Socket通信协议解析(文章摘要)
参考网址: https://zhuanlan.zhihu.com/p/84800923
在计算机通信领域,socket 被翻译为“套接字”,它是计算机之间进行通信的一种约定或一种方式。通过 socket 这种约定,一台计算机可以接收其他计算机的数据,也可以向其他计算机发送数据。
socket 的典型应用就是 Web 服务器和浏览器:浏览器获取用户输入的URL,向服务器发起请求,服务器分析接收到的URL,将对应的网页内容返回给浏览器,浏览器再经过解析和渲染,就将文字、图片、视频等元素呈现给用户。
学习 socket,也就是学习计算机之间如何通信,并编写出实用的程序。
IP地址(IP Address)
计算机分布在世界各地,要想和它们通信,必须要知道确切的位置。确定计算机位置的方式有多种,IP 地址是最常用的,例如,114.114.114.114 是国内第一个、全球第三个开放的 DNS 服务地址,127.0.0.1 是本机地址。
其实,我们的计算机并不知道 IP 地址对应的地理位置,当要通信时,只是将 IP 地址封装到要发送的数据包中,交给路由器去处理。路由器有非常智能和高效的算法,很快就会找到目标计算机,并将数据包传递给它,完成一次单向通信。
目前大部分软件使用 IPv4 地址,但 IPv6 也正在被人们接受,尤其是在教育网中,已经大量使用。
端口(Port)
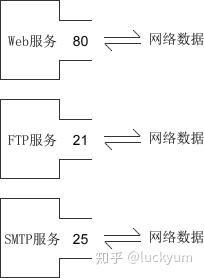
有了 IP 地址,虽然可以找到目标计算机,但仍然不能进行通信。一台计算机可以同时提供多种网络服务,例如Web服务、FTP服务(文件传输服务)、SMTP服务(邮箱服务)等,仅有 IP 地址,计算机虽然可以正确接收到数据包,但是却不知道要将数据包交给哪个网络程序来处理,所以通信失败。
为了区分不同的网络程序,计算机会为每个网络程序分配一个独一无二的端口号(Port Number),例如,Web服务的端口号是 80,FTP 服务的端口号是 21,SMTP 服务的端口号是 25。
端口(Port)是一个虚拟的、逻辑上的概念。可以将端口理解为一道门,数据通过这道门流入流出,每道门有不同的编号,就是端口号。如下图所示:
协议(Protocol)
协议(Protocol)就是网络通信的约定,通信的双方必须都遵守才能正常收发数据。协议有很多种,例如 TCP、UDP、IP 等,通信的双方必须使用同一协议才能通信。协议是一种规范,由计算机组织制定,规定了很多细节,例如,如何建立连接,如何相互识别等。
协议仅仅是一种规范,必须由计算机软件来实现。例如 IP 协议规定了如何找到目标计算机,那么各个开发商在开发自己的软件时就必须遵守该协议,不能另起炉灶。
所谓协议族(Protocol Family),就是一组协议(多个协议)的统称。最常用的是 TCP/IP 协议族,它包含了 TCP、IP、UDP、Telnet、FTP、SMTP 等上百个互为关联的协议,由于 TCP、IP 是两种常用的底层协议,所以把它们统称为 TCP/IP 协议族。
数据传输方式
计算机之间有很多数据传输方式,各有优缺点,常用的有两种:SOCK_STREAM 和 SOCK_DGRAM。
1) SOCK_STREAM 表示面向连接的数据传输方式。数据可以准确无误地到达另一台计算机,如果损坏或丢失,可以重新发送,但效率相对较慢。常见的 http 协议就使用 SOCK_STREAM 传输数据,因为要确保数据的正确性,否则网页不能正常解析。
2) SOCK_DGRAM 表示无连接的数据传输方式。计算机只管传输数据,不作数据校验,如果数据在传输中损坏,或者没有到达另一台计算机,是没有办法补救的。也就是说,数据错了就错了,无法重传。因为 SOCK_DGRAM 所做的校验工作少,所以效率比 SOCK_STREAM 高。
QQ 视频聊天和语音聊天就使用 SOCK_DGRAM 传输数据,因为首先要保证通信的效率,尽量减小延迟,而数据的正确性是次要的,即使丢失很小的一部分数据,视频和音频也可以正常解析,最多出现噪点或杂音,不会对通信质量有实质的影响。
注意:SOCK_DGRAM 没有想象中的糟糕,不会频繁的丢失数据,数据错误只是小概率事件。
有可能多种协议使用同一种数据传输方式,所以在 socket 编程中,需要同时指明数据传输方式和协议。
综上所述:IP地址和端口能够在广袤的互联网中定位到要通信的程序,协议和数据传输方式规定了如何传输数据,有了这些,两台计算机就可以通信了。
socket缓冲区
每个 socket 被创建后,都会分配两个缓冲区,输入缓冲区和输出缓冲区。
write()/send() 并不立即向网络中传输数据,而是先将数据写入缓冲区中,再由TCP协议将数据从缓冲区发送到目标机器。一旦将数据写入到缓冲区,函数就可以成功返回,不管它们有没有到达目标机器,也不管它们何时被发送到网络,这些都是TCP协议负责的事情。
TCP协议独立于 write()/send() 函数,数据有可能刚被写入缓冲区就发送到网络,也可能在缓冲区中不断积压,多次写入的数据被一次性发送到网络,这取决于当时的网络情况、当前线程是否空闲等诸多因素,不由程序员控制。
read()/recv() 函数也是如此,也从输入缓冲区中读取数据,而不是直接从网络中读取。
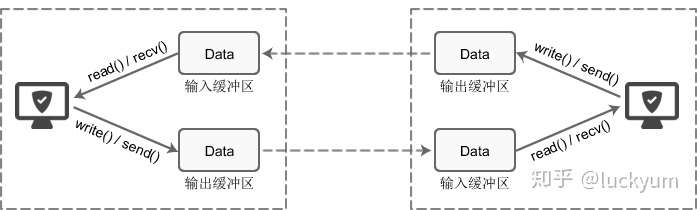
图:TCP套接字的I/O缓冲区示意图
这些I/O缓冲区特性可整理如下:
- I/O缓冲区在每个TCP套接字中单独存在;
- I/O缓冲区在创建套接字时自动生成;
- 即使关闭套接字也会继续传送输出缓冲区中遗留的数据;
- 关闭套接字将丢失输入缓冲区中的数据。
输入输出缓冲区的默认大小一般都是 8K,可以通过 getsockopt() 函数获取:
unsigned optVal;
int optLen = sizeof(int);
getsockopt(servSock, SOL_SOCKET, SO_SNDBUF, (char*)&optVal, &optLen);
