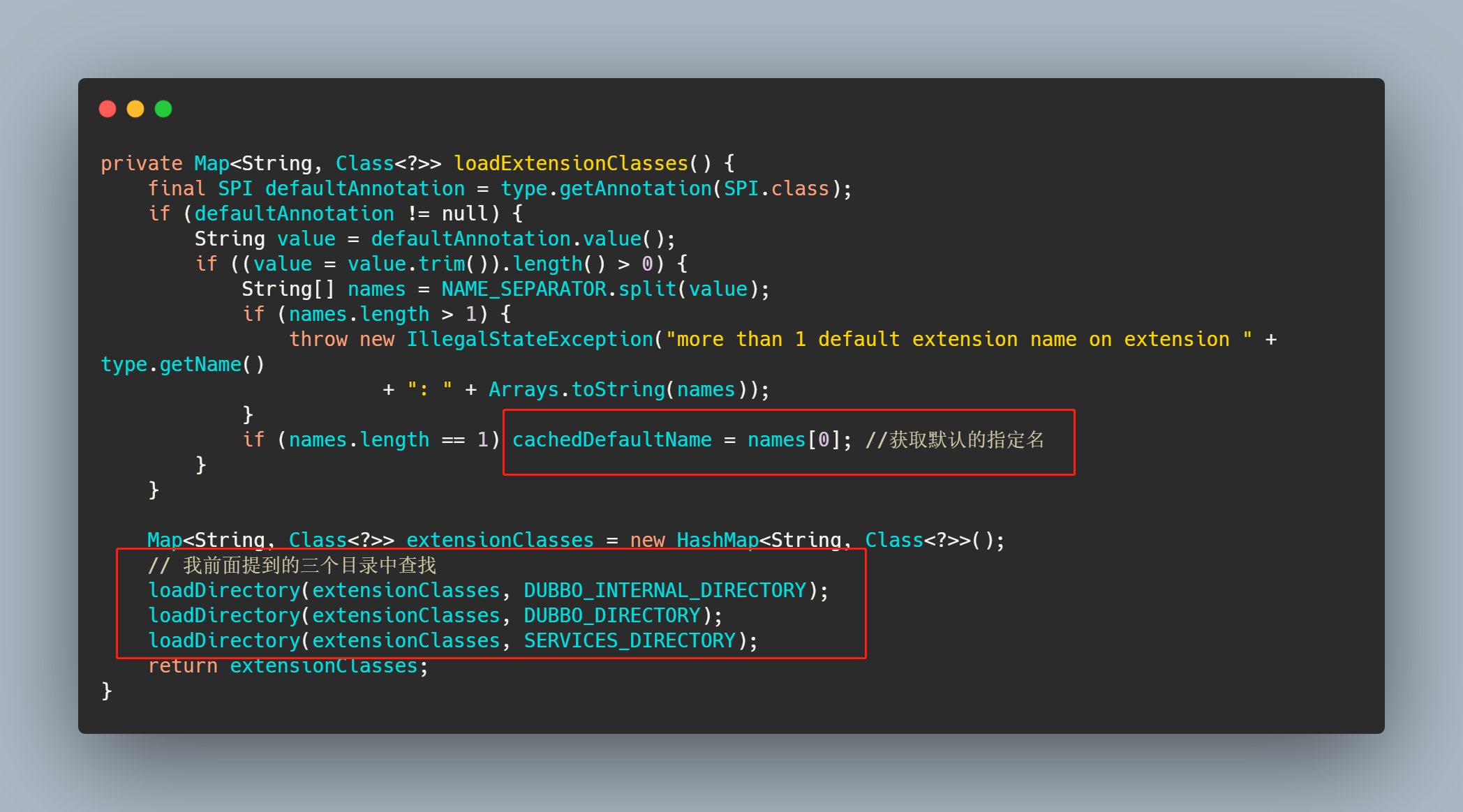
而 loadDirectory里面就是根据类名和指定的目录,找到文件先获取所有的资源,然后一个一个去加载类,然后再通过loadClass去做一下缓存操作。
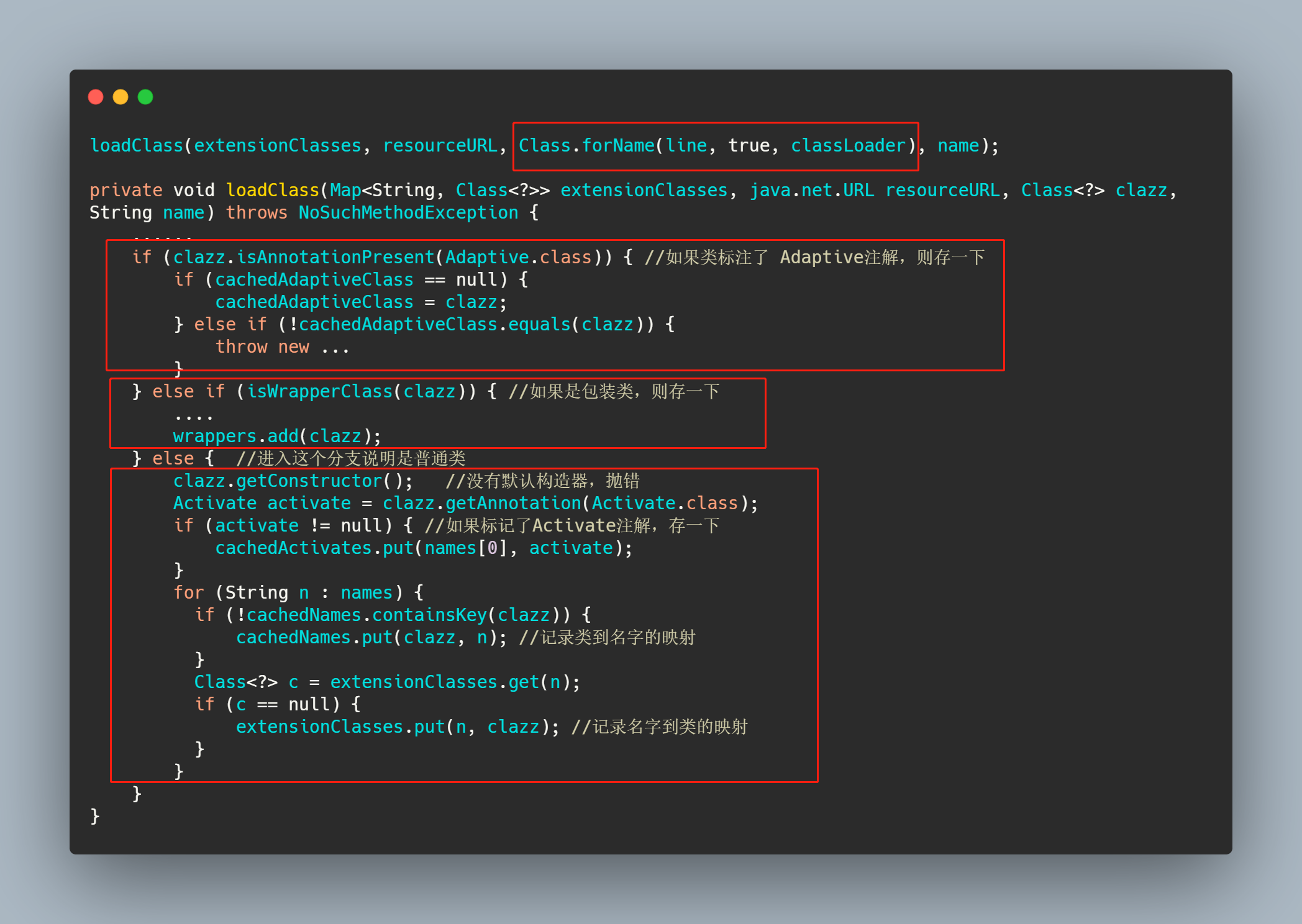
可以看到,loadClass 之前已经加载了类,loadClass 只是根据类上面的情况做不同的缓存。分别有 Adaptive 、WrapperClass 和普通类这三种,普通类又将Activate记录了一下。至此对于普通的类来说整个 SPI 过程完结了。
再分别看不是普通类的几种东西是干啥用的。
Adaptive 注解 - 自适应扩展
