python网络爬虫-数据储存(七)
数据储存
主要介绍两种数据储存方法:
- 储存在文件中,包括text文件和csv文件
- 存储在数据库中,包括MySQL关系型数据库和mongoDB数据库
存储到txt
title = "第一个文本"# W创建写入 W+创建读取+写入# R读取 r+读取+写入# A 写入 a+ 读取写入 附加with open(r'C:\Users\K1567\Desktop\title.txt', "a+") as f:f.write(title)f.close()output = '\t'.join(['name', 'title', 'age', 'gender'])with open(r'C:\Users\K1567\Desktop\title.txt', "a+") as f:f.write(output)f.close()output = '\t'.join(['name', 'title', 'age', 'gender'])with open(r'C:\Users\K1567\Desktop\title.txt', "r") as f:resulf = f.read()print(resulf)
存储到csv
# 逗号分隔行,换行分隔列with open(r'C:\Users\K1567\Desktop\test.csv', 'r', encoding='UTF-8') as csvfile:csv_reader = csv.reader(csvfile)for row in csv_reader:print(row)print(row[0])output_list = ['1', '2', '3', '4']with open(r'C:\Users\K1567\Desktop\test2.csv', 'a+', encoding='UTF-8', newline='') as csvfile:w = csv.writer(csvfile)w.writerow(output_list)
存储至MySQL数据库
安装MySQL数据库
具体步骤另外搜一搜就好了,有两种安装方式,一种是在线安装,一种离线安装。在线安装的这个比较麻烦没有成功过,本人用的离线安装的。
1.在线的参考一下这个:https://blog.csdn.net/theLostLamb/article/details/78797643
离线安装:
1.先下载好压缩包:zip包下载地址:https://dev.mysql.com/downloads/file/?id=476233,进入页面后可以不登录。点击底部“No thanks, just start my download.”即可开始下载。
2.安装: 解压zip包到安装目录---配置初始化的my.ini文件
点击查看代码
[mysqld]# 设置3306端口port=3306# 设置mysql的安装目录basedir=E:\DownLoad\mysql\mysql-8.0.27-winx64# 设置mysql数据库的数据的存放目录datadir=E:\DownLoad\mysql\mysql-8.0.27-winx64\data# 允许最大连接数max_connections=200# 允许连接失败的次数。这是为了防止有人从该主机试图攻击数据库系统max_connect_errors=10# 服务端使用的字符集默认为UTF8character-set-server=utf8# 创建新表时将使用的默认存储引擎default-storage-engine=INNODB# 默认使用“mysql_native_password”插件认证default_authentication_plugin=mysql_native_password[mysql]# 设置mysql客户端默认字符集default-character-set=utf8
注意:其中的data目录不需要创建,下一步初始化工作中会自动创建。
3.cmd进入bin文件夹
通过管理员权限进入cmd(如果不是管理员权限就会出现问题),进入MySQL安装目录的bin目录下

4.初始化数据库:mysqld --initialize --console
执行完成后,会打印 root 用户的初始默认密码
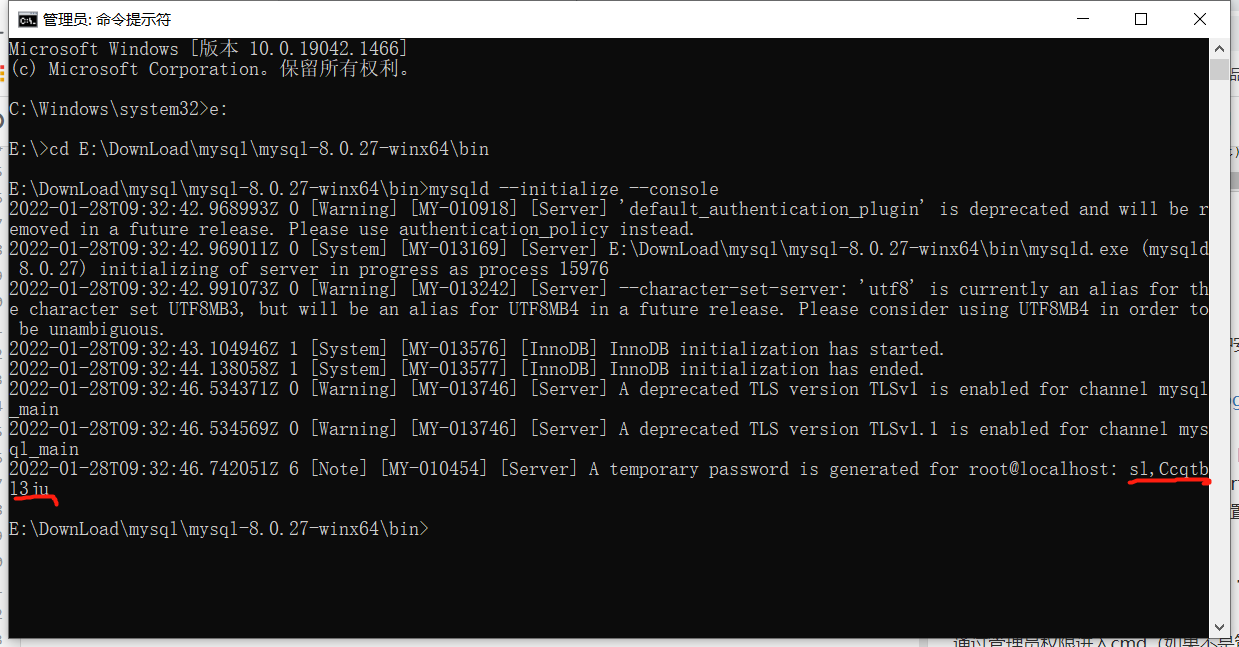
要是你手贱,关快了,或者没记住,那也没事,删掉初始化的 datadir 目录,再执行一遍初始化命令,又会重新生成的。
5.安装服务:mysqld --install [服务名] 后面的服务名可以不写,默认的名字为 mysql。当然,如果你的电脑上需要安装多个MySQL服务,就可以用不同的名字区分了,比如 mysql5 和 mysql8。安装完成之后,就可以通过命令net start mysql启动MySQL的服务了。通过命令net stop mysql停止服务。通过命令sc delete MySQL/mysqld -remove卸载 MySQL 服务
6.更改密码:mysql -u root -p
这时候会提示输入密码,记住了上面第3.1步安装时的密码,填入即可登录成功,进入MySQL命令模式。
