ELK集群之kibana(4)
kibane安装及基础使用


- Kibana的安装
- Kibana包含前端展示、es操作简化
- yum localinstall kibana-7.6.2-x86_64.rpm -y
- Kibana配置修改kibana.yml,连接es的用户名密码需要正确
- server.port: 5601
- server.host: "0.0.0.0"
- elasticsearch.hosts: ["http://xxx:9200", "http://xxx:9200"]
- elasticsearch.username: "elastic"
- elasticsearch.password: "sjgpwd"
- logging.dest: /tmp/kibana.log
- Kibana的启动和访问
- systemctl enable kibana
- systemctl restart kibana
- 检查端口、访问kibana、登录尝试
- kibana端口5601 密码默认使用es
kibana安装
k8s中安装kibana:
- ---
- apiVersion: v1
- kind: Service
- metadata:
- name: kibana
- namespace: kube-system
- labels:
- component: kibana
- spec:
- selector:
- component: kibana
- ports:
- - name: http
- port: 80
- targetPort: http
- ---
- #ingress
- apiVersion: extensions/v1beta1
- kind: Ingress
- metadata:
- name: kibana
- namespace: kube-system
- spec:
- rules:
- - host: kibana.mooc.com
- http:
- paths:
- - path: /
- backend:
- serviceName: kibana
- servicePort: 80
- ---
- apiVersion: apps/v1beta1
- kind: Deployment
- metadata:
- name: kibana
- namespace: kube-system
- labels:
- component: kibana
- spec:
- replicas: 1
- selector:
- matchLabels:
- component: kibana
- template:
- metadata:
- labels:
- component: kibana
- spec:
- containers:
- - name: kibana
- image: registry.cn-hangzhou.aliyuncs.com/imooc/kibana:5.5.1
- env:
- - name: CLUSTER_NAME
- value: docker-cluster
- - name: ELASTICSEARCH_URL
- value: http://elasticsearch-api:9200/
- resources:
- limits:
- cpu: 1000m
- requests:
- cpu: 100m
- ports:
- - containerPort: 5601
- name: http
kibana.yaml
kibana提供了简化es功能可以调用开发者工具执行简化命令
- Kibana简化ES的操作
- 验证集群是否成功
- curl -u elastic:sjgpwd http://xxx:9200 -> GET /
- curl -u elastic:sjgpwd http://xxx:9200/_cat/nodes?v -> GET /_cat/nodes?v
- curl -u elastic:sjgpwd http://xxx:9200/_cat/indices?v -> GET /_cat/indices?v
- 由于地址、用户名、密码已经配置在Kibana,所以可以直接简化访问
- Kibana提示功能
- GET /_cat
- GET /_cat/nodes?v
- 插入数据-X PUT
- PUT /sjg/_doc/1
- {
- "name":"sjg",
- "age": 30
- }
- ES查询数据
- GET /sjg/_doc/1
- GET /sjg/_search?q=*
- 写入随机id
- POST /sjg/_doc
- {
- "name":"sjg",
- "age": 20
- }
- ES修改数据
- POST /sjg/_update/1
- {
- "doc": {
- "age": 28
- }
- }
- 修改所有的数据
- POST /sjg/_update_by_query
- {
- "script": {
- "source": "ctx._source['age']=28"
- },
- "query": {
- "match_all": {}
- }
- }
- 增加字段
- POST /sjg/_update_by_query
- {
- "script":{
- "source": "ctx._source['city']='hangzhou'"
- },
- "query":{
- "match_all": {}
- }
- }
- ES删除数据
- DELETE /sjg/_doc/1
- DELETE /sjg
- DELETE /sjg*
简化命令示例
示例图:
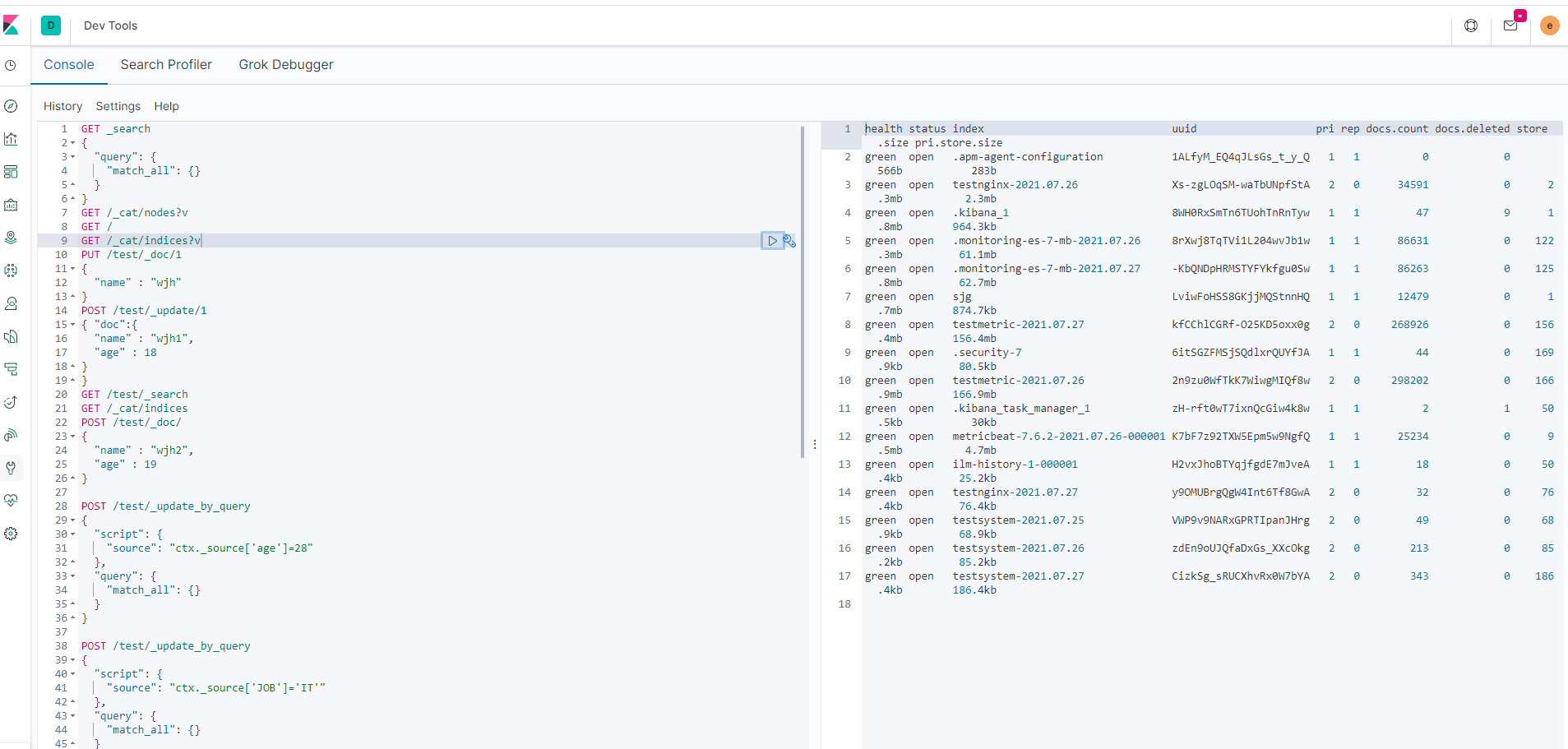
kibana设置es类型索引分片及副本数量
- 索引的分片数及副本数设置
- 索引的分片数及副本数设置:两台es,最多一个副本
- 分片确认
- 获取分片信息 GET /sjg/_search_shards
- 根据id查询在哪个分片 GET /sjg/_search_shards?routing=yBRjn3MB4u0rZ3IOTB8p
- 索引创建后分片不可修改,副本数量可修改
- PUT /sjg/_settings
- {
- "number_of_shards" : 4,
- "number_of_replicas": 1
- }
- 索引模板
- 如果要每个索引都要单独设置分片数、分片副本数,操作会比较麻烦
- 索引模板可以针对一批索引设置分片、副本,例如可针对sjg*设置
- 内置索引模板:GET _template
- 简单索引模板创建
- PUT _template/sjgtemplate
- {
- "index_patterns": ["sjg*"],
- "settings":{
- "number_of_shards": 2,
- "number_of_replicas": 0
- }
- }
- 检查索引模板是否生效
- POST /sjg1/_doc
- {
- "name":"sjg2",
- "age": 30
- }
- POST /sjg2/_doc
- {
- "name":"sjg2",
- "age": 30
- }
设置分片
kibana开发者工具模拟logstash正则测试:
示例图:
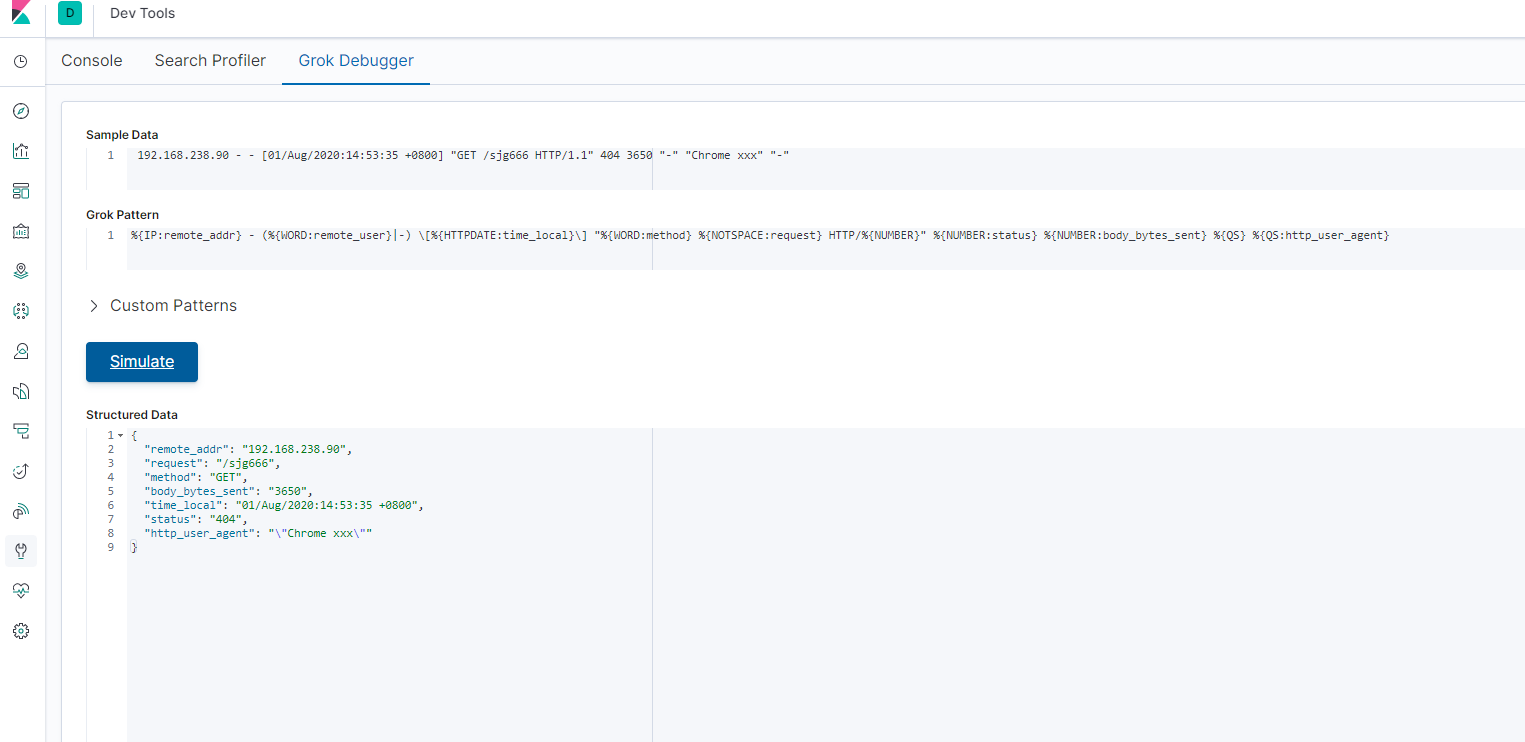
python操作es
- #!/usr/bin/env python
- # -*- coding: utf-8 -*-
- import time
- import datetime
- from elasticsearch import Elasticsearch
- es = Elasticsearch(['http://elastic:1.Q1.Q1.Q@123.57.130.84:9200','http://elastic:1.Q1.Q1.Q@123.56.99.47:9200','http://elastic:1.Q1.Q1.Q@123.57.93.4:9200'])
- # for i in range(10000):
- # body = {"name": "test{0}".format(i), "count": i}
- # es.index(index='test', body=body)
- # time.sleep(0.5)
- # print('insert {0}'.format(i))
- # body = {"name": "sjgpython", "age": 29}
- # es.index(index='sjg', body=body)
- # print('Insert Success')
- # print(es.search(index='sjg'))
- # print(es.indices.delete(index='sjg'))
- for i in range(10000):
- curtime=datetime.datetime.utcnow().isoformat()
- body = {"name": "sjg{0}".format(i), "@timestamp": curtime, "sjgcount": i}
- es.index(index='sjg', body=body)
- time.sleep(1)
- print('insert {0}'.format(i))
es.py
Kibana的 原理和使用:
Kibana 在整个 Elastic Stack 家族中起到数据可视化的作用,也就是通过图、 表、统计等方式将复杂的数据以更直观的形式展示出来。由于 Kibana 运行于 Elasticsearch 基础之上,所以可以将 Kibana 视为 Elasticsearch 的用户图形界面 ( Graphic User Interface, GUI) 。 因为 Kibana 中可视化对象很多,我们挑选几个典型的进行讲解。
文档发现 ( Discover)
本章主要介绍 Kibana 导航栏中的第一个功能文档发现 ( Discover) ,它提供了 交互式检索文档的接口,用户可以在这里提交查询条件、设置过滤器并查看检索 结果。在文档发现中的查询条件还可以保存起来,这些保存起来的查询条件称为 查询对象,可以在文档可视化和仪表盘功能中使用。
索引模式
在使用文档发现功能检索文档之前,首先要告诉 Kibana 要检索 Elastiesearch 的哪些索引,这在 Kibana 中是通过定义 索引模式 来实现的。没有被索引模式包 含进来的索引不能在文档发现、文档可视化和仪表盘等功能中使用,如何创建索 引模式?