我们先来看一个场景,首先我们根据配置来进行 SPI 扩展的加载,但是我不想在启动的时候让扩展被加载,我想根据请求时候的参数来动态选择对应的扩展。
Dubbo 通过一个代理机制实现了自适应扩展,简单的说就是为你想扩展的接口生成一个代理类,可以通过JDK 或者 javassist 编译你生成的代理类代码,然后通过反射创建实例。
这个实例里面的实现会根据本来方法的请求参数得知需要的扩展类,然后通过 ExtensionLoader.getExtensionLoader(type.class).getExtension(从参数得来的name),来获取真正的实例来调用。
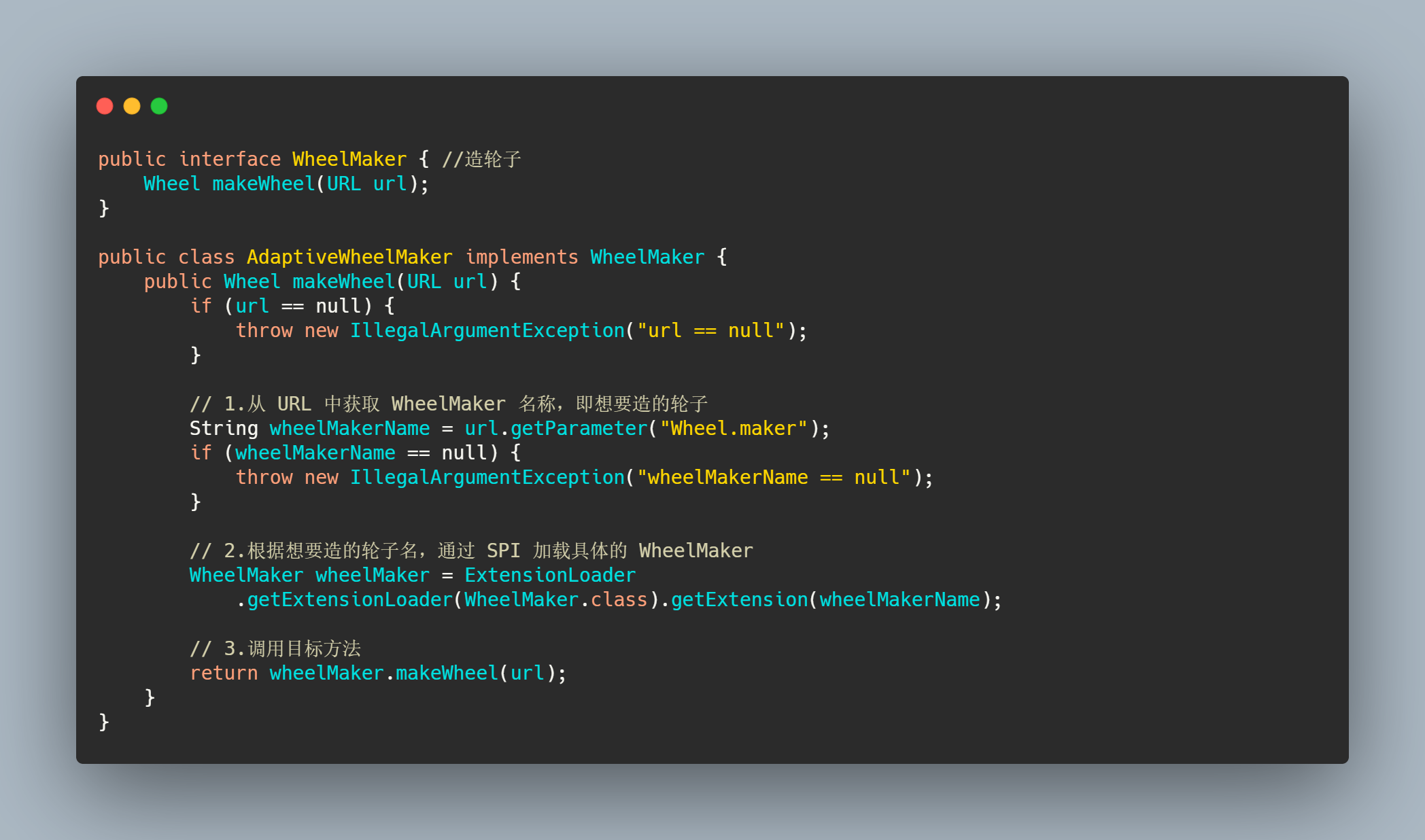
再来看下源码,到底怎么做的。
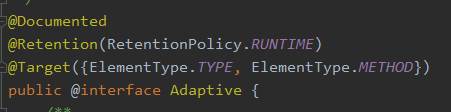