printf("Buffer length: %d\n", optVal);运行结果:
Buffer length: 8192
这里仅给出示例,后面会详细讲解。
阻塞模式
对于TCP套接字(默认情况下),当使用 write()/send() 发送数据时:
1) 首先会检查缓冲区,如果缓冲区的可用空间长度小于要发送的数据,那么 write()/send() 会被阻塞(暂停执行),直到缓冲区中的数据被发送到目标机器,腾出足够的空间,才唤醒 write()/send() 函数继续写入数据。
2) 如果TCP协议正在向网络发送数据,那么输出缓冲区会被锁定,不允许写入,write()/send() 也会被阻塞,直到数据发送完毕缓冲区解锁,write()/send() 才会被唤醒。
3) 如果要写入的数据大于缓冲区的最大长度,那么将分批写入。
4) 直到所有数据被写入缓冲区 write()/send() 才能返回。
当使用 read()/recv() 读取数据时:
1) 首先会检查缓冲区,如果缓冲区中有数据,那么就读取,否则函数会被阻塞,直到网络上有数据到来。
2) 如果要读取的数据长度小于缓冲区中的数据长度,那么就不能一次性将缓冲区中的所有数据读出,剩余数据将不断积压,直到有 read()/recv() 函数再次读取。
3) 直到读取到数据后 read()/recv() 函数才会返回,否则就一直被阻塞。
这就是TCP套接字的阻塞模式。所谓阻塞,就是上一步动作没有完成,下一步动作将暂停,直到上一步动作完成后才能继续,以保持同步性。
我们讲到了socket缓冲区和数据的传递过程,可以看到数据的接收和发送是无关的,read()/recv() 函数不管数据发送了多少次,都会尽可能多的接收数据。也就是说,read()/recv() 和 write()/send() 的执行次数可能不同。
例如,write()/send() 重复执行三次,每次都发送字符串"abc",那么目标机器上的 read()/recv() 可能分三次接收,每次都接收"abc";也可能分两次接收,第一次接收"abcab",第二次接收"cabc";也可能一次就接收到字符串"abcabcabc"。
假设我们希望客户端每次发送一位学生的学号,让服务器端返回该学生的姓名、住址、成绩等信息,这时候可能就会出现问题,服务器端不能区分学生的学号。例如第一次发送 1,第二次发送 3,服务器可能当成 13 来处理,返回的信息显然是错误的。
这就是数据的“粘包”问题,客户端发送的多个数据包被当做一个数据包接收。也称数据的无边界性,read()/recv() 函数不知道数据包的开始或结束标志(实际上也没有任何开始或结束标志),只把它们当做连续的数据流来处理。
下面的代码演示了粘包问题,客户端连续三次向服务器端发送数据,服务器端却一次性接收到所有数据。
服务器端代码 server.cpp:
#include <stdio.h>
#include <windows.h>
#pragma comment (lib, "ws2_32.lib") //加载 ws2_32.dll
#define BUF_SIZE 100
int main(){
WSADATA wsaData;
WSAStartup( MAKEWORD(2, 2), &wsaData);
//创建套接字
SOCKET servSock = socket(AF_INET, SOCK_STREAM, 0);
//绑定套接字
sockaddr_in sockAddr;
memset(&sockAddr, 0, sizeof(sockAddr)); //每个字节都用0填充
sockAddr.sin_family = PF_INET; //使用IPv4地址
sockAddr.sin_addr.s_addr = inet_addr("127.0.0.1"); //具体的IP地址
sockAddr.sin_port = htons(1234); //端口
bind(servSock, (SOCKADDR*)&sockAddr, sizeof(SOCKADDR));
//进入监听状态
listen(servSock, 20);
//接收客户端请求
SOCKADDR clntAddr;
int nSize = sizeof(SOCKADDR);
char buffer[BUF_SIZE] = {0}; //缓冲区
SOCKET clntSock = accept(servSock, (SOCKADDR*)&clntAddr, &nSize);
Sleep(10000); //注意这里,让程序暂停10秒
//接收客户端发来的数据,并原样返回
int recvLen = recv(clntSock, buffer, BUF_SIZE, 0);
send(clntSock, buffer, recvLen, 0);
//关闭套接字并终止DLL的使用
closesocket(clntSock);
closesocket(servSock);
WSACleanup();
return 0;
}客户端代码 client.cpp:
#include <stdio.h>
#include <stdlib.h>
#include <WinSock2.h>
#include <windows.h>
#pragma comment(lib, "ws2_32.lib") //加载 ws2_32.dll
#define BUF_SIZE 100
int main(){
//初始化DLL
WSADATA wsaData;
WSAStartup(MAKEWORD(2, 2), &wsaData);
//向服务器发起请求
sockaddr_in sockAddr;
memset(&sockAddr, 0, sizeof(sockAddr)); //每个字节都用0填充
sockAddr.sin_family = PF_INET;