在MySQL中执行命令:
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '新密码';
可以用 命令查看一下默认安装的数据库:
show databases;
use mysql;
show tables;
创建数据库
-- 创建数据库CREATE DATABASE scraping-- 切换数据库USE scraping-- 创建表CREATE TABLE urls(id int not null auto_increment,url varchar(1000) not null,content varchar(4000) not null,created_time timestamp default current_timestamp,primary key (id))
连接操作MySQL
# 创建数据库连接conn = MySQLdb.Connection(host='localhost', user='root', passwd='123456', db='scraping')# 创建游标cur = conn.cursor()# 写入纯SQL语句cur.execute("insert into urls (url,content)VALUES('www.baidu.com','百度')")# 关闭游标cur.close()# 执行SQLconn.commit()# 关闭连接conn.close()
连接MongoDB
安装mongdb
1.下载安装包,有安装版的可执行文件,一直Next就可以安装,免安装版的要解压到本地计算机。在解压的目录下新建data和logs文件夹,新建mongo.config文件,在data文件下新建db文件夹,mongo.conf文件添加配置信息如下:
dbpath=E:\DownLoad\MongoDB\mongodb-win32-x86_64-2012plus-4.2.18-rc0-12-gbe2c559\data\db #数据库路径logpath=E:\DownLoad\MongoDB\mongodb-win32-x86_64-2012plus-4.2.18-rc0-12-gbe2c559\logs\mongo.log #日志输出文件路径logappend=true #错误日志采用追加模式journal=true #启用日志文件,默认启用quiet=true #这个选项可以过滤掉一些无用的日志信息,若需要调试使用请设置为falseport=27017 #端口号 默认为27017
2.启动mongdb
打开命令行窗口(cmd打开)--cd 跳转到mongodb的bin目录下--执行命令告诉mongodb自己要把数据存放到哪里,在命令行输入:mongod -dbpath E:\mongodbFiles\db\data (根据自己刚才创建的data文件夹路径,此处为我创建的实际路径)
mongodb默认连接端口27017,如果出现如图的情况,在浏览器访问:http://localhost:27017
3.打开新的cmd命令行窗口,之前的不要关闭。
在新的命令行cd到mongodb的bin目录下,继而输入命令:mongod --config D:\software\professional\mongoDB\mongo.config --install -serviceName "MongoDB"
这一步是告诉mongodb,配置文件的方法,并将mongodb作为系统服务启动。
命令行窗口(cmd)输入services.msc命令——查看服务可以看到MongoDB服务,点击可以启动。
弹出窗口如下,找到MongoDB服务,双击MongoDB项(此处我的已经启动了),弹出窗口点击启动,并将启动类型设置为自动:至此已经完全配置完毕。
操作mongdb
1.使用mongodb有两种启动方式,一种是以程序的方式打开另外一种是以window服务的方式打开
//查看所有数据库show dbs
使用python操作mongdb
client = MongoClient('localhost', 27017)db = client.blog_databasecollection = db.bloglink = "http://www.santostang.com/"headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'}r = requests.get(link, headers=headers)soup = BeautifulSoup(r.text, "html.parser")title_list = soup.find_all('h1', class_="post-title")for h in title_list:url = h.a['href']title = h.a.text.strip()post = {"url": url,"title": title,"date": datetime.datetime.utcnow()}collection.insert_one(post)
MongoDB爬虫实践:虎扑论坛