创建索引模式
索引模式是一种对 Elasticsearch 中索引的模式匹配,以定义哪些索引将被包含到这个模式中。它以索引名称为基础,可以匹配单个索引也可以使用星号“* ” 匹配多个索引。例如在导入飞行记录样例数据时,Kibana 会创建一个名为 kibana_sample_data_flights 的索引模式。索引模式的管理功能位于 Management 菜单中。
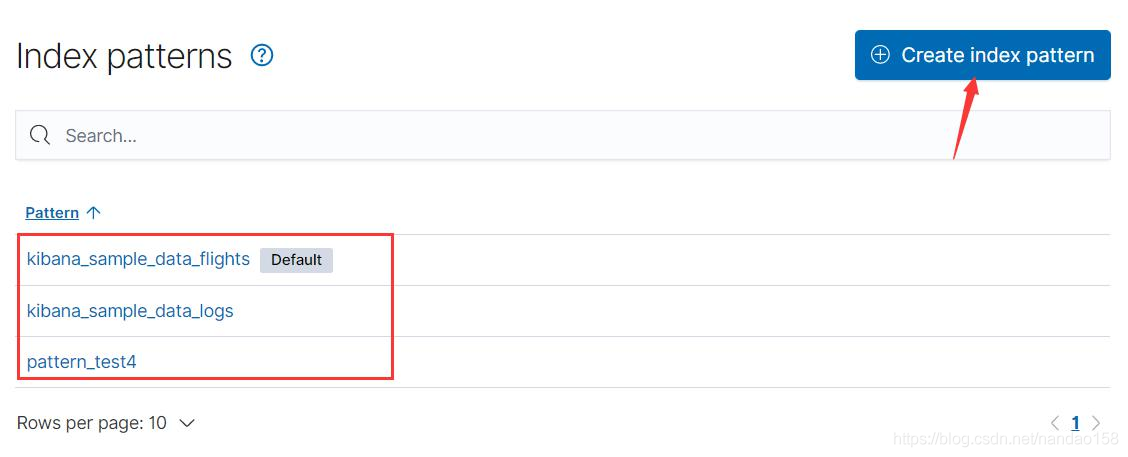
配索引名称的模式。模式可以直接使用索引名称,也可以使用星号“ * ”匹配 任意字符。在输入模式的同时,Kibana 会在输入框下动态地将匹配索引模式的 所有索引列出来,用户可以实时查看索引模式是否满足要求。单击 Next Step 按 钮进入下一步。
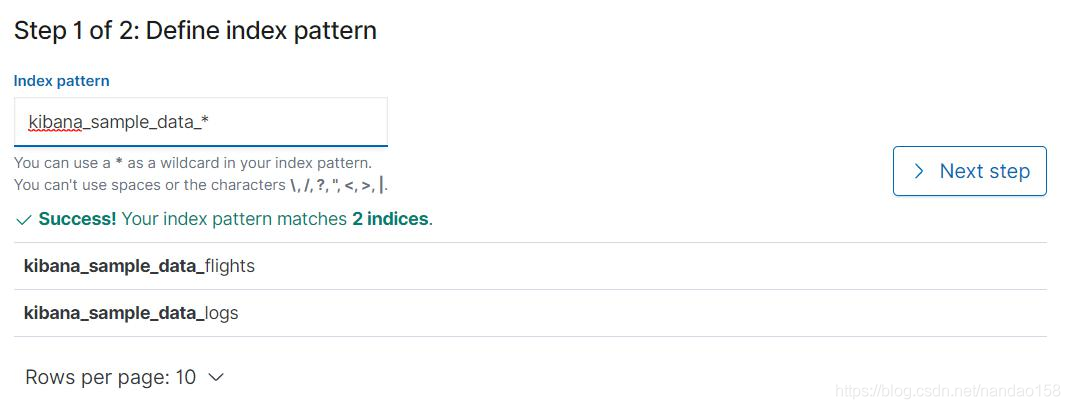
创建索引模式第二步是设置索引模式的一些配置信息, 这包括添加时间过 滤器和为索引模式指定 ID 。如果模式匹配的索引中包含有时间类型的字段,在 这一页将会包含一个设置时间过滤器的选项,用户可以选择使用哪一个字段作为 过滤条件; 否则页面将提示不包含时间类型的字段而不会有时间过滤器选项。 在时间过滤器下,还有一个链接“Show advanced options" , 单击这个链接 会打开设置索引模式 ID 的输入框。默认情况下, Kibana 会给索引模式自动生成 一个 ID 。如果想自己定义索引模式 ID, 可以在这个输入框中输入 ID 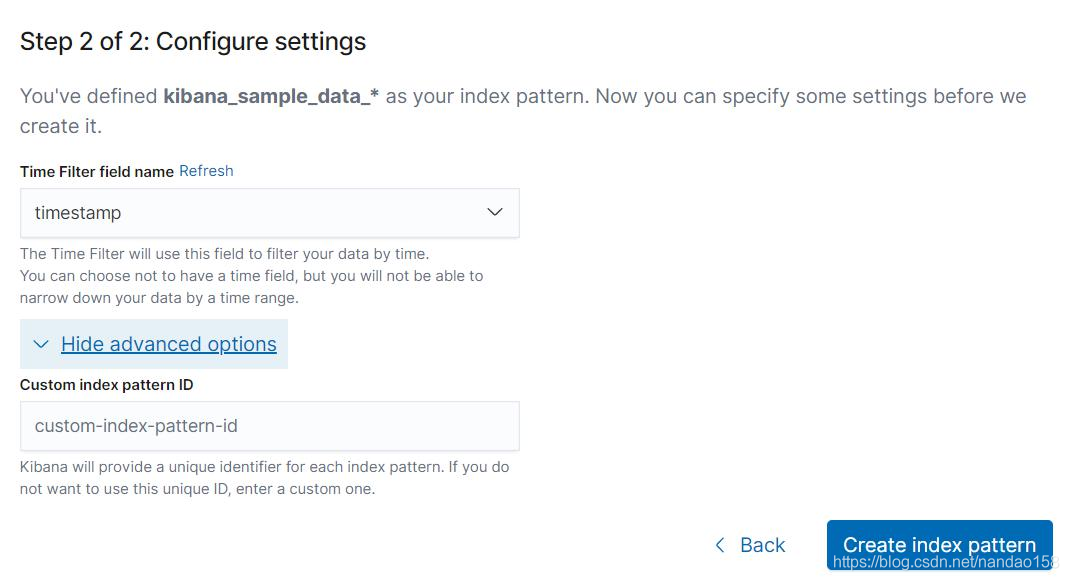
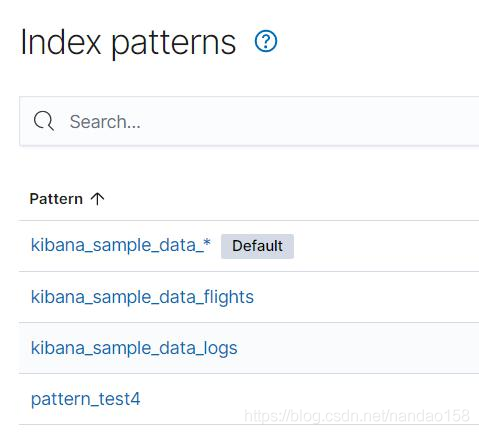
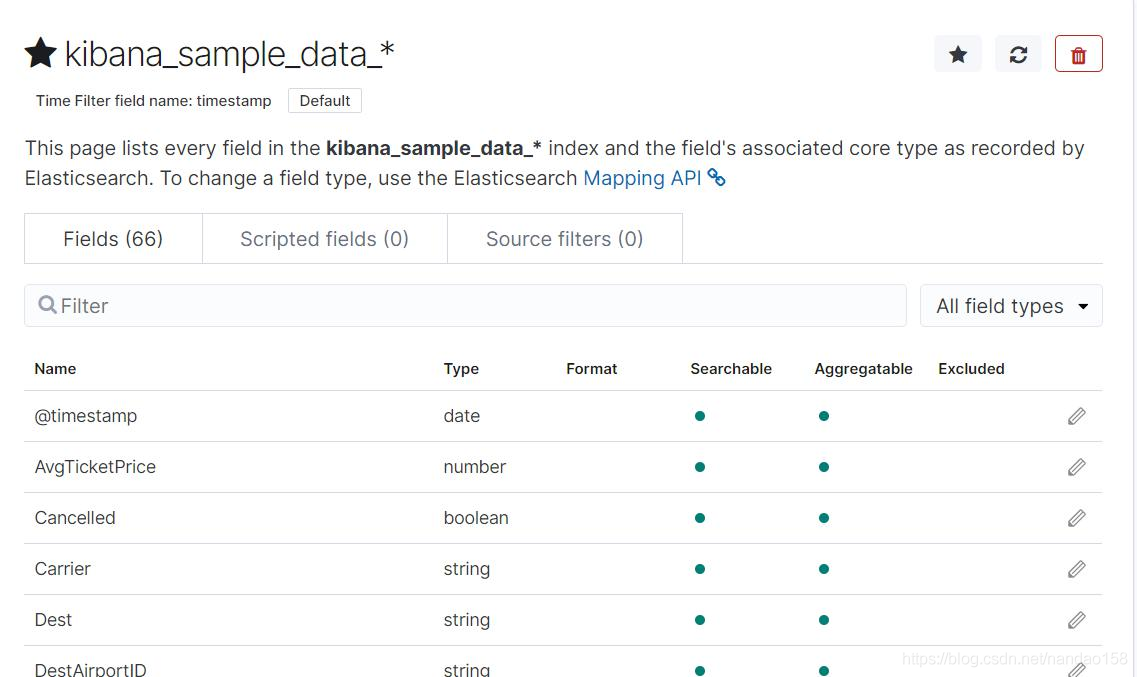
除了字段以外,在管理字段的界面中还包括脚本字段 (Scripted fields) 、 源过 滤器(Source filters) 两个标签页。脚本字段是通过脚本在运行时动态添加到索引模 式中的字段,而源过滤器则用于从源文档中过滤字段。 脚本字段并不是真实地存在于索引中,而是根据其他字段值运算而来。给索 引模式添加脚本字段需要在索引模式创建后,在管理索引模式的界面中在 “Scripted Field" 标签页中处理。例如, Kibana 提供的样例索引模式 kibana_sample_data_flights 中就包含一个脚本字段。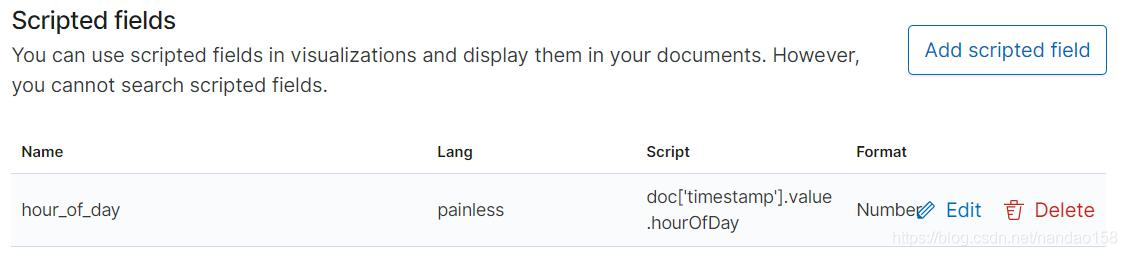
源过滤器用于从源文档中过滤字段,被过滤的字段将不会在文档发现和仪表 盘中展示。源过滤器在定义时可以使用字段名称精确匹配字段,也可以使用星号 匹配多个字段。 在索引模式管理界面的右上角有 三个按钮,它们的作用分别是设 置默认索引模式、刷新字段列表和删除索引模式。当设置索引模式为默认时,它 将在文档发现中成为默认索引模式。
发现文档
文档发现就是要将满足条件的文档检索出来, Kibana 提供了多种方式设置 查询条件。 这包括通过时间范围过滤文档、使用过滤器过滤文档,还可以通过 Lucene 或 KQL 查询语言过滤文档。无论使用哪一种方式过滤文档,它们最终都会以 DSL 查询语言的形式传递给底层的 Elasticsearch 。先来看看时间范围和过滤器这两种 方式,它们最终会以 must 子句的形式组合进 bool 查询。
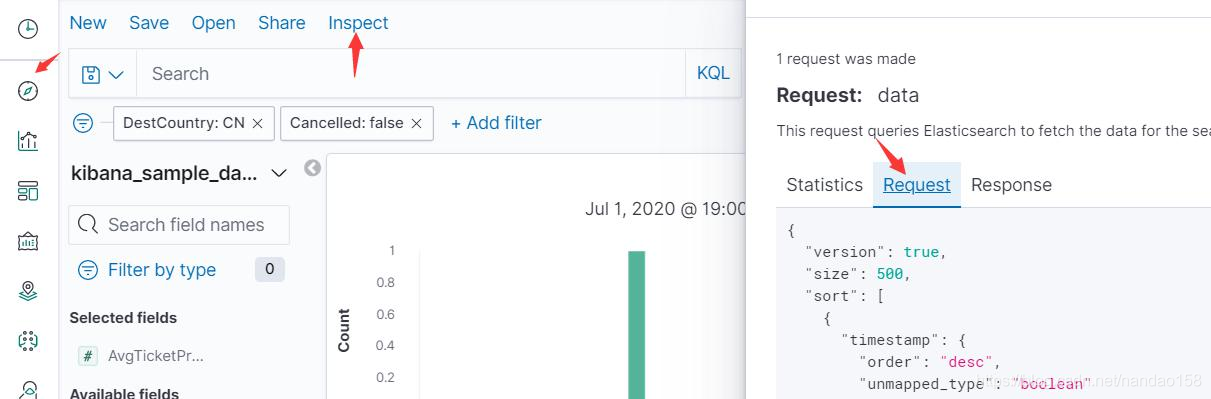
如果想要查看 Kibana 最终生成的请求,可单击工具栏中的 Inspect 按钮,在 弹出窗口中选择 Request 标签页查看。
数据发现界面结构
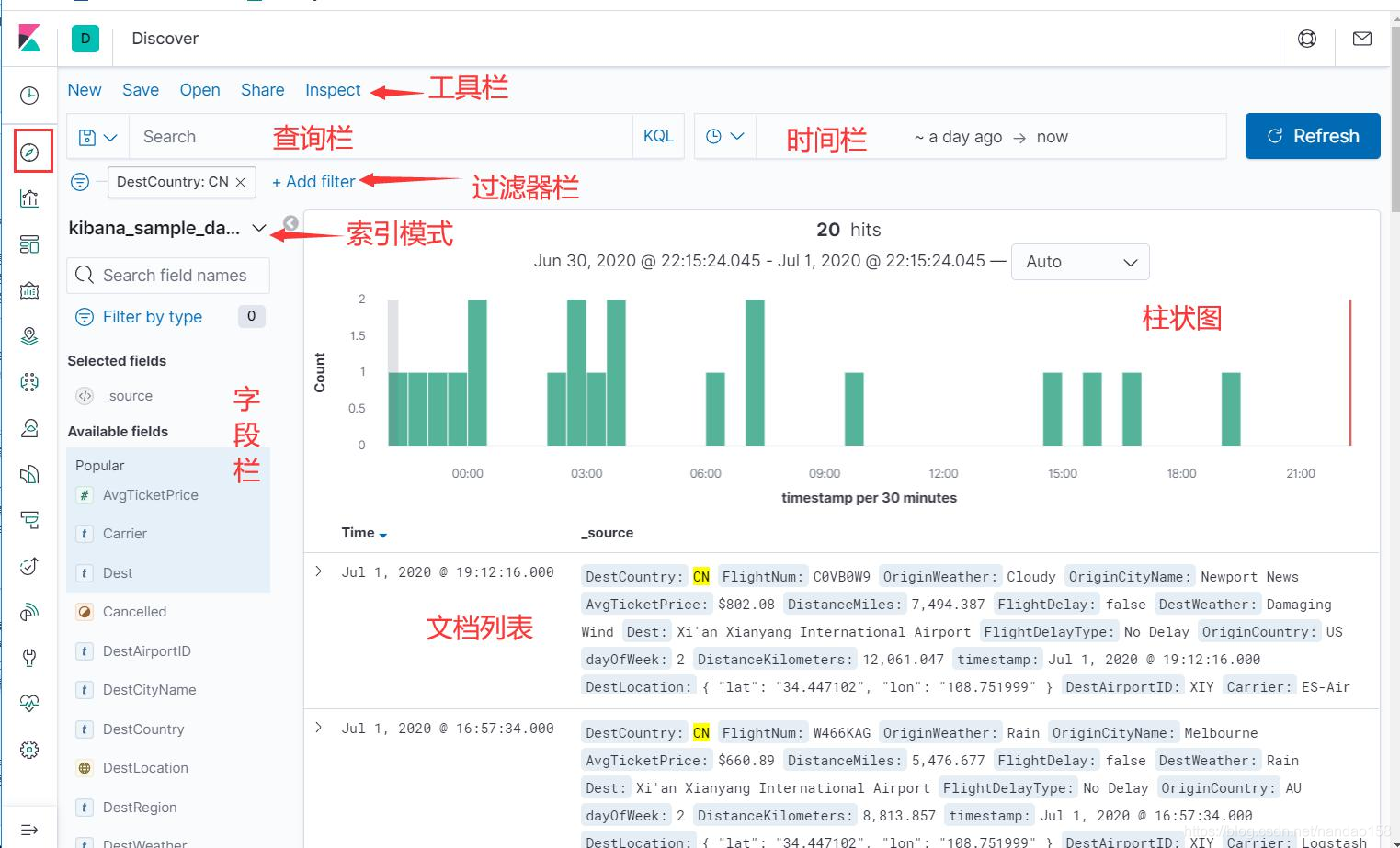
首先,在数据发现界面最上面靠左侧有一排包含了特定功能的按钮,如 New 、 Save、 Open 等,本书后续章节将这一栏称为工具栏, 它们用于实现对文档发现 的创建、保存等基础管理功能。 接下来,在工具栏下面有一个输入框可键入查询条件检索文档,我们把这个 这个输入栏称为为查询栏。查询栏接收 Elasticsearch 查询语言 DSL, 或者 Kibana 内置查询语言 KQL 。 在查询栏下侧称为过滤器栏,在没有定义过滤器时该栏只有一个 Add a filter 链接,而添加了过滤器后会有相应的过滤器定义展示出来。
在查询栏右侧是时间栏,这一栏的作用可以设置检索文档的时间范围,还可 以设置检索文档的刷新频率。所以查询栏、过滤器栏和时间栏的主要作用都是精 确地限定检索文档的范围。 再往下可以分为左右两栏,左侧分别列出了索引模式、已选择字段和可选择 字段; 而右侧上部显示了满足过滤条件文档的柱状图,下部则将相应的文档数据 展示出来了。在了解了文档发现界面的基本结构后就可以在其中浏览文档了,但 有时会发现文档不存在,这时就需要更新文档的时间范围和刷新频率了。
使用时间过滤文档
在前面曾介绍过,如果索引包含时间类型的字段,则在创建索引模式的第二 步中可以为索引模式添加时间过滤器。 如果在创建索引模式时添加了时间过滤器,那么在文档发现中就会看到设置 时间过滤器的按钮。通常这个过滤器的默认值为"Last 15minutes",位于文档发现 界面的时间栏上。 时间栏上有一个日历图形的按钮,单击它会弹出选择时间范围的界面。时间 范围可以设置为一个相对时间范围,例如最近 24 小时、前两周、前两个月等 ; 也可以是一个绝对时间范围,例如从 2019-4-1 至 2019-5-10 ,如图所示。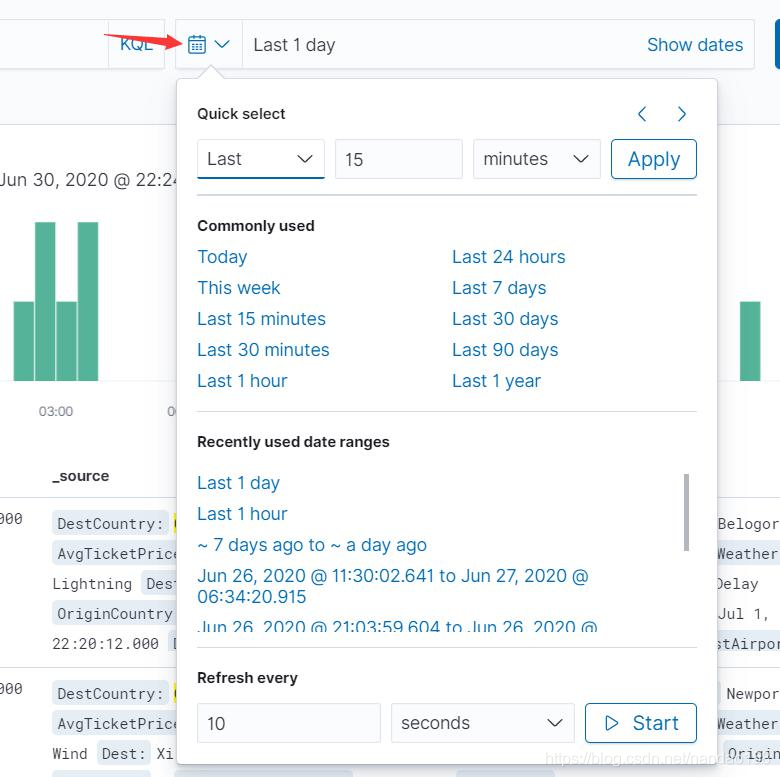
在图中,弹出时间范围窗口的最下面还有一个可以设置刷新频率的输入框。 在这个输 入 框中可以按秒、分、小时为单位,输 入 页面刷新的时间间隔。设置好 后单击后面的 Start 按钮,页面就会按设置好的时间间隔自动刷新数据。
自定义过滤器