sockAddr.sin_addr.s_addr = inet_addr("127.0.0.1");
sockAddr.sin_port = htons(1234);
//创建套接字
SOCKET sock = socket(PF_INET, SOCK_STREAM, IPPROTO_TCP);
connect(sock, (SOCKADDR*)&sockAddr, sizeof(SOCKADDR));
//获取用户输入的字符串并发送给服务器
char bufSend[BUF_SIZE] = {0};
printf("Input a string: ");
gets(bufSend);
for(int i=0; i<3; i++){
send(sock, bufSend, strlen(bufSend), 0);
}
//接收服务器传回的数据
char bufRecv[BUF_SIZE] = {0};
recv(sock, bufRecv, BUF_SIZE, 0);
//输出接收到的数据
printf("Message form server: %s\n", bufRecv);
closesocket(sock); //关闭套接字
WSACleanup(); //终止使用 DLL
system("pause");
return 0;
}先运行 server,再运行 client,并在10秒内输入字符串"abc",再等数秒,服务器就会返回数据。运行结果如下:
Input a string: abc
Message form server: abcabcabc
本程序的关键是 server.cpp 第31行的代码Sleep(10000);
,它让程序暂停执行10秒。在这段时间内,client 连续三次发送字符串"abc",由于 server 被阻塞,数据只能堆积在缓冲区中,10秒后,server 开始运行,从缓冲区中一次性读出所有积压的数据,并返回给客户端。
另外还需要说明的是 client.cpp 第34行代码。client 执行到 recv() 函数,由于输入缓冲区中没有数据,所以会被阻塞,直到10秒后 server 传回数据才开始执行。用户看到的直观效果就是,client 暂停一段时间才输出 server 返回的结果。
client 的 send() 发送了三个数据包,而 server 的 recv() 却只接收到一个数据包,这很好的说明了数据的粘包问题。
TCP(Transmission Control Protocol,传输控制协议)是一种面向连接的、可靠的、基于字节流的通信协议,数据在传输前要建立连接,传输完毕后还要断开连接。
客户端在收发数据前要使用 connect() 函数和服务器建立连接。建立连接的目的是保证IP地址、端口、物理链路等正确无误,为数据的传输开辟通道。
TCP建立连接时要传输三个数据包,俗称三次握手(Three-way Handshaking)。可以形象的比喻为下面的对话:
- [Shake 1] 套接字A:“你好,套接字B,我这里有数据要传送给你,建立连接吧。”
- [Shake 2] 套接字B:“好的,我这边已准备就绪。”
- [Shake 3] 套接字A:“谢谢你受理我的请求。”
TCP数据报结构
我们先来看一下TCP数据报的结构:
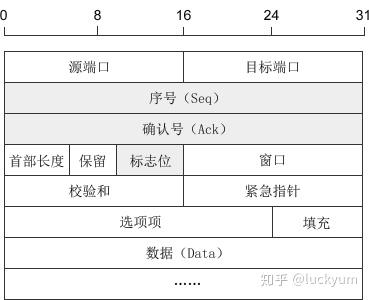
带阴影的几个字段需要重点说明一下:
1) 序号:Seq(Sequence Number)序号占32位,用来标识从计算机A发送到计算机B的数据包的序号,计算机发送数据时对此进行标记。
2) 确认号:Ack(Acknowledge Number)确认号占32位,客户端和服务器端都可以发送,Ack = Seq + 1。
3) 标志位:每个标志位占用1Bit,共有6个,分别为 URG、ACK、PSH、RST、SYN、FIN,具体含义如下:
- URG:紧急指针(urgent pointer)有效。
- ACK:确认序号有效。
- PSH:接收方应该尽快将这个报文交给应用层。
- RST:重置连接。
- SYN:建立一个新连接。
- FIN:断开一个连接。
对英文字母缩写的总结:Seq 是 Sequence 的缩写,表示序列;Ack(ACK) 是 Acknowledge 的缩写,表示确认;SYN 是 Synchronous 的缩写,愿意是“同步的”,这里表示建立同步连接;FIN 是 Finish 的缩写,表示完成。
连接的建立(三次握手)
使用 connect() 建立连接时,客户端和服务器端会相互发送三个数据包,请看下图:
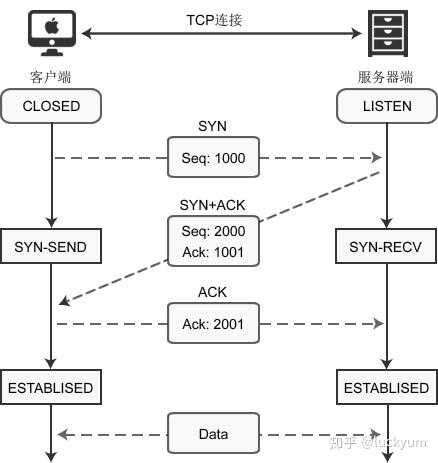
客户端调用 socket() 函数创建套接字后,因为没有建立连接,所以套接字处于CLOSED状态;服务器端调用 listen() 函数后,套接字进入LISTEN
状态,开始监听客户端请求。
这个时候,客户端开始发起请求:
1) 当客户端调用 connect() 函数后,TCP协议会组建一个数据包,并设置 SYN 标志位,表示该数据包是用来建立同步连接的。同时生成一个随机数字 1000,填充“序号(Seq)”字段,表示该数据包的序号。完成这些工作,开始向服务器端发送数据包,客户端就进入了SYN-SEND
状态。
2) 服务器端收到数据包,检测到已经设置了 SYN 标志位,就知道这是客户端发来的建立连接的“请求包”。服务器端也会组建一个数据包,并设置 SYN 和 ACK 标志位,SYN 表示该数据包用来建立连接,ACK 用来确认收到了刚才客户端发送的数据包。
服务器生成一个随机数 2000,填充“序号(Seq)”字段。2000 和客户端数据包没有关系。
服务器将客户端数据包序号(1000)加1,得到1001,并用这个数字填充“确认号(Ack)”字段。
服务器将数据包发出,进入SYN-RECV
状态。