这个注解就是自适应扩展相关的注解,可以修饰类和方法上,在修饰类的时候不会生成代理类,因为这个类就是代理类,修饰在方法上的时候会生成代理类。
Adaptive 注解在类上
ExtensionFactory 有三个实现类,其中一个实现类就被标注了 Adaptive 注解。


在 ExtensionLoader 构造的时候就会去通过getAdaptiveExtension 获取指定的扩展类的 ExtensionFactory。
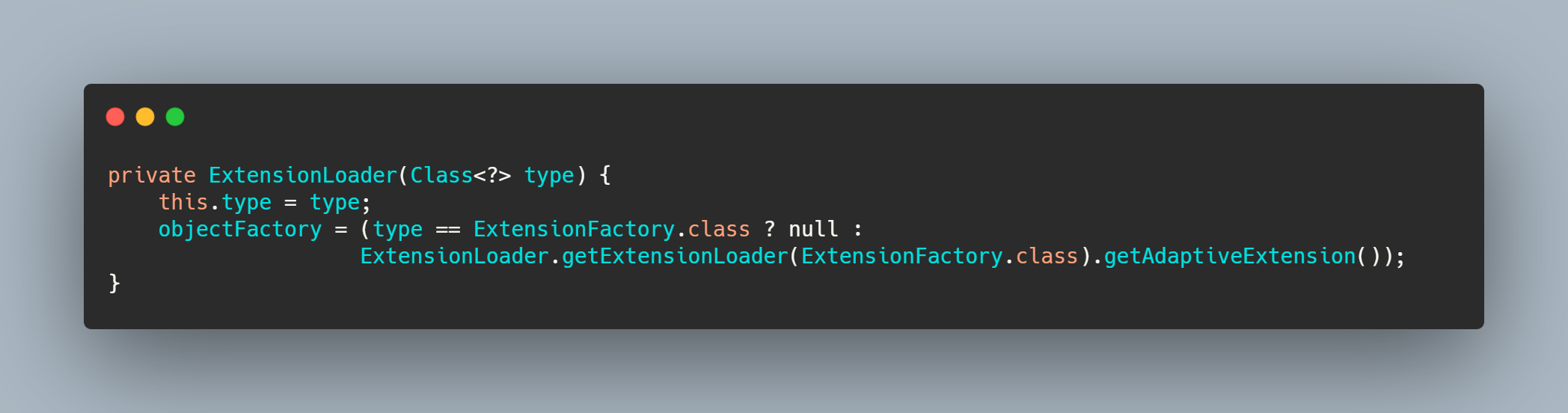
我们再来看下 AdaptiveExtensionFactory 的实现。
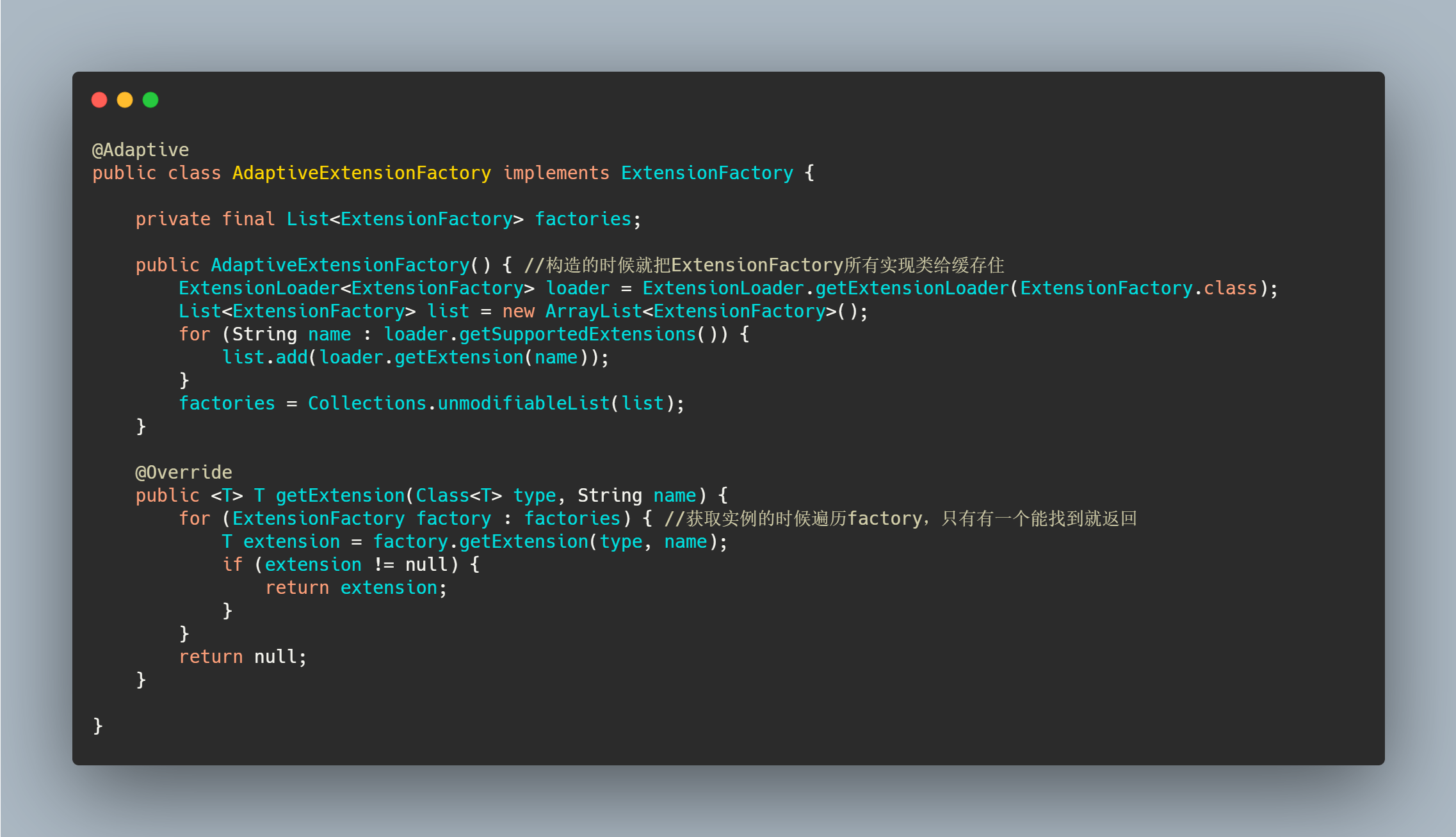