通过时间范围过滤文档只能通过在创建索引模式时指定的时间字段过滤文 档,如果想通过其他字段对文档做过滤就必须要借助过滤器了。为文档发现添加 过滤器可通过过滤器栏的 Add filter 按钮完成,单击这个按钮会弹出 EIDT FILTER 对话框,如图所示。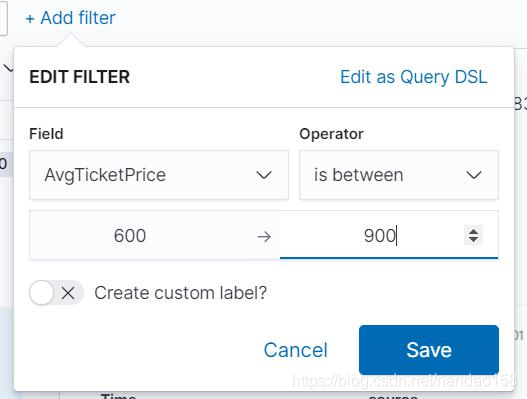
在 EDIT FILTER 对话框中,可通过 Field 下拉列表选择字段,然后通过 Operator 和 Value 下拉列表选择操作符和具体值。例如设置一个根据平均票价介于“600 ”到 “900 ” 之间的条件过滤航班文档,首先要在 Field 下拉列表中选择 AvgTicketPrice 字段,然后在 Operator 下拉列表中选择“ is between", 最后在弹 出的 From 和 To 输入框中输入“ 600 ”和“ 900 ”,单击 Save 按钮就完成了过
滤器的设置。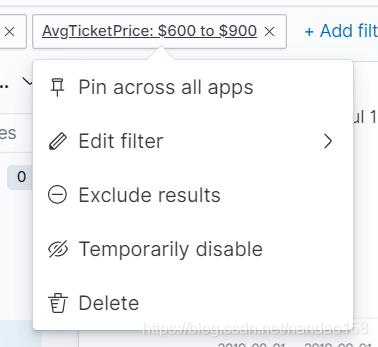
使用查询语言
时间范围和过滤器设置的查询条件都是以逻辑与的形式组合在一起的, 如 果需要设置更复杂的查询条件就需要在查询栏中输人查询条件以检索文档。目前 Kibana 文档发现中支持 L ucene 和 KQL ( Kibana Query Language) 两种查询语 言,前者可以认为就是 Elasticsearch 中的 DSL, 而后者则是 Kibana 提供的一种 新查询语言。 要切换查询语言,只需
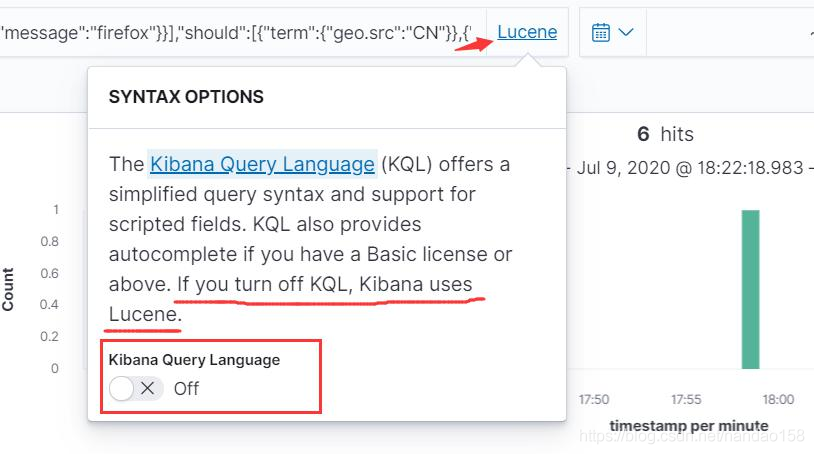
要查询,在输入栏中输入查询语言即可,比如: {"bool": {"must":[{"match": { "message": "firefox"} }],"should":[{"term": { "geo.src": "CN"}},{"term": { "geo.dest": "CN"}}]}}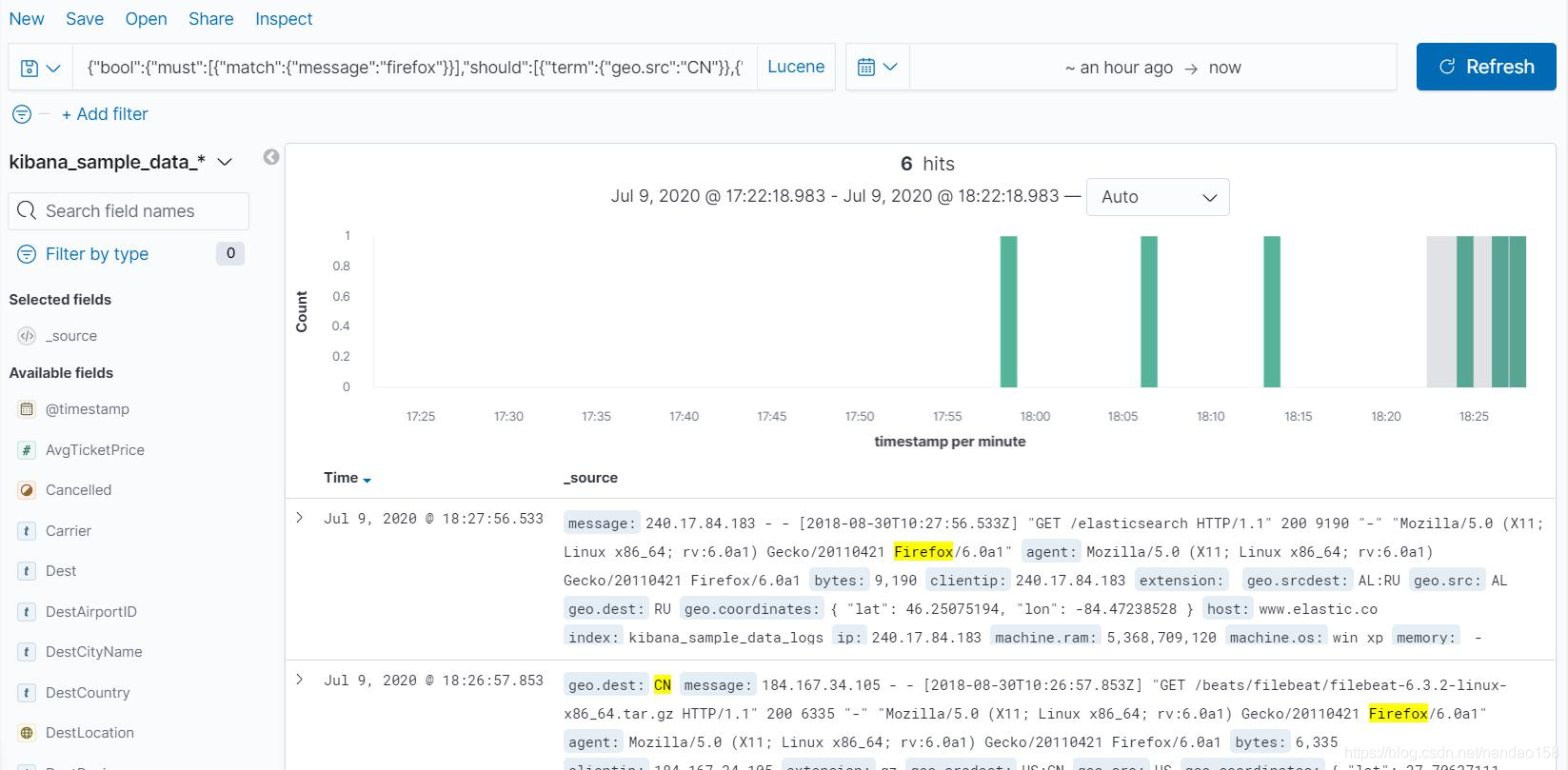
tips :
还记得这个查询条件的含义吗? 只有 message 字段包含 firefox 词项的日志文档才会被返回,而 geo 的 src 字 段和 dest 字段是否为 CN 只影响相关度,当然相关度越高的肯定排在前面。
文档展示与字段过滤
通过时间范围、过滤器和查询语言发现的文档最终会以柱状图和表格两种形 式展示
柱状图
文档发现会根据保存的查询条件刷新页面。根据查询条件生成的柱状图会以 时间为 X 轴,而以文档数量为 Y 轴。当鼠标指针悬停于单个柱子上时,还会弹 出当前柱子代表数据的具体说明,包括时间范围、文档数量等。在默认情况下, 柱状图中各个柱子之间的时间间隔会根据时间范围自动匹配。在柱状图栏右上侧 也提供了一个下拉列表修改时间间隔,如图所示。
柱状图还有另外一个功能,它可以通过鼠标划选的方式选择文档发现的时间 范围,这对于通过柱状图精细查看某一时间段数据来说非常方便。当鼠标指针悬 停于柱状图上时,指针会变为十字星状。按下鼠标左键选择一个范围做拖拽,会 弹出提示框,并显示满足条件的文档数量和时间范围。选择到合适的时间范围后 放开鼠标,Kibana 会根据划定的范围自动将时间范围设置好。
文档展示
默认情况下文档栏只包含两列,一列是 Time, 另一列是 _source 。 Time 列 仅在索引模式设置了时间过滤器时才会有,它会展示时间过滤器中指定的时间字 段值。_ source 列则显示源文档,也就是在使用 DSL 查询时返回的 _source 字段 值。文档栏展示哪些列可通过左侧的字段栏来定制,字段栏分为“Selected fields" 和“Available fields" 两个区域。 “ Selectedfelds" 区域列出了将在文展示栏展示的所有字段,默认情况下 只有一个_ source 字段 ; 而“ Available fields" 区域则列出了文档所有可以展示的 字段。“ Available fields" 区域列出的字段受到索引模式的源文档过滤器影响。 当鼠标指针悬停在“Available fields" 列表中的字段上时,字段后面将会出 现"add" 按钮。单击这个按钮,字段就会被添加到“ Selected fields" 列表中,同 时文档展示栏中展示的字段也会随变化。一旦明确指定了需要展示的字段, source 字段就不会再出现在文档展示栏中。反过来,当鼠标指针悬停在 “Selected fields" 字段上时,字段后面将会出现 remove 按钮。单击这个按钮, 字段将从“Selected fields" 列表中删除并出现在“ Available fields" 列表中,而 文档展示栏中也不会再展示这个字段的内容。
添加过滤器
除了可以通过 add 和 remove 按钮设置展示字段外,单击任何一个字段都会 列出字段中出现的热门词项。这些词项是根据它们词频的排名,取前五位而形成 的词项列表。例如单击 DestCountry 字段会列出五个词项 IT 、 US 、 CA 、 CN 和 JP,在每个词项下面还有它们出现的百分比,这代表了航班的五大热门目的地 国家。如图所示。
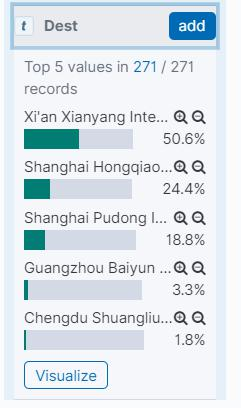
热门词项后面有一对类似于放大和缩小的图标,它们用于根据词项过滤文档。 本书将称类似放大图标的按钮为包含按钮,而称类似缩小图标的按钮为排除按钮。 这两个按钮在数据发现界面上的其他地方也会出现,作用是包含或排除词项值。 具体来说,单击包含按钮会将当前字段包含该词项的文档过滤出来,而点击排除 按钮则会将当前字段不包含该词项的文档过滤出来。单击这两个按钮会形成不同 的过滤器,它们会自动出现在过滤器栏中。例如,选择 DestCountry 是 CN ,而 Cancelled 为 false 的所有文档,会形成两个过滤器如图所示。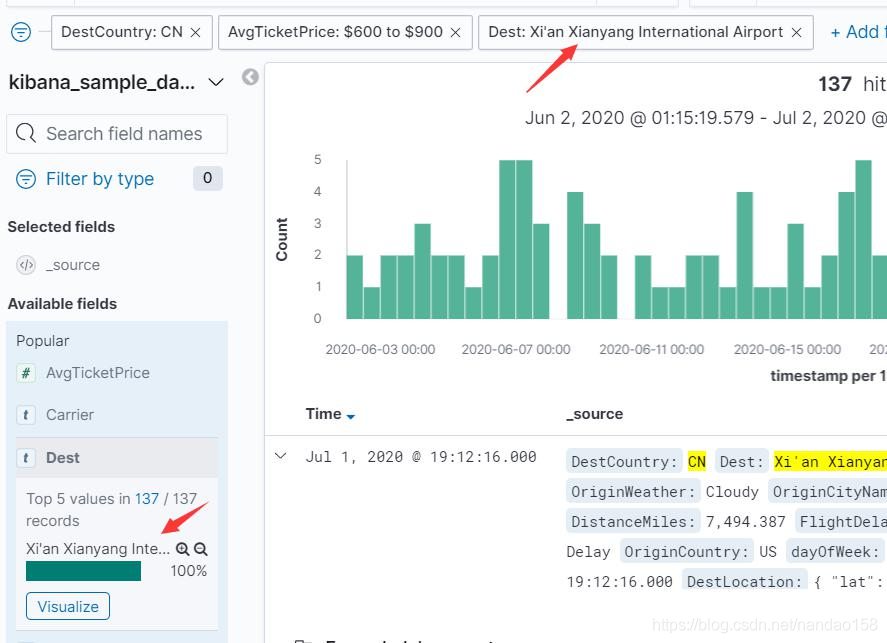
最后再来看一下文档栏。当鼠标指针悬停在每条文档的字段值上时,同样会 出现包含按钮和排除按钮,它们也可以用于根据字段与词项生成过滤器。在每条 文档前还有一个展开/ 收起开关,点击展开文档,可以看到当前文档的全部详细。 这包括所有字段以及它们的值,还有对字段的操作等,如图所示。