3) 客户端收到数据包,检测到已经设置了 SYN 和 ACK 标志位,就知道这是服务器发来的“确认包”。客户端会检测“确认号(Ack)”字段,看它的值是否为 1000+1,如果是就说明连接建立成功。
接下来,客户端会继续组建数据包,并设置 ACK 标志位,表示客户端正确接收了服务器发来的“确认包”。同时,将刚才服务器发来的数据包序号(2000)加1,得到 2001,并用这个数字来填充“确认号(Ack)”字段。
客户端将数据包发出,进入ESTABLISED
状态,表示连接已经成功建立。
4) 服务器端收到数据包,检测到已经设置了 ACK 标志位,就知道这是客户端发来的“确认包”。服务器会检测“确认号(Ack)”字段,看它的值是否为 2000+1,如果是就说明连接建立成功,服务器进入ESTABLISED
状态。
至此,客户端和服务器都进入了ESTABLISED状态,连接建立成功,接下来就可以收发数据了。
最后的说明
三次握手的关键是要确认对方收到了自己的数据包,这个目标就是通过“确认号(Ack)”字段实现的。计算机会记录下自己发送的数据包序号 Seq,待收到对方的数据包后,检测“确认号(Ack)”字段,看Ack = Seq + 1是否成立,如果成立说明对方正确收到了自己的数据包。
建立连接后,两台主机就可以相互传输数据了。如下图所示:
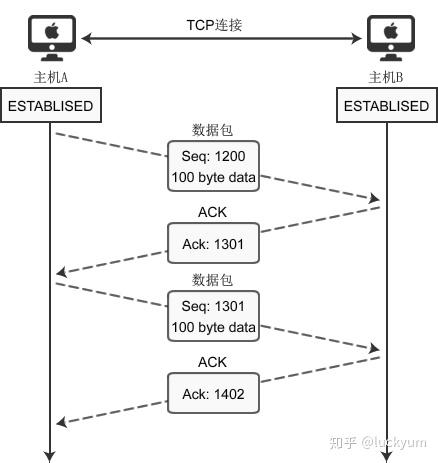
图1:TCP 套接字的数据交换过程
上图给出了主机A分2次(分2个数据包)向主机B传递200字节的过程。首先,主机A通过1个数据包发送100个字节的数据,数据包的 Seq 号设置为 1200。主机B为了确认这一点,向主机A发送 ACK 包,并将 Ack 号设置为 1301。
为了保证数据准确到达,目标机器在收到数据包(包括SYN包、FIN包、普通数据包等)包后必须立即回传ACK包,这样发送方才能确认数据传输成功。
此时 Ack 号为 1301 而不是 1201,原因在于 Ack 号的增量为传输的数据字节数。假设每次 Ack 号不加传输的字节数,这样虽然可以确认数据包的传输,但无法明确100字节全部正确传递还是丢失了一部分,比如只传递了80字节。因此按如下的公式确认 Ack 号:
Ack号 = Seq号 + 传递的字节数 + 1
与三次握手协议相同,最后加 1 是为了告诉对方要传递的 Seq 号。
下面分析传输过程中数据包丢失的情况,如下图所示:
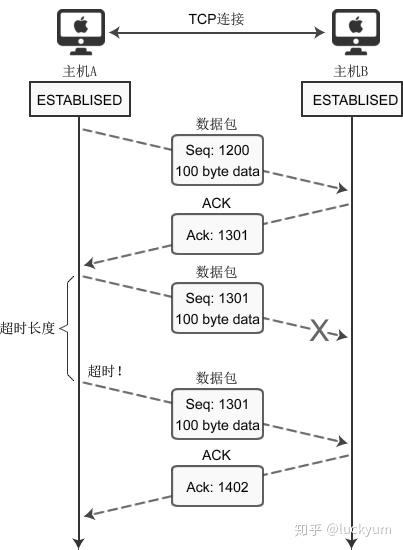
图2:TCP套接字数据传输过程中发生错误
上图表示通过 Seq 1301 数据包向主机B传递100字节的数据,但中间发生了错误,主机B未收到。经过一段时间后,主机A仍未收到对于 Seq 1301 的ACK确认,因此尝试重传数据。
为了完成数据包的重传,TCP套接字每次发送数据包时都会启动定时器,如果在一定时间内没有收到目标机器传回的 ACK 包,那么定时器超时,数据包会重传。
上图演示的是数据包丢失的情况,也会有 ACK 包丢失的情况,一样会重传。
重传超时时间(RTO, Retransmission Time Out)
这个值太大了会导致不必要的等待,太小会导致不必要的重传,理论上最好是网络 RTT 时间,但又受制于网络距离与瞬态时延变化,所以实际上使用自适应的动态算法(例如 Jacobson 算法和 Karn 算法等)来确定超时时间。
往返时间(RTT,Round-Trip Time)表示从发送端发送数据开始,到发送端收到来自接收端的 ACK 确认包(接收端收到数据后便立即确认),总共经历的时延。
重传次数
TCP数据包重传次数根据系统设置的不同而有所区别。有些系统,一个数据包只会被重传3次,如果重传3次后还未收到该数据包的 ACK 确认,就不再尝试重传。但有些要求很高的业务系统,会不断地重传丢失的数据包,以尽最大可能保证业务数据的正常交互。
建立连接非常重要,它是数据正确传输的前提;断开连接同样重要,它让计算机释放不再使用的资源。如果连接不能正常断开,不仅会造成数据传输错误,还会导致套接字不能关闭,持续占用资源,如果并发量高,服务器压力堪忧。
建立连接需要三次握手,断开连接需要四次握手,可以形象的比喻为下面的对话:
- [Shake 1] 套接字A:“任务处理完毕,我希望断开连接。”
- [Shake 2] 套接字B:“哦,是吗?请稍等,我准备一下。”
- 等待片刻后……
- [Shake 3] 套接字B:“我准备好了,可以断开连接了。”
- [Shake 4] 套接字A:“好的,谢谢合作。”
下图演示了客户端主动断开连接的场景:
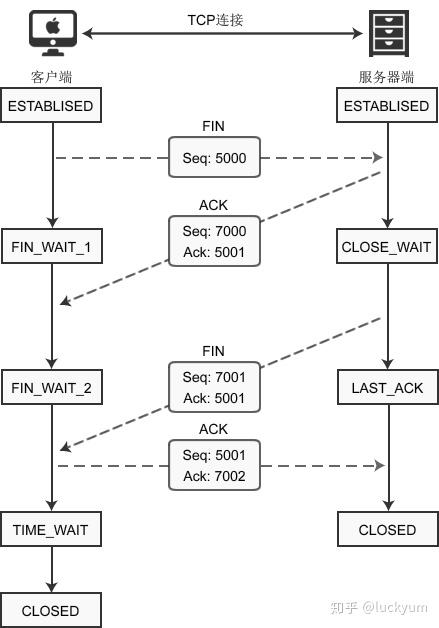
建立连接后,客户端和服务器都处于ESTABLISED状态。这时,客户端发起断开连接的请求:
1) 客户端调用 close() 函数后,向服务器发送 FIN 数据包,进入FIN_WAIT_1
状态。FIN 是 Finish 的缩写,表示完成任务需要断开连接。
2) 服务器收到数据包后,检测到设置了 FIN 标志位,知道要断开连接,于是向客户端发送“确认包”,进入CLOSE_WAIT
状态。
注意:服务器收到请求后并不是立即断开连接,而是先向客户端发送“确认包”,告诉它我知道了,我需要准备一下才能断开连接。
3) 客户端收到“确认包”后进入FIN_WAIT_2
状态,等待服务器准备完毕后再次发送数据包。
4) 等待片刻后,服务器准备完毕,可以断开连接,于是再主动向客户端发送 FIN 包,告诉它我准备好了,断开连接吧。然后进入LAST_ACK
状态。
5) 客户端收到服务器的 FIN 包后,再向服务器发送 ACK 包,告诉它你断开连接吧。然后进入TIME_WAIT
状态。
6) 服务器收到客户端的 ACK 包后,就断开连接,关闭套接字,进入CLOSED状态。
关于 TIME_WAIT 状态的说明
客户端最后一次发送 ACK包后进入 TIME_WAIT 状态,而不是直接进入 CLOSED 状态关闭连接,这是为什么呢?
