C语言 使用char字符实现汉字处理
- 系统:windows 64
- 编译器:gcc version 8.1.0 (x86_64-posix-seh-rev0, Built by MinGW-W64 project)
- 文本编辑器:notepad
- 控制台:Cmder
- 编程语言:C、Python
首先,要想打印汉字,必须考虑到编码问题。在windows下,由于系统使用GBK编码,而GCC解析时使用UTF-8而会导致以下代码运行时出现乱码:

#include <stdio.h> int main()
{
char *str = "你好,世界!"; printf("%s\n", str); return 0;
}

解决方法为:使用“-fexec-charset=gbk”命令
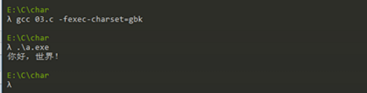
解决了编码问题,我们还需要了解几点:
- char类型本质上是数字,占据一个字节(即八位),可以通过%d打印编码,通过%c打印字符
- 在C语言中,一个汉字占据两个char类型
- 汉字的两个char类型为负数
- 在打印汉字时,它的两个char必须紧跟着
根据这几点,我们可以打印出汉字以及它们的编码:
#include <stdio.h>
#include <string.h> int main()
{
// str为字符指针,指向一个字符字面量,这个字符字面量由'\0'结尾
char *str = "你好,世界!Hello, world!";
// chr为字符指针,指向str所指向的字符字面量的第一个字符的地址,即'你'字符的两个char中的第一个
char *chr = str; printf("%zu %s\n", strlen(str), str);
// 如果遇到'\0',说明字符串结束了
while (*chr != '\0')
{
// 如果chr的编码为负数,则说明遇到了一个汉字
if (*chr < 0)
{
// 打印汉字及汉字的编码
// 注意两个char必须紧紧跟着打印(%c%c),否则会打印出 ??
printf("%c%c: %d%d\n", *chr, *(chr+1), *(chr), *(chr+1));
// chr自增两个字节(因为每个汉字都由两个char组成)
chr += 2;
}
else
{
// 打印英文字符
printf("%c: %d\n", *chr, *chr);
// chr自增一个字节
++chr;
}
} return 0;
}
从上图,我们可以看出,这个字符串占据了25个字节,4个汉字加2个全角符号占据了12个字节,再加上23个英文字符,总共25个字节。我们可以从下图更清晰地看出str的构造:

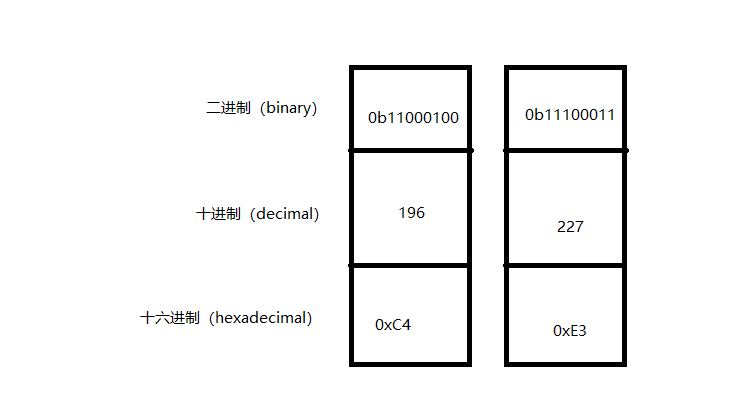
但是,根据我们在网上查询的结果,汉字‘你’的GBK编码应为:C4E3,但是在这里,却打印出了:-60-29,这是为什么呢?

这里涉及到进制的问题,可能-60-29是十六进制数C4E3的十进制数?
首先,我们先通过Python看看C4E3的二进制数以及十进制数。这好像跟-60-29根本不沾边。
我们先看看下面的代码,导入<limits.h>头文件,看看char类型的取值范围为多少:
#include <stdio.h>
#include <limits.h> int main()
{
printf("[%d ~ %d]\n", CHAR_MIN, CHAR_MAX);
printf("%c%c\n", 0xC4, 0xE3);return 0;
}

我们可以看到:char类型的取值范围为[-128 ~ 127],但是我们却可以打印出汉字”你“。这是为什么呢?明明char的取值范围最多127,而汉字“你”的两个字符分别为:196和227,都超过了这个值。其实这是因为,C语言将这两个数字的二进制数作为负数处理。C中的char类型有1个字节,占8位,而它的最高位为符号位,当它为0时为正,1时则为负。C通过对正数做补码操作得到负数。补码,即对一个二进制数取反,然后再加1。比如,0xC4的二进制数为0b11000100,我们可以看到最高位1,在C中这个数就是负数。我们可以通过对这个二进制数做补码操作,得到0b00111100,即60。所以0b11000100在C中表示为-60。

从以上,我们可以发现,GBK编码中,一个汉字占两字节。因为C中char类型只占一个字节,所以需要使用两个char类型来表示汉字。因为C中char为有符号类型,char的表示范围为[-128 ~ 127],所以在遇到大于127的数字时,会被char表示为负数。
其实,我们还可以使用unsigned char来实现。char默认是有符号的,取值范围为:-128 ~127。而unsigned char的取值范围则为:0~255,那么汉字“你”的编码就会被显示为:196和227。
#include <stdio.h>
#include <string.h> int main()
{
// str为字符指针,指向一个字符字面量,这个字符字面量由'\0'结尾
unsigned char *str = (unsigned char *)"你好,世界!Hello, world!";
// chr为字符指针,指向str所指向的字符字面量的第一个字符的地址,即'你'字符的两个char中的第一个
unsigned char *chr = str; printf("%zu %s\n", strlen(str), str);
// 如果遇到'\0',说明字符串结束了
while (*chr != '\0')
{
// 如果chr的编码大于127,则说明遇到了一个汉字
if (*chr > 127)
{
// 打印汉字及汉字的编码
// 注意两个char必须紧紧跟着打印(%c%c),否则会打印出 ??
printf("%c%c: %d %d\n", *chr, *(chr+1), *(chr), *(chr+1));
// chr自增两个字节(因为每个汉字都由两个char组成)
chr += 2;
}
else
{
// 打印英文字符
printf("%c: %d\n", *chr, *chr);
// chr自增一个字节
++chr;
}
} return 0;
}