除了包含和排除按钮以外,还有两个按钮。 按钮的作用是从文档栏的列 表中添加或删除字段的开关,而 按钮则会添加一个字段存在性的过滤器。
文档的可视化
Kibana 可视化功能以图表形式展示 Elasticsearch 中的文档数据,能够让用 户以最直观的形式了解数据变化的趋势、峰谷值或形成对比。这些图表根据查询 条件从索引中提取文档,查询条件可以在文档可视化界面中定制,也可以使用在 文档发现中保存的查询对象。文档可视化生成的图表也可以保存,本书后续章节 称这些保存起来的可视化图表为可视化对象。在进入文档可视化界面时将会列出 Kibana 中所有的可视化对象,如果已经将 Kibana 提供的样例数据导人,则在 这个页面上将列出几十个不同的可视化对象。可以逐一点开查看这些可视化对象, 它们是学习文档可视化的好素材。在列表上方有搜索框,可根据名称搜索文档可
视化对象,如图所示。
在搜索框上面面有一个按钮,点击这个按钮会展示出所有可选的文档可视化 类型,创建自定义的可视化对象就是从这里开始。文档可视化类型很多,包括折线图、饼图、仪表、表格等。因为很多,我们只挑选几个有代表性的进行学习。

二维坐标图
二维坐标图基于二维直角坐标系的 X/Y 轴绘制数据,包括折线图、面积图 和柱状图三种。在二维直角坐标系中,X 轴也称横轴是自变量,而 Y 轴也称纵轴 是因变量,Y 总是随 X 变化而变化。以折线图为例,它反映的就是 Y 随 X 变化 的趋势。比如速度体现了距离随时间变化的趋势,那么 X 轴就应该是时间,而 Y 轴则是距离。在 Kibana 中,二维坐标图的 Y 轴一般是一个或多个指标聚集,比如平均值、 总数、极值等。而 X 轴则是桶型聚集,比如词项聚集、范围聚集等。所以指标 聚集、桶型聚集的知识是学习可视化功能的基础。
面积图
下面使用 kibana_sample_data_ flights 索引模式,创建个面积图来反映飞 行距离与机票价格之间的关系。首先要确定飞行距离与机票价格哪一个是 X 轴, 哪一个是 Y 轴。从数学角度来说,飞行距离是决定机票 价格的一个重要因素, 所以飞行距离是自变量而机票价格则是因变量。从聚集查询的角度来说,机票平 均价格使用指标聚集运算比较合适,而飞行距离使用桶型聚集更合适。所以从这 两个角度来分析都可以使用飞行距离作为 X 轴,而使用机票价格作为 Y 轴。当 然反过来也可以,但从逻辑上看比较奇怪。 在 kibana_sample_data_ flights 中, DistanceKilometers 字段代表航班飞 行距离,而 AvgTicketPrice 代表机票价格。接下来就来开始创建第 1 个可视化 对象,飞行距离与机票价格 关系的面积图。先在新建可视化对象中选择第 2 个 图形 Area ,进入选择索引模式的界面,如图所示。
单击 kibana_sample_data_flights 进入文档可视化创建界面。先在 Metrics 下面将 Y 轴设置为机票平均价格,即 AvgTicketPrice 字段的平均值。单击 Y-Axis 展开表单,将 Aggregation 的默认聚集类型 Count 修改为 Average 。接 下来在 Field 选项中,选择字段为 AvgTicketPrice 。 表单中 Custom Label 用于 定制 Y 轴的文字说明,比如输入“ Price"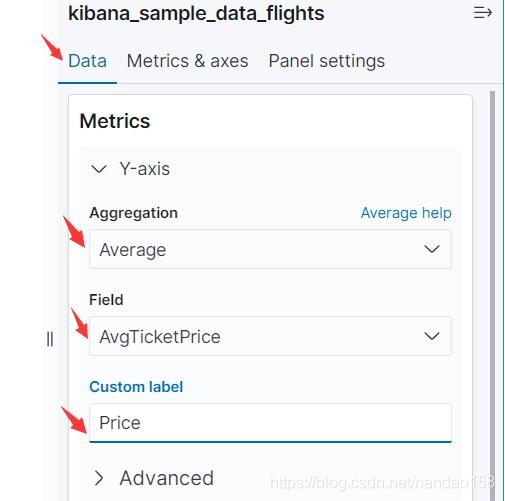
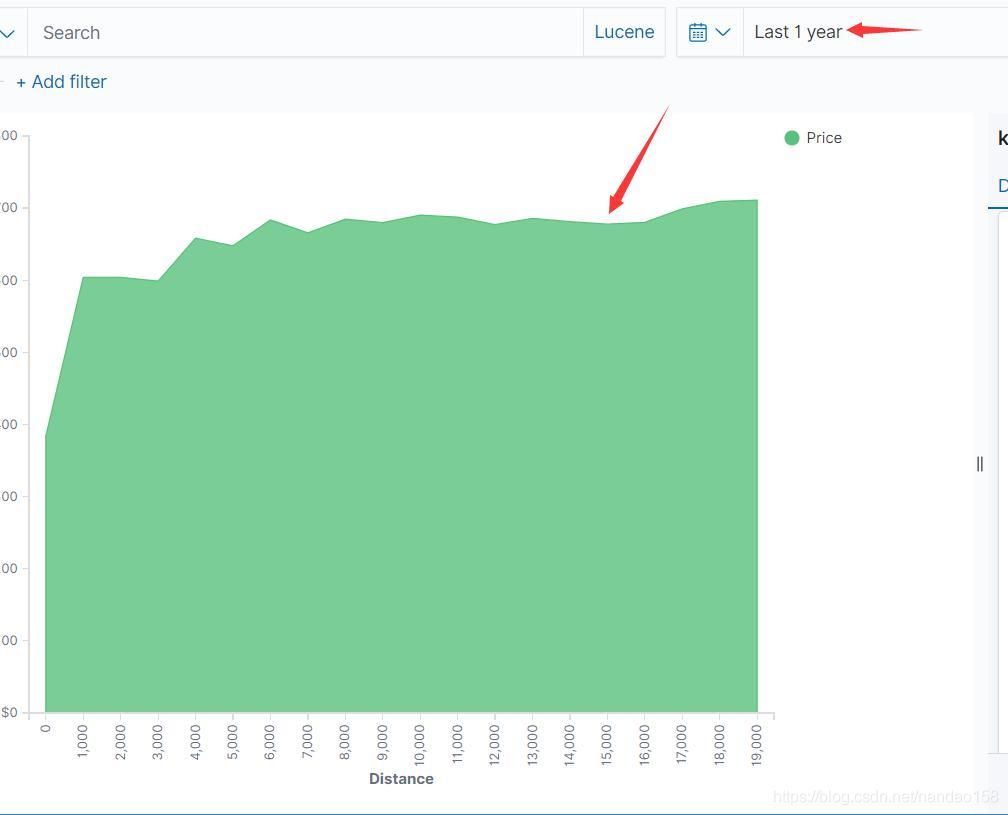
接下来再在 Buckets 下面将 X 轴设置为飞行距离,即按 DistanceKilometers 字段的值分桶。首先点击 X Asis 展开表单,将 Aggregation 下的聚集类型设置 为 Histogram 接下来在 Field 选项中,选择字段为 DistanceKilometers;Minimum Interval 则设置为 1000 。 表单中 Custom Label 用于定制 X 轴的文字说明,可 输入 Distance 。 X 轴和 Y 轴这样设置的目的是将文档按 DistanceKilometers 字段以 1000km 为最小分隔单元划分成不同的组,然后再对每一组文档的机票价格求平均值,最 后将它们绘制在界面上。设置结束后,单击”Update” 按钮,右侧的图形就会将数 据绘制出来,如图所示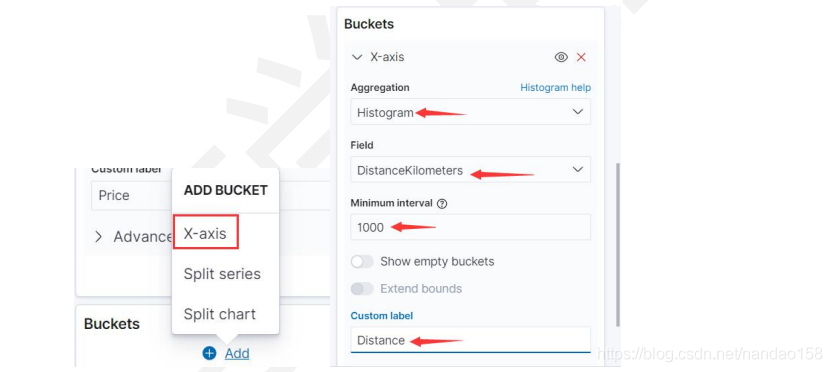

如果生成的面积图比较奇怪或者数据量比较少,这极有可能是时间范围取得 太小,可将时间范围设置为“This year ”以提取所有文档绘图。
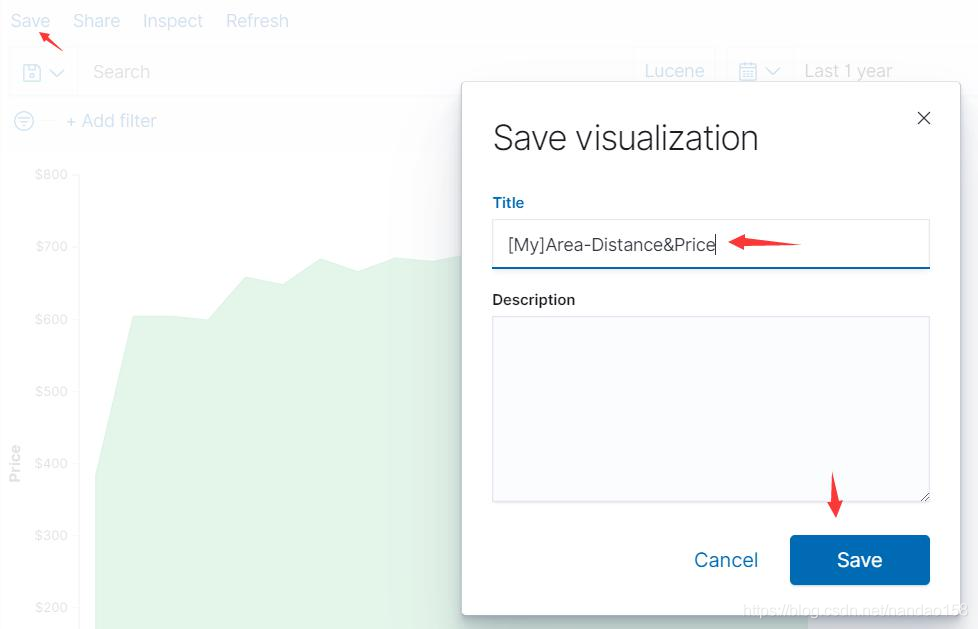
创建好的可视化对象可以保存起来,单击工具栏的 Save 按钮,将面积图保 存为“[My]Area-Distance&Price" 。保存好的可视化对象,可以在进入可视化功 能界面中看到。
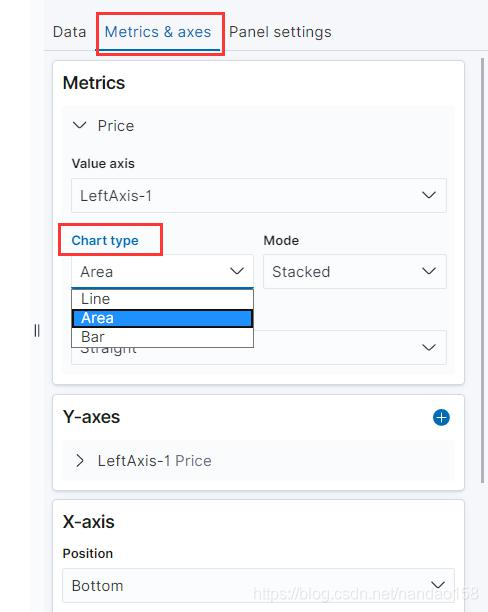
Metrics&Axis 配置页分为 Metrics 、 Y-Axis 、 X-Axis 三部分,分别用于配 置指标、Y 轴和 X 轴。在 Metrics 下有四个选项可以配置,其中的 Chart Type 有三个选项 line 、 area 和 bar ,可以切换二维坐标图的类型。可自行选择切换类 型,然后按“Update ”按钮查看效果。 事实上在创建可视化对象时,可供选择的可视化对象类型中有单独的折线图 和柱状图。要想创建保存独立的折线图或柱状图,可以在创建时选择 Line 、 Horizontal Bar 或 VerticalBar 。由于它们创建的过程与面积图基本相同。
指标叠加