TCP 是面向连接的传输方式,必须保证数据能够正确到达目标机器,不能丢失或出错,而网络是不稳定的,随时可能会毁坏数据,所以机器A每次向机器B发送数据包后,都要求机器B”确认“,回传ACK包,告诉机器A我收到了,这样机器A才能知道数据传送成功了。如果机器B没有回传ACK包,机器A会重新发送,直到机器B回传ACK包。
客户端最后一次向服务器回传ACK包时,有可能会因为网络问题导致服务器收不到,服务器会再次发送 FIN 包,如果这时客户端完全关闭了连接,那么服务器无论如何也收不到ACK包了,所以客户端需要等待片刻、确认对方收到ACK包后才能进入CLOSED状态。那么,要等待多久呢?
数据包在网络中是有生存时间的,超过这个时间还未到达目标主机就会被丢弃,并通知源主机。这称为报文最大生存时间(MSL,Maximum Segment Lifetime)。TIME_WAIT 要等待 2MSL 才会进入 CLOSED 状态。ACK 包到达服务器需要 MSL 时间,服务器重传 FIN 包也需要 MSL 时间,2MSL 是数据包往返的最大时间,如果 2MSL 后还未收到服务器重传的 FIN 包,就说明服务器已经收到了 ACK 包。
我们来完成 socket 文件传输程序,这是一个非常实用的例子。要实现的功能为:client 从 server 下载一个文件并保存到本地。
编写这个程序需要注意两个问题:
1) 文件大小不确定,有可能比缓冲区大很多,调用一次 write()/send() 函数不能完成文件内容的发送。接收数据时也会遇到同样的情况。
要解决这个问题,可以使用 while 循环,例如:
- //Server 代码
- int nCount;
- while( (nCount = fread(buffer, 1, BUF_SIZE, fp)) > 0 ){
- send(sock, buffer, nCount, 0);
- }
- //Client 代码
- int nCount;
- while( (nCount = recv(clntSock, buffer, BUF_SIZE, 0)) > 0 ){
- fwrite(buffer, nCount, 1, fp);
- }
对于 Server 端的代码,当读取到文件末尾,fread() 会返回 0,结束循环。
对于 Client 端代码,有一个关键的问题,就是文件传输完毕后让 recv() 返回 0,结束 while 循环。
注意:读取完缓冲区中的数据 recv() 并不会返回 0,而是被阻塞,直到缓冲区中再次有数据。
2) Client 端如何判断文件接收完毕,也就是上面提到的问题——何时结束 while 循环。
最简单的结束 while 循环的方法当然是文件接收完毕后让 recv() 函数返回 0,那么,如何让 recv() 返回 0 呢?recv() 返回 0 的唯一时机就是收到FIN包时。
FIN 包表示数据传输完毕,计算机收到 FIN 包后就知道对方不会再向自己传输数据,当调用 read()/recv() 函数时,如果缓冲区中没有数据,就会返回 0,表示读到了”socket文件的末尾“。
这里我们调用 shutdown() 来发送FIN包:server 端直接调用 close()/closesocket() 会使输出缓冲区中的数据失效,文件内容很有可能没有传输完毕连接就断开了,而调用 shutdown() 会等待输出缓冲区中的数据传输完毕。
本节以Windows为例演示文件传输功能,Linux与此类似,不再赘述。请看下面完整的代码。
服务器端 server.cpp:
#include <stdio.h>
#include <stdlib.h>
#include <winsock2.h>
#pragma comment (lib, "ws2_32.lib") //加载 ws2_32.dll
#define BUF_SIZE 1024
int main(){
//先检查文件是否存在
char *filename = "D:\\send.avi"; //文件名
FILE *fp = fopen(filename, "rb"); //以二进制方式打开文件
if(fp == NULL){
printf("Cannot open file, press any key to exit!\n");
system("pause");
exit(0);
}
WSADATA wsaData;
WSAStartup( MAKEWORD(2, 2), &wsaData);
SOCKET servSock = socket(AF_INET, SOCK_STREAM, 0);
sockaddr_in sockAddr;
memset(&sockAddr, 0, sizeof(sockAddr));
sockAddr.sin_family = PF_INET;
sockAddr.sin_addr.s_addr = inet_addr("127.0.0.1");
sockAddr.sin_port = htons(1234);
bind(servSock, (SOCKADDR*)&sockAddr, sizeof(SOCKADDR));
listen(servSock, 20);
SOCKADDR clntAddr;
int nSize = sizeof(SOCKADDR);
SOCKET clntSock = accept(servSock, (SOCKADDR*)&clntAddr, &nSize);
//循环发送数据,直到文件结尾
char buffer[BUF_SIZE] = {0}; //缓冲区
int nCount;
while( (nCount = fread(buffer, 1, BUF_SIZE, fp)) > 0 ){
send(clntSock, buffer, nCount, 0);
}
shutdown(clntSock, SD_SEND); //文件读取完毕,断开输出流,向客户端发送FIN包
recv(clntSock, buffer, BUF_SIZE, 0); //阻塞,等待客户端接收完毕
fclose(fp);
closesocket(clntSock);
closesocket(servSock);
WSACleanup();
system("pause");
return 0;
}客户端代码:
#include <stdio.h>
#include <stdlib.h>
#include <WinSock2.h>
#pragma comment(lib, "ws2_32.lib")
#define BUF_SIZE 1024
int main(){
//先输入文件名,看文件是否能创建成功
char filename[100] = {0}; //文件名
printf("Input filename to save: ");
gets(filename);
FILE *fp = fopen(filename, "wb"); //以二进制方式打开(创建)文件
if(fp == NULL){
printf("Cannot open file, press any key to exit!\n");
system("pause");
exit(0);
}
WSADATA wsaData;
WSAStartup(MAKEWORD(2, 2), &wsaData);
SOCKET sock = socket(PF_INET, SOCK_STREAM, IPPROTO_TCP);
sockaddr_in sockAddr;
memset(&sockAddr, 0, sizeof(sockAddr));
sockAddr.sin_family = PF_INET;
sockAddr.sin_addr.s_addr = inet_addr("127.0.0.1");
sockAddr.sin_port = htons(1234);
connect(sock, (SOCKADDR*)&sockAddr, sizeof(SOCKADDR));
//循环接收数据,直到文件传输完毕
char buffer[BUF_SIZE] = {0}; //文件缓冲区
int nCount;
while( (nCount = recv(sock, buffer, BUF_SIZE, 0)) > 0 ){
fwrite(buffer, nCount, 1, fp);
}
puts("File transfer success!");
//文件接收完毕后直接关闭套接字,无需调用shutdown()
fclose(fp);
closesocket(sock);
WSACleanup();
system("pause");
return 0;
}在D盘中准备好send.avi文件,先运行 server,再运行 client:
Input filename to save: D:\\recv.avi
//稍等片刻后
File transfer success!
