MySQL中的联表查询与子查询
- 0.准备数据
- 1.内连接:INNER JOIN
- 2.左连接:LEFT JOIN
- 3.右连接:RIGHT JOIN
- 4.USING子句
- 扩展知识点:
- 0.表别名的使用:
- 1.group by的用法
- 2.子查询
- 1)不相关子查询
- 2)相关子查询
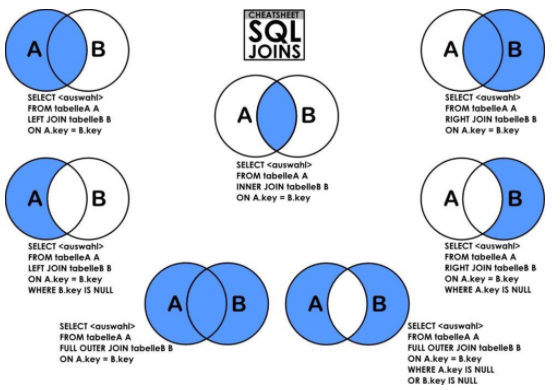
JOIN的含义就如英文单词“join”一样,连接两张表,语法如下所示:
SELECT * FROM A INNER|LEFT|RIGHT JOIN B ON condition
JOIN 按照功能大致分为如下三类:
INNER JOIN(内连接,或等值连接):取得两个表中存在连接匹配关系的记录。
LEFT JOIN(左连接):取得左表(A)完全记录,即是右表(B)并无对应匹配记录。
RIGHT JOIN(右连接):与 LEFT JOIN 相反,取得右表(B)完全记录,即是左表(A)并无匹配对应记录。
注意:mysql不支持Full join,不过可以通过UNION 关键字来合并 LEFT JOIN 与 RIGHT JOIN来模拟FULL join
0.准备数据
|
表
|
表数据
|
命令
|
|---|---|---|
| blog 记录文章名与文章类型 |
|
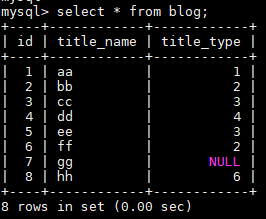
create table blog( id INT primary key auto_increment, title_name varchar(40), title_type int ); insert into blog values(0,'aa',1),(0,'bb',2),(0,'cc',3),(0,'dd',4),(0,'ee',3),(0,'ff',2),(0,'gg',default),(0,'hh',6); |
| blog_type 记录文章类型 |
|
create table blog_type( id INT primary key auto_increment, name varchar(40) ); insert into blog_type values(0,'C'),(0,'PYTHON'),(0,'JAVA'),(0,'HTML'),(0,'C++'); |

1.内连接:INNER JOIN
内连接INNER JOIN/JOIN是最常用的连接操作。从数学的角度讲就是求两个表的交集:
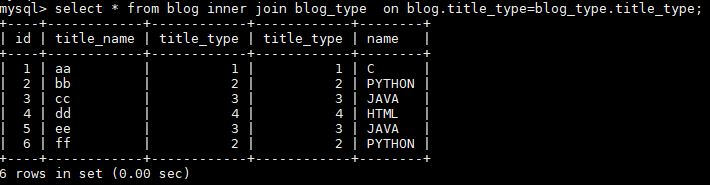
- select * from blog inner join blog_type on blog.title_type=blog_type.id;
- select * from blog join blog_type on blog.title_type=blog_type.id;
- select * from blog,blog_type where blog.title_type=blog_type.id;
输出结果:

2.左连接:LEFT JOIN
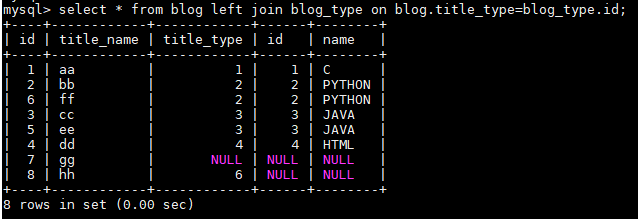
左连接LEFT JOIN的含义就是求两个表的交集外加左表剩下的数据,左连接从左表(A)产生一套完整的记录,与匹配的记录(右表(B)) .如果没有匹配,右侧将包含null。
- select * from blog left join blog_type on blog.title_type=blog_type.id;
如果想只从左表(A)中产生一套记录,但不包含右表(B)的记录,可以通过设置where语句来执行,如下:
- select * from blog left join blog_type on blog.title_type=blog_type.id where blog_type.id is null;

3.右连接:RIGHT JOIN
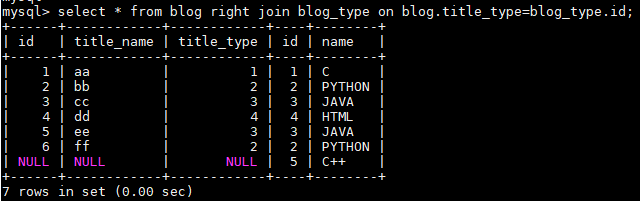
同理右连接RIGHT JOIN就是求两个表的交集外加右表剩下的数据。
select * from blog right join blog_type on blog.title_type=blog_type.id;
4.USING子句
MySQL中连接SQL语句中,ON子句的语法格式为:table1.column_name = table2.column_name。当模式设计对联接表的列采用了相同的命名样式时,就可以使用 USING 语法来简化 ON 语法,格式为:USING(column_name)。 所以,USING的功能相当于ON,区别在于USING指定一个属性名用于连接两个表,而ON指定一个条件。另外,SELECT *时,USING会去除USING指定的列,而ON不会。实例如下。
create table blog_type_1 as select * from blog_type;
alter table blog_type drop id;
alter table blog_type add title_type int not null primary key auto_increment first;
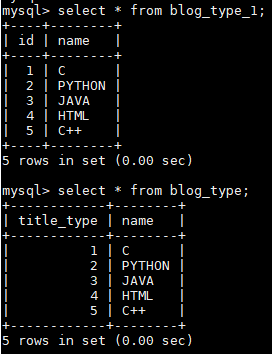