指标叠加是创建多个指标聚集,并且在一张二维坐标图中绘制出来,直观的 表现就是在二维坐标中有多个图共享相同的坐标。下面就在飞行距离与机票价格 的基础上,给可视化对象再添加一个指标,以体现不同飞行距离的航班数量。 重新打开“[My]Area-Distance&Price ", 将它另存为 “[My]Area-Distance&Price &Count" 。 在 Metrics 下面单击 Add 按钮为 Y 轴增加新的指标。在弹出的 Seleet metrics type 中选择 Y- Axis, 再选择指标聚集类型为 Count, 并为坐标添加说明
标签 Count 。如图所示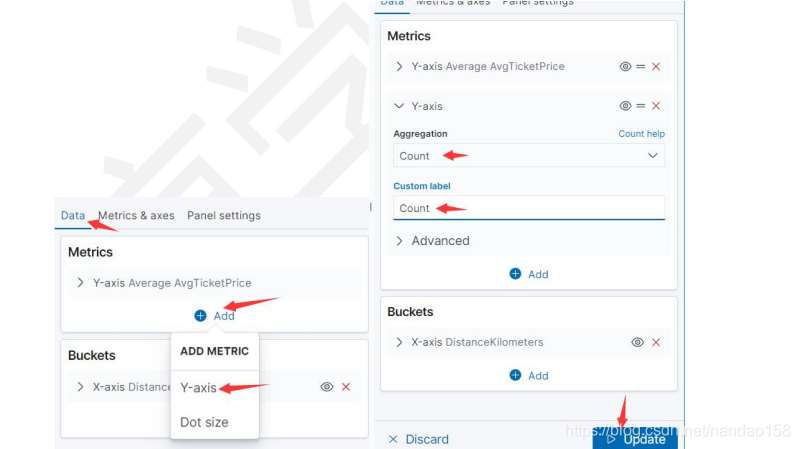
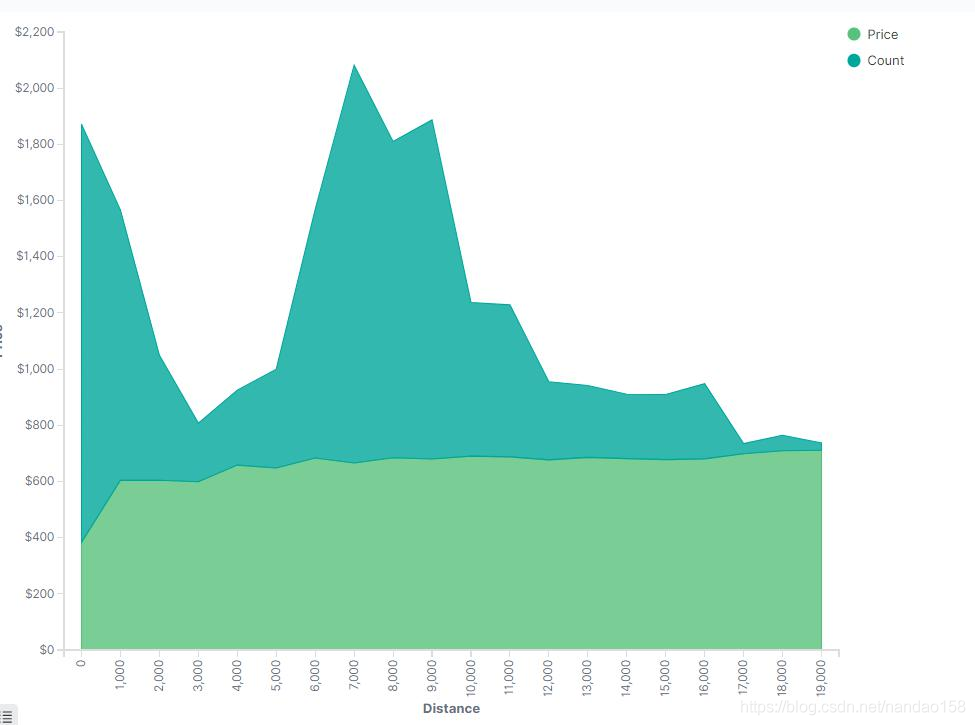
设置好之后 Update ,会看到在面积图中出现了两种不同颜色的面积图,如 图所示:
在默认情况下,叠加指标之间不会出现交叉,但可通过设置 Mode 参数修改。 将配置页面切换回 Mris&Axes 会看到 Meries 在原来 Price 的基础上多了一个 Count。在 Mode 参数的下拉列表中分别选择 normal 看看。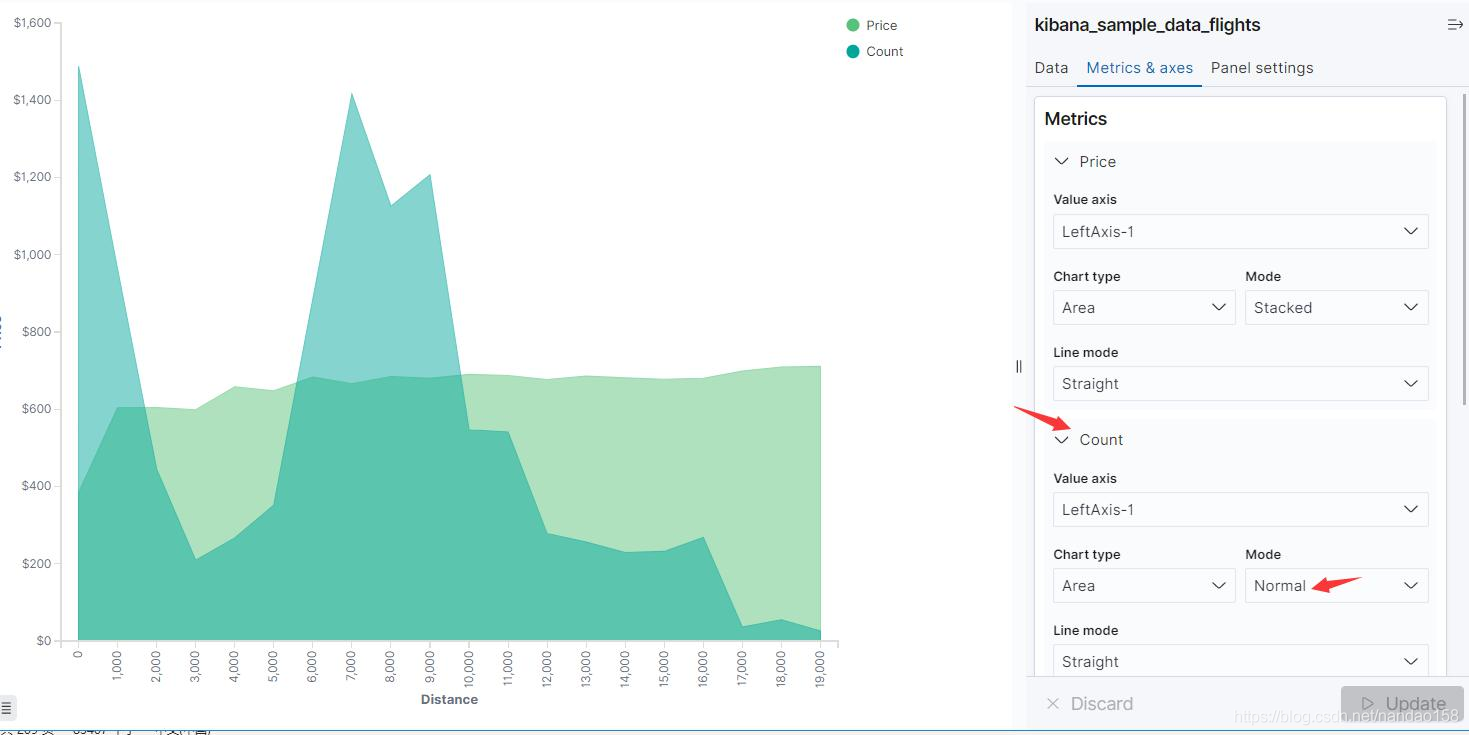
在多指标的情况下每一个指标的设置都是独立的,可以分别给每个指标选择 不同的图形,因此可以在一个图形中同时使用折线图、面积图和柱状图来表现不 同的指标。 叠加指标时多个指标可以共享一个 Y 轴,也可以在 Metrics& Axes 配置页中 设置图像使用多个Y 轴。在 Metrics& Axes 配置页中将 Count 指标展开,在“ Value Axis"选项中选择“ New Axis ” , 这时在下面的 Y-Axes 中就会多出来一个新的 Y 轴,如图所示: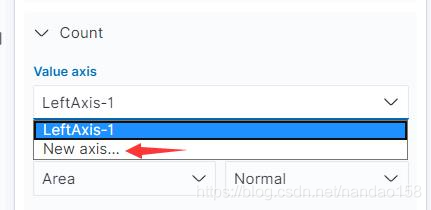
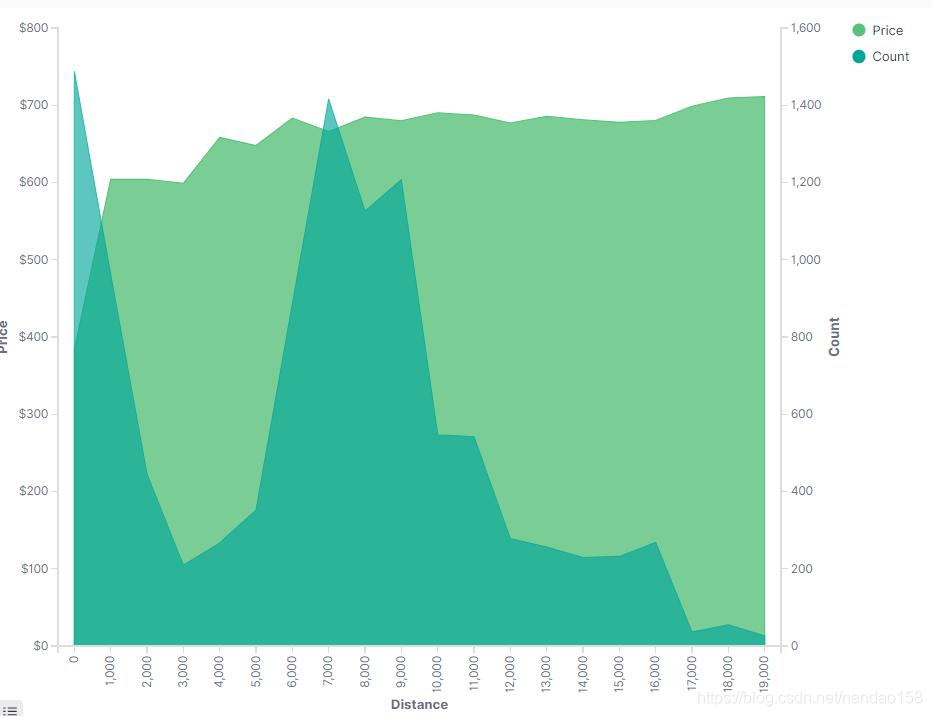
如果将两个指标的 Y 轴分列两边,则图形的 Mode 就只能是 normal 了,即 使选择 stacked 也不会再起作用了。 在配置栏最后一个标签页是“ Panel Settings", 可以设置图例位置、提示、 网格线等等配置。图侧默认情况下位于坐标图形的右上侧,它展示了图形中不同 颜色图形对应的信息。不仅如此,单击这个图例还可以配置图形颜色,如图所示。 在图 10-11 中, Price 指标被设置为折线图,而 Count 则被设置为柱状图。 同时,Count 指标通过图例修改为浅兰色,并通过 Grid 参数绘制了 Y 轴的网格
线。“Panel Settings" 其余参数中, Legend position 用于设置图例位置,包括 Top、 Left 、 Right 、 Bottom 四个选项, Show tooltip 则是图形提示信息的开关, 当开启时鼠标指针悬停在图形拐点上时会出现提示信息,不过目前这个参数不起 什么作用。 最后将这个可视化对象另存为“[My]Line-Bar-Distance&Price &Count "。 它非常直观地体现了飞行距离与票价的关系,同时还体现了飞行距离在数量 上的分布情况。
圆形与弧形图
二维坐标图是中规中矩的统计图形,它们可以严谨地体现出自变量与因变量 之间的关系和趋势。在实际应用中,圆形与弧形也经常用来展示统计数据,但它 们体现的往往是部分与整体之间的关系。 在 Kibana 中也包含了几种圆形或弧形的可视化对象,它们是饼图 (Pie) 、目 标(Goal) 和仪表 (Gauge) , 本小节就来介绍这三种可视化对象。
饼图
饼图使用圆或圆环表示整个数据空间,并以扇面代表数据空间的某一部分, 所以饼图在展示部分与整体的关系时非常直观。目标和仪表是两个不同的可视化 对象,它们会将某一 指标值的范围绘制在一个 表盘中,并以指针或进度条的形式显示该指标在仪表中的实际值。这两种对象一般用于监控某系统的运行状态, 体现该系统在某一项指标上的健康状态。 饼图有两项变量需要定义,一是饼图要区分多少个扇面,另一个就是每个扇 面有多大。这两个变量在 Kibana 中由桶型聚集和指标聚集来决定,所以创建
Kibana 饼图也同样包含 Metrics 和 Buckets 两个配置项。其中, Metries 只能定 义一个指标聚集, 决定扇面大小;而 Buckets 则可以定义多个,决定扇面有多 少个。下面说明如何配置 Kibana 饼图。在创建可视化对象窗口中选择 Pie 并选择
kibana_sample_data_flights 索引模式,进入创建饼图的配置界面。
在 Metrics 配置项下单击 Slice Size 按钮展开表单,选择指标聚集为 Count, 并在 CustomLabel 中填写标识为“ Count ”。 接下来选择 Buckets 下面的 Split Slices,并选择聚集为 Carrier 字段的 Terms 桶型聚集。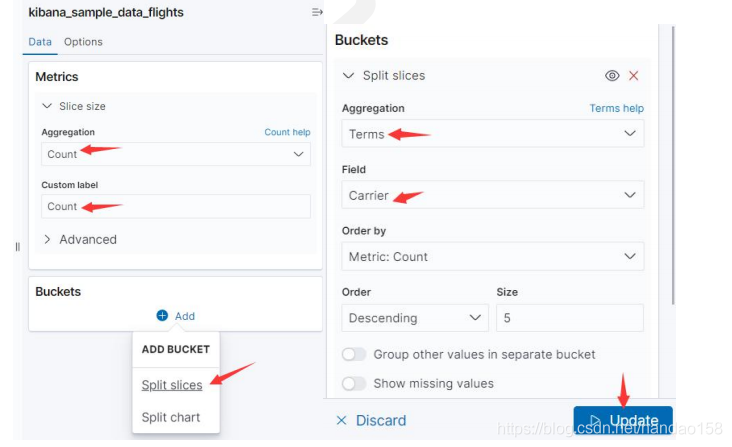
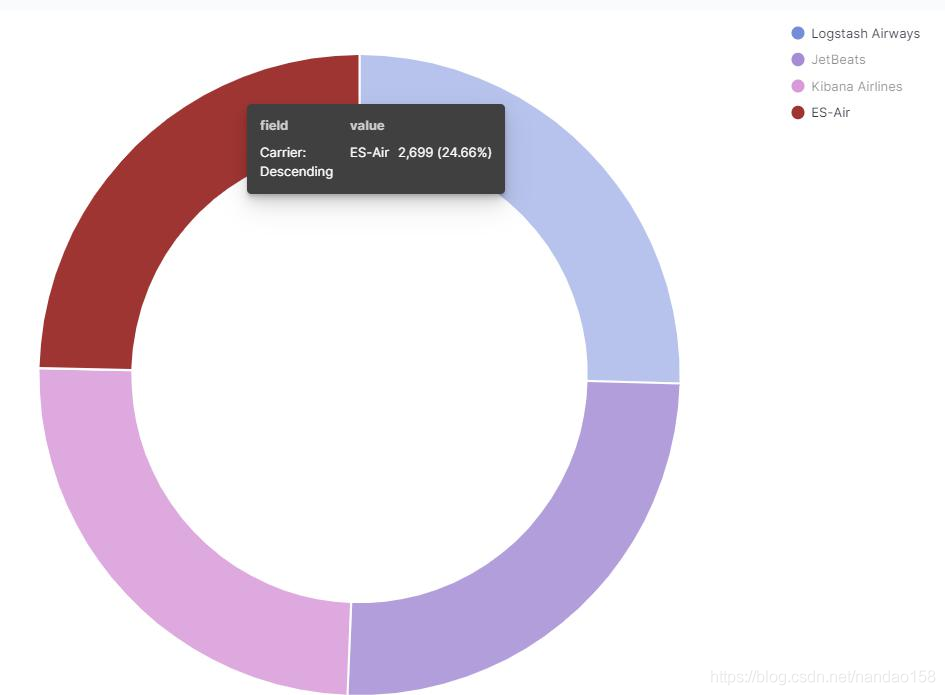
默认情况下, Kibana 饼图为圆环形,这可以通过在 Options 界面中修改 Donut 开关更改。勾选 Donut 选项时绘制的图形为圆环,而取消勾选 Donut 则 绘制的图形为圆形。除了设置饼图的类型,还可以设置扇面的标识,即勾选 Show Labels 可以开启每个扇面的标识信息。最后,通过 Legend Position 下拉列表 可以设置图例的位置,可选项包括 left 、 right 、 top 、 bottom ,饼图被绘制为圆 形,并包含了标识信息。将这个饼图保存为“[My] Pie- Carrier&Count ”。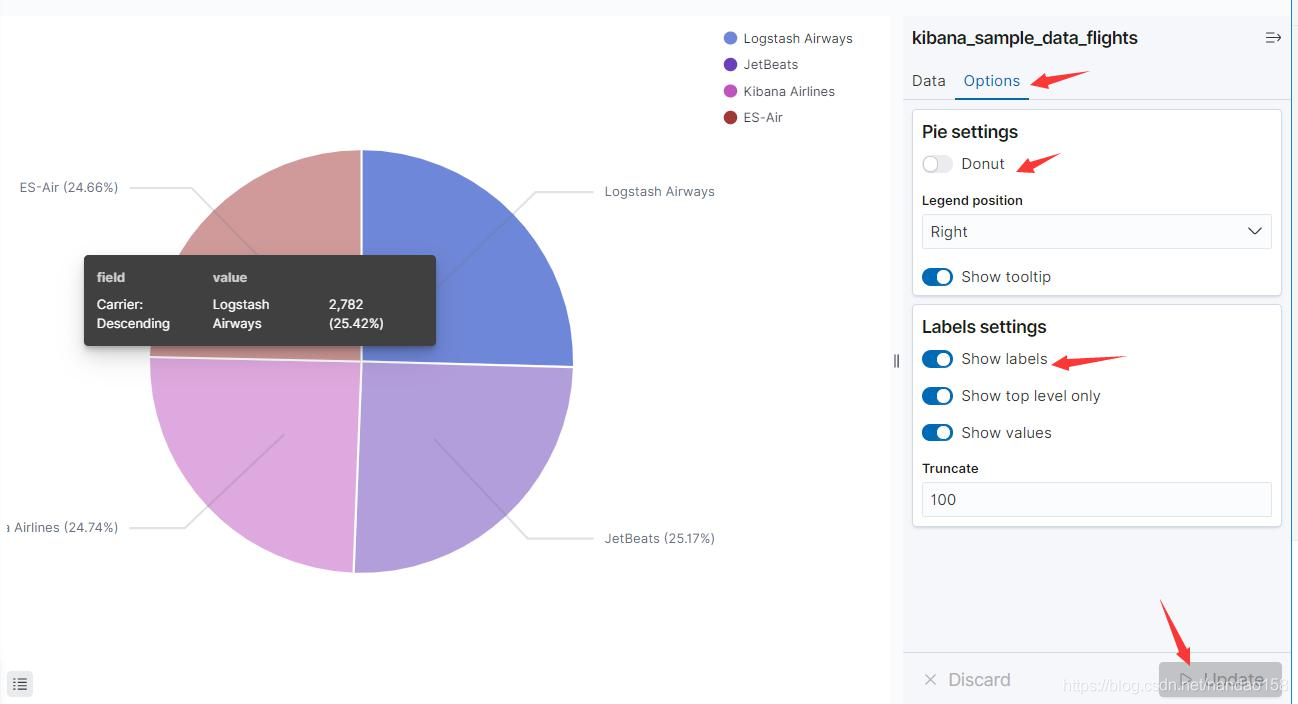
饼图叠加
在添加桶型聚集时有两个选项,一 个是 Split Slices, 而另 - 一个则是 Split Chart。与折线图类似, Split Chart 会以分割 X 轴或 Y 轴的形式添加子桶型,但 只能添加一次且必须要先于 Split Slices 添加。上一小节的示例中选择了 Spit Slices, 这时如果再通过 Add sub buckets 添加子桶型时就不能再添加 Slipt Chart 了。 先将“[My] Pie- Carrier&Count " 另存为“ [My]Pie.Split.Chart-Carier&Count ”。 单击桶型聚集后面的叉子按钮删除原来的桶型聚集,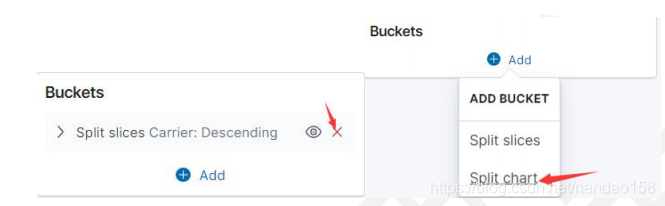