可以看到先缓存了所有实现类,然后在获取的时候通过遍历找到对应的 Extension。
我们再来深入分析一波 getAdaptiveExtension 里面到底干了什么。
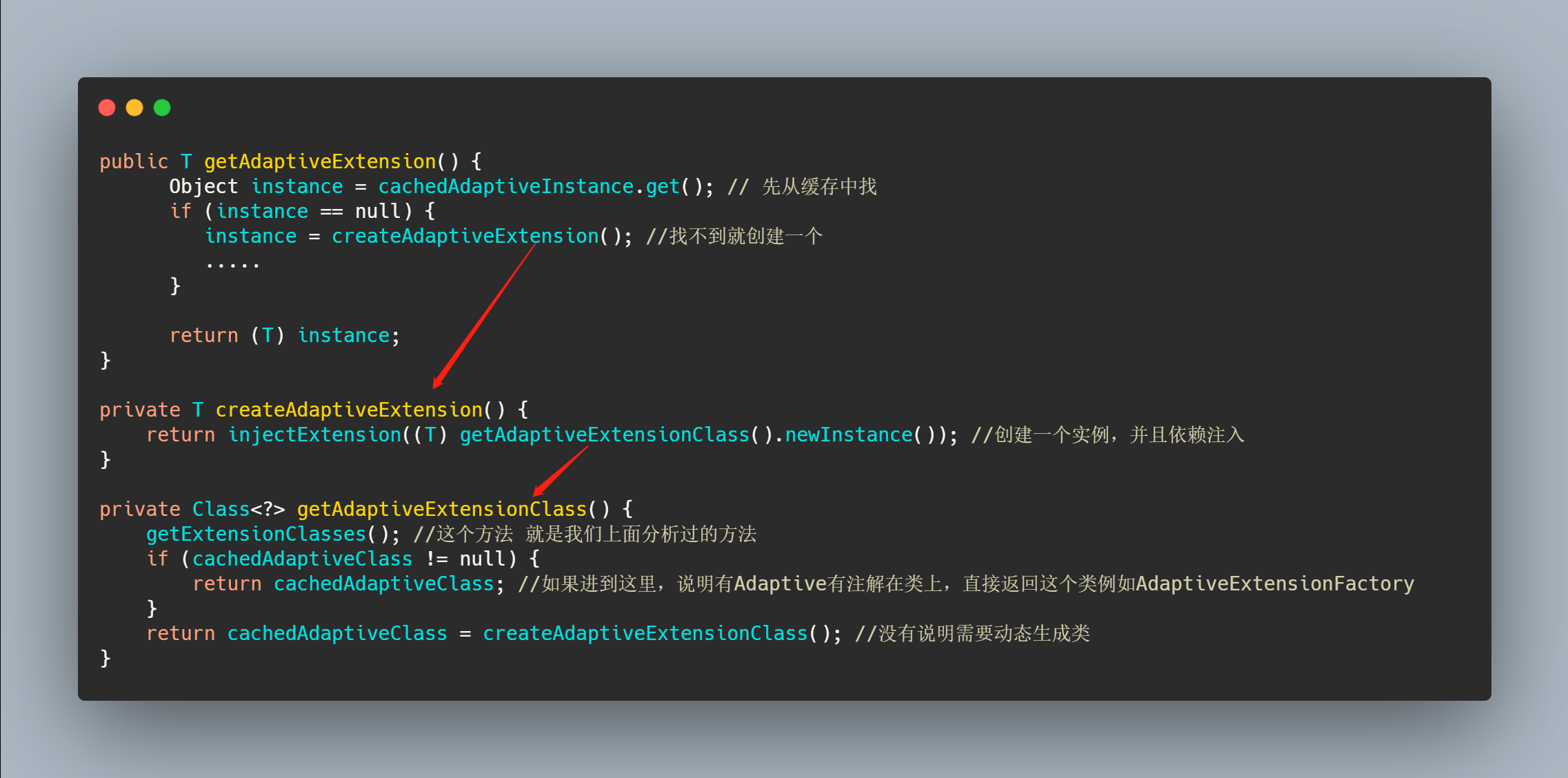
到这里其实已经和上文分析的 getExtensionClasses中loadClass 对 Adaptive 特殊缓存相呼应上了。
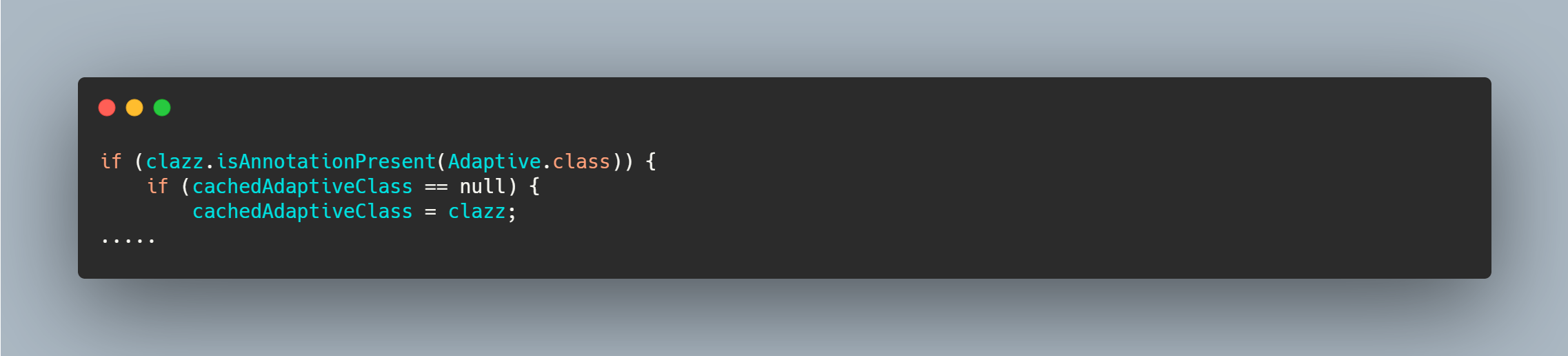
Adaptive 注解在方法上
注解在方法上则需要动态拼接代码,然后动态生成类,我们以 Protocol 为例子来看一下。
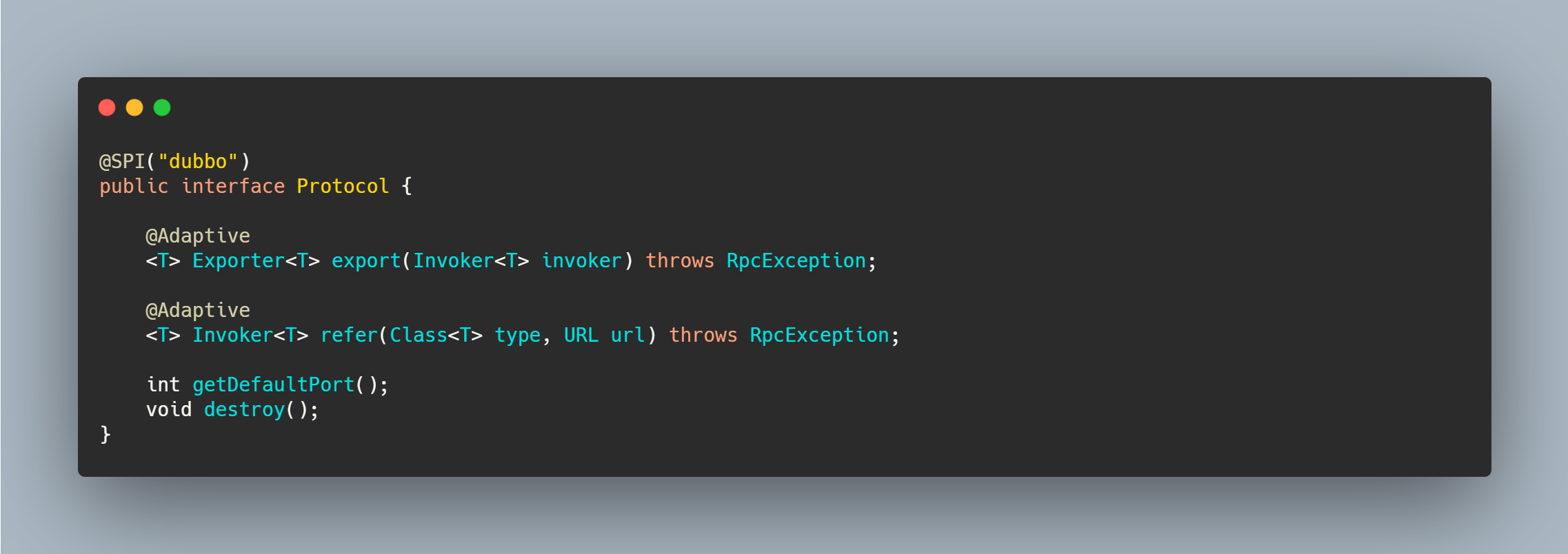