打开D盘就可以看到 recv.avi,大小和 send.avi 相同,可以正常播放。
注意 server.cpp 第42行代码,recv() 并没有接收到 client 端的数据,当 client 端调用 closesocket() 后,server 端会收到FIN包,recv() 就会返回,后面的代码继续执行。
不同CPU中,4字节整数1在内存空间的存储方式是不同的。4字节整数1可用2进制表示如下:
00000000 00000000 00000000 00000001
有些CPU以上面的顺序存储到内存,另外一些CPU则以倒序存储,如下所示:
00000001 00000000 00000000 00000000
若不考虑这些就收发数据会发生问题,因为保存顺序的不同意味着对接收数据的解析顺序也不同。
大端序和小端序
CPU向内存保存数据的方式有两种:
- 大端序(Big Endian):高位字节存放到低位地址(高位字节在前)。
- 小端序(Little Endian):高位字节存放到高位地址(低位字节在前)。
仅凭描述很难解释清楚,不妨来看一个实例。假设在 0x20 号开始的地址中保存4字节 int 型数据 0x12345678,大端序CPU保存方式如下图所示:

图1:整数 0x12345678 的大端序字节表示
对于大端序,最高位字节 0x12 存放到低位地址,最低位字节 0x78 存放到高位地址。小端序的保存方式如下图所示:

图2:整数 0x12345678 的小端序字节表示
不同CPU保存和解析数据的方式不同(主流的Intel系列CPU为小端序),小端序系统和大端序系统通信时会发生数据解析错误。因此在发送数据前,要将数据转换为统一的格式——网络字节序(Network Byte Order)。网络字节序统一为大端序。
主机A先把数据转换成大端序再进行网络传输,主机B收到数据后先转换为自己的格式再解析。
网络字节序转换函数
在《使用bind()和connect()函数》一节中讲解了 sockaddr_in 结构体,其中就用到了网络字节序转换函数,如下所示:
//创建sockaddr_in结构体变量
struct sockaddr_in serv_addr;
memset(&serv_addr, 0, sizeof(serv_addr)); //每个字节都用0填充
serv_addr.sin_family = AF_INET; //使用IPv4地址
serv_addr.sin_addr.s_addr = inet_addr("127.0.0.1"); //具体的IP地址
serv_addr.sin_port = htons(1234); //端口号htons() 用来将当前主机字节序转换为网络字节序,其中h代表主机(host)字节序,n代表网络(network)字节序,s
代表short,htons 是 h、to、n、s 的组合,可以理解为”将short型数据从当前主机字节序转换为网络字节序“。
常见的网络字节转换函数有:
- htons():host to network short,将short类型数据从主机字节序转换为网络字节序。
- ntohs():network to host short,将short类型数据从网络字节序转换为主机字节序。
- htonl():host to network long,将long类型数据从主机字节序转换为网络字节序。
- ntohl():network to host long,将long类型数据从网络字节序转换为主机字节序。
通常,以s为后缀的函数中,s代表2个字节short,因此用于端口号转换;以l为后缀的函数中,l
代表4个字节的long,因此用于IP地址转换。
举例说明上述函数的调用过程:
#include <stdio.h>
#include <stdlib.h>
#include <WinSock2.h>
#pragma comment(lib, "ws2_32.lib")
int main(){
unsigned short host_port = 0x1234, net_port;
unsigned long host_addr = 0x12345678, net_addr;
net_port = htons(host_port);
net_addr = htonl(host_addr);
printf("Host ordered port: %#x\n", host_port);
printf("Network ordered port: %#x\n", net_port);
printf("Host ordered address: %#lx\n", host_addr);
printf("Network ordered address: %#lx\n", net_addr);
system("pause");
return 0;
}运行结果:
Host ordered port: 0x1234
Network ordered port: 0x3412
Host ordered address: 0x12345678
Network ordered address: 0x78563412
另外需要说明的是,sockaddr_in 中保存IP地址的成员为32位整数,而我们熟悉的是点分十进制表示法,例如 127.0.0.1,它是一个字符串,因此为了分配IP地址,需要将字符串转换为4字节整数。
inet_addr() 函数可以完成这种转换。inet_addr() 除了将字符串转换为32位整数,同时还进行网络字节序转换。请看下面的代码:
#include <stdio.h>
#include <stdlib.h>
#include <WinSock2.h>
#pragma comment(lib, "ws2_32.lib")
int main(){
char *addr1 = "1.2.3.4";
char *addr2 = "1.2.3.256";
unsigned long conv_addr = inet_addr(addr1);
if(conv_addr == INADDR_NONE){
puts("Error occured!");
}else{
printf("Network ordered integer addr: %#lx\n", conv_addr);
}
conv_addr = inet_addr(addr2);
if(conv_addr == INADDR_NONE){
puts("Error occured!");
}else{
printf("Network ordered integer addr: %#lx\n", conv_addr);
}
system("pause");
return 0;
}运行结果:
Network ordered integer addr: 0x4030201
Error occured!
从运行结果可以看出,inet_addr() 不仅可以把IP地址转换为32位整数,还可以检测无效IP地址。
注意:为 sockaddr_in 成员赋值时需要显式地将主机字节序转换为网络字节序,而通过 write()/send() 发送数据时TCP协议会自动转换为网络字节序,不需要再调用相应的函数。
TCP 是面向连接的传输协议,建立连接时要经过三次握手,断开连接时要经过四次握手,中间传输数据时也要回复ACK包确认,多种机制保证了数据能够正确到达,不会丢失或出错。
UDP 是非连接的传输协议,没有建立连接和断开连接的过程,它只是简单地把数据丢到网络中,也不需要ACK包确认。
UDP 传输数据就好像我们邮寄包裹,邮寄前需要填好寄件人和收件人地址,之后送到快递公司即可,但包裹是否正确送达、是否损坏我们无法得知,也无法保证。UDP 协议也是如此,它只管把数据包发送到网络,然后就不管了,如果数据丢失或损坏,发送端是无法知道的,当然也不会重发。
既然如此,TCP应该是更加优质的传输协议吧?