再以 Split Chart 方式添加 Carrier 字段的 Terms 聚集。然后再单击 Add subuckets 添加子桶型,这时就只有一个 Split Slices 选项了,将子桶型设置为 DestCountry 的 Terms 聚集。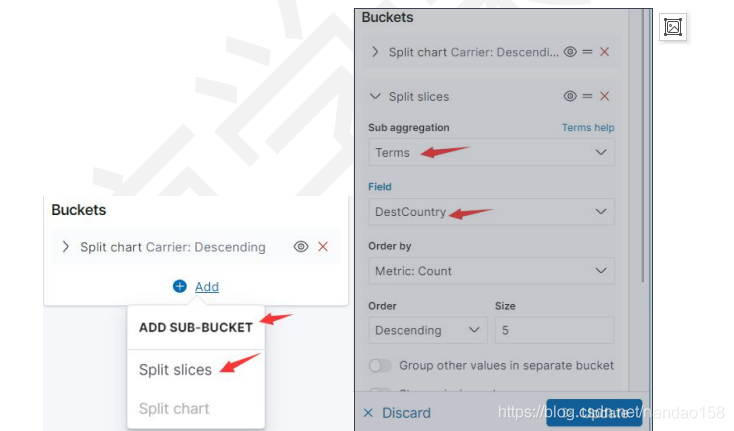
饼图的 Split Chart 也有 Rows 和 Columns 两个按钮,选择 Rows 时按行分 割 Y 轴,而选择 Columns 则按列分割 X 轴。
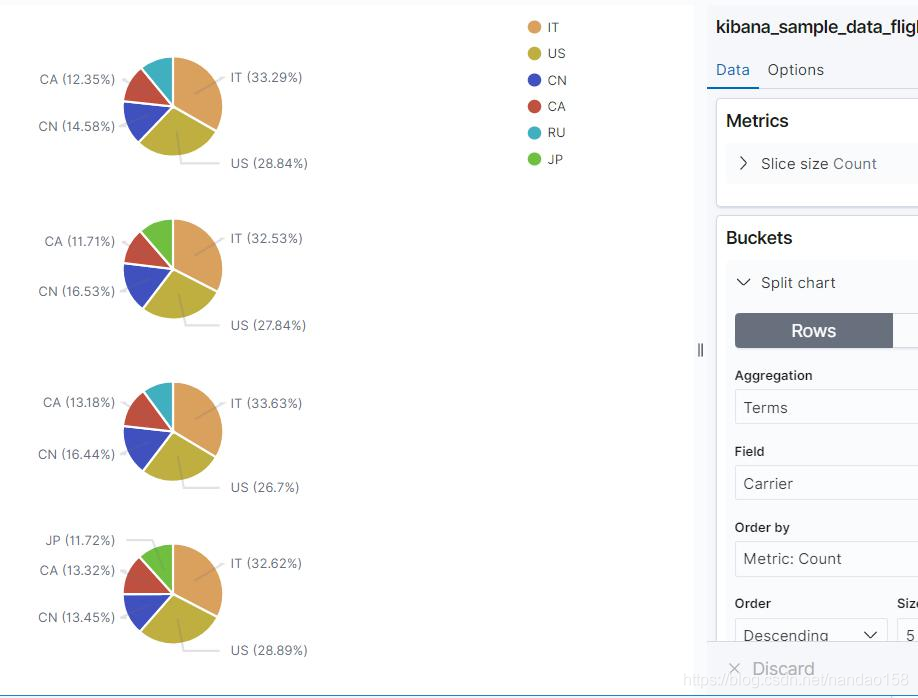

上所示的饼图先按不同的航空公司 (Carrier) 分割坐标,所以每一个饼图就 代表一个航空公司。在每一个饼图中, 每个扇面代表的是航班的目的地国家占 比。与 Split Chart 只能添加一次不同, Split Slices 可以添加多次子桶型。新添 加进来的子桶型,会对父桶型中每一个桶再次分桶, 展示出来的饼图是同心环 或同心圆。将上面的可视化对象另存为“[My] Pie. Split.Slices-Carrier&Count ”, 将所有的桶型聚集删除后再使用两个 Split Slices 添加 Carrier 和 DestCountry 字段的 Terms 聚集,最终的效果如图所示。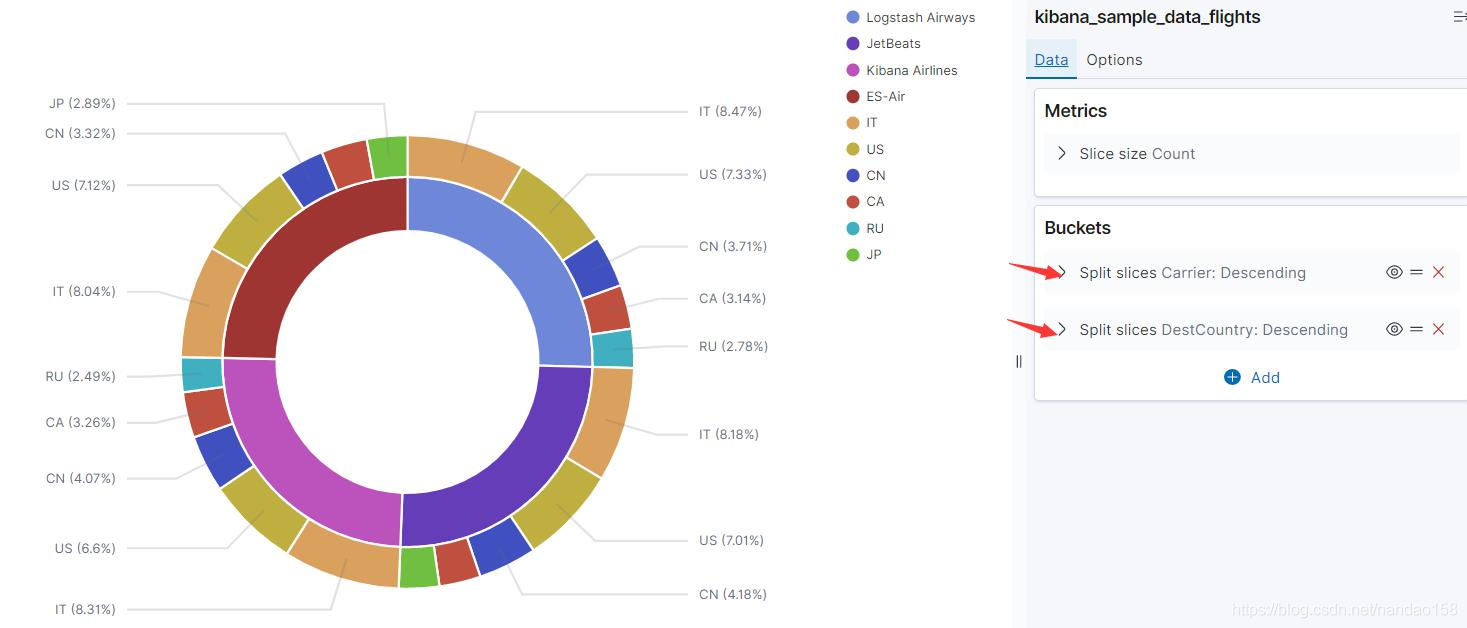
在上图中使用两个圆环代表两个桶型聚集,内侧圆环分为 4 个扇面代表 4 个航空公司; 而外侧圆环又将每个扇面划分为 10 个更小的扇面,代表 10 个不同 的目的地国家。从这个饼图可以清楚地看出 4 个航空公司的航班数量占比,而每 家航空公司在每个国家的市场份额也一目了然。
目标图
目标可视化对象体现的是指标值距离设定目标值之间的差距,实际值越高越 接近目标值说明系统运行越好。比如,设定一个年度销售额目标,通过目标可视 化对象就可以体现出当前实际销售额与目标销售额之间的对应关系。同样,仪表 可视化对象也可以体现指标值在仪表中的实际位置,但体现的往往是系统某一 项指标是否处于安全区间。因此,仪表会给不同的数值区间赋予不同的颜色,值 越高颜色越深。目标和仪表一般使用弧形, 也可以配置为圆环形状。 比如我们设置 Kibana Airlines 航空公司每月航班数量的目标为 3000 次,来 生成一个目标可视化对象。由于这次要生成的可视化对象要过滤航空公司,所以 在配置目标可视化对象前要先配置检索。在创建可视化对象中选择 Goal 对象, 然后选择 kibana_sample_data_flights 索引模式。
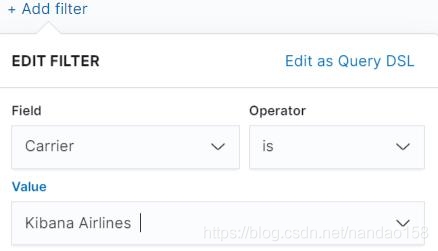
进入 Goal 对象配置界面后,先给可视化对象添加过滤器。单击 Add a filter 并设置过滤器为 Carrier is Kibana Airlines" ,单击 Save 按钮保存过滤器。
同时还要注意,由于图形展示的目标是月度航班数量,所以要将时间范围设 置为月。接下来,在 Options 界面中设置目标值为 3000 次。找到 Ranges 选项,将 “To 设置为“ 3000” ,这时目标对象会按 3000 目标来计算百分比,如图所示: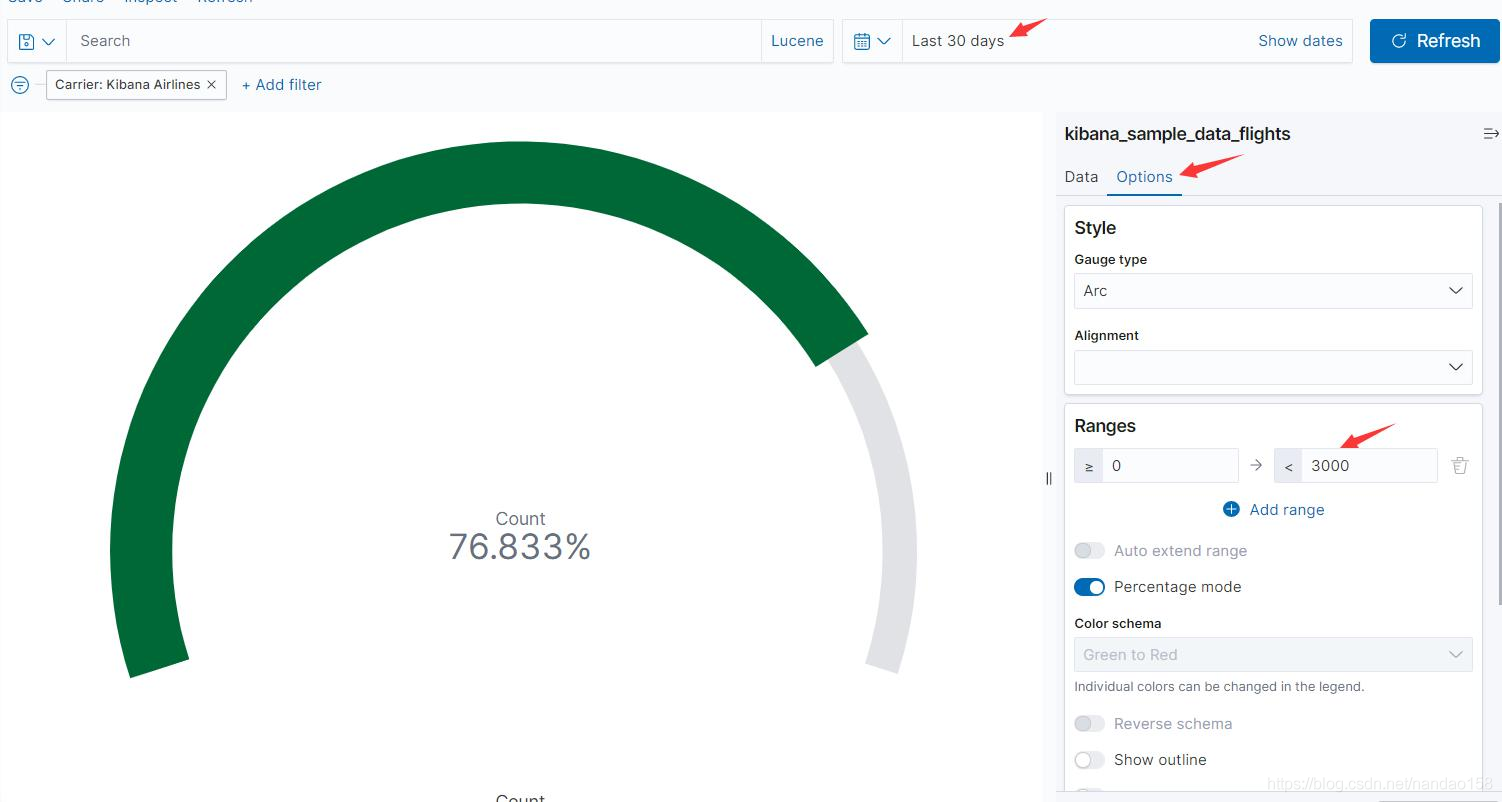
将它保存为“ [My] Goal- Count" 。 Ranges 选项可以设置为多个,生成的目 标对象会根据实际值选择不同颜色,但这对于目标对象来说意义并不大。。
仪表图
以航空公司的航班延误时间为指标,生成一个航班延误时间的仪表。选择 Gauge 对象及 kibana_sample_data_flights 索引模式后,在配置页面上将指标 聚集设置为 FlightDelayMin 的 Average 聚集。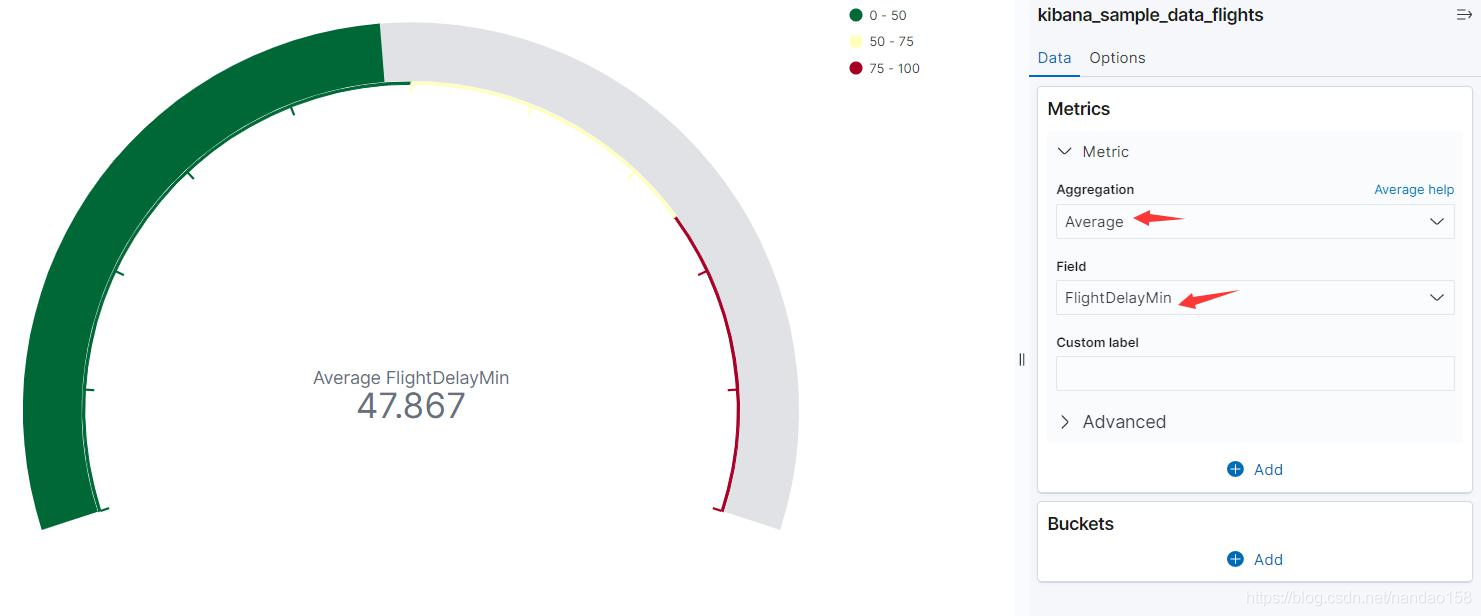
在仪表中看到平均延误时间为 47.867 ,且标识该值的进度条为绿色。这是 因为 Kibana 默认将整个取值范围设置为 100, 并且设置了 0~50 、 50~75 和 75-~ 100 三个区间,它们对应的颜色分别为绿色、黄色和红色。可以到 Options 配 置页面,将延误取值范围修改为 1 个小时,并设置 0~20 、 20~40 和 40 ~60 三 个区间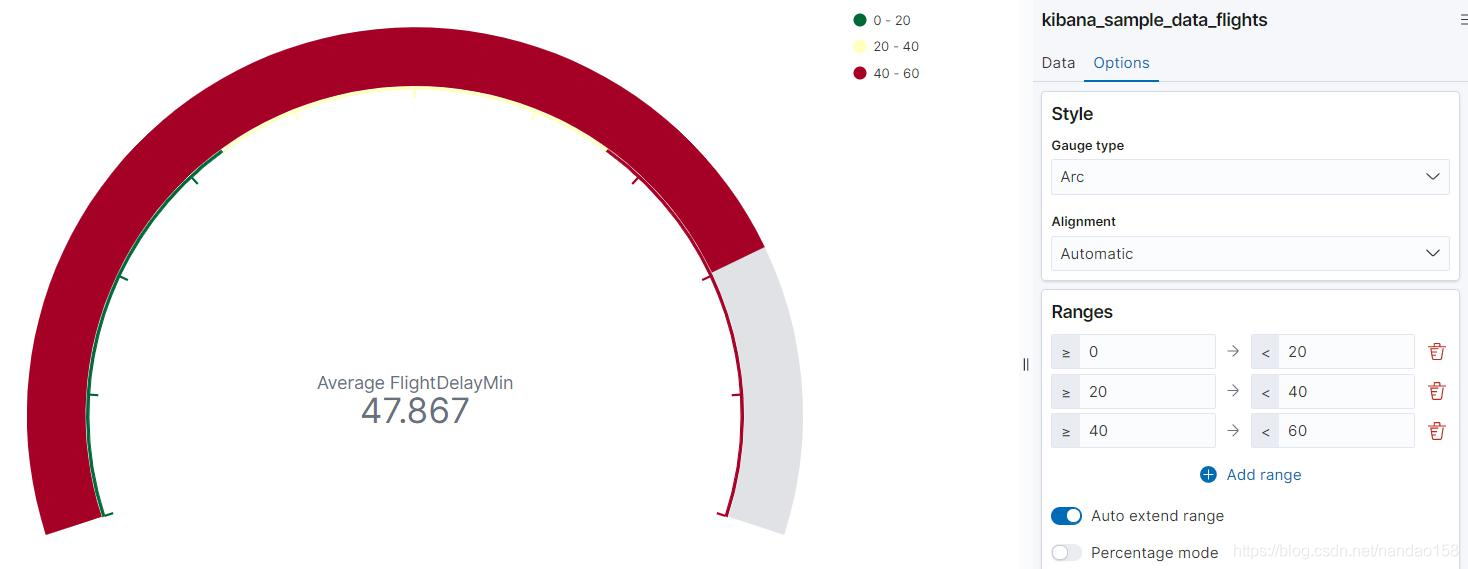
修改范围区间后,由于当前平均延误时间已经达到第三个区间,进度条变为 红色。有关颜色的变化,可以通过修改“Color Options" 变更。另外在 Options 上还有其他一些 选项可以配置目标和仪表对象,比如可以通过“Gauge Type" 将它们的图像设置为完整的圆形。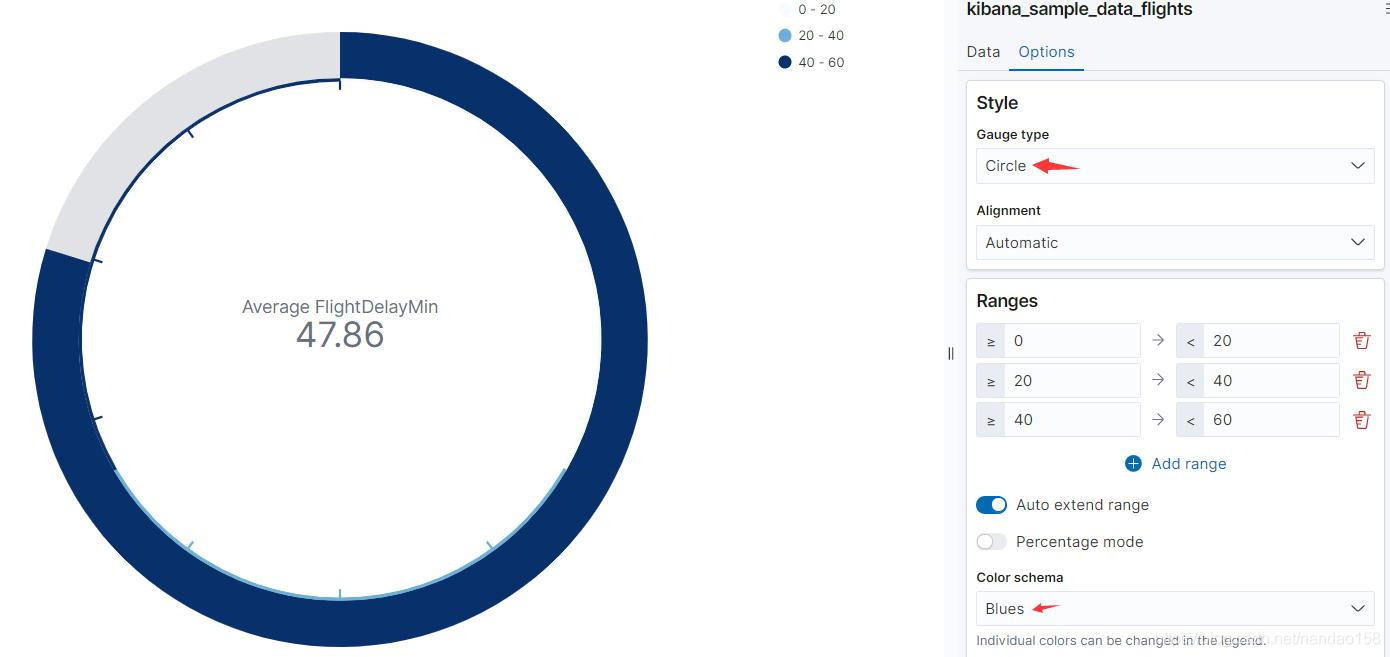
修改完成后,将可视化对象保存为“ [My] Gauge- Delay" 。
热力图
热度原本是指某一事物的冷热程度,但在互联网和大数据时代它越来越多地 代表某种资源的使用频度,资源使用得越多,它的热度也就越高。比如在搜索引 擎中的热词,在地图中展示的交通流量、热点区域等。Kibana 有几种与热度相 关的可视化对象。比如热力图、标签云等,我们来了解下热力图。 热力图通常是在一个可区分为不同区域的图形上,以不同颜色标识某一指标