Protocol 没有实现类注释了 Adaptive ,但是接口上有两个方法注解了 Adaptive ,有两个方法没有。因此它走的逻辑应该应该是 createAdaptiveExtensionClass
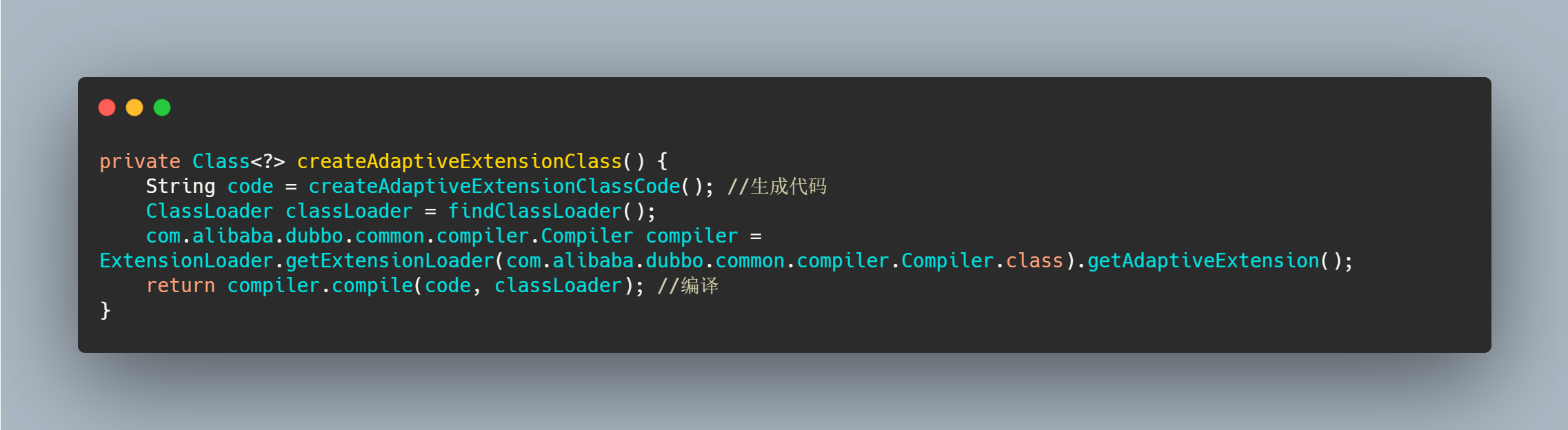
具体在里面如何生成代码的我就不再深入了,有兴趣的自己去看吧,我就把成品解析一下,就差不多了。

可以看到会生成包,也会生成 import 语句,类名就是接口加个$Adaptive,并且实现这接口,没有标记 Adaptive 注解的方法调用的话直接抛错。
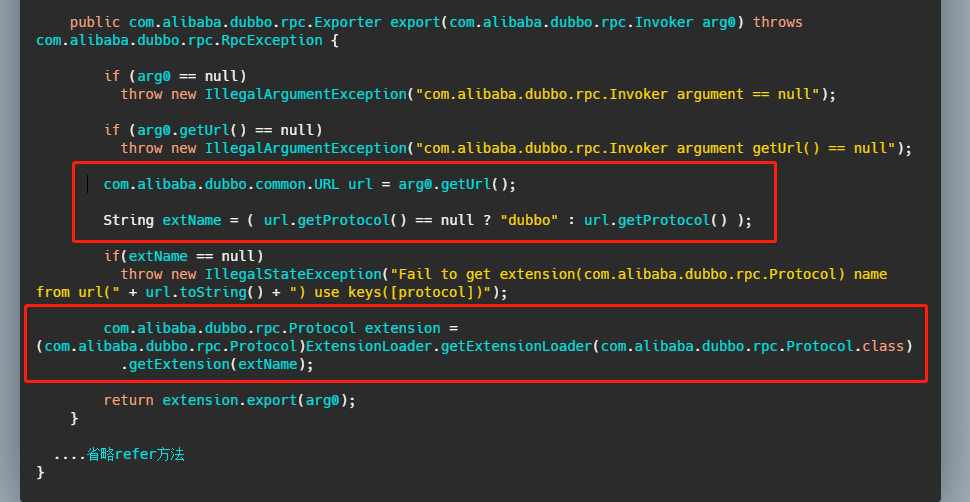
我们再来看一下标注了注解的方法,我就拿 export 举例。
WrapperClass - AOP