使用mongodb的类,可以很方便的连接数据库,提取数据库中的内容,向数据库中加入数据以及更新数据库中的数据。
# coding=utf-8from pymongo import MongoClientclass MongoAPI(object):def __init__(self, db_ip, db_port, db_name, table_name):self.db_ip = db_ipself.db_port = db_portself.db_name = db_nameself.table_name = table_nameself.conn = MongoClient(host=self.db_ip, port=self.db_port)self.db = self.conn[self.db_name]self.table = self.db[self.table_name]# 获取数据库中的第一条数据def get_one(self, query):return self.table.find_one(query, projection={"_id": False})# 获取数据库满足条件的所有数据def get_all(self, query):return self.table.find(query)# 向集合中添加数据def add(self, kv_dict):return self.table.insert_one(kv_dict)# 删除集合中的数据def delete(self, query):return self.table.delete_many(query)# 查看集合中是否包含满足条件的数据 找到了返回True 没找到返回Falsedef check_exist(self, query):ret = self.table.find_one(query)return ret != None# 更新集合中的数据在集合中找不到就会增加一条数据def update(self, query, kv_dict):self.table.update_one(query, {"$set": kv_dict}, update=True)
from MongoAPI import MongoAPI# 连接数据库hupu中的post集合。hupu_post = MongoAPI("localhost", 27017, "hupu", "post")for i in range(1, 11):link = "https://bbs.hupu.com/bxj" + "-" + str(i)headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'}r = requests.get(link, headers=headers)suop = BeautifulSoup(r.text, "html.parser")li_list = suop.find_all("li", class_="bbs-sl-web-post-body")for li in li_list:title = li.find('div', class_="post-title").a.text.strip()title_link = li.find('div', class_="post-title").a["href"]datum = li.find("div", class_="post-datum").text.strip()reply = datum.split('/')[0]browse = datum.split('/')[1]author = li.find("div", class_="post-auth").text.strip()start_date = li.find("div", class_="post-time").text.strip()# data = datetime.datetime.strptime(start_date, '%Y-%m-%d').date()# 添加数据hupu_post.update({"title": title, "title_link": title_link, "reply": reply, "browse": browse, "author": author,"data": start_date})print(title, title_link, reply, browse, author, start_date)time.sleep(1)
python网络爬虫-数据储存(七)的更多相关文章
- python网络爬虫数据中的三种数据解析方式
一.正则解析 常用正则表达式回顾: 单字符: . : 除换行以外所有字符 [] :[aoe] [a-w] 匹配集合中任意一个字符 \d :数字 [0-9] \D : 非数字 \w :数字.字母.下划线 ...
- Python网络爬虫数据解析的三种方式
request实现数据爬取的流程: 指定url 基于request发起请求 获取响应的数据 数据解析 持久化存储 1.正则解析: 常用的正则回顾:https://www.cnblogs.com/wqz ...