值在不同区域的高低分布情况。比如在地图的不同区域以不同颜色标识交通流量、 人口分布等情况,交通流量越大、人口密度越高它们所在区域的热度也就越高, 区域对应的颜色也就越深。Kibana 热力图与此类似,但它并不是绘制在地图上,而是绘制在二维坐标 上。与前面介绍的几种二维坐标图不同,Kibana 热力图的 X 轴和 Y 轴都是桶型 聚集。它们相互交叉形成一个可以用热度值标识的二维矩阵,而热度值则由另一 个独立的指标聚集来定义。 所以,在 Kibana 热力图中至少要定义三个聚集,即 X 轴的桶型聚集、 Y 轴 的桶型聚集和热度值对应的指标聚集。Kibana 在绘制热力图时,会根据 X 轴和 Y 轴对应的两个桶型聚集,分别计算它们所对应的指标聚集,然后再在热力图矩 阵中以不同的颜色绘制出来。下面还是以飞行距离与机票价格的对应关系为基础, 并添加航空公司这一桶型聚集, 来看一下飞行距离、航空公司在机票价格上形 成的热力图。 首先在创建文档可视化的弹出窗口中选择 Heat Map,并在接下来的索引模 式中选择 kibana_sample_data_fights 。 热力图的配置栏也包含 Metrics 和 Buckets 两个配置项,点击 Metrics 下的 Value 按钮,将热度对应的指标配置为 AvgTicketPrice 的平均值聚集:
接下来再来配置 X 轴和 Y 轴的桶型聚集。在 Buckets 下先选择 X-Axis, 将 X 轴设置为 DistanceKilometers 字段的 Histogram 桶型聚集, Minimum Interval 设 置为 1000 。
这之后再点击 Add sub- buckets
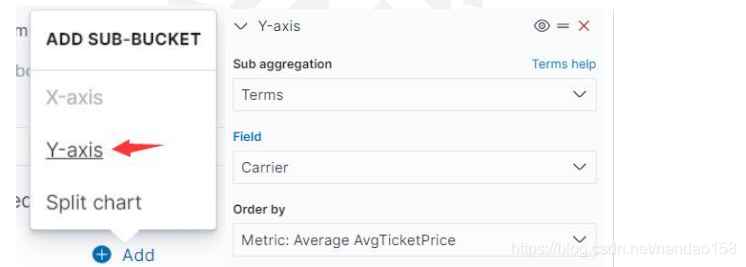
选择 Y- Axis 设置 Y 轴的桶型聚集为 Carrier 字段的 Terms 聚集:

这个热力图看上去不是那么经典,这主要是因为指标值的范围比较集中,所 以绘制出来的热力图层次感并不强。但在热力图配置的 Options 页面,可以设置 包括热度颜色种类、指标数量或范围等内容,通过这些配置可以让热力图看起来 更能反映实际情况。设置结束后单击 Save 按钮,以 "[My] Heat Map-Distance& Carrier&Price"" 为名称保存热力图对象。
表格
尽管表格在文档可视化中的应用越来越少,但它在展示具体数值时具有一定 的优势, 所以在一些特定场景下表格是不可或缺的可视化元素。 Kibana 中表格对应的可视化对象为 Data Table 。
表格由行和列组成,是一种通用的展现关系型数据的形式,所以要想绘制表 格必须先确定行和列分别由什么来确定。在 Kibana 的表格中,行由桶型聚集决 定,而列则由指标聚集决定。 下面来创建一一个表格,并以航空公司为行分别统计它们的航班数量、平均 票价、平均飞行距离等,这将形成 4 行 3 列的表格 ( 不包含表头 ) 。在创建可视化 对象页面选择 Data Table, 然后选择 kibana_sample_data_fights 索引模式进入 表格配置界面。表格配置栏包含 Metrics 和 Buckets 两栏, Metric 相当于列可以
设置多个, Buckets 相当于行也可以设置多个。 先添加三个指标聚集,分别为 Count 聚集、 AvgTicketPrice 字段的 Average
聚集和 DistanceKilometers 字段的 Average 聚集,
设置完成生成图所示的表格:

如果想给表格增加更多列,可以在 Metrics 配置项中继续添加指标聚集。表 格可按每一列排序,当鼠标指针悬停于每一行的表头时还会出现排除和包含按钮。 单击它们可以在可视化对象中添加过滤器,表格中的数据也会跟着发生变化。将 这个表格保存为“[My]Table-Carrier" 。
在添加 Buckets 时,有“ Split Rows ”和“ Split Table ”两个选择。“ Split Rows ” 在添加子桶型时会将父桶型按行分割,后者则会直接将表格分割成多个。为上述 表格再添加一个 DestCountry 的 Terms 聚集,在使用“ Split Rows" 形成的表格
如图所示: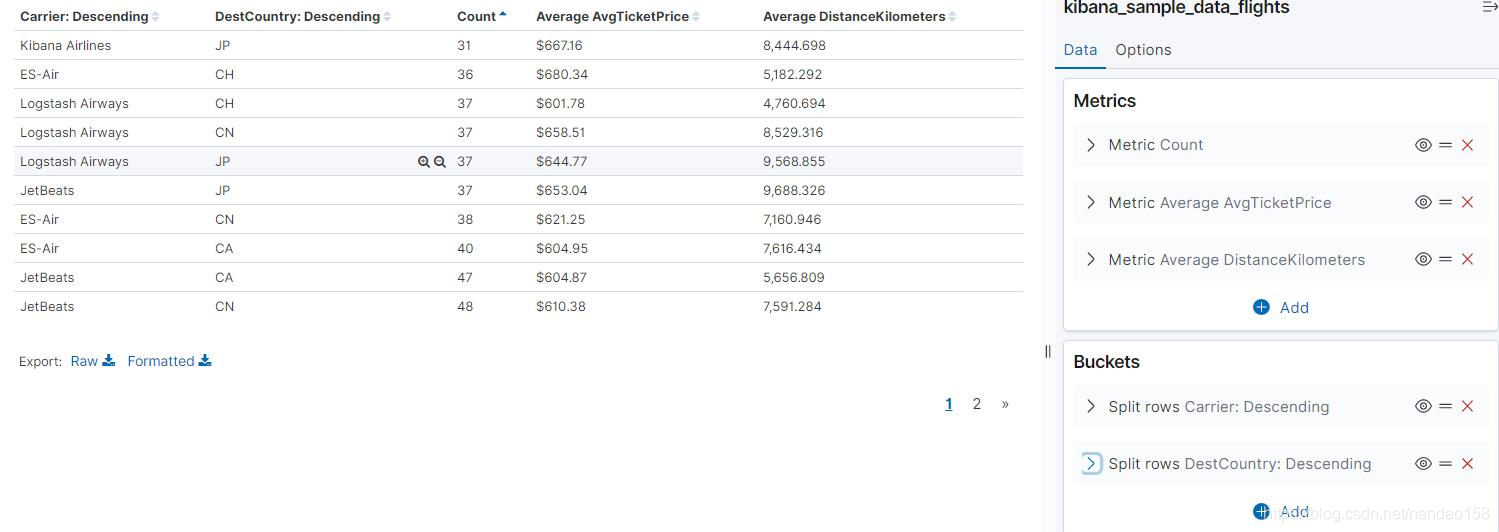
“ Split Table" 会将表格分割成多个,而且也是只可以添加一次。同样是为表 格添加一个 DestCountry 的 Tems 聚集,但这次使用“ Split Table" ,如图所示。
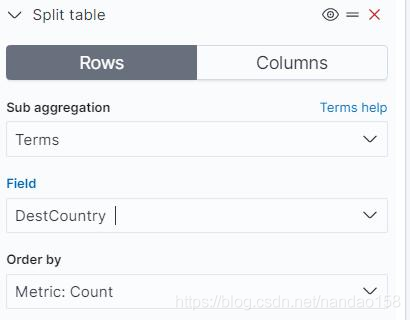
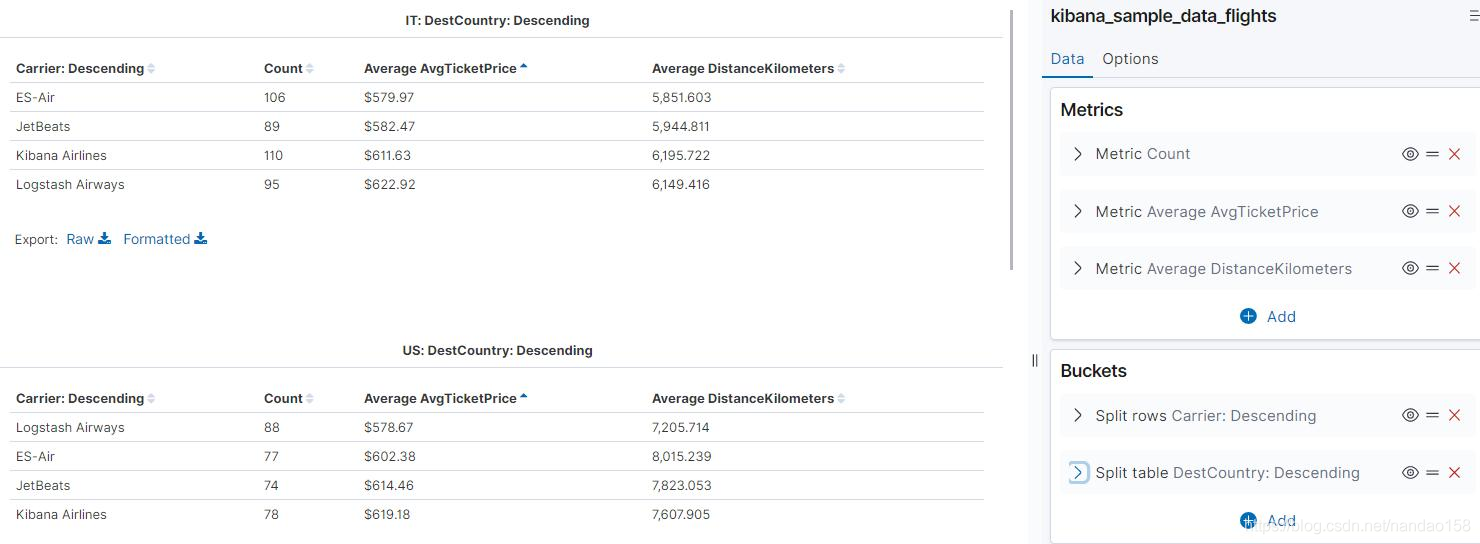
默认情况下表格在展示时会分页,在 Options 标签页中可以设置每页展示数 据的数量,默认值为 10 。
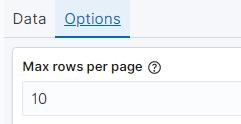
默认情况下表格在展示时会分页,在 Options 标签页中可以设置每页展示数 据的数量,默认值为 10 。
仪表盘
仪表盘 (Dashboard) 是 Kibana 提供的综合展示数据的功能,在 Kibara 中保 存的可视化对象可以在仪表盘中组合起来共同展示。
仪表盘是位于导航栏的第三个功能,如果已经导入了 Kibana 样例数据,进 入仪表盘界面后会看到已经保存的仪表盘对象,如图所示:
果想要创建新的仪表盘对象,可单击 Create new dashboard 按钮。 事实上,如果我们根据前面的章节里保存了查询对象和可视化对象,创建一 个仪表盘还是非常简单的。 单击Create dashboard 按钮进人创建仪表盘界面,仪表盘界面与文档发现、
文档可视化界面类似,也包含有工具栏、查询栏、时间栏和过滤器栏,只是工具 栏中的按钮有些不同。创建仪表盘的过程很简单,单击工具栏中的 Add 按钮或者是在展示区域中 的 Add 链接会弹出 Add Panels 对话框,其中包含了已经保存的可视化对象和查 询对象列表。用户可在其中挑选希望加入仪表盘的对象,也可以单击 Add new Visualization 按钮创建可视化对象,如图所示。
存的可视化对象,如图所示。