|
mysql
|
结果
|
|---|---|
|
select * from blog inner join blog_type on blog.title_type=blog_type.title_type; |
|
|
select * from blog join blog_type using(title_type); USING会去除USING指定的列 |
|

join中改善性能的一些注意点:来自https://www.cnblogs.com/fudashi/p/7506877.html
- 小表驱动大表能够减少内循环的次数从而提高连接效率。
- 在被驱动表建立索引能够提高连接效率
- 优先选择驱动表的属性进行排序能够提高连接效率
扩展知识点:
0.表别名的使用:
对单表做简单的别名查询通常是无意义的。一般是对一个表要当作多个表来操作,或者是对多个表进行操作时,才设置表别名。
1.group by的用法
2.子查询
嵌套在其它查询中的查询称之为子查询或内部查询,包含子查询的查询称之为主查询或外部查询
1)不相关子查询
内部查询的执行独立于外部查询,内部查询仅执行一次,执行完毕后将结果作为外部查询的条件使用
一般在子查询中,程序先运行在嵌套在最内层的语句,再运行外层。因此在写子查询语句时,可以先测试下内层的子查询语句是否输出了想要的内容,再一层层往外测试,增加子查询正确率。否则多层的嵌套使语句可读性很低。
举栗:想要从数据库中获取文章类型是Python的文章列表
|
A
|
B
|
|---|---|
|
select title_name from blog where title_type= (select id from blog_type_1 where name='PYTHON');
|
select title_name from blog A join blog_type_1 B on A.title_type=B.id where B.name='PYTHON';
|
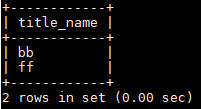
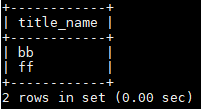
分步执行:
获取id: select id from blog_type_1 where name='PYTHON';---->id=2
获取文章列表:select title_name from blog where title_type=2;-→title name=(bb,ff)
联合查询:
子查询的方式:select title_name from blog where title_type=(select id from blog_type_1 where name='PYTHON');
联表查询的方式:select title_name from blog A join blog_type_1 B on A.title_type=B.id where B.name='PYTHON';
2)相关子查询
内部查询的执行依赖于外部查询的数据,外部查询每执行一次,内部查询也会执行一次。每一次都是外部查询先执行,取出外部查询表中的一个元组,将当前元组中的数据传递给内部查询,然后执行内部查询。
根据内部查询执行的结果,判断当前元组是否满足外部查询中的where条件,若满足则当前元组是符合要求的记录,否则不符合要求。然后,外部查询继续取出下一个元组数据,执行上述的操作,直到全部元组均被处理完毕。
举栗:从历史最好记录的表中获取各个指标最新时间的值
表数据:
蓝色框框中的fr指标数据是重复的,预期想要获取各个指标最新时间的指标值
|
相关子查询
|
联表查询
|
|---|---|
| select * from test_best_history_for_storm_largescale t where date =(select max(date) from test_best_history_for_storm_largescale where fr=t.fr and area="largescale_fuji") and area="largescale_fuji"; | select * from test_best_history_for_storm_largescale A join (select max(date) date,fr from test_best_history_for_storm_largescale where area='largescale_fuji' group by fr)B on A.date=B.date and A.fr=B.fr and A.area='largescale_fuji'; |
|
|
p.p1 { margin: 0; font: 16px Menlo; color: rgba(0, 0, 0, 1) }
span.s1 { font-variant-ligatures: no-common-ligatures }
MySQL中的联表查询与子查询的更多相关文章
- MySQL学习笔记——多表连接和子查询
多表连接查询 # 返回的是两张表的乘积 SELECT * FROM tb_emp,tb_dept SELECT COUNT(*) FROM tb_emp,tb_dept # 标准写法,每个数据库都能这 ...