包装类是因为一个扩展接口可能有多个扩展实现类,而这些扩展实现类会有一个相同的或者公共的逻辑,如果每个实现类都写一遍代码就重复了,并且比较不好维护。
因此就搞了个包装类,Dubbo 里帮你自动包装,只需要某个扩展类的构造函数只有一个参数,并且是扩展接口类型,就会被判定为包装类,然后记录下来,用来包装别的实现类。
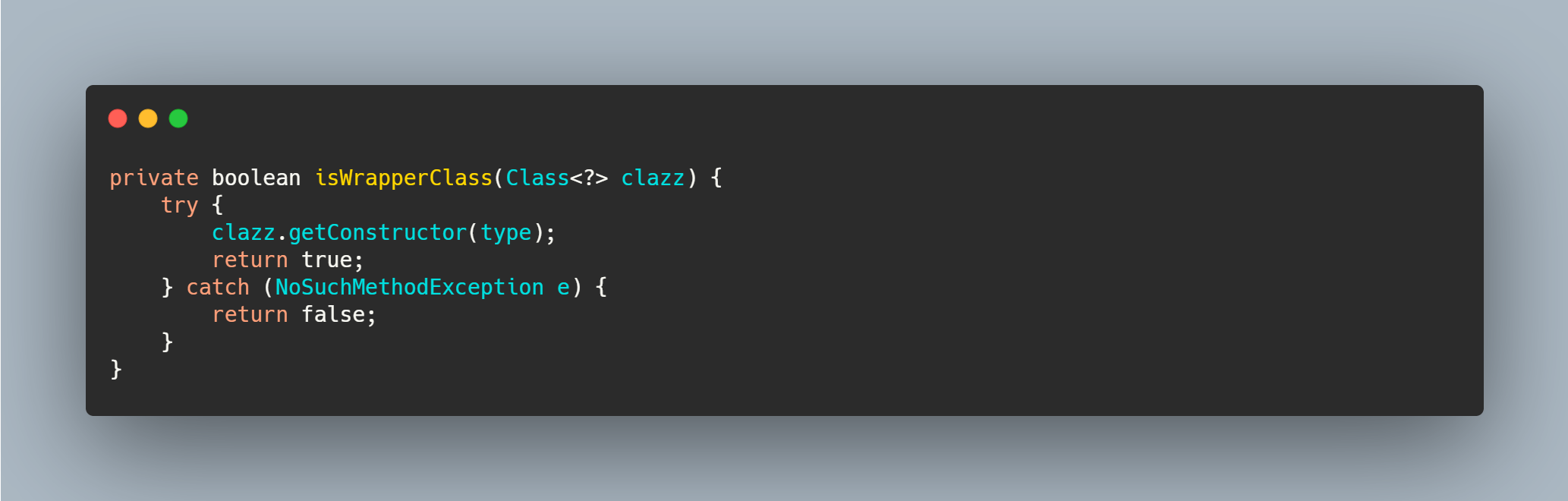
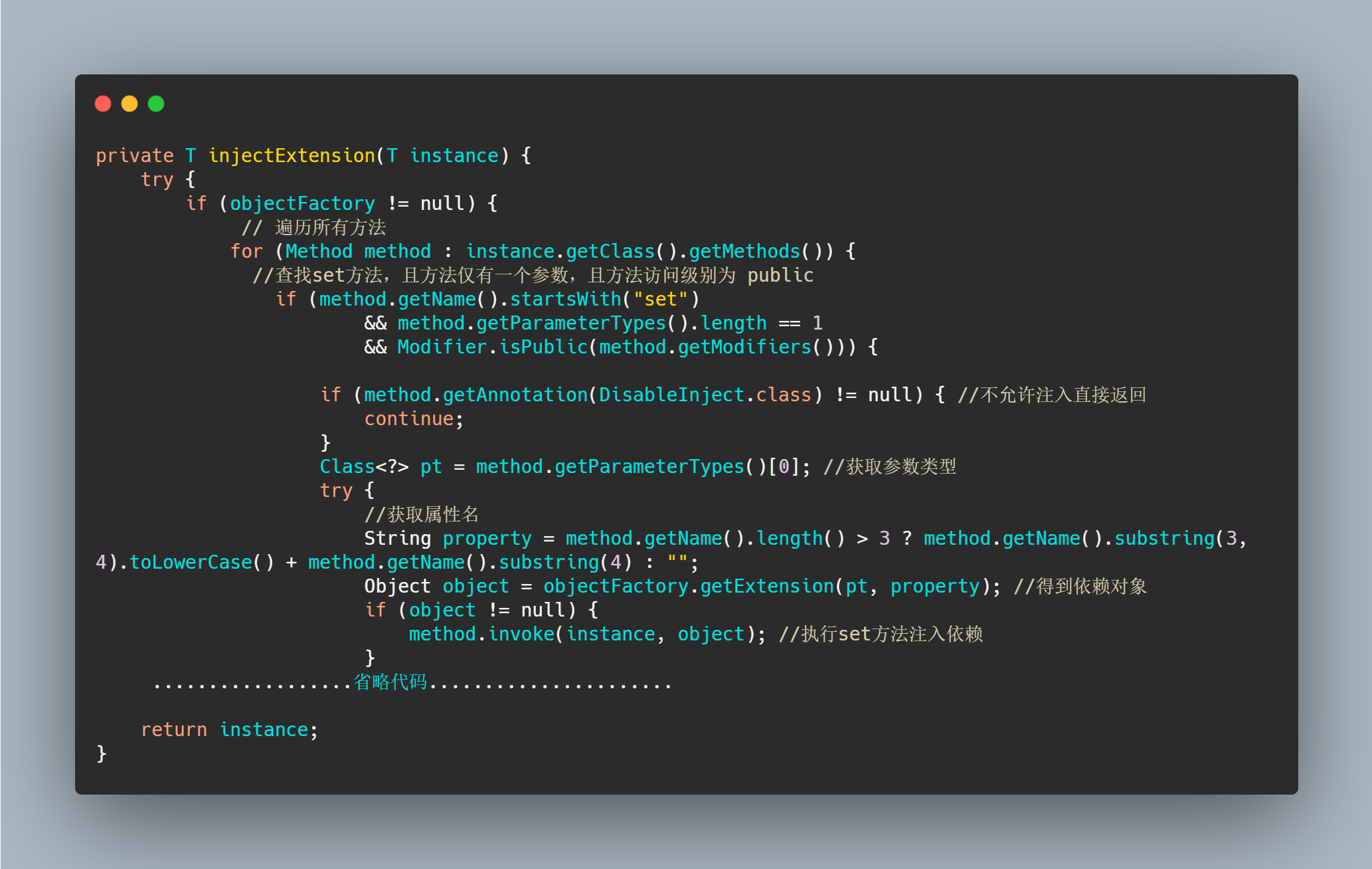
injectExtension - IOC
直接看代码,很简单,就是查找 set 方法,根据参数找到依赖对象则注入。
Activate 注解
这个注解我就简单的说下,拿 Filter 举例,Filter 有很多实现类,在某些场景下需要其中的几个实现类,而某些场景下需要另外几个,而 Activate 注解就是标记这个用的。