单击某个可视化对象名称,控件就被添加到仪表盘中了。按相同的方式选择 所有感兴趣的可视化对象将它们依次添加到仪表盘中,它们将按添加顺序依次出 现在仪表盘中。在每一个面板的右上角都有一个设置按钮 , 单击这个按钮 会弹出一个选项对话框,通过个这对话框的选项可以实现对每个面板的定制。在 每一个面板的右 下角还有一个 形状的按钮,可通过这个按钮调节面板大小。另外,使用鼠标左键按住面板的标题部分还可以在仪表盘中移动面板,调整 面板在仪表盘中的位置。 仅仅通过鼠标进行几下简单的点击,一个像模像样的仪表盘就展现出来了。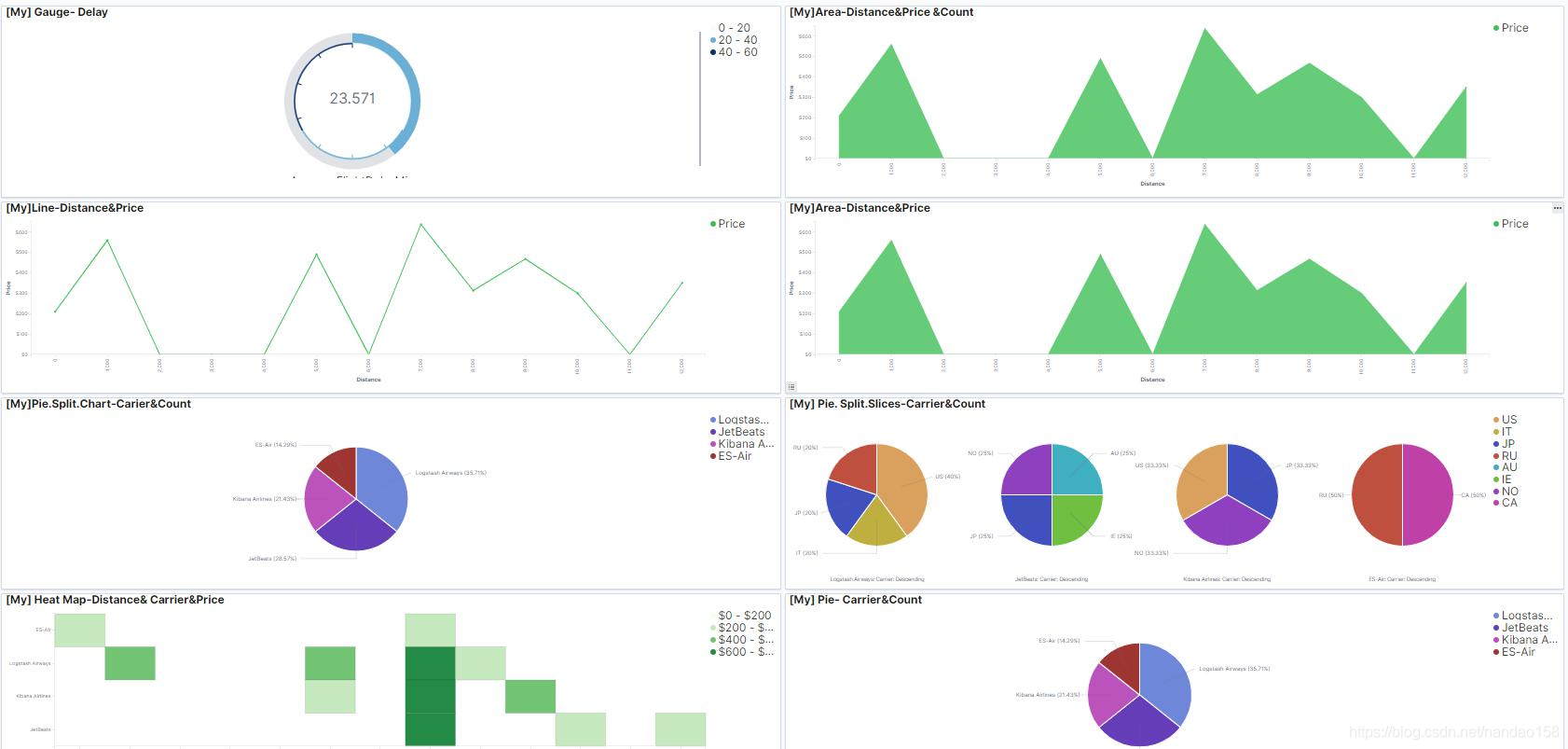
ELK集群之kibana(4)的更多相关文章
- Kibana安装(图文详解)(多节点的ELK集群安装在一个节点就好)
对于Kibana ,我们知道,是Elasticsearch/Logstash/Kibana的必不可少成员. 前提: Elasticsearch-2.4.3的下载(图文详解) Elasticsearch ...
- Centos7中ELK集群安装流程
Centos7中ELK集群安装流程 说明:三个版本必须相同,这里安装5.1版. 一.安装Elasticsearch5.1 hostnamectl set-hostname elk vim /e ...
- ansible playbook部署ELK集群系统
一.介绍 总共4台机器,分别为 192.168.1.99 192.168.1.100 192.168.1.210 192.168.1.211 服务所在机器为: redis:192.168.1.211 ...
- Filebeat-1.3.1安装和设置(图文详解)(多节点的ELK集群安装在一个节点就好)(以Console Output为例)
前期博客 Filebeat的下载(图文讲解) 前提 Elasticsearch-2.4.3的下载(图文详解) Elasticsearch-2.4.3的单节点安装(多种方式图文详解) Elasticse ...
- 通过docker搭建ELK集群
单机ELK,另外两台服务器分别有一个elasticsearch节点,这样形成一个3节点的ES集群. 可以先尝试单独搭建es集群或单机ELK https://www.cnblogs.com/lz0925 ...
- ELK集群搭建
基于5台虚拟机,搭建ELK集群. 方案: 1. ELK是日志分析平台,而不是一款软件,是一整套解决方案,是三个软件产品的首字母缩写,ELK分别代表: Elasticsearch:负责日志检索和储存 L ...
- 搭建ELK 集群 rpm安装
上次是使用docker搭建的ELK,三个软件都跑在一台机器的一个docker中,这个就当是测试环境吧. 下面开始搭建正式环境下的ELK集群. 三台服务器 A:logstash B:Elasticsea ...
- elk集群配置配置文件中节点数配多少
配置elk集群时,遇到,elasticsearch配置文件中的一个配置discovery.zen.minimum_master_nodes: 2.这里是三配的2 看到某一位的解释是这样:为了避免脑裂, ...
- 部署elasticsearch(三节点)集群+filebeat+kibana
用途 ▷ 通过各个beat实时收集日志.传输至elasticsearch集群 ▷ 通过kibana展示日志 实验架构 名称:IP地址:CPU:内存 kibana&cerebro:192.168 ...
随机推荐
- 网络IO模型与Reactor模式
一.三种网络IO模型: 分类: BIO 同步的.阻塞式 IO NIO 同步的.非阻塞式 IO AIO 异步非阻塞式 IO 阻塞和同步的概念: 阻塞:若读写未完成,调用读写的线程一直等待 非阻塞:若读写 ...
- django forms的常用命令及方法(一)
根据别人网上发布,个人爱好收集 Form表单的功能 自动生成HTML表单元素 检查表单数据的合法性 如果验证错误,重新显示表单(数据不会重置) 数据类型转换(字符类型的数据转换成相应的Python类型 ...
- Dockerfile 的常用参数注解和范例
一. docker hello world 1.1 Dockerfile FROM centos:7.5.1804 MAINTAINER 11@qq.com CMD echo "hello ...
- P7408-[JOI 2021 Final]ダンジョン 3【贪心,树状数组】
正题 题目链接:https://www.luogu.com.cn/problem/P7408 题目大意 一个有\(n+1\)层的地牢,从\(i\)到\(i+1\)层要\(A_i\)点能量,第\(i\) ...
- Sentry 监控 - Distributed Tracing 分布式跟踪
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...
- C++学习笔记:07 类的继承与派生
课程<C++语言程序设计进阶>清华大学 郑莉老师) 基本概念 继承与派生的区别: 继承:保持已有类的特性而构造新类的过程称为继承. 派生:在已有类的基础上新增自己的特性(函数方法.数据成员 ...
- disruptor笔记之八:知识点补充(终篇)
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- B站视频:CocosCreator Bundle 特性三个实例详解,轻松实现大厅子游戏模式
详细内容:https://forum.cocos.org/t/topic/112146
- VirtualBox上安装Debian10个人备忘笔记
准备 VirtualBox 下载链接:Downloads – Oracle VM VirtualBox,下载完成后安装即可. Debian 下载链接:通过 HTTP/FTP 下载 Debian CD/ ...
- 手机淘宝轻店业务 Serverless 研发模式升级实践
一.前言 随着 Serverless 在业界各云平台落地,阿里内部 Serverless 研发平台.各种研发模式也在业务中逐步落地,如火如荼.在此契机下,淘系团队启动了轻店 Serverless 研发 ...