如果只考虑可靠性,TCP的确比UDP好。但UDP在结构上比TCP更加简洁,不会发送ACK的应答消息,也不会给数据包分配Seq序号,所以UDP的传输效率有时会比TCP高出很多,编程中实现UDP也比TCP简单。
UDP 的可靠性虽然比不上TCP,但也不会像想象中那么频繁地发生数据损毁,在更加重视传输效率而非可靠性的情况下,UDP是一种很好的选择。比如视频通信或音频通信,就非常适合采用UDP协议;通信时数据必须高效传输才不会产生“卡顿”现象,用户体验才更加流畅,如果丢失几个数据包,视频画面可能会出现“雪花”,音频可能会夹带一些杂音,这些都是无妨的。
与UDP相比,TCP的生命在于流控制,这保证了数据传输的正确性。
最后需要说明的是:TCP的速度无法超越UDP,但在收发某些类型的数据时有可能接近UDP。例如,每次交换的数据量越大,TCP 的传输速率就越接近于 UDP。
前面的文章中我们给出了几个TCP的例子,对于UDP而言,只要能理解前面的内容,实现并非难事。
UDP中的服务器端和客户端没有连接
UDP不像TCP,无需在连接状态下交换数据,因此基于UDP的服务器端和客户端也无需经过连接过程。也就是说,不必调用 listen() 和 accept() 函数。UDP中只有创建套接字的过程和数据交换的过程。
UDP服务器端和客户端均只需1个套接字
TCP中,套接字是一对一的关系。如要向10个客户端提供服务,那么除了负责监听的套接字外,还需要创建10套接字。但在UDP中,不管是服务器端还是客户端都只需要1个套接字。之前解释UDP原理的时候举了邮寄包裹的例子,负责邮寄包裹的快递公司可以比喻为UDP套接字,只要有1个快递公司,就可以通过它向任意地址邮寄包裹。同样,只需1个UDP套接字就可以向任意主机传送数据。
基于UDP的接收和发送函数
创建好TCP套接字后,传输数据时无需再添加地址信息,因为TCP套接字将保持与对方套接字的连接。换言之,TCP套接字知道目标地址信息。但UDP套接字不会保持连接状态,每次传输数据都要添加目标地址信息,这相当于在邮寄包裹前填写收件人地址。
发送数据使用 sendto() 函数:
- ssize_t sendto(int sock, void *buf, size_t nbytes, int flags, struct sockaddr *to, socklen_t addrlen); //Linux
- int sendto(SOCKET sock, const char *buf, int nbytes, int flags, conststruct sockadr *to, int addrlen); //Windows
Linux和Windows下的 sendto() 函数类似,下面是详细参数说明:
- sock:用于传输UDP数据的套接字;
- buf:保存待传输数据的缓冲区地址;
- nbytes:带传输数据的长度(以字节计);
- flags:可选项参数,若没有可传递0;
- to:存有目标地址信息的 sockaddr 结构体变量的地址;
- addrlen:传递给参数 to 的地址值结构体变量的长度。
UDP 发送函数 sendto() 与TCP发送函数 write()/send() 的最大区别在于,sendto() 函数需要向他传递目标地址信息。
接收数据使用 recvfrom() 函数:
- ssize_t recvfrom(int sock, void *buf, size_t nbytes, int flags, struct sockadr *from, socklen_t *addrlen); //Linux
- int recvfrom(SOCKET sock, char *buf, int nbytes, int flags, conststruct sockaddr *from, int *addrlen); //Windows
由于UDP数据的发送端不不定,所以 recvfrom() 函数定义为可接收发送端信息的形式,具体参数如下:
- sock:用于接收UDP数据的套接字;
- buf:保存接收数据的缓冲区地址;
- nbytes:可接收的最大字节数(不能超过buf缓冲区的大小);
- flags:可选项参数,若没有可传递0;
- from:存有发送端地址信息的sockaddr结构体变量的地址;
- addrlen:保存参数 from 的结构体变量长度的变量地址值。
基于UDP的回声服务器端/客户端
下面结合之前的内容实现回声客户端。需要注意的是,UDP不同于TCP,不存在请求连接和受理过程,因此在某种意义上无法明确区分服务器端和客户端,只是因为其提供服务而称为服务器端,希望各位读者不要误解。
下面给出Windows下的代码,Linux与此类似,不再赘述。
服务器端 server.cpp:
#include <stdio.h>
#include <winsock2.h>
#pragma comment (lib, "ws2_32.lib") //加载 ws2_32.dll
#define BUF_SIZE 100
int main(){
WSADATA wsaData;
WSAStartup( MAKEWORD(2, 2), &wsaData);
//创建套接字
SOCKET sock = socket(AF_INET, SOCK_DGRAM, 0);
//绑定套接字
sockaddr_in servAddr;
memset(&servAddr, 0, sizeof(servAddr)); //每个字节都用0填充
servAddr.sin_family = PF_INET; //使用IPv4地址
servAddr.sin_addr.s_addr = htonl(INADDR_ANY); //自动获取IP地址
servAddr.sin_port = htons(1234); //端口
bind(sock, (SOCKADDR*)&servAddr, sizeof(SOCKADDR));
//接收客户端请求
SOCKADDR clntAddr; //客户端地址信息
int nSize = sizeof(SOCKADDR);
char buffer[BUF_SIZE]; //缓冲区
while(1){
int strLen = recvfrom(sock, buffer, BUF_SIZE, 0, &clntAddr, &nSize);
sendto(sock, buffer, strLen, 0, &clntAddr, nSize);
}
closesocket(sock);
WSACleanup();
return 0;
}代码说明:
1) 第12行代码在创建套接字时,向 socket() 第二个参数传递 SOCK_DGRAM,以指明使用UDP协议。
2) 第18行代码中使用htonl(INADDR_ANY)
来自动获取IP地址。
利用常数 INADDR_ANY 自动获取IP地址有一个明显的好处,就是当软件安装到其他服务器或者服务器IP地址改变时,不用再更改源码重新编译,也不用在启动软件时手动输入。而且,如果一台计算机中已分配多个IP地址(例如路由器),那么只要端口号一致,就可以从不同的IP地址接收数据。所以,服务器中优先考虑使用INADDR_ANY;而客户端中除非带有一部分服务器功能,否则不会采用。
客户端 client.cpp:
#include <stdio.h>
#include <WinSock2.h>
#pragma comment(lib, "ws2_32.lib") //加载 ws2_32.dll
#define BUF_SIZE 100
int main(){
//初始化DLL
WSADATA wsaData;
WSAStartup(MAKEWORD(2, 2), &wsaData);
//创建套接字
SOCKET sock = socket(PF_INET, SOCK_DGRAM, 0);
//服务器地址信息
sockaddr_in servAddr;
memset(&servAddr, 0, sizeof(servAddr)); //每个字节都用0填充
servAddr.sin_family = PF_INET;
servAddr.sin_addr.s_addr = inet_addr("127.0.0.1");
servAddr.sin_port = htons(1234);
//不断获取用户输入并发送给服务器,然后接受服务器数据
sockaddr fromAddr;
int addrLen = sizeof(fromAddr);
while(1){
char buffer[BUF_SIZE] = {0};
printf("Input a string: ");
gets(buffer);
sendto(sock, buffer, strlen(buffer), 0, (struct sockaddr*)&servAddr, sizeof(servAddr));
int strLen = recvfrom(sock, buffer, BUF_SIZE, 0, &fromAddr, &addrLen);
buffer[strLen] = 0;
printf("Message form server: %s\n", buffer);
}
closesocket(sock);
WSACleanup();
return 0;
}先运行 server,再运行 client,client 输出结果为:
Input a string: C语言中文网
Message form server: C语言中文网
Input a string: http://c.biancheng.net Founded in 2012
Message form server: http://c.biancheng.net Founded in 2012
Input a string:
从代码中可以看出,server.cpp 中没有使用 listen() 函数,client.cpp 中也没有使用 connect() 函数,因为 UDP 不需要连接。
Socket通信协议解析(文章摘要)的更多相关文章
- Django HTML 显示文章摘要
在用Django写个人博客,发现一般都是标题加上文章摘要,然后点击标题可以看详细内容.这样主页就可以多显示几篇文章. 那么就要用到文章摘要功能. 比如要100个字的文章摘要,就可以这样写: {{art ...