C语言 使用char字符实现汉字处理的更多相关文章
- 黑马程序员——C语言基础 char字符 数组
Java培训.Android培训.iOS培训..Net培训.期待与您交流! (以下内容是对黑马苹果入学视频的个人知识点总结) (一)char类型 1)存储细节 ASCII单字节表(双字节GBK\GB2 ...
- Java 语言中一个字符占几个字节?
Java中理论说是一个字符(汉字 字母)占用两个字节. 但是在UTF-8的时候 new String("字").getBytes().length 返回的是3 表示3个字节 作者: ...
- 【转载】C#怎么判断字符是不是汉字
支持并尊重原创!原文地址:http://jingyan.baidu.com/article/2c8c281deb79ed0008252af1.html 判断一个字符是不是汉字通常有三种方法,第1种用 ...
- Atian inputmethod 输入法解决方案 方言与多语言多文字支持 英语汉字汉语阿拉伯文的支持 (au
Atian inputmethod 输入法解决方案 方言与多语言多文字支持 英语汉字汉语阿拉伯文的支持 (au 1.1. Overview概论 支持母语优先的战略性产品,主要是针对不想以及不愿使用普通 ...
- 根据Unicode编码用C#语言把它转换成汉字的代码
rt 根据所具有的Unicode编码用C#语言把它转换成汉字的代码 var s = System.Web.HttpUtility.HtmlDecode(Utf8Str); var o = Newton ...
- Swift3.0语言教程获取字符
Swift3.0语言教程获取字符 Swift3.0语言教程获取字符,在字符串中获取某一下标位置(下标索引)处的字符是很常见的功能,在NSString中使用character(at:)方法实现,其语法形 ...
- 如何利用java把文件中的Unicode字符转换为汉字
有些文件中存在Unicode字符和非Unicode字符,如何利用java快速的把文件中的Unicode字符转换为汉字而不影响文件中的其他字符呢, 我们知道虽然java 在控制台会把Unicode字符直 ...
- Regex 字符是不是汉字
Regex 字符是不是汉字 一. 判断一个字符是不是汉字通常有三种方法: 1.用ASCII码判断 在 ASCII码表中,英文的范围是0-127,而汉字则是大于127 string text = & ...
- C 语言实例 - 查找字符在字符串中出现的次数
C 语言实例 - 查找字符在字符串中出现的次数 C 语言实例 C 语言实例 查找字符在字符串中的起始位置(索引值从 开始). 实例 #include <stdio.h> int main( ...
随机推荐
- GO系列-ioutil包
ioutil包提供给外部使用的一共有1个变量,7个方法. // Discard 是一个 io.Writer 接口,调用它的 Write 方法将不做任何事情 // 并且始终成功返回. var Disca ...
- 【翻译】拟合与高斯分布 [Curve fitting and the Gaussian distribution]
参考与前言 英文原版 Original English Version:https://fabiandablander.com/r/Curve-Fitting-Gaussian.html 如何通俗易懂 ...
- Redis学习——数据结构上
一.常用的全局命令 1.查看所有的键: KEYS * KEYS pattern:查找所有符合给定模式 pattern 的 key . KEYS 的速度非常快,但在一个大的数据库中使用它仍然可能造成性能 ...
- python之数据驱动Excel+ddt操作(方法二)
一.Mail163数据如下: 二.Excel+ddt代码如下: import xlrdimport unittestfrom selenium import webdriverfrom seleniu ...
- 第二篇 -- SpringBoot入门Helloworld
之前讲Jmeter接口的时候讲过社区版怎么创建web接口,那么现在用企业版创建一个Springboot项目.企业版自带Springboot,新建起来更加简单. 第一步:新建一个项目 第二步:选择Spr ...
- endnote x9.3.3 for windows安装教程
EndNote X9.3.3 是一款非常nice的实用型文献管理软件,EndNote X9功能极其强劲,便捷好用.本文提供EndNote X9.3.3安装破解激活教程.方法,内附EndNote x9. ...
- CSS 格式 设置标签间距 和 input slot
作者:张艳涛 日期:2020-07-29 CSS设置俩个标签的间距 及 Input Slots <div> <div class="m-b-20 ovf-hd"& ...
- Intouch/ifix关于语音报警的一种设置思路
工控项目最近升级改造,需要使用Intouch/ifix提供一个语音报警功能.这个不像先前提供的单一的声音报警,业主方要求能详细的提供某某水泵或者是某某设备故障报警,这就要求我们这边对语音解析或者基础控 ...
- 🔥 LeetCode 热题 HOT 100(71-80)
253. 会议室 II(NO) 279. 完全平方数 class Solution { public int numSquares(int n) { // dp[i] : 组成和为 i 的最少完全平方 ...
- wdlinux一键安装包
下载安装(ssh登录服务器,执行如下操作即可,需要用到root用户权限来安装) v3版本已经发布,更多可看论坛 wdCP v3版本讨论区 更多安装请看 http://www.wdlinux.cn/bb ...