它有三个属性,group 表示修饰在哪个端,是 provider 还是 consumer,value 表示在 URL参数中出现才会被激活,order 表示实现类的顺序。
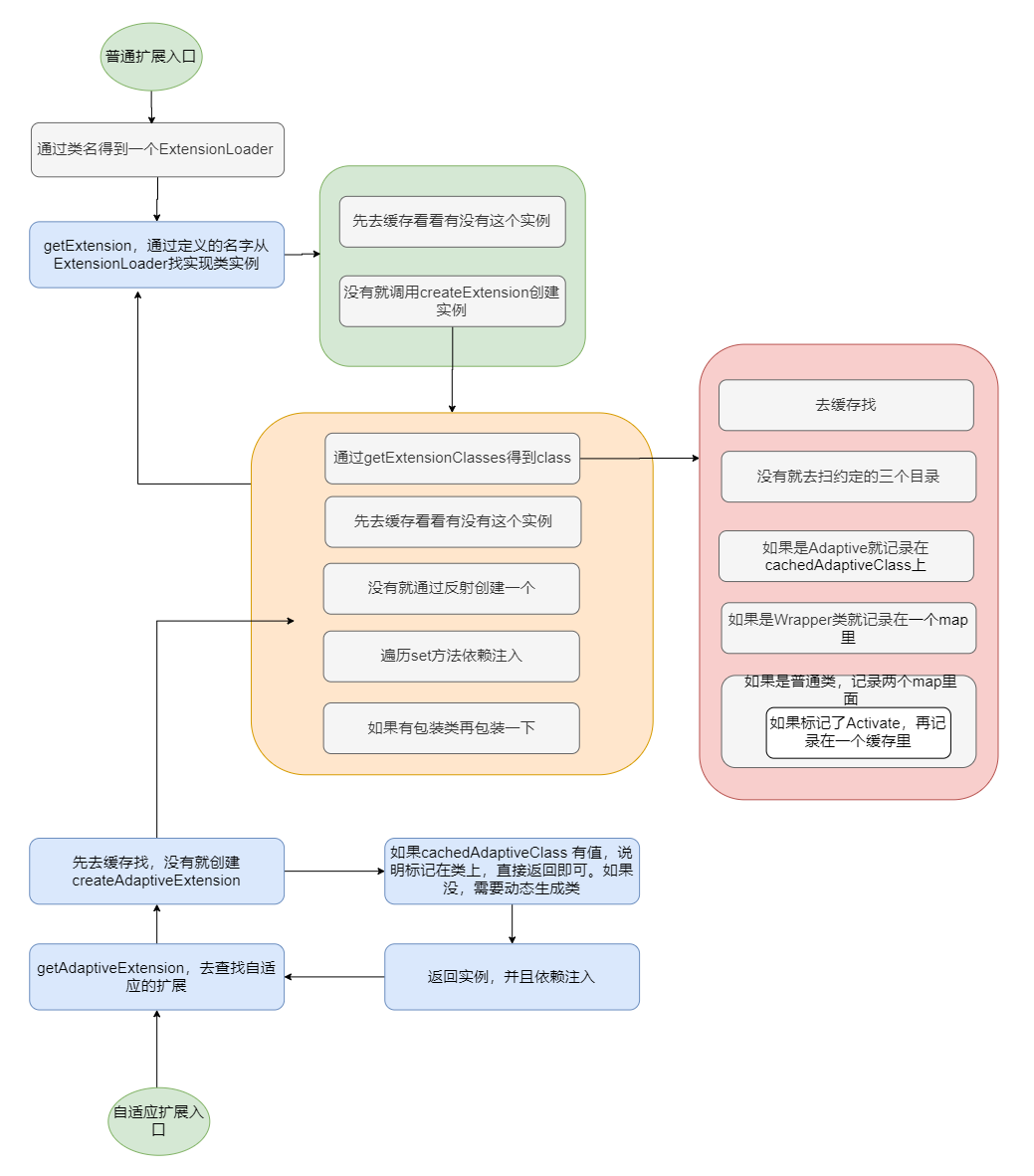
总结
先放个上述过程完整的图。
本文参考:
阿里面试真题:Dubbo的SPI机制
【Dubbo】SPI的更多相关文章
- 【dubbo】服务提供者运行的三种方式
[dubbo]服务提供者运行的三种方式 学习了:https://blog.csdn.net/yxwb1253587469/article/details/78712451 1,使用容器: 2,使用自建 ...