- MySQL中的DML、DQL和子查询
一.MySQL中的DML语句 1.使用insert插入数据记录: INSERT INTO `myschool`.`student` (`studentNo`, `loginPwd`, `student ...
- MySQL多表查询之外键、表连接、子查询、索引
MySQL多表查询之外键.表连接.子查询.索引 一.外键: 1.什么是外键 2.外键语法 3.外键的条件 4.添加外键 5.删除外键 1.什么是外键: 主键:是唯一标识一条记录,不能有重复的,不允许为 ...
- MySQL开发——【联合查询、多表连接、子查询】
联合查询 所谓的联合查询就是将满足条件的结果进行拼接在同一张表中. 基本语法: select */字段 from 数据表1 union [all | distinct] select */字段 fro ...
- MySQL之多表查询一 介绍 二 多表连接查询 三 符合条件连接查询 四 子查询 五 综合练习
MySQL之多表查询 阅读目录 一 介绍 二 多表连接查询 三 符合条件连接查询 四 子查询 五 综合练习 一 介绍 本节主题 多表连接查询 复合条件连接查询 子查询 首先说一下,我们写项目一般都会建 ...
- mysql数据库之联表查询
表准备: 这次我们用到5张表: class表: student表: score表: course表: teacher表: 表结构模型: 我们针对以下需求分析联表查询: 1.查询所有的课程的名称以及对应 ...
- php mysql 多表查询之子查询语句
所谓子查询语句,就是先通过一个语句来查询出一个结果,然后再通过一个查询语句从这个结果中再次查询.子查询语句一般有以下3种.下面以一个案例来做讲解. 案例:查询[例1]中每个分类下的最新的那一条商品信息 ...
- MYSQL - 外键、约束、多表查询、子查询、视图、事务
MYSQL - 外键.约束.多表查询.子查询.视图.事务 关系 创建成绩表scores,结构如下 id 学生 科目 成绩 思考:学生列应该存什么信息呢? 答:学生列的数据不是在这里新建的,而应该从学生 ...
- mysql多表连接和子查询
文章实例的数据表,来自上一篇博客<mysql简单查询>:http://blog.csdn.net/zuiwuyuan/article/details/39349611 MYSQL的多表连接 ...
随机推荐
- 源码安装nginx env
源码安装nginx 1. For ubuntu:18.04 apt -y install build-essential libtool libpcre3 libpcre3-dev zlib1g-de ...
- Java中单列集合List排序的真实应用场景
一.需求描述 最近产品应客户要求提出了一个新的需求,有一个列表查询需要按照其中的多列进行排序. 二.需求分析 由于数据总量不多,可以全部查询出来,因此我就考虑使用集合工具类Collections.so ...
- [论文阅读笔记] Are Meta-Paths Necessary, Revisiting Heterogeneous Graph Embeddings
[论文阅读笔记] Are Meta-Paths Necessary? Revisiting Heterogeneous Graph Embeddings 本文结构 解决问题 主要贡献 算法原理 参考文 ...
- object_pool对象池
object_pool对象池 object_pool是用于类实例(对象)的内存池,它能够在析构时调用所有已经分配的内存块调用析构函数,从而正确释放资源,需要包含以下头文件: #include < ...
- 使用 Flux+Flagger+Istio+Kubernetes 实战 GitOps 云原生渐进式(金丝雀)交付
在这篇指南中,你将获得使用 Kubernetes 和 Istio 使用 GitOps 进行渐进式交付(Progressive Delivery)的实际经验. 介绍 gitops-istio GitOp ...
- 解决Maven资源过滤问题
向pom文件添加如下配置 <build> <resources> <resource> <directory>src/main/java</dir ...
- 书列荐书 |《黑天鹅·如何应对不可预知的未来》【美】纳西姆 尼古拉斯 塔勒布 著
你不知道的事比你知道的事更有意义,因为生活中发生了许多微小的事情,尽管出现的概率非常小,但是却以某一种巨大的力量影响我们的生活.但是由于思维习惯的问题,导致我们看问题的方式使得我们不能很快地把握事物的 ...
- sql server 操作(不定期更新)
要求:基本的语法要清楚. sql server疑难点: 1.Partition by可以理解为 对多行数据分组后排序取每个产品的第一行数据 先处理内查询,由内向外处理,外层查询利用内层查询的结果嵌套查 ...
- 基于TensorRT车辆实时推理优化
基于TensorRT车辆实时推理优化 Optimizing NVIDIA TensorRT Conversion for Real-time Inference on Autonomous Vehic ...
- Spring Cloud系列(二):服务提供者
上一篇介绍了注册中心,这一篇介绍如何把服务注册到注册中心. 一.创建服务提供者 我们依然使用上一篇的项目,在其中创建一个spring boot模块,填好必要的信息,依赖需要选择Spring Web和E ...