- Python网络爬虫
http://blog.csdn.net/pi9nc/article/details/9734437 一.网络爬虫的定义 网络爬虫,即Web Spider,是一个很形象的名字. 把互联网比喻成一个蜘蛛 ...
- 《精通python网络爬虫》笔记
<精通python网络爬虫>韦玮 著 目录结构 第一章 什么是网络爬虫 第二章 爬虫技能概览 第三章 爬虫实现原理与实现技术 第四章 Urllib库与URLError异常处理 第五章 正则 ...
- Python 网络爬虫干货总结
Python 网络爬虫干货总结 爬取 对于爬取来说,我们需要学会使用不同的方法来应对不同情景下的数据抓取任务. 爬取的目标绝大多数情况下要么是网页,要么是 App,所以这里就分为这两个大类别来进行了介 ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- Python 正则表达式 (python网络爬虫)
昨天 2018 年 01 月 31 日,农历腊月十五日.20:00 左右,152 年一遇的月全食.血月.蓝月将今晚呈现空中,虽然没有看到蓝月亮,血月.月全食也是勉强可以了,还是可以想像一下一瓶蓝月亮洗 ...
- Python网络爬虫笔记(五):下载、分析京东P20销售数据
(一) 分析网页 下载下面这个链接的销售数据 https://item.jd.com/6733026.html#comment 1. 翻页的时候,谷歌F12的Network页签可以看到下面 ...
- 如何利用Python网络爬虫抓取微信朋友圈的动态(上)
今天小编给大家分享一下如何利用Python网络爬虫抓取微信朋友圈的动态信息,实际上如果单独的去爬取朋友圈的话,难度会非常大,因为微信没有提供向网易云音乐这样的API接口,所以很容易找不到门.不过不要慌 ...
随机推荐
- 【LeetCode】20. Valid Parentheses 有效的括号
作者: 负雪明烛 id: fuxuemingzhu 个人博客:http://fuxuemingzhu.cn/ 个人公众号:负雪明烛 本文关键词:有效,括号,括号匹配,栈,题解,leetcode, 力扣 ...
- 【LeetCode】310. Minimum Height Trees 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 BFS 相似题目 参考资料 日期 题目地址:http ...
- Sum of Consecutive Integers
Sum of Consecutive Integers 题目链接 题意 问N能够分解成多少种不同的连续数的和. 思路 连续数是一个等差数列:$$ \frac{(2a1 + n -1)n}{2} = T ...
- 【LeetCode】842. Split Array into Fibonacci Sequence 解题报告(Python & C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 日期 题目地址:https://leetcode.c ...
- MySQL数据库报错 > 1366 - Incorrect string value: ‘\xE6\xB1\x9F\xE6\x96\x87‘ for column ‘Teacher‘ at row 1
数据库报错这个多半是数据库在创建的时候没有选择字符编码,导致输入中文的时候出现报错. > 1366 - Incorrect string value: '\xE6\xB1\x9F\xE6\x96 ...
- RazorEngine.NetCore 相见恨晚,它让我彻底放弃了T4模板
在dbfrist 时代,用T4模板生成代码,貌似还没有感觉到别扭.但是到了codefrist 后,我想要实体生成生成备注,我就得想方设法的去把备注弄到数据库,然后 还要处理模型中类型像枚举这种属性,渐 ...
- RabbitMQ开启SSL与SpringBoot连接测试
楔子 近期公司程序被安全扫描出 远程主机允许明文身份验证 中风险漏洞,查了下修复方案,RabbitMQ官方提供了SSL连接方式,而且 SpringBoot AMQP 也支持 SSL 连接.以下将配置R ...
- ES6解构与默认值的结合使用
在读源码框架时遇到方法中有这样的形参:{ message = 'ok' } = {} 有点懵为什么已经赋值了还又赋了一个空对象 随后我去看了阮一峰老师的 ECMAScript 6 入门才明白.这是参数 ...
- solr - 安装ik中文分词 和初始化富文本检索
1.下载安装包 https://repo1.maven.org/maven2/org/apache/solr/solr-dataimporthandler/7.4.0/solr-dataimporth ...
- [ vue ] 自定义组件的 v-model 理解
需求场景描述: 1. 在父组件 myself.vue 里面定义数据 button_val 2. 在父组件 myself.vue.里面定义按钮,它的功能是吧 button_val 的值 -1 ---- ...