- 【DUBBO】 Dubbo原理解析-Dubbo内核实现之基于SPI思想Dubbo内核实现
转载:http://blog.csdn.net/quhongwei_zhanqiu/article/details/41577235 SPI接口定义 定义了@SPI注解 public @interfa ...
- 【DUBBO】dubbo的LoadBalance接口
LoadBalance负载均衡, 负责从多个 Invokers中选出具体的一个Invoker用于本次调用,调用过程中包含了负载均衡的算法,调用失败后需要重新选择 --->类注解@SPI说明可以基 ...
- 【DUBBO】zookeeper在dubbo中作为注册中心的原理结构
[一]原理图 [二]原理图解释 流程:1.服务提供者启动时向/dubbo/com.foo.BarService/providers目录下写入URL2.服务消费者启动时订阅/dubbo/com.foo. ...
- 【DUBBO】Dubbo:monitor的配置
[一]:配置项 <dubbo:monitor protocol="registry"/> [二]:配置解析器-->具体解析器为com.alibaba.dubbo. ...
- 【DUBBO】Dubbo:protocol 的配置项
[一]:配置项 <dubbo:protocol id="标识" port="端口号" name="名字"/> [二]:配置解析器 ...
- 【DUBBO】dubbo的registry配置
[一]:配置项 注册中心地址:zookeeper://ip:端口 <dubbo:registry address="注册中心的地址" check="启动时检查注册中 ...
- 【DUBBO】dobbo的application的配置项
Dubbo:application的配置项[一]:配置项 <dubbo:application name="服务名字" owner="拥有者" organ ...
- 【DUBBO】Dubbo原理解析-Dubbo内核实现之SPI简单介绍
Dubbo采用微内核+ 插件体系,使得设计优雅,扩展性强.那所谓的微内核+插件体系是如何实现的呢!大家是否熟悉spi(service providerinterface)机制,即我们定义了服务接口标准 ...
随机推荐
- OSPF 综合实验
实验拓扑 实验需求 1.按照图示配置好 IP 地址,PC1 网关指向为 R8 2.OSPF 划分为 4 个区域,其中 192.168.0.0/24,192.168.1.0/24,192.168.2.0 ...
- Qt开发技术:Qt拽拖开发(一)拽托框架详解及Demo
前话 Qt中的拽拖操作详细介绍. Demo 图片拽拖 控件拽拖 窗口拽拖 拽托框架(高级开发) 拖放(Drag and Drop) 拖放提供了一种简单的可视 ...
- 基于MATLAB的手写公式识别(转折)
2021-03-29 21:11:00 很难说自己是不是上当受骗了,老师明明说利用MATLAB进行手写体(记得是手写体,再不济印刷体)的识别是轻而易举的. 平时我也十分喜欢MATLAB这一操作系统,认 ...
- 996. Number of Squareful Arrays
Given an array A of non-negative integers, the array is squareful if for every pair of adjacent elem ...
- 通过中转DLL函数实现DLL劫持
当我们运行程序时,一般情况下会默认加载Ntdll.dll和Kernel32.dll这两个链接库,在进程未被创建之前Ntdll.dll库就被默认加载了,三环下任何对其劫持都是无效的,除了该Dll外,其他 ...
- POJ1328贪心放雷达
题意: 有一个二维坐标,y>0是海,y<=0是陆地,然后只能在y=0的岸边上放雷达,有n个城市需要被监控,问最少放多少个雷达. 思路: 贪心去做就行了,其实题目不 ...
- 如何绕过WAF
目录 HTTP报文包体的解析 Transfer-Encoding Charset 溢量数据 HTTP协议兼容性 HTTP请求行种的空格 HTTP 0.9+Pipelining Websocket.HT ...
- CVE-2012-3569:VMware OVF Tool 格式化字符串漏洞调试分析
0x01 简介 VMware OVF Tool 是一个命令行实用程序,允许您从许多 VMware 产品导入和导出 OVF 包.在 2.1.0 - 2.1.3 之间的版本中存在格式化字符串漏洞,通过修改 ...
- 接口测试原理及Postman详解
接口测试定义 接口是前后端沟通的桥梁,是数据传输的通道,包括外部接口.内部接口.内部接口又包括:上层服务与下层服务接口,同级接口 生活中常见接口:电脑上的键盘.USB接口,电梯按钮,KFC下单 接口测 ...
- 关于HTTP的一些概念
各种概念 HTTP HTTP(HyperText Transfer Protocol) -- 超文本传输协议 它可以拆成三个部分:"超文本"."传输".&quo ...