- wordpress自动截取文章摘要代码
想要实现 wordpress 首页显示摘要有几种方法: 第一种,可以在写文章的时侯在需要分割的地方加入<!–more–>标签,但在输出首页摘要的同时,也会使feed只显示摘要,不方便读者阅 ...
- dedecms首页调用的简介一直修改不了是自动文章摘要在作怪
一位美女问:dedecms首页调用的简介一直修改不了,ytkah让她到具体的文章修改,然后再重新生成一下首页.她说还是不行.那就奇了怪了,点击到具体的文章页面是显示已经修改好了,为什么首页还是原来的呢 ...
- dede文章摘要字数的设置方法
本文转自:http://blog.csdn.net/yxwmzouzou/article/details/17491991 在织梦系统中(针对5.7版本),文章摘要(可以通过以下四种相关标签调用)被设 ...
- WordPress批量修改文章内容、URL链接、文章摘要
通过SQL语句来批量修改wordpress博客内容,文章中所有语句都使用默认的wp_表前缀,如果您的数据表前缀不是wp_则需要在语句中作相应更改. 方法/步骤 批量修改文章内容 如果您想替换之前写 ...
- DEDECMS织梦文章摘要批量更改方法
我们建站有时候需要直接把数据库导入,只要修改一下基本的名称信息就可以直接用,但是遇用到一些问题.比如文章摘要不会随着文章内容的更新而更新.织梦(dede)在添加文章的时候会自动生成文章摘要,如果重新修 ...
- 【Common】NO.81.Note.1.Common.1.002-【文章摘要】
1.0.0 Summary Tittle:[Common]NO.81.Note.1.Common.1.002-[文章摘要] Style:Common Series:Common Since:2018- ...
- django 使用内建过滤器实现文章摘要效果
django 使用内建过滤器实现文章摘要效果 前端html代码 <div class="list-group"> {% if articles %} {% for ar ...
- wordpress调用文章摘要,若无摘要则自动截取文章内容字数做为摘要
以下是调用指定分类文章列表的一个方法,作者如果有填写文章摘要则直接调用摘要:如果文章摘要忘记写了则自动截取文章内容字数做为摘要.这个方法也适用于调用description标签 <ul> & ...
随机推荐
- [转载]API网关
1. 使用API网关统一应用入口 API网关的核心设计理念是使用一个轻量级的消息网关作为所有客户端的应用入口,并且在 API 网关层面上实现通用的非功能性需求.如下图所示:所有的服务通过 API 网关 ...
- Selenium执行完毕未关闭chromedriver/geckodriver进程的解决办法(java版+python版)
selenium操作chrome浏览器需要有ChromeDriver驱动来协助.webdriver中关浏览器关闭有两个方法,一个叫quit,一个叫close. 1 /** 2 * Close the ...
- Kubernetes全栈架构师(二进制高可用安装k8s集群部署篇)--学习笔记
目录 二进制高可用基本配置 二进制系统和内核升级 二进制基本组件安装 二进制生成证书详解 二进制高可用及etcd配置 二进制K8s组件配置 二进制使用Bootstrapping自动颁发证书 二进制No ...
- 测试管理工具 - Tuleap部署和安装使用教程
安装 通过CentOS的安装,非常简单,命令直接为pip install tuleap 部署 登录管理员权限 登录名为中文名拼音,如wuweiping. 设置的默认密码为12345678,也可以进入配 ...
- Grafana、Prometheus、mtail-日志监控
一:日志如何监控 在上一篇博客Grafana.Prometheus-监控平台中,简单了解了Grafana与Prometheus对项目做特定的监控打点,可视化的配置操作. 但是对于没有设置监控或者不容易 ...
- 【深度学习】在linux和windows下anaconda+pycharm+tensorflow+cuda的配置
在linux和windows下anaconda+pycharm+tensorflow+cuda的配置 在linux和windows下anaconda+pycharm+tensorflow+cuda的配 ...
- div标签width:auto无效
1,因为div标签默认是display:block,独占一行,宽度为父元素的100%,但是高度是auto,跟随内部内容而定.所以要想 设值父元素随子元素的宽高,那么就要设置div标签为display: ...
- python基础之列表推导式
#列表推导式 ---> 返回的是列表 for语句 效率更高# 1*1 2*2 3*3 4*4 5*5 6*6 7*7 8*8 9*9# import time# to = time.clock( ...
- 国产深度学习框架mindspore-1.3.0 gpu版本无法进行源码编译
官网地址: https://www.mindspore.cn/install 所有依赖环境 进行sudo make install 安装,最终报错: 错误记录信息: cat /tmp/mind ...
- JavaScript实现拖放效果
JavaScript实现拖放效果 笔者实现该效果也是套用别人的轮子的.传送门 然后厚颜无耻的贴别人的readme~,笔者为了方便查阅就直接贴了,有不想移步的可以看这篇.不过还是最好请到原作者的